map
تختلف Go عن اللغات الأخرى في أن دعم جدول التعيين يتم توفيره بواسطة الكلمة المفتاحية map، وليس بتغليفه في المكتبة القياسية. جدول التعيين هو هيكل بيانات يُستخدم في العديد من السيناريوهات، وله العديد من طرق التنفيذ في الطبقة السفلية. أكثر طريقتين شيوعًا هما الشجرة الحمراء-السوداء وجدول التجزئة. تستخدم Go طريقة جدول التجزئة.
TIP
تنفيذ الخريطة يتضمن الكثير من عمليات تحريك المؤشرات، لذا قراءة هذه المقالة تتطلب معرفة بمكتبة unsafe القياسية.
البنية الداخلية
بنية runtime.hmap تمثل map في Go. مثل الشرائح، التنفيذ الداخلي لـ map هو أيضًا بنية.
// A header for a Go map.
type hmap struct {
// Note: the format of the hmap is also encoded in cmd/compile/internal/reflectdata/reflect.go.
// Make sure this stays in sync with the compiler's definition.
count int // # live cells == size of map. Must be first (used by len() builtin)
flags uint8
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields
}التعليقات الإنجليزية أوضحت بالفعل، فيما يلي شرح بسيط للحقول الأكثر أهمية:
count، يمثل عدد العناصر في hmap، والنتيجة تساويlen(map).flags، بتات العلم لـ hmap، تُستخدم للإشارة إلى الحالة التي عليها hmap، لها الاحتمالات التالية:goconst ( iterator = 1 // المتكرر يستخدم الدلو oldIterator = 2 // المتكرر يستخدم الدلو القديم hashWriting = 4 // كوروتين واحد يكتب في hmap sameSizeGrow = 8 // يتم توسيع بنفس الحجم )B، عدد دلاء التجزئة في hmap هو1 << B.noverflow، العدد التقريبي لدلاء الفيضان في hmap.hash0، بذرة التجزئة، تُحدد عند إنشاء hmap، وتُستخدم لحساب قيمة التجزئة.buckets، مؤشر لمصفوفة دلاء التجزئة.oldbuckets، مؤشر لمصفوفة دلاء التجزئة القديمة قبل التوسع.extra، يحتوي على دلاء الفيضان في hmap. دلاء الفيضان تعني أن الدلو الحالي ممتلئ، فيتم إنشاء دلو جديد لتخزين العناصر، والدلو الجديد هو دلو الفيضان.
buckets في hmap هو مؤشر لمصفوفة الدلاء، والذي يُمثله في Go البنية runtime.bmap، كما يلي:
// A bucket for a Go map.
type bmap struct {
tophash [bucketCnt]uint8
}من أعلاه يمكن رؤية أنه يحتوي فقط على حقل tophash، هذا الحقل يُستخدم لتخزين البتات الثمانية العليا لكل مفتاح. لكن في الواقع، حقول bmap أكثر من ذلك، لأن map يمكنها تخزين أزواج مفتاح-قيمة من أنواع مختلفة، لذا يجب استنتاج المساحة المشغولة بناءً على النوع في وقت الترجمة. دالة MapBucketType في cmd/compile/internal/reflectdata/reflect.go هي المسؤولة عن بناء bmap في وقت الترجمة، وستقوم بسلسلة من الفحوصات، مثل التحقق مما إذا كان نوع المفتاح comparable.
// MapBucketType makes the map bucket type given the type of the map.
func MapBucketType(t *types.Type) *types.Typeلذا في الواقع، بنية bmap كما يلي، لكن هذه الحقول غير مرئية لنا، وتقوم Go بالوصول إليها من خلال تحريك مؤشرات unsafe في العمليات الفعلية:
type bmap struct {
tophash [BUCKETSIZE]uint8
keys [BUCKETSIZE]keyType
elems [BUCKETSIZE]elemType
overflow *bucket
}بعض التفسيرات:
tophash، يخزن قيم البتات الثمانية العليا لكل مفتاح. لعنصر tophash عدة قيم خاصة:goconst ( emptyRest = 0 // العنصر الحالي فارغ، ولا توجد قيم مفاتيح متاحة بعده emptyOne = 1 // العنصر الحالي فارغ، لكن توجد قيم مفاتيح متاحة بعده evacuatedX = 2 // يظهر عند التوسع، يظهر فقط في oldbuckets، يعني أن العنصر نُقل إلى النصف العلوي من مصفوفة الدلاء الجديدة evacuatedY = 3 // يظهر عند التوسع، يظهر فقط في oldbuckets، يعني أن العنصر نُقل إلى النصف السفلي من مصفوفة الدلاء الجديدة evacuatedEmpty = 4 // يظهر عند التوسع، العنصر نفسه فارغ، سُمي عند النقل minTopHash = 5 // الحد الأدنى لقيمة tophash لمفتاح عادي )طالما أن قيمة
tophash[i]أكبر منminTophash، فهذا يعني أن الفهرس المقابل يحتوي على زوج مفتاح-قيمة عادي.keys، مصفوفة لتخزين المفاتيح من النوع المحدد.elems، مصفوفة لتخزين القيم من النوع المحدد.overflow، مؤشر لدلو الفيضان.
بما أن أزواج المفتاح-القيمة لا يمكن الوصول إليها مباشرة من خلال حقول البنية، أعلنت Go مسبقًا ثابتًا dataoffset، والذي يمثل إزاحة الذاكرة للبيانات في bmap.
const dataOffset = unsafe.Offsetof(struct {
b bmap
v int64
}{}.v)في الواقع، المفاتيح والقيم تُخزن في عنوان ذاكرة متصل، مشابه للبنية التالية، وهذا لتجنب هدر المساحة الناتج عن محاذاة الذاكرة.
k1,k2,k3,k4,k5,k6...v1,v2,v3,v4,v5,v6...لذا بالنسبة لـ bmap، بعد تحريك المؤشر بمقدار dataoffset، ثم تحريكه i*sizeof(keyType) يكون عنوان المفتاح i:
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))الحصول على عنوان القيمة i يتم بنفس الطريقة:
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))مؤشر buckets في hmap يشير إلى عنوان أول دلو تجزئة. إذا أردت الحصول على عنوان الدلو i، الإزاحة تكون i*sizeof(bucket).
b := (*bmap)(add(h.buckets, i*uintptr(t.BucketSize)))في المحتوى اللاحق، ستظهر هذه العمليات بشكل متكرر.
التجزئة
التعارض
في hmap، هناك حقل extra مخصص لتخزين معلومات دلاء الفيضان، سيشير إلى شريحة تحتوي على دلاء الفيضان، وبنيتها كما يلي:
type mapextra struct {
// شريحة مؤشرات دلاء الفيضان
overflow *[]*bmap
// شريحة مؤشرات دلاء الفيضان القديمة قبل التوسع
oldoverflow *[]*bmap
// مؤشر لأول دلو فيضان فارغ
nextOverflow *bmap
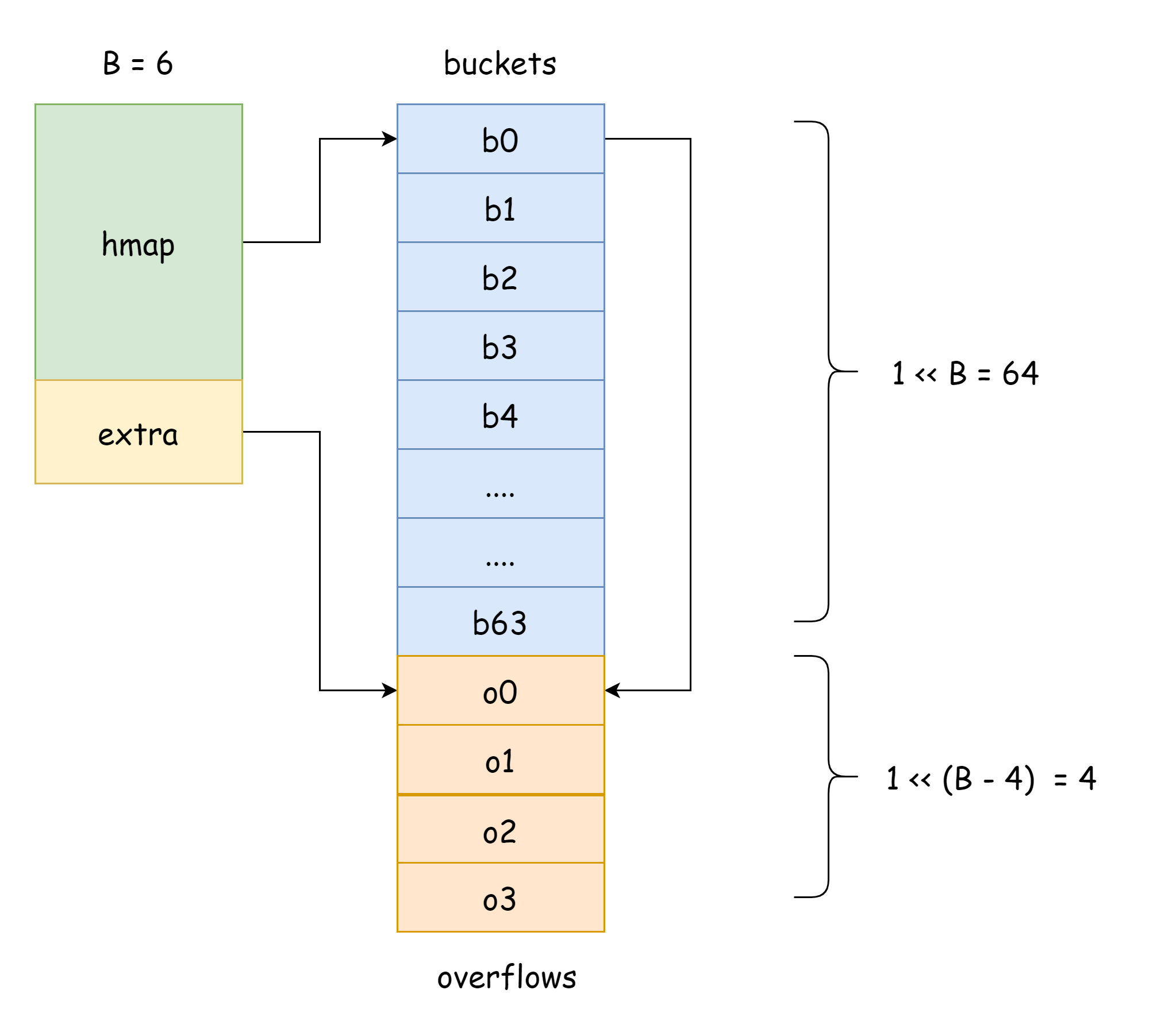
}
TIP
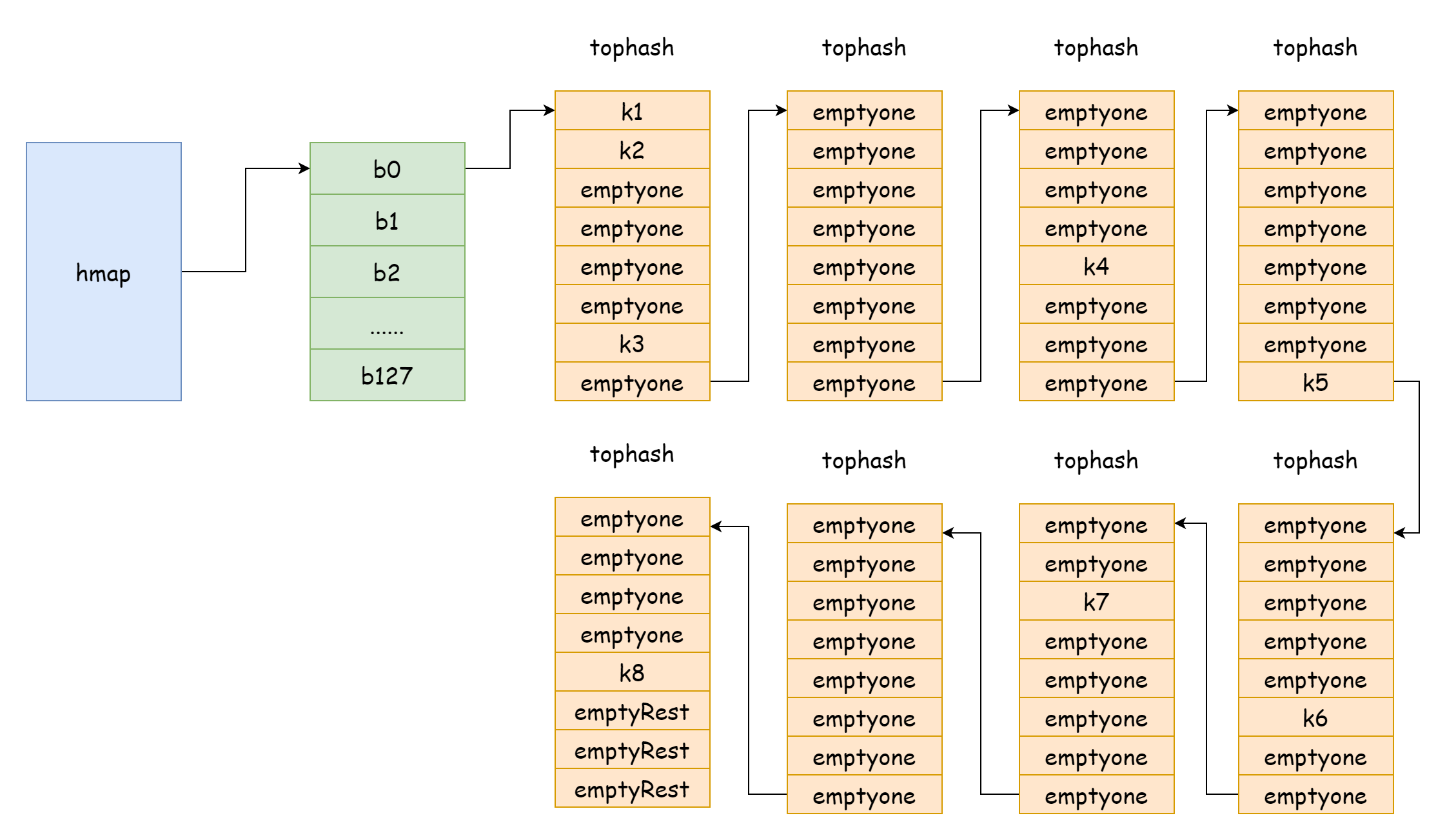
في الصورة أعلاه، الجزء الأزرق هو مصفوفة دلاء التجزئة، والجزء البرتقالي هو مصفوفة دلاء الفيضان. فيما يلي سيُشار إلى دلاء الفيضان ببساطة كدلاء فيضان.
الصورة أعلاه توضح بشكل جيد البنية العامة لـ hmap. buckets يشير إلى مصفوفة دلاء التجزئة، extra يشير إلى مصفوفة دلاء الفيضان، الدلو bucket0 يشير إلى دلو الفيضان overflow0. النوعان من الدلاء موجودان في شريحتين منفصلتين، وذاكرة كلا النوعين متصلة. عندما يُخصص مفتاحان إلى نفس الدلو بعد حساب التجزئة، هذه الحالة تسمى تعارض التجزئة. طريقة Go لحل تعارض التجزئة هي طريقة السلسلة. عندما يتجاوز عدد المفاتيح المتعارضة سعة الدلو، عادة 8، تعتمد قيمته على internal/abi.MapBucketCount. ثم يُ创建 دلو جديد لتخزين هذه المفاتيح، وهذا الدلو يسمى دلو الفيضان، بمعنى أن الدلو الأصلي لم يستطع الاستيعاب، فتدفق العناصر إلى هذا الدلو الجديد. بعد الإنشاء، سيكون للدلو مؤشر يشير إلى دلو الفيضان الجديد، وروابط مؤشرات هذه الدلاء تشكل قائمة مرتبطة بـ bmap.
بالنسبة لطريقة السلسلة، يُستخدم عامل الحمل لقياس حالة تعارض جدول التجزئة، وصيغة حسابه كما يلي:
loadfactor := len(elems) / len(buckets)كلما زاد عامل الحمل، زادت تعارضات التجزئة، أي زاد عدد دلاء الفيضان. عند قراءة وكتابة جدول التجزئة، سيحتاج الأمر لاجتياز المزيد من قوائم دلاء الفيضان للعثور على الموقع المحدد، لذا ينخفض الأداء. لتحسين هذه الحالة، يجب زيادة عدد buckets، أي التوسع. بالنسبة لـ hmap، هناك حالتان تثيران التوسع:
- عامل الحمل يتجاوز العتبة
bucketCnt*13/16، قيمته على الأقل 6.5. - عدد دلاء الفيضان كبير جدًا
كلما صغر عامل الحمل، دل ذلك على انخفاض معدل استخدام ذاكرة hmap، وازدياد الذاكرة المشغولة. الدالة المستخدمة في Go لحساب عامل الحمل هي runtime.overLoadFactor، والكود كما يلي:
func overLoadFactor(count int, B uint8) bool {
return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)
}حيث loadFactorNum و loadFactorDen كلاهما ثوابت، و bucketshift تحسب 1 << B، ومن المعروف أن:
loadFactorNum = (bucketCnt * 13 / 16) * loadFactorDenلذا يمكن تبسيطها للحصول على:
count > bucketCnt && uintptr(count) / 1 << B > (bucketCnt * 13 / 16)حيث قيمة (bucketCnt * 13 / 16) هي 6.5، و 1 << B هو عدد دلاء التجزئة. لذا وظيفة هذه الدالة هي حساب ما إذا كانت قيمة عدد العناصر مقسومًا على عدد الدلاء أكبر من عامل الحمل 6.5.
الحساب
دالة حساب التجزئة الداخلية في Go موجودة في ملف runtime/alg.go وهي f32hash، كما يلي، وتتضمن معالجة لحالتين NaN و 0:
func f32hash(p unsafe.Pointer, h uintptr) uintptr {
f := *(*float32)(p)
switch {
case f == 0:
return c1 * (c0 ^ h) // +0, -0
case f != f:
return c1 * (c0 ^ h ^ uintptr(fastrand())) // any kind of NaN
default:
return memhash(p, h, 4)
}
}يمكن ملاحظة أن طريقة حساب تجزئة الخريطة ليست مبنية على النوع، بل على الذاكرة، وستنتهي في النهاية بالدالة memhash، التي تُنفذ بالتجميع، والمنطق موجود في runtime/asm*.s. قيمة التجزئة المبنية على الذاكرة لا يجب حفظها بشكل دائم، لأنها يجب أن تُستخدم فقط في وقت التشغيل، ولا يمكن ضمان أن توزيع الذاكرة سيكون متطابقًا تمامًا في كل تشغيل.
في نفس الملف توجد دالة تسمى typehash، هذه الدالة تحسب قيمة التجزئة بناءً على أنواع مختلفة، لكن الخريطة لا تستخدم هذه الدالة لحساب التجزئة.
func typehash(t *_type, p unsafe.Pointer, h uintptr) uintptrهذا التنفيذ أبطأ من السابق، لكنه أكثر عمومية، ويُستخدم بشكل أساسي في الانعكاس وتوليد الدوال في وقت الترجمة، مثل الدالة التالية:
//go:linkname reflect_typehash reflect.typehash
func reflect_typehash(t *_type, p unsafe.Pointer, h uintptr) uintptr {
return typehash(t, p, h)
}الإنشاء
هناك طريقتان لتهيئة الخريطة، كما ذُكر في مقدمة اللغة: الأولى باستخدام الكلمة المفتاحية map مباشرة، والثانية باستخدام دالة make. بصرف النظر عن طريقة التهيئة، في النهاية يتم إنشاء الخريطة بواسطة runtime.makemap، وتوقيع الدالة كما يلي:
func makemap(t *maptype, hint int, h *hmap) *hmapالمعاملات:
t، يشير إلى نوع الخريطة، فالأنواع المختلفة تتطلب مساحة ذاكرة مختلفةhint، يشير إلى المعامل الثاني لدالةmake، السعة المتوقعة لعناصر الخريطةh، يشير إلى مؤشر hmap، يمكن أن يكونnil
القيمة المرجعة هي مؤشر hmap بعد التهيئة. لهذه الدالة عدة مهام رئيسية أثناء التهيئة. أولاً حساب ما إذا كانت الذاكرة المتوقع تخصيصها تتجاوز الحد الأقصى للتخصيص:
// ضرب السعة المتوقعة في حجم ذاكرة نوع الدلو
mem, overflow := math.MulUintptr(uintptr(hint), t.Bucket.Size_)
// تجاوز رقمي أو تجاوز الحد الأقصى للتخصيص
if overflow || mem > maxAlloc {
hint = 0
}كما ذُكر سابقًا في البنية الداخلية، يتكون hmap من دلاء، وفي حالة أدنى استغلال للذاكرة، كل دلو يحتوي على عنصر واحد فقط، ويشغل أكثر ذاكرة. لذا الحد الأقصى المتوقع للذاكرة هو عدد العناصر مضروبًا في حجم الذاكرة للنوع المقابل. عند تجاوز النتيجة رقميًا أو تجاوز الحد الأقصى للذاكرة القابلة للتخصيص، يُضبط hint على 0.
الخطوة الثانية تهيئة hmap وحساب بذرة تجزئة عشوائية:
// التهيئة
if h == nil {
h = new(hmap)
}
// الحصول على بذرة تجزئة عشوائية
h.hash0 = fastrand()ثم حساب سعة دلاء التجزئة بناءً على قيمة hint:
B := uint8(0)
// الاستمرار في التكرار حتى hint / 1 << B < 6.5
for overLoadFactor(hint, B) {
B++
}
// الإسناد إلى hmap
h.B = Bمن خلال التكرار المستمر للعثور على أول قيمة B تحقق (hint / 1 << B) < 6.5، وإسنادها إلى hmap. بعد معرفة سعة دلاء التجزئة، الخطوة الأخيرة هي تخصيص ذاكرة لدلاء التجزئة:
if h.B != 0 {
var nextOverflow *bmap
// الدلاء المخصصة ودلاء الفيضان الفارغة المخصصة مسبقًا
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
// إذا تم تخصيص دلاء فيضان فارغة مسبقًا، أشِر إليها
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}دالة makeBucketArray تخصص ذاكرة بحجم مناسب لدلاء التجزئة بناءً على قيمة B، بالإضافة إلى تخصيص دلاء فيضان فارغة مسبقًا. عندما يكون B أقل من 4، لا تُنشأ دلاء فيضان. إذا كان أكبر من أو يساوي 4، تُنشأ 2^B-4 دلو فيضان. الكود المقابل في دالة runtime.makeBucketArray:
base := bucketShift(b)
nbuckets := base
// أقل من 4 لن تُنشأ دلاء فيضان
if b >= 4 {
// إضافة 1 << (b-4) لعدد الدلاء المتوقع
nbuckets += bucketShift(b - 4)
// الذاكرة المطلوبة لدلاء الفيضان
sz := t.Bucket.Size_ * nbuckets
// تقريب المساحة للأعلى
up := roundupsize(sz)
if up != sz {
// إذا لم تتساويا، أعد الحساب باستخدام up
nbuckets = up / t.Bucket.Size_
}
}base يشير إلى عدد الدلاء المتوقع تخصيصها، nbuckets يشير إلى عدد الدلاء الفعلي المخصص، وهو يضيف عدد دلاء الفيضان.
if base != nbuckets {
// أول دلو فيضان متاح
nextOverflow = (*bmap)(add(buckets, base*uintptr(t.BucketSize)))
// لتقليل تكلفة تتبع دلاء الفيضان، اجعل مؤشر الفيضان في آخر دلو فيضان متاح يشير إلى رأس دلو التجزئة
last := (*bmap)(add(buckets, (nbuckets-1)*uintptr(t.BucketSize)))
// آخر دلو فيضان يشير إلى دلو التجزئة
last.setoverflow(t, (*bmap)(buckets))
}عندما لا تتساوى القيمتان، فهذا يعني أنه تم تخصيص دلاء فيضان إضافية. مؤشر nextoverflow يشير إلى أول دلو فيضان متاح. من هذا يتضح أن دلاء التجزئة ودلاء الفيضان موجودة فعليًا في نفس كتلة الذاكرة المتصلة، وهذا يفسر لماذا في الصورة تكون مصفوفة دلاء التجزئة ومصفوفة دلاء الفيضان متجاورتين.
الوصول
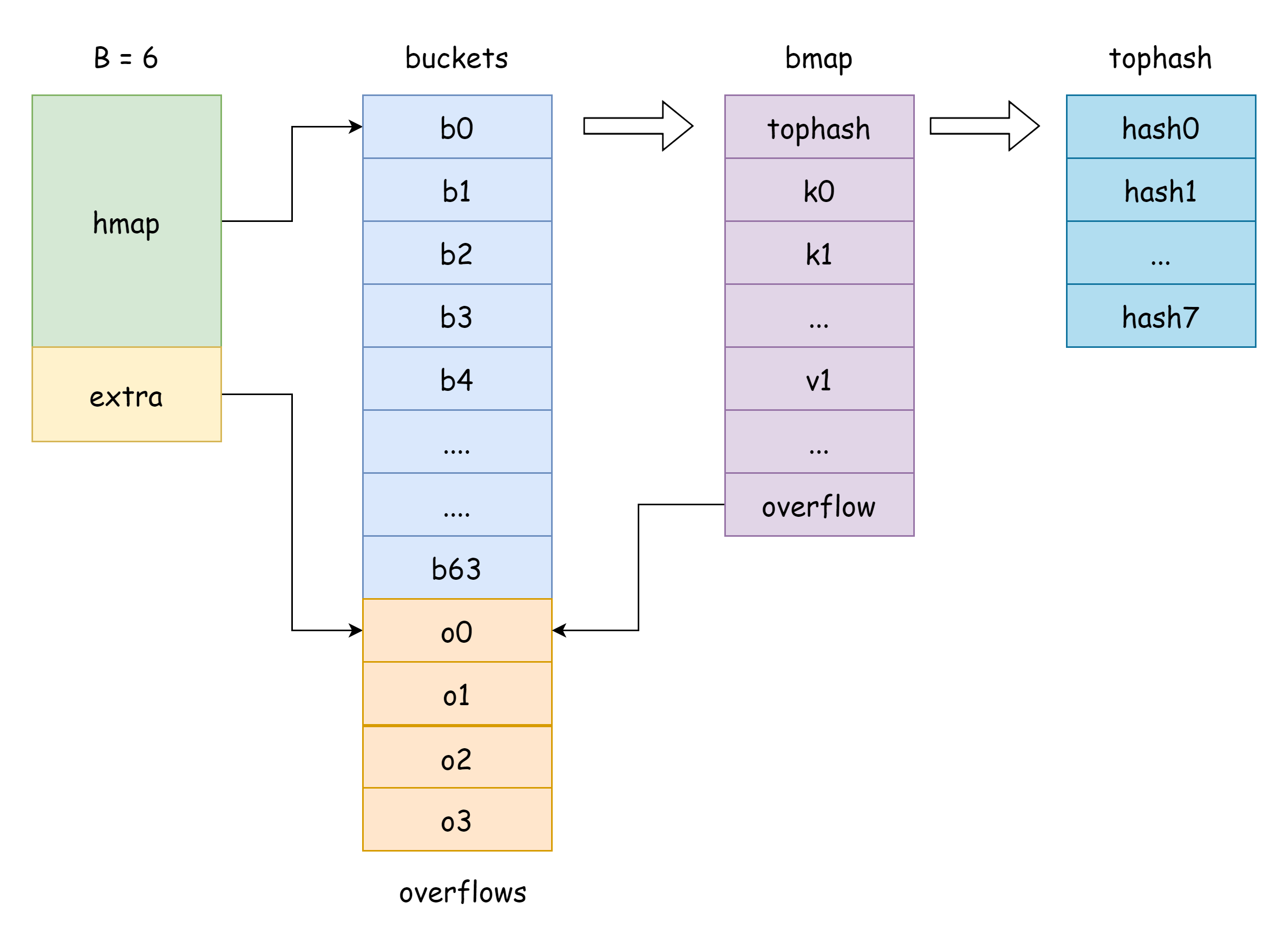
كما ذُكر في مقدمة القواعد، هناك ثلاث طرق للوصول إلى الخريطة:
# الوصول المباشر للقيمة
val := dict[key]
# الوصول للقيمة ومعرفة ما إذا كان المفتاح موجودًا
val, exist := dict[key]
# اجتياز الخريطة
for key, val := range dict{
}كل طريقة من هذه الطرق الثلاث تستخدم دوال مختلفة، واجتياز الخريطة بـ for range هو الأكثر تعقيدًا.
المفتاح والقيمة
بالنسبة للطريقتين الأوليين، هناك دالتان مقابلتان: runtime.mapaccess1 و runtime.mapaccess2، وتوقيع الدالتين:
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer
func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool)حيث key هو مؤشر لمفتاح الخريطة المراد الوصول إليه، وتُرجع الدالة المؤشر فقط. عند الوصول، يجب أولاً حساب قيمة تجزئة المفتاح وتحديد موقعه في أي دلو تجزئة:
// معالجة الحدود
if h == nil || h.count == 0 {
if t.HashMightPanic() {
t.Hasher(key, 0) // see issue 23734
}
return unsafe.Pointer(&zeroVal[0])
}
// منع القراءة والكتابة المتزامنة
if h.flags&hashWriting != 0 {
fatal("concurrent map read and map write")
}
// حساب قيمة التجزئة باستخدام hasher للنوع المحدد
hash := t.Hasher(key, uintptr(h.hash0))
// (1 << B) - 1
m := bucketMask(h.B)
// تحريك المؤشر لتحديد موقع الدلو الذي يحتوي على المفتاح
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.BucketSize)))في بداية الوصول، تتم معالجة الحالات الحدودية ومنع القراءة والكتابة المتزامنة للخريطة. عندما تكون الخريطة في حالة قراءة وكتابة متزامنة، يحدث panic. ثم حساب قيمة التجزئة. دالة bucketMask تحسب (1 << B) - 1. العملية hash & m تساوي hash & (1 << B) - 1، وهي عملية باقِي ثنائية، تكافئ hash % (1 << B)، وميزة استخدام العمليات البتية أنها أسرع. الأسطر الثلاثة الأخيرة تأخذ باقي قيمة التجزئة المحسوبة مع عدد الدلاء الحالي للحصول على رقم الدلو، ثم تحريك المؤشر للحصول على مؤشر الدلو.
بعد معرفة الدلو الذي يقع فيه المفتاح، يمكن البدء في البحث:
// الحصول على البتات الثمانية العليا لقيمة التجزئة
top := tophash(hash)
bucketloop:
// اجتياز القائمة المرتبطة bmap
for ; b != nil; b = b.overflow(t) {
// عناصر bmap
for i := uintptr(0); i < bucketCnt; i++ {
// مقارنة top المحسوب بعناصر tophash
if b.tophash[i] != top {
// ما يلي فارغ، لا يوجد المزيد
if b.tophash[i] == emptyRest {
break bucketloop
}
// عدم التساوي يعني الاستمرار في اجتياز دلو الفيضان
continue
}
// تحريك المؤشر للحصول على المفتاح المقابل للفهرس i
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
// معالجة المؤشر
if t.IndirectKey() {
k = *((*unsafe.Pointer)(k))
}
// مقارنة ما إذا كان المفتاحان متساويين
if t.Key.Equal(key, k) {
// إذا تساويا، حرك المؤشر لإرجاع العنصر المقابل للمفتاح k
// من هذا السطر يتضح أن عناوين ذاكرة المفتاح والقيمة متصلة
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
if t.IndirectElem() {
e = *((*unsafe.Pointer)(e))
}
return e
}
}
}
// لم يُعثر عليه، إرجاع القيمة الصفرية
return unsafe.Pointer(&zeroVal[0])عند تحديد موقع دلو التجزئة، يتم ذلك من خلال الباقي، لذا موقع المفتاح في أي دلو يعتمد على البتات الدنيا لقيمة التجزئة، وعدد البتات الدنيا يعتمد على حجم B. بعد العثور على الدلو، يحتوي tophash على البتات الثمانية العليا لقيمة التجزئة، لأن قيمة الباقي للبتات الدنيا هي نفسها، فلا حاجة لمقارنة المفاتيح واحدًا تلو الآخر، بل فقط مقارنة البتات الثمانية العليا تكفي. الحصول على البتات الثمانية العليا من قيمة التجزئة المحسوبة مسبقًا، ومقارنتها واحدة واحدة مع مصفوفة tophash في bmap. إذا تساوت البتات الثمانية العليا، تتم مقارنة المفاتيح. إذا تساوت المفاتيح، فهذا يعني العثور على العنصر. إذا لم تتساوى، يستمر اجتياز مصفوفة tophash. إذا لم يُعثر عليه، يستمر اجتياز القائمة المرتبطة لدلاء الفيضان bmap حتى يكون tophash[i] في bmap يساوي emptyRest للخروج من الحلقة، وأخيرًا إرجاع القيمة الصفرية للنوع المقابل.
دالة mapaccess2 لها نفس منطق mapaccess1 تمامًا، مع إضافة قيمة إرجاع منطقية فقط للإشارة إلى وجود العنصر.
الاجتياز
صيغة اجتياز الخريطة:
for key, val := range dict {
// do somthing...
}عند الاجتياز الفعلي، تستخدم Go بنية hiter لتخزين معلومات الاجتياز. hiter هو اختصار لـ hmap iterator، ويعني مكرر جدول التجزئة، وبنيته كما يلي:
// A hash iteration structure.
// If you modify hiter, also change cmd/compile/internal/reflectdata/reflect.go
// and reflect/value.go to match the layout of this structure.
type hiter struct {
key unsafe.Pointer // Must be in first position. Write nil to indicate iteration end (see cmd/compile/internal/walk/range.go).
elem unsafe.Pointer // Must be in second position (see cmd/compile/internal/walk/range.go).
t *maptype
h *hmap
buckets unsafe.Pointer // bucket ptr at hash_iter initialization time
bptr *bmap // current bucket
overflow *[]*bmap // keeps overflow buckets of hmap.buckets alive
oldoverflow *[]*bmap // keeps overflow buckets of hmap.oldbuckets alive
startBucket uintptr // bucket iteration started at
offset uint8 // intra-bucket offset to start from during iteration (should be big enough to hold bucketCnt-1)
wrapped bool // already wrapped around from end of bucket array to beginning
B uint8
i uint8
bucket uintptr
checkBucket uintptr
}بعض التفسيرات البسيطة لبعض الحقول:
key،elemهما المفتاح والقيمة التي يتم الحصول عليها عند الاجتياز بـfor rangebuckets، يُحدد عند تهيئة المكرر، يشير إلى رأس دلاء التجزئةbptr، الـ bmap الحالي الجاري اجتيازهstartBucket، رقم الدلو الذي بدأ منه الاجتيازoffset، الإزاحة داخل الدلو، المدى[0, bucketCnt-1]B، هي قيمة B في hmapi، فهرس العنصر داخل الدلوwrapped، ما إذا كان قد عاد من نهاية مصفوفة الدلاء إلى البداية
قبل بدء الاجتياز، تقوم Go بتهيئة المكرر من خلال دالة runtime.mapiterinit، ثم تجتاز الخريطة من خلال دالة runtime.mapinternext. كلا الدالتين تستخدمان بنية hiter، وتوقيع الدالتين:
func mapiterinit(t *maptype, h *hmap, it *hiter)
func mapiternext(it *hiter)بالنسبة لتهيئة المكرر، أولاً يجب الحصول على لقطة حالية للخريطة:
it.t = t
it.h = h
// تسجيل لقطة الحالة الحالية لـ hmap، فقط قيمة B
it.B = h.B
it.buckets = h.buckets
if t.Bucket.PtrBytes == 0 {
h.createOverflow()
it.overflow = h.extra.overflow
it.oldoverflow = h.extra.oldoverflow
}لاحقًا عند التكرار، يتم فعليًا اجتياز لقطة من الخريطة وليس الخريطة الفعلية، لذا العناصر والدلاء المضافة أثناء الاجتياز لن يتم اجتيازها. كما أن الاجتياز والكتابة المتزامنة قد يثيرا fatal.
if h.flags&hashWriting != 0 {
fatal("concurrent map iteration and map write")
}الخطوة الثانية تحديد موقعي البدء للاجتياز، الأول موقع الدلو البادئ، والثاني موقع البدء داخل الدلو، وكلاهما يُختار عشوائيًا:
// r هو رقم عشوائي
var r uintptr
if h.B > 31-bucketCntBits {
r = uintptr(fastrand64())
} else {
r = uintptr(fastrand())
}
// r % (1 << B) للحصول على موقع الدلو البادئ
it.startBucket = r & bucketMask(h.B)
// r >> B % 8 للحصول على موقع البدء داخل الدلو
it.offset = uint8(r >> h.B & (bucketCnt - 1))
// تسجيل رقم الدلو الحالي الجاري اجتيازه
it.bucket = it.startBucketمن خلال fastrand() أو fastrand64() يتم الحصول على رقم عشوائي، ثم عمليتا باقِ للحصول على موقع الدلو البادئ وموقع البدء داخل الدلو.
TIP
الخريطة لا تسمح بالقراءة والكتابة المتزامنة، لكنها تسمح بالاجتياز المتزامن.
الآن يبدأ اجتياز الخريطة فعليًا. كيفية اجتياز الدلاء واستراتيجية الخروج:
// hmap
h := it.h
// maptype
t := it.t
// موقع الدلو المراد اجتيازه
bucket := it.bucket
// bmap المراد اجتيازه
b := it.bptr
// الفهرس داخل الدلو i
i := it.i
next:
if b == nil {
// إذا كان موقع الدلو الحالي يساوي موقع البدء، فهذا يعني أنه دار دور كامل وعاد، وتم اجتياز ما يلي
// انتهى الاجتياز، يمكن الخروج
if bucket == it.startBucket && it.wrapped {
it.key = nil
it.elem = nil
return
}
// تحريك فهرس الدلو للأمام
bucket++
// bucket == 1 << B، يعني الوصول لنهاية مصفوفة دلاء التجزئة
if bucket == bucketShift(it.B) {
// البدء من البداية
bucket = 0
it.wrapped = true
}
i = 0
}يُختار موقع الدلو البادئ عشوائيًا. عند الاجتياز، يتم التكرار من موقع البدء نحو نهاية شريحة الدلاء، وعند الوصول إلى 1 << B، يُعاد البدء من البداية. عند العودة لموقع البدء مرة أخرى، يكون الاجتياز قد انتهى. الكود أعلاه يتعلق بكيفية اجتياز الدلاء في الخريطة، والكود التالي يصف كيفية الاجتياز داخل الدلو.
for ; i < bucketCnt; i++ {
// (i + offset) % 8
offi := (i + it.offset) & (bucketCnt - 1)
// إذا كان العنصر الحالي فارغًا تخطاه
if isEmpty(b.tophash[offi]) || b.tophash[offi] == evacuatedEmpty {
continue
}
// تحريك المؤشر للحصول على المفتاح
k := add(unsafe.Pointer(b), dataOffset+uintptr(offi)*uintptr(t.KeySize))
if t.IndirectKey() {
k = *((*unsafe.Pointer)(k))
}
// تحريك المؤشر للحصول على القيمة
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+uintptr(offi)*uintptr(t.ValueSize))
// معالجة حالة التوسع بنفس الحجم، عندما يتم نقل المفتاح والقيمة لمواقع أخرى، يجب إعادة البحث عنهما
if (b.tophash[offi] != evacuatedX && b.tophash[offi] != evacuatedY) ||
!(t.ReflexiveKey() || t.Key.Equal(k, k)) {
it.key = k
if t.IndirectElem() {
e = *((*unsafe.Pointer)(e))
}
it.elem = e
} else {
rk, re := mapaccessK(t, h, k)
if rk == nil {
continue
}
it.key = rk
it.elem = re
}
it.bucket = bucket
it.i = i + 1
return
}
// إذا لم يُعثر عليه، ابحث في دلو الفيضان
b = b.overflow(t)
i = 0
goto nextTIP
في شرط حكم التوسع أعلاه، هناك تعبير قد يسبب الحيرة:
t.Key.Equal(k, k)سبب الحكم على ما إذا كان k يساوي نفسه هو لتصفية حالة المفتاح NaN. إذا كان مفتاح عنصر هو NaN، فلن يمكن الوصول لهذا العنصر بشكل طبيعي، سواء بالاجتياز أو الوصول المباشر أو الحذف، لأن NaN != NaN دائمًا صحيح، ولن يمكن أبدًا العثور على هذا المفتاح.
أولاً بناءً على قيمة i و offset وعملي الباقِ للحصول على الفهرس داخل الدلو، ثم تحريك المؤشر للحصول على المفتاح والقيمة. نظرًا لأنه أثناء اجتياز الخريطة، قد تثير عمليات الكتابة الأخرى توسعًا للخريطة، فقد لا يكون المفتاح والقيمة الفعليان في موضعهما الأصلي. في هذه الحالة، يجب استخدام دالة mapaccessK لإعادة الحصول على المفتاح والقيمة الفعليين. توقيع الدالة:
func mapaccessK(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, unsafe.Pointer)وظيفتها مطابقة تمامًا لدالة mapaccess1، والفرق أن mapaccessK تُرجع قيمتي المفتاح والقيمة معًا. بعد الحصول على المفتاح والقيمة، تُسندان لمكرر key و elem، ثم يُحدَّث فهرس المكرر، وهكذا تكتمل تكرار واحدة، ويعود تنفيذ الكود إلى كتلة for range. إذا لم يُعثر عليه داخل الدلو، يُبحث في دلو الفيضان، وتُكرر نفس الخطوات حتى تنتهي من اجتياز القائمة المرتبطة لدلاء الفيضان، ثم يستمر اجتياز دلو التجزئة التالي.
التعديل
صيغة تعديل الخريطة:
dict[key] = valفي Go، عملية تعديل الخريطة تتم بواسطة دالة runtime.mapassign، وتوقيع الدالة:
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointerمنطق عملية الوصول مشابه لـ mapaccess1، لكن عندما لا يكون المفتاح موجودًا يُخصص له موقع، وإذا كان موجودًا يُحدَّث، وأخيرًا يُرجع مؤشر العنصر. في البداية، يجب القيام ببعض التحضيرات:
// لا يُسمح بالكتابة في خريطة nil
if h == nil {
panic(plainError("assignment to entry in nil map"))
}
// منع الكتابة المتزامنة
if h.flags&hashWriting != 0 {
fatal("concurrent map writes")
}
// حساب قيمة تجزئة المفتاح
hash := t.Hasher(key, uintptr(h.hash0))
// تعديل حالة hmap
h.flags ^= hashWriting
// تهيئة دلاء التجزئة
if h.buckets == nil {
h.buckets = newobject(t.Bucket) // newarray(t.Bucket, 1)
}الكود أعلاه يقوم بعدة أمور:
- فحص حالة hmap
- حساب قيمة تجزئة المفتاح
- فحص ما إذا كانت دلاء التجزئة تحتاج للتهيئة
بعد ذلك من خلال قيمة التجزئة وعملي الباقِ للحصول على موقع دلو التجزئة و tophash للمفتاح:
again:
// hash % (1 << B)
bucket := hash & bucketMask(h.B)
// تحريك المؤشر للحصول على bmap في الموقع المحدد
b := (*bmap)(add(h.buckets, bucket*uintptr(t.BucketSize)))
// حساب tophash
top := tophash(hash)الآن تم تحديد موقع الدلو و bmap و tophash، يمكن البدء في البحث عن العنصر:
// tophash للإدراج
var inserti *uint8
// مؤشر قيمة المفتاح للإدراج
var insertk unsafe.Pointer
// مؤشر قيمة القيمة للإدراج
var elem unsafe.Pointer
bucketloop:
for {
// اجتياز مصفوفة tophash داخل الدلو
for i := uintptr(0); i < bucketCnt; i++ {
// عدم تساوي tophash
if b.tophash[i] != top {
// إذا كان الفهرس داخل الدلو الحالي فارغًا ولم يُدرج عنصر بعد، اختر هذا الموقع للإدراج
if isEmpty(b.tophash[i]) && inserti == nil {
// عثر على موقع مناسب لتخصيصه للمفتاح
inserti = &b.tophash[i]
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
}
// انتهى الاجتياع، اخرج من الحلقة
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
// إذا تساوى tophash، فهذا يعني أن المفتاح قد يكون موجودًا بالفعل
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
if t.IndirectKey() {
k = *((*unsafe.Pointer)(k))
}
// الحكم على ما إذا كان المفتاحان متساويين
if !t.Key.Equal(key, k) {
continue
}
// إذا كان يحتاج لتحديث قيمة المفتاح، انسخ ذاكرة المفتاح مباشرة إلى موقع k
if t.NeedKeyUpdate() {
typedmemmove(t.Key, k, key)
}
// تم الحصول على مؤشر العنصر
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
// تم التحديث، أرجع مؤشر العنصر
goto done
}
// الوصول هنا يعني عدم العثور على المفتاح، اجتياز القائمة المرتبطة لدلاء الفيضان، واستمرار البحث
ovf := b.overflow(t)
if ovf == nil {
break
}
b = ovf
}
// الوصول هنا يعني أن المفتاح غير موجود في الخريطة، لكن قد يكون عُثر على موقع مناسب لتخصيصه، أو لا
// لم يُعثر على موقع مناسب لتخصيصه للمفتاح
if inserti == nil {
// هذا يعني أن دلو التجزئة الحالي ودلاء فيضانه ممتلئة، لذا خصص دلو فيضان جديد
newb := h.newoverflow(t, b)
// خصص موقعًا في دلو الفيضان للمفتاح
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
elem = add(insertk, bucketCnt*uintptr(t.KeySize))
}
// إذا كان يخزن مؤشر مفتاح
if t.IndirectKey() {
// تخصيص ذاكرة جديدة، يُرجع مؤشر unsafe
kmem := newobject(t.Key)
*(*unsafe.Pointer)(insertk) = kmem
// إسناده لـ insertk لتسهيل نسخ ذاكرة المفتاح لاحقًا
insertk = kmem
}
// إذا كان يخزن مؤشر عنصر
if t.IndirectElem() {
// تخصيص ذاكرة
vmem := newobject(t.Elem)
// جعل المؤشر يشير إلى vmem
*(*unsafe.Pointer)(elem) = vmem
}
// نسخ ذاكرة المفتاح مباشرة إلى موقع insertk
typedmemmove(t.Key, insertk, key)
*inserti = top
// زيادة العدد بمقدار واحد
h.count++
done:
// الوصول هنا يعني اكتمال عملية التعديل
if h.flags&hashWriting == 0 {
fatal("concurrent map writes")
}
h.flags &^= hashWriting
if t.IndirectElem() {
elem = *((*unsafe.Pointer)(elem))
}
// إرجاع مؤشر العنصر
return elemفي الكود الطويل أعلاه، أولاً تدخل حلقة for لمحاولة البحث في دلو التجزئة ودلاء الفيضان. منطق البحث مطابق تمامًا لـ mapaccess. في هذه اللحظة هناك ثلاث احتمالات:
- الأولى، عُثر على مفتاح موجود بالفعل في الخريطة، انتقل مباشرة لكتلة الكود
done، وأرجع مؤشر العنصر - الثانية، عُثر على موقع في الخريطة لتخصيصه للمفتاح، انسخ المفتاح للموقع المحدد، وأرجع مؤشر العنصر
- الثالثة، تم البحث في جميع الدلاء ولم يُعثر على موقع يمكن تخصيصه للمفتاح في الخريطة، أنشئ دلو فيضان جديد، وخصص المفتاح في الدلو، ثم انسخ المفتاح للموقع المحدد، وأرجع مؤشر العنصر
بعد الحصول على مؤشر العنصر، يمكن الإسناد، لكن هذه العملية لا تتم بواسطة دالة mapassign، هي مسؤولة فقط عن إرجاع مؤشر العنصر، وعملية الإسناد تُدرج في وقت الترجمة. الكود غير مرئي في المصدر، لكن يمكن رؤيته في الكود المترجم. لنفترض الكود التالي:
func main() {
dict := make(map[string]string, 100)
dict["hello"] = "world"
}من خلال الأمر التالي للحصول على كود التجميع:
go tool compile -S -N -l main.goالنقطة المهمة في هذا الجزء:
0x004e 00078 LEAQ type:map[string]string(SB), AX
0x0055 00085 CALL runtime.mapassign_faststr(SB)
0x005a 00090 MOVQ AX, main..autotmp_2+40(SP)
0x0083 00131 LEAQ go:string."world"(SB), CX
0x008a 00138 MOVQ CX, (AX)يمكن ملاحظة استدعاء runtime.mapassign_faststr، ومنطقها مشابه جدًا لـ mapassign. LEAQ go:string."world"(SB), CX تخزن عنوان السلسلة في CX، و MOVQ CX, (AX) تخزنه في AX، وبذلك تكتمل عملية إسناد العنصر.
الحذف
في Go، لحذف عنصر من الخريطة، يمكن فقط استخدام الدالة المدمجة delete:
delete(dict, "abc")داخليًا تستدعي runtime.mapdelete، وتوقيع الدالة:
func mapdelete(t *maptype, h *hmap, key unsafe.Pointer)تحذف عنصر المفتاح المحدد من الخريطة. سواء كان العنصر موجودًا في الخريطة أم لا، لن يكون هناك أي رد فعل. منطق التحضير في بداية الدالة مشابه، وهو عدة أمور:
- فحص حالة hmap
- حساب قيمة تجزئة المفتاح
- تحديد موقع دلو التجزئة
- حساب tophash
بما أن هناك الكثير من المحتوى المكرر، لن نكرره. هنا نهتم فقط بمنطق الحذف:
bOrig := b
search:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
// لم يُعثر عليه، اخرج من الحلقة
if b.tophash[i] == emptyRest {
break search
}
continue
}
// تحريك المؤشر للعثور على موقع المفتاح
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
k2 := k
if t.IndirectKey() {
k2 = *((*unsafe.Pointer)(k2))
}
if !t.Key.Equal(key, k2) {
continue
}
// حذف المفتاح
if t.IndirectKey() {
*(*unsafe.Pointer)(k) = nil
} else if t.Key.PtrBytes != 0 {
memclrHasPointers(k, t.Key.Size_)
}
// تحريك المؤشر للعثور على موقع العنصر
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
// حذف العنصر
if t.IndirectElem() {
*(*unsafe.Pointer)(e) = nil
} else if t.Elem.PtrBytes != 0 {
memclrHasPointers(e, t.Elem.Size_)
} else {
memclrNoHeapPointers(e, t.Elem.Size_)
}
notLast:
// إنقاص العدد بمقدار واحد
h.count--
// إعادة تعيين بذرة التجزئة، تقليل احتمال التعارض
if h.count == 0 {
h.hash0 = fastrand()
}
break search
}
}من الكود أعلاه، منطق البحث مطابق تقريبًا للعمليات السابقة. يُعثر على العنصر، ثم يُحذف، ويُنقَص عدد hmap بمقدار واحد. عندما يصل العدد إلى 0، تُعاد تعيين بذرة التجزئة.
نقطة أخرى يجب الانتباه لها هي أنه بعد حذف العنصر، يجب تعديل حالة tophash للفهرس الحالي. الكود المقابل: عندما يكون i في نهاية الدلو، يُحكم بناءً على دلو الفيضان التالي لمعرفة ما إذا كان العنصر الحالي هو آخر عنصر متاح، وإلا يُنظر مباشرة في حالة العنصر المجاور. إذا لم يكن العنصر الحالي هو الأخير، تُضبط الحالة على emptyOne.
// تعليم tophash الحالي كفارغ
b.tophash[i] = emptyOne
// إذا كان في نهاية tophash
if i == bucketCnt-1 {
// دلو الفيضان ليس فارغًا، وفيه عناصر، هذا يعني أن العنصر الحالي ليس الأخير
if b.overflow(t) != nil && b.overflow(t).tophash[0] != emptyRest {
goto notLast
}
} else {
// العنصر المجاور ليس فارغًا
if b.tophash[i+1] != emptyRest {
goto notLast
}
}إذا كان العنصر فعلاً هو الأخير، يجب تصحيح قيم مصفوفة tophash لبعض دلاء القائمة المرتبطة، وإلا سيؤدي ذلك إلى عدم القدرة على الخروج في الموضع الصحيح عند الاجتياع اللاحق.
المسح
في نسخة go1.21، أُضيفت الدالة المدمجة clear، التي يمكن استخدامها لمسح جميع عناصر الخريطة:
clear(dict)داخليًا تستدعي runtime.mapclear، وهي مسؤولة عن حذف جميع عناصر الخريطة، وتوقيع الدالة:
func mapclear(t *maptype, h *hmap)منطق هذه الدالة ليس معقدًا. أولاً يجب تعليم الخريطة بأكملها كفارغة:
// اجتياع كل دلو ودلاء الفيضان، وجعل جميع عناصر tophash تساوي emptyRest
markBucketsEmpty := func(bucket unsafe.Pointer, mask uintptr) {
for i := uintptr(0); i <= mask; i++ {
b := (*bmap)(add(bucket, i*uintptr(t.BucketSize)))
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
b.tophash[i] = emptyRest
}
}
}
}
markBucketsEmpty(h.buckets, bucketMask(h.B))ما يفعله الكود أعلاه هو اجتياع كل دلو، وجعل جميع عناصر مصفوفة tophash تساوي emptyRest، وتعليم الخريطة كفارغة، مما يمنع المكرر من الاستمرار في التكرار، ثم مسح الخريطة:
// إعادة تعيين بذرة التجزئة
h.hash0 = fastrand()
// إعادة تعيين البنية extra
if h.extra != nil {
*h.extra = mapextra{}
}
// هذه العملية تمسح ذاكرة buckets الأصلية، وتخصص دلاء جديدة
_, nextOverflow := makeBucketArray(t, h.B, h.buckets)
if nextOverflow != nil {
// تخصيص دلاء فيضان فارغة جديدة
h.extra.nextOverflow = nextOverflow
}من خلال makeBucketArray تُمسح ذاكرة الدلاء السابقة، ثم يُخصص دلو جديد. بهذا تكتمل عملية مسح الدلاء. هناك أيضًا بعض التفاصيل مثل ضبط count على 0 وغيرها.
التوسع
في جميع العمليات السابقة، للتركيز على المنطق نفسه، تم حجب الكثير من المحتوى المتعلق بالتوسع. منطق التوسع معقد نسبيًا، لذا تُرك للنهاية. الآن لنرَ كيف تقوم Go بتوسيع الخريطة. كما ذُكر سابقًا، هناك شرطان يثيران التوسع:
- عامل الحمل يتجاوز 6.5
- عدد دلاء الفيضان كبير جدًا
دالة الحكم على ما إذا كان عامل الحمل يتجاوز العتبة هي runtime.overLoadFactor، وقد شُرحت في جزء تعارض التجزئة. أما دالة الحكم على ما إذا كان عدد دلاء الفيضان كبيرًا جدًا فهي runtime.tooManyOverflowBuckets، ومبدأ عملها بسيط:
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {
if B > 15 {
B = 15
}
return noverflow >= uint16(1)<<(B&15)
}يمكن تبسيط الكود أعلاه للتعبير التالي:
overflow >= 1 << (min(15,B) % 16)هنا، تعريف Go لـ "too many" هو: عدد دلاء الفيضان يقارب عدد دلاء التجزئة.
التوسع التدريجي
عندما يكون عامل الحمل كبيرًا جدًا، أي أن عدد العناصر أكبر بكثير من عدد دلاء التجزئة، وعندما تكون تعارضات التجزئة حادة، ستتشكل العديد من القوائم المرتبطة لدلاء الفيضان، مما يؤدي لانخفاض أداء القراءة والكتابة للخريطة، لأن البحث عن عنصر يتطلب اجتياع المزيد من القوائم المرتبطة. تعقيد الوقت للاجتياع هو O(n). تعقيد الوقت للبحث في جدول التجزئة يعتمد بشكل أساسي على وقت حساب التجزئة ووقت الاجتياع. عندما يكون وقت الاجتياع أقل بكثير من وقت حساب التجزئة، يمكن القول أن تعقيد وقت البحث هو O(1). إذا كانت تعارضات التجزئة متكررة، وكثير من المفاتيح تُخصص لنفس دلو التجزئة، وطول القائمة المرتبطة لدلو الفيضان طويل، سيزداد وقت الاجتياع، مما يزيد وقت البحث. وعمليات الإضافة والحذف والتعديل تتطلب أولاً عملية بحث، مما يؤدي لانخفاض أداء الخريطة بالكامل.
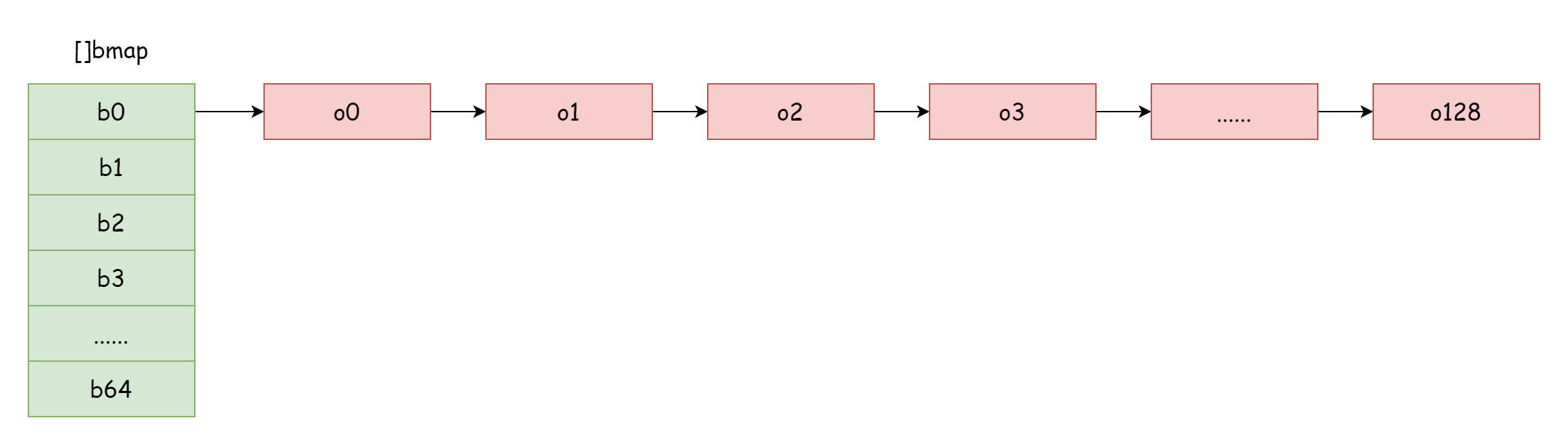
في حالة شديدة مثل الصورة، تعقيد وقت البحث لا يختلف كثيرًا عن O(n). الحل لهذه الحالة هو إضافة المزيد من دلاء التجزئة لتجنب تشكيل قوائم طويلة لدلاء الفيضان، وهذه الطريقة تسمى التوسع التدريجي.
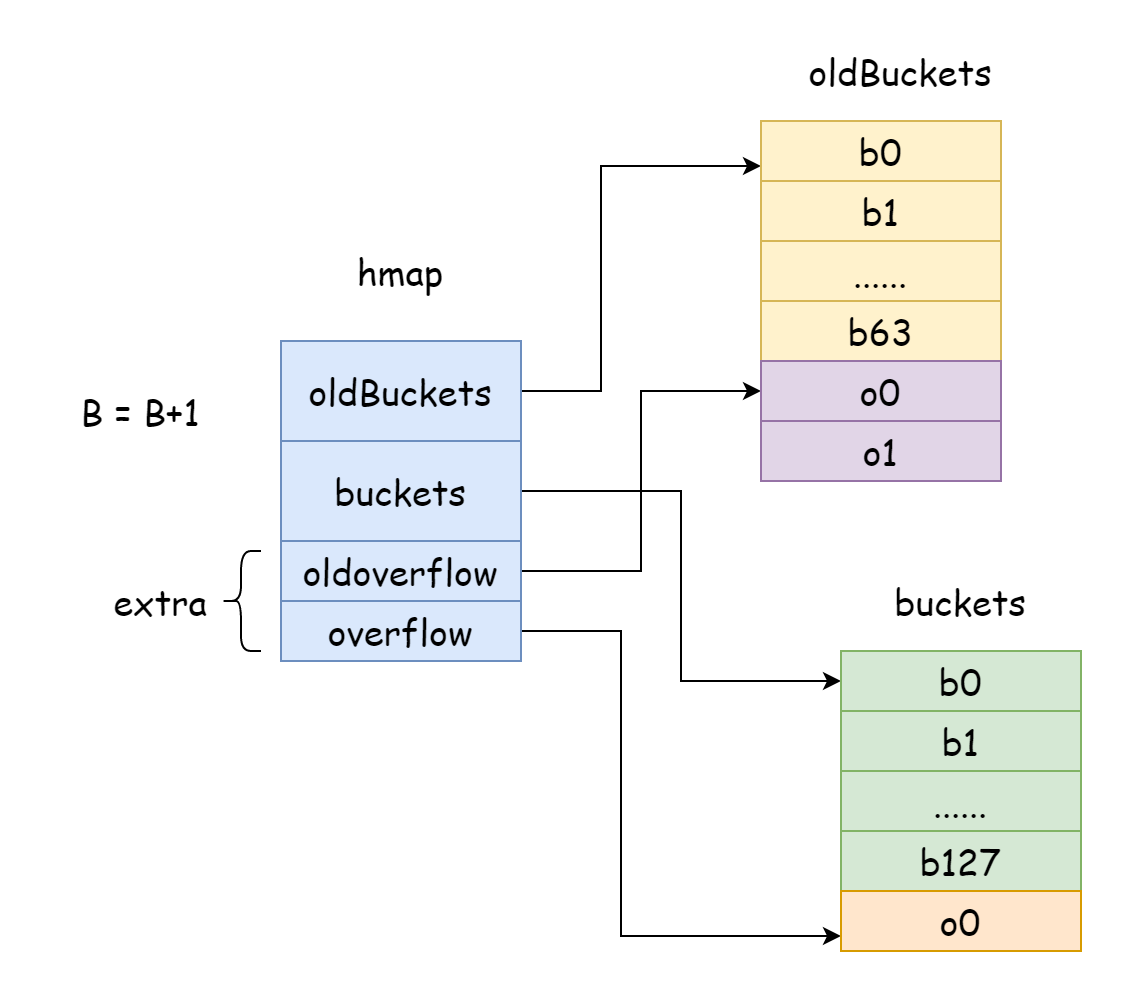
في Go، التوسع التدريجي يزيد B بمقدار واحد في كل مرة، أي أن حجم دلاء التجزئة يتضاعف في كل مرة. بعد التوسع، يجب نقل البيانات القديمة للخريطة الجديدة. إذا كان عدد العناصر في الخريطة بالملايين أو حتى مليارات، سيستغرق نقلها جميعًا دفعة واحدة وقتًا طويلاً، لذا تستخدم Go استراتيجية نقل تدريجي. لهذا، ستشير oldBuckets في hmap إلى مصفوفة دلاء التجزئة الأصلية، للدلالة على أنها بيانات قديمة، ثم تُنشأ مصفوفة دلاء تجزئة بسعة أكبر، ويُشار إليها بـ buckets في hmap. ثم في كل عملية تعديل أو حذف، تُنقل بعض العناصر من الدلاء القديمة للجديدة، حتى يكتمل النقل، عندها تُحرر ذاكرة الدلاء القديمة.
func hashGrow(t *maptype, h *hmap) {
// الفرق
bigger := uint8(1)
// الدلاء القديمة
oldbuckets := h.buckets
// دلاء التجزئة الجديدة
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
flags := h.flags &^ (iterator | oldIterator)
if h.flags&iterator != 0 {
flags |= oldIterator
}
// B+bigger
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
h.nevacuate = 0
h.noverflow = 0
// دلاء الفيضان أيضًا يجب تحديدها للدلاء القديمة والجديدة
if h.extra != nil && h.extra.overflow != nil {
if h.extra.oldoverflow != nil {
throw("oldoverflow is not nil")
}
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
}
if nextOverflow != nil {
if h.extra == nil {
h.extra = new(mapextra)
}
h.extra.nextOverflow = nextOverflow
}
}ما يفعله الكود أعلاه هو إنشاء دلاء تجزئة جديدة بسعة مضاعفة، ثم تحديد مراجع الدلاء القديمة والجديدة، وكذلك مراجع دلاء الفيضان القديمة والجديدة. عمل النقل الفعلي لا تتم بواسطة hashGrow، هي مسؤولة فقط عن تحديد الدلاء القديمة والجديدة وتحديث بعض حالة hmap. العمل الفعلي يتم بواسطة runtime.growWork:
func growWork(t *maptype, h *hmap, bucket uintptr)يُستدعى في mapassign و mapdelete بالشكل التالي، وظيفته إذا كانت الخريطة الحالية في حالة توسع، إجراء عملية نقل جزئي:
if h.growing() {
growWork(t, h, bucket)
}عند إجراء عمليات التعديل والحذف، يجب الحكم على ما إذا كانت الحالة الحالية في توسع، وهذا يتم أساسًا بواسطة طريقة hmap.growing:
func (h *hmap) growing() bool {
return h.oldbuckets != nil
}دالة growWork:
func growWork(t *maptype, h *hmap, bucket uintptr) {
// bucket % 1 << (B-1)
evacuate(t, h, bucket&h.oldbucketmask())
if h.growing() {
evacuate(t, h, h.nevacuate)
}
}حيث bucket&h.oldbucketmask() تحسب موقع الدلو القديم. من الدالة يتضح أن المسؤول الفعلي عن النقل هو runtime.evacuate، حيث تُستخدم بنية evaDst للإشارة لوجهة النقل، وظيفتها الرئيسية تكرار الدلاء الجديدة أثناء النقل:
type evacDst struct {
b *bmap // الدلو الجديد لوجهة النقل
i int // الفهرس داخل الدلو
k unsafe.Pointer // المؤشر لوجهة المفتاح الجديد
e unsafe.Pointer // المؤشر لوجهة القيمة الجديدة
}قبل بدء النقل، تخصص Go بنيتي evacDst، واحدة تشير للنصف العلوي من دلاء التجزئة الجديدة، والأخرى للنصف السفلي:
// تحديد موقع دلو التجزئة المحدد في الدلاء القديمة
b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.BucketSize)))
// طول الدلاء القديمة = 1 << (B - 1)
newbit := h.noldbuckets()
var xy [2]evacDst
x := &xy[0]
// الإشارة للنصف العلوي من الدلاء الجديدة
x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.BucketSize)))
x.k = add(unsafe.Pointer(x.b), dataOffset)
x.e = add(x.k, bucketCnt*uintptr(t.KeySize))
// الحكم على ما إذا كان توسعًا بنفس الحجم
if !h.sameSizeGrow() {
y := &xy[1]
// الإشارة للنصف السفلي من الدلاء الجديدة
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.BucketSize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.e = add(y.k, bucketCnt*uintptr(t.KeySize))
}وجهة نقل الدلاء القديمة هي دلاء جديدة، بعد النقل، بعض البيانات ستكون في النصف العلوي، وبعضها في النصف السفلي. هذا لتوزيع البيانات بشكل أكثر تجانسًا بعد التوسع، وكلما كان التوزيع أكثر تجانسًا، كان أداء البحث في الخريطة أفضل. كيف تنقل Go البيانات للدلاء الجديدة:
// اجتياع القائمة المرتبطة لدلاء الفيضان
for ; b != nil; b = b.overflow(t) {
// الحصول على أول زوج مفتاح-قيمة في كل دلو
k := add(unsafe.Pointer(b), dataOffset)
e := add(k, bucketCnt*uintptr(t.KeySize))
// اجتياع كل زوج مفتاح-قيمة في الدلو
for i := 0; i < bucketCnt; i, k, e = i+1, add(k, uintptr(t.KeySize)), add(e, uintptr(t.ValueSize)) {
top := b.tophash[i]
// إذا كان فارغًا تخطاه
if isEmpty(top) {
b.tophash[i] = evacuatedEmpty
continue
}
// دلاء التجزئة الجديدة لا يجب أن تكون في حالة نقل
// وإلا فبالتأكيد هناك مشكلة
if top < minTopHash {
throw("bad map state")
}
k2 := k
if t.IndirectKey() {
k2 = *((*unsafe.Pointer)(k2))
}
// هذا المتغير يحدد ما إذا كان زوج المفتاح-القيمة الحالي يُنقل للنصف العلوي أم السفلي
// قيمته يمكن أن تكون فقط 0 أو 1
var useY uint8
if !h.sameSizeGrow() {
// إعادة حساب قيمة التجزئة
hash := t.Hasher(k2, uintptr(h.hash0))
// معالجة الحالة الخاصة k2 != k2
if h.flags&iterator != 0 && !t.ReflexiveKey() && !t.Key.Equal(k2, k2) {
useY = top & 1
top = tophash(hash)
} else {
// hash % 1 << (B - 1)
if hash&newbit != 0 {
useY = 1
}
}
}
// فحص قيم الثوابت
if evacuatedX+1 != evacuatedY || evacuatedX^1 != evacuatedY {
throw("bad evacuatedN")
}
// تحديث tophash للدلو القديم، للإشارة بأن العنصر نُقل
b.tophash[i] = evacuatedX + useY // evacuatedX + 1 == evacuatedY
// تحديد وجهة النقل
dst := &xy[useY] // evacuation destination
// إذا لم تعد سعة الدلو الجديد كافية، أنشئ دلو فيضان
if dst.i == bucketCnt {
dst.b = h.newoverflow(t, dst.b)
dst.i = 0
dst.k = add(unsafe.Pointer(dst.b), dataOffset)
dst.e = add(dst.k, bucketCnt*uintptr(t.KeySize))
}
dst.b.tophash[dst.i&(bucketCnt-1)] = top
// نسخ المفتاح
if t.IndirectKey() {
*(*unsafe.Pointer)(dst.k) = k2 // copy pointer
} else {
typedmemmove(t.Key, dst.k, k) // copy elem
}
// نسخ القيمة
if t.IndirectElem() {
*(*unsafe.Pointer)(dst.e) = *(*unsafe.Pointer)(e)
} else {
typedmemmove(t.Elem, dst.e, e)
}
// تحريك مؤشر وجهة الدلو الجديد استعدادًا للمفتاح والقيمة التاليين
dst.i++
dst.k = add(dst.k, uintptr(t.KeySize))
dst.e = add(dst.e, uintptr(t.ValueSize))
}
}من الكود أعلاه، يتضح أن Go تجتاع كل دلو في القائمة المرتبطة للدلاء القديمة، وتنقل بياناتها للدلاء الجديدة. تحديد ما إذا كانت البيانات تذهب للنصف العلوي أم السفلي يعتمد على إعادة حساب قيمة التجزئة:
// hash % 1 << (B - 1)
if hash&newbit != 0 {
useY = 1
}بعد النقل، تُضبط قيمة tophash للعنصر الحالي على evacuatedX أو evacuatedY. إذا حُاول البحث عن بيانات أثناء التوسع، من خلال هذه الحالة يمكن معرفة أن البيانات نُقلت، ويجب البحث عنها في الدلاء الجديدة. هذا المنطق موجود في runtime.mapaccess1.
في growWork، تم استدعاء evacuate مرتين: الأولى لنقل الدلو القديم للدلو الذي يجري الوصول إليه حاليًا، والثانية لنقل الدلو القديم الذي يشير إليه h.nevacuate. إذن عند النقل التدريجي، يُنقل دلوان في كل مرة.
التوسع بنفس الحجم
ذكرنا سابقًا أن شرط إثارة التوسع بنفس الحجم هو كثرة دلاء الفيضان. إذا أضيفت للخريطة أولاً كمية كبيرة من العناصر، ثم حُذف منها كمية كبيرة، قد يكون الكثير من الدلاء فارغًا، وقد يكون بعض الدلاء يحتوي على الكثير من العناصر، وتوزيع البيانات غير متجانس، وعدد كبير من دلاء الفيضان فارغ، تشغل مساحة كبيرة من الذاكرة. لحل هذه المشكلات، يجب إنشاء خريطة جديدة بنفس السعة، وإعادة تخصيص دلاء التجزئة، وهذه العملية تسمى التوسع بنفس الحجم. لذا فهي ليست عملية توسع فعليًا، بل إعادة توزيع جميع العناصر لتوزيع البيانات بشكل أكثر تجانسًا. عملية التوسع بنفس الحجم مدمجة في عملية التوسع التدريجي، ومنطقها مطابق تمامًا للتوسع التدريجي، وسعة الخريطة القديمة والجديدة متساوية تمامًا.