map
Go が他の言語と異なるのは、マップ表のサポートが map キーワードによって提供されており、標準ライブラリにカプセル化されているわけではありません。マップ表は非常に多くの使用シーンがあるデータ構造で、底层には多くの実装方式があります。最も一般的な 2 つの方式は赤黒木とハッシュテーブルで、Go はハッシュテーブルの実装方式を採用しています。
TIP
map の実装には大量のポインタ移動操作が含まれているため、本文を読むには unsafe 標準ライブラリの知識が必要です。
内部構造
runtime.hmap 構造体は Go 内の map を表しており、スライスと同様に map の内部実装も構造体です。
// A header for a Go map.
type hmap struct {
// Note: the format of the hmap is also encoded in cmd/compile/internal/reflectdata/reflect.go.
// Make sure this stays in sync with the compiler's definition.
count int // # live cells == size of map. Must be first (used by len() builtin)
flags uint8
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields
}英語の注釈はすでに非常に明確に説明しています。以下では、より重要なフィールドについて簡単に説明します。
count:hmap 内の要素数を表し、結果はlen(map)と等しくなります。flags:hmap のフラグで、hmap がどのような状態にあるかを示します。以下の可能性があります。goconst ( iterator = 1 // イテレータがバケットを使用している oldIterator = 2 // イテレータが古いバケットを使用している hashWriting = 4 // 1 つのゴルーチンが hmap に書き込んでいる sameSizeGrow = 8 // 等量拡張中 )B:hmap 内のハッシュバケットの数は1 << Bです。noverflow:hmap 内のオーバーフローバケットのおおよその数。hash0:ハッシュシード。hmap が作成される際に指定され、ハッシュ値を計算するために使用されます。buckets:ハッシュバケット配列を格納するポインタ。oldbuckets:拡張前の hmap のハッシュバケット配列へのポインタ。extra:hmap 内のオーバーフローバケットを格納します。オーバーフローバケットとは、現在のバケットが満杯になった場合に要素を格納するために作成される新しいバケットのことです。
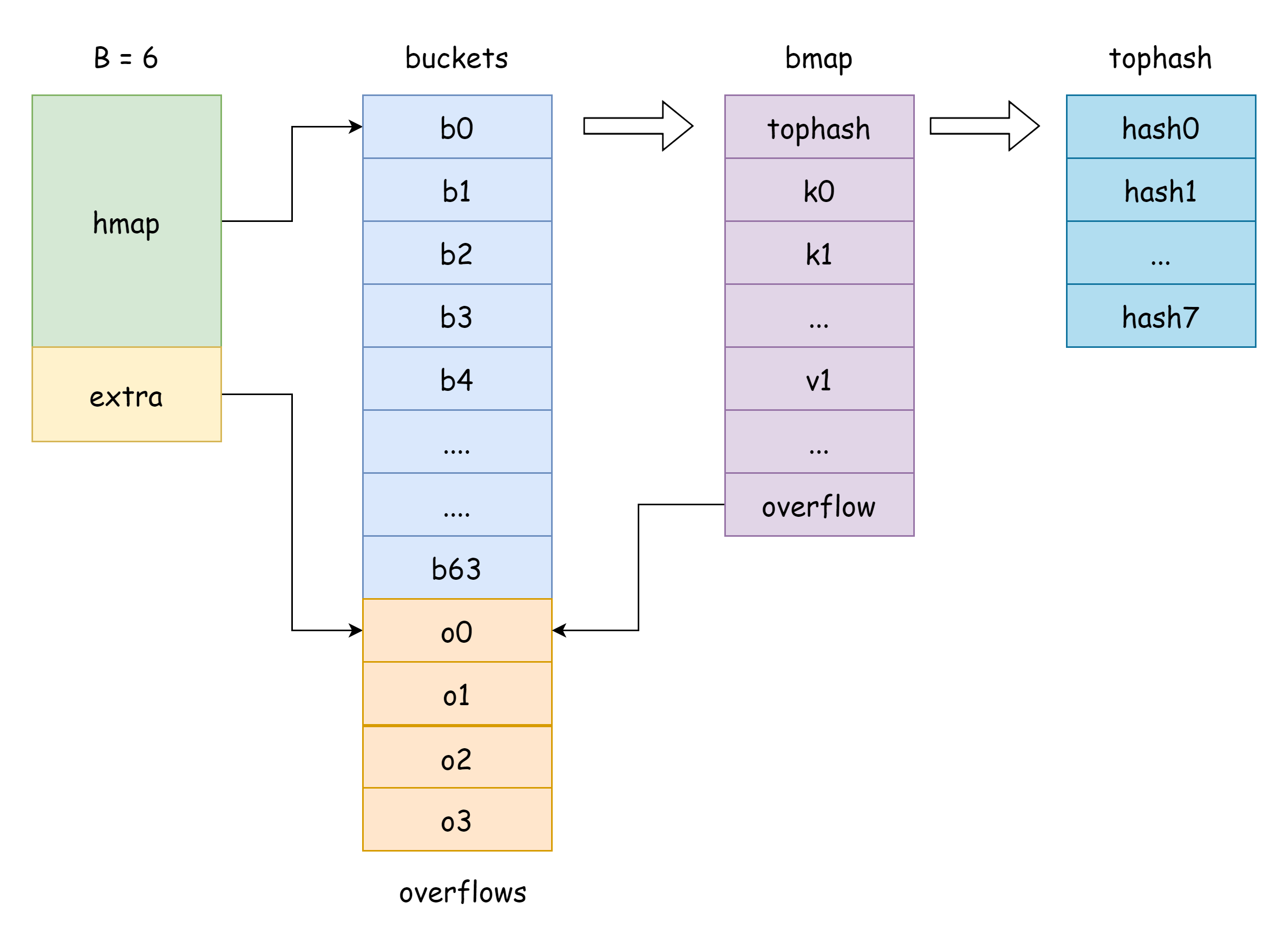
hmap 内の buckets はバケットスライスポインタで、Go に対応する構造体は runtime.bmap です。
// A bucket for a Go map.
type bmap struct {
tophash [bucketCnt]uint8
}上記から、tophash フィールドのみがあり、このフィールドは各キーの上位 8 ビットを格納するために使用されることがわかります。しかし実際には、bmap のフィールドはこれだけではありません。map はさまざまな型のキーバリューを格納できるため、コンパイル時に型に基づいて必要なメモリ空間を推論する必要があるからです。cmd/compile/internal/reflectdata/reflect.go の MapBucketType 関数はコンパイル時に bmap を構築する機能を持ち、一連のチェックを行います。例えば、キーの型が comparable かどうかなどです。
// MapBucketType makes the map bucket type given the type of the map.
func MapBucketType(t *types.Type) *types.Typeしたがって、実際には bmap の構造は以下のようになりますが、これらのフィールドは私たちには見えません。Go は実際に操作する際に unsafe ポインタを移動してアクセスします。
type bmap struct {
tophash [BUCKETSIZE]uint8
keys [BUCKETSIZE]keyType
elems [BUCKETSIZE]elemType
overflow *bucket
}いくつかの説明は以下の通りです。
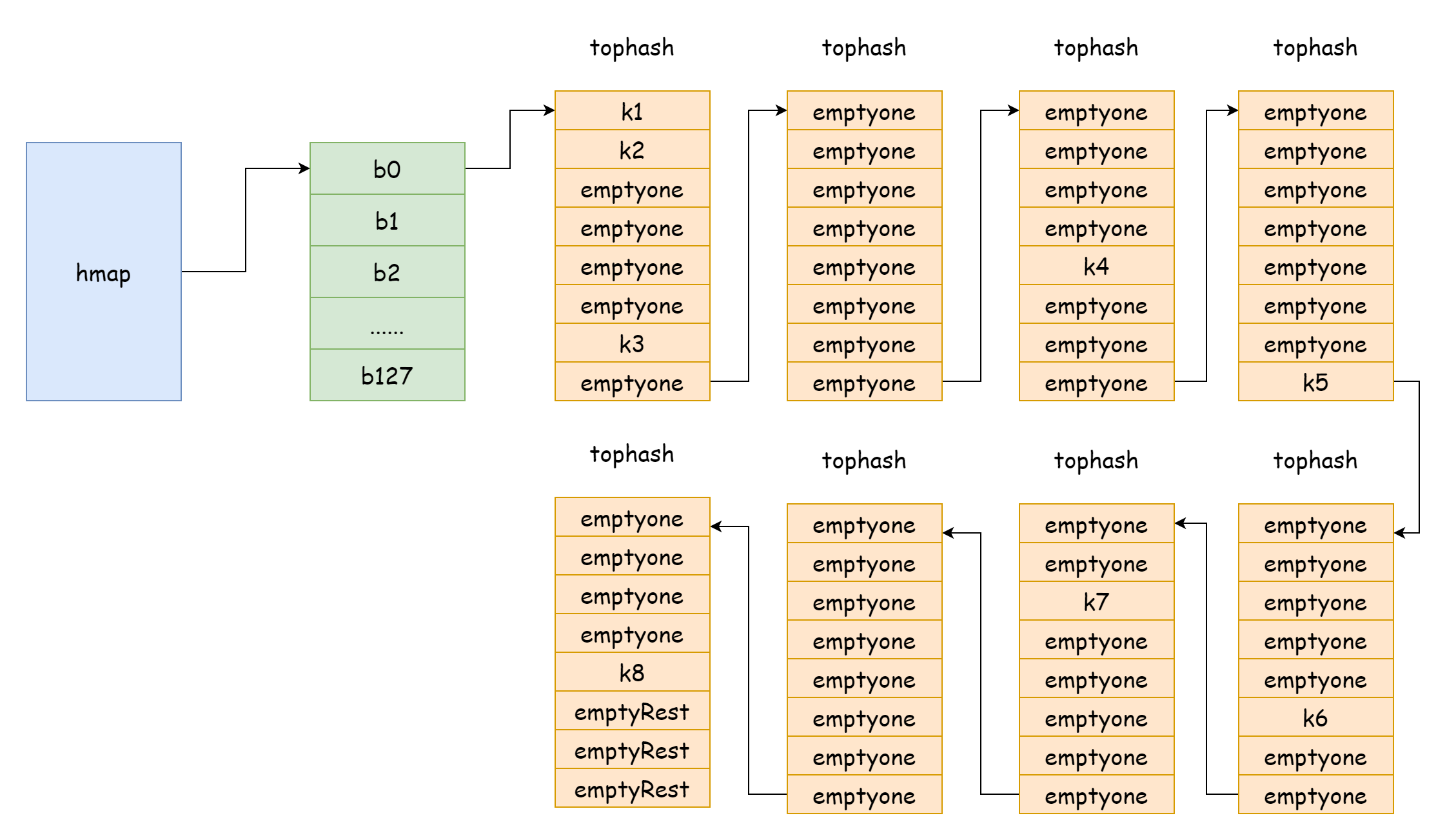
tophash:各キーの上位 8 ビット値を格納します。tophash の要素には以下の特殊な値があります。goconst ( emptyRest = 0 // 現在の要素は空で、この要素の後ろにも利用可能なキーバリューはない emptyOne = 1 // 現在の要素は空だが、この要素の後ろには利用可能なキーバリューがある evacuatedX = 2 // 拡張時に出現。oldbuckets にのみ出現可能。現在の要素が新しいハッシュバケット配列の上半分に移動されたことを示す evacuatedY = 3 // 拡張時に出現。oldbuckets にのみ出現可能。現在の要素が新しいハッシュバケット配列の下半分に移動されたことを示す evacuatedEmpty = 4 // 拡張時に出現。要素自体は空で、移動時にマークされた minTopHash = 5 // 通常のキーバリューに対する tophash の最小値 )tophash[i]の値がminTopHashより大きい場合、対応するインデックスに通常のキーバリューが存在することを示します。keys:指定された型のキーを格納する配列。elems:指定された型の値を格納する配列。overflow:オーバーフローバケットへのポインタ。
キーバリューが構造体フィールドから直接アクセスできないため、Go は事前に定数 dataoffset を宣言します。これは bmap 内のメモリオフセットを表します。
const dataOffset = unsafe.Offsetof(struct {
b bmap
v int64
}{}.v)実際には、キーバリューは連続したメモリアドレスに格納されており、以下のような構造になっています。これはメモリアラインメントによるスペースの浪費を避けるためです。
k1,k2,k3,k4,k5,k6...v1,v2,v3,v4,v5,v6...したがって、bmap 而言、ポインタを dataoffset 移動した後、i*sizeof(keyType) を移動すると、i 番目の key のアドレスになります。
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))i 番目の value のアドレスを取得するのも同様です。
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))hamp 内の buckets ポインタは、最初のハッシュバケットのアドレスを指しています。i 番目のハッシュバケットのアドレスを取得したい場合、オフセットは i*sizeof(bucket) になります。
b := (*bmap)(add(h.buckets, i*uintptr(t.BucketSize)))後続の内容では、これらの操作が非常に頻繁に現れます。
ハッシュ
衝突
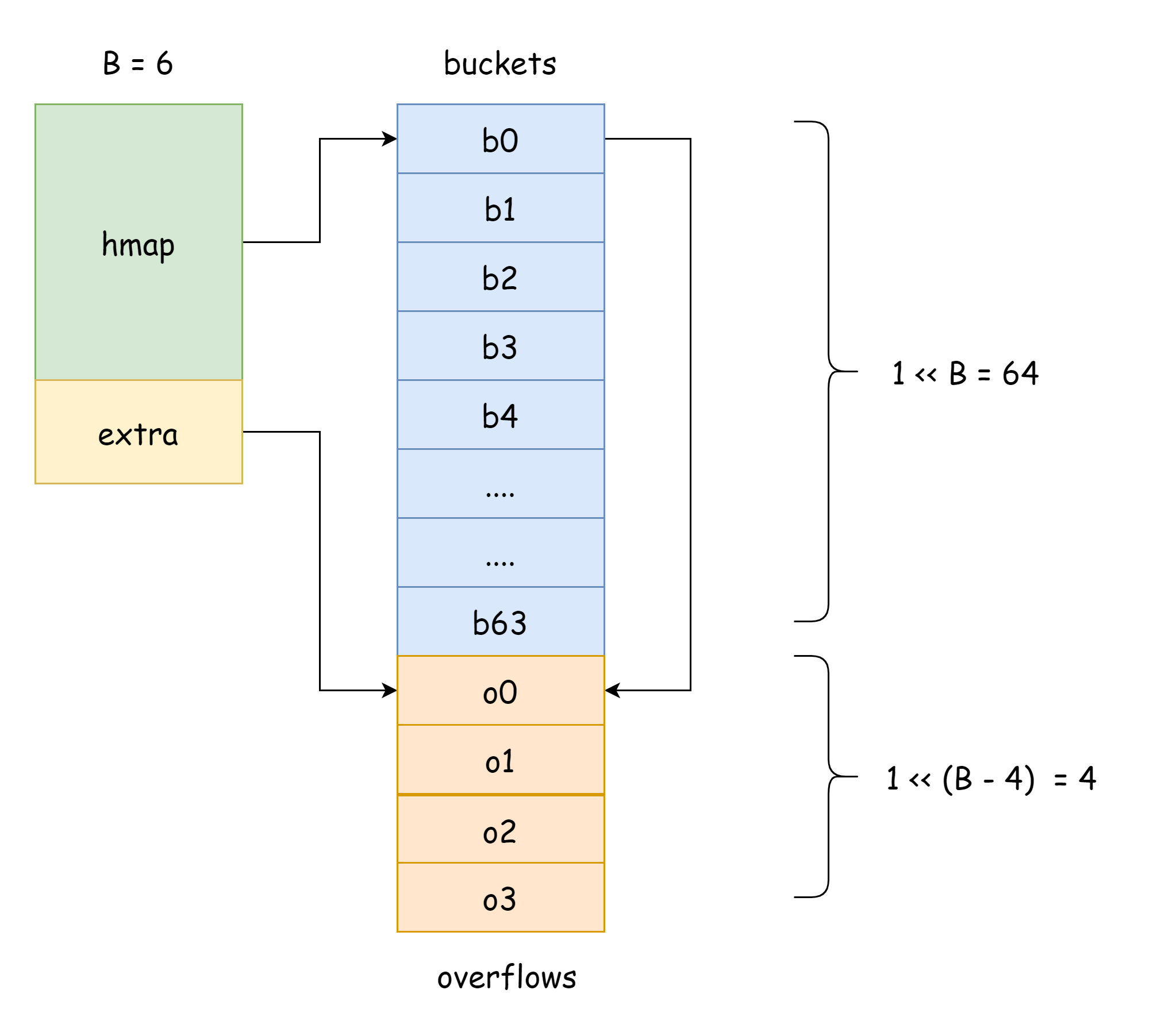
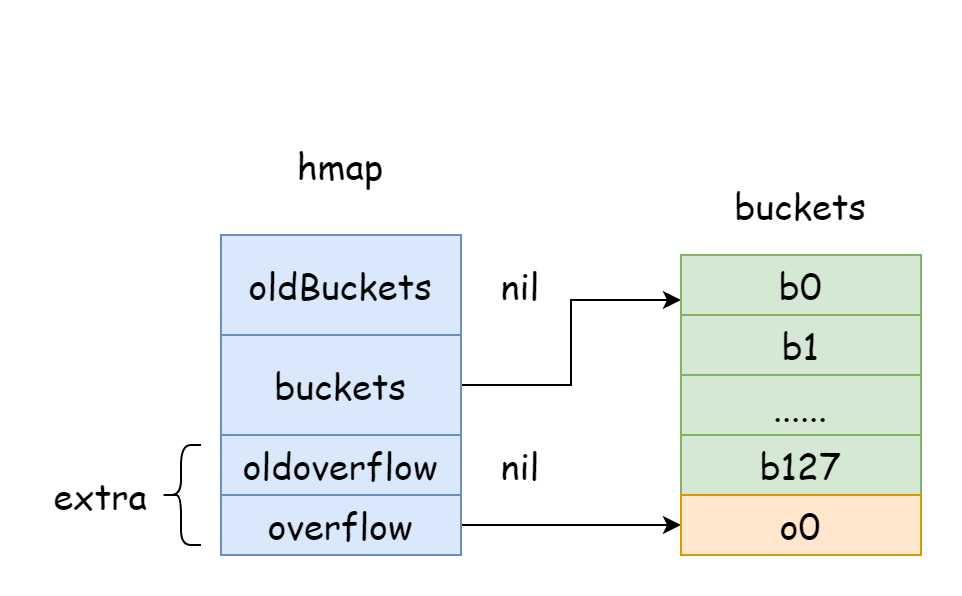
hmap には、オーバーフローバケットの情報を格納するために使用される extra フィールドがあります。これはオーバーフローバケットを格納するスライスを指します。その構造は以下の通りです。
type mapextra struct {
// オーバーフローバケットのポインタスライス
overflow *[]*bmap
// 拡張前の古いオーバーフローバケットのポインタスライス
oldoverflow *[]*bmap
// 次の空きオーバーフローバケットへのポインタ
nextOverflow *bmap
}
TIP
上図では、青色の部分はハッシュバケット配列、オレンジ色の部分はオーバーフローハッシュバケット配列です。オーバーフローハッシュバケットは以下ではオーバーフローバケットと総称します。
上図は hmap のおおよその構造を非常によく示しています。buckets はハッシュバケット配列を指し、extra はオーバーフローバケット配列を指します。バケット bucket0 はオーバーフローバケット overflow0 を指し、2 つの異なるバケットはそれぞれ 2 つのスライスに格納されており、2 つのバケットのメモリは連続しています。2 つのキーがハッシュ後に同じバケットに割り当てられた場合、これをハッシュ衝突と呼びます。Go がハッシュ衝突を解決する方法はチェーン法です。衝突するキーの数がバケットの容量(通常は 8 個)を超えると、internal/abi.MapBucketCount の値に依存します。その後、これらのキーを格納するために新しいバケットが作成されます。このバケットはオーバーフローバケットと呼ばれ、元のバケットに入りきらない要素がこの新しいバケットにオーバーフローするためです。作成完毕后、ハッシュバケットには新しいオーバーフローバケットを指すポインタがあり、これらのバケットのポインタを連結すると bmap リストが形成されます。
チェーン法而言、負荷因子を使用してハッシュテーブルの衝突状況を測定します。その計算式は以下の通りです。
loadfactor := len(elems) / len(buckets)負荷因子が大きいほど、ハッシュ衝突が多く、つまりオーバーフローバケットの数が多いことを示します。そのため、ハッシュテーブルの読み書き時に、指定の位置を見つけるためにより多くのオーバーフローバケットリストを走査する必要があります。パフォーマンスが低下します。この状況を改善するためには、buckets バケットの数を増やす必要があります。つまり拡張です。hmap 而言、2 つの状況で拡張がトリガーされます。
- 負荷因子が閾値
bucketCnt*13/16を超える。その値は少なくとも 6.5 です。 - オーバーフローバケットの数が多すぎる
負荷因子が小さいほど、hmap のメモリ利用率が低く、占有するメモリが大きくなります。Go で負荷因子を計算する関数は runtime.overLoadFactor です。
func overLoadFactor(count int, B uint8) bool {
return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)
}ここで loadFactorNum と loadFactorDen は定数で、bucketshift は 1 << B を計算します。既知です。
loadFactorNum = (bucketCnt * 13 / 16) * loadFactorDenしたがって、簡略化すると以下が得られます。
count > bucketCnt && uintptr(count) / 1 << B > (bucketCnt * 13 / 16)ここで (bucketCnt * 13 / 16) の値は 6.5 で、1 << B はハッシュバケットの数です。したがって、この関数の役割は、要素数をバケット数で割った値が負荷因子 6.5 より大きいかどうかを計算することです。
計算
Go 内部でハッシュを計算する関数は runtime/alg.go ファイル内の f32hash にあります。
func f32hash(p unsafe.Pointer, h uintptr) uintptr {
f := *(*float32)(p)
switch {
case f == 0:
return c1 * (c0 ^ h) // +0, -0
case f != f:
return c1 * (c0 ^ h ^ uintptr(fastrand())) // any kind of NaN
default:
return memhash(p, h, 4)
}
}map のハッシュ計算方法は型に基づくのではなく、メモリに基づいていることがわかります。最終的には memhash 関数に到達します。この関数はアセンブリで実装されており、ロジックは runtime/asm*.s にあります。メモリに基づくハッシュ値は永続的に保存されるべきではありません。実行時にのみ使用されるべきで、毎回実行時のメモリ分布が完全に一致することを保証することはできないからです。
このファイルには typehash という関数もあり、この関数はさまざまな型に基づいてハッシュ値を計算しますが、map はこの関数を使用してハッシュを計算しません。
func typehash(t *_type, p unsafe.Pointer, h uintptr) uintptrこの実装は上記のものよりも遅いですが、より汎用的です。主にリフレクションおよびコンパイル時の関数生成に使用されます。
//go:linkname reflect_typehash reflect.typehash
func reflect_typehash(t *_type, p unsafe.Pointer, h uintptr) uintptr {
return typehash(t, p, h)
}作成
map の初期化には 2 つの方法があります。これは言語入門で既に説明済みです。1 つは map キーワードを使用して直接作成する方法で、もう 1 つは make 関数を使用する方法です。どちらの初期化方法を使用しても、最終的には runtime.makemap によって map が作成されます。この関数のシグネチャは以下の通りです。
func makemap(t *maptype, hint int, h *hmap) *hmapパラメータは以下の通りです。
t:map の型を指します。異なる型は必要なメモリ占有が異なります。hint:make関数の 2 番目のパラメータで、map の予想要素容量です。h:hmapのポインタで、nilであり得ます。
戻り値は初期化完毕の hmap ポインタです。この関数は初期化プロセス中にいくつかの主要な作業を行います。まず、予想される割り当てメモリが最大割り当てメモリを超えるかどうかを計算します。
// 予想容量とバケット型のメモリサイズを乗算
mem, overflow := math.MulUintptr(uintptr(hint), t.Bucket.Size_)
// 数値がオーバーフローまたは最大割り当てメモリを超えた
if overflow || mem > maxAlloc {
hint = 0
}以前の内部構造で既に言及したように、hmap は内部でバケットで構成されています。メモリ利用率が最低の場合、1 つのバケットに 1 つの要素しかなく、メモリが最も多く占有されます。したがって、予想される最大メモリ占有は要素数に型ごとのメモリ占有サイズを掛けたものです。計算結果の数値がオーバーフローした場合、または割り当て可能な最大メモリを超えた場合、hint を 0 に設定します。後続で hint を使用してバケット配列の容量を計算する必要があるためです。
2 番目に hmap を初期化し、ランダムなハッシュシードを計算します。
// 初期化
if h == nil {
h = new(hmap)
}
// ランダムなハッシュシードを取得
h.hash0 = fastrand()その後、hint の値に基づいてハッシュバケットの容量を計算します。
B := uint8(0)
// hint / 1 << B < 6.5 になるまで繰り返し
for overLoadFactor(hint, B) {
B++
}
// hmap に代入
h.B = B(hint / 1 << B) < 6.5 を満たす最初の B 値を見つけるまで繰り返し、それを hmap に代入します。ハッシュバケットの容量がわかった後、最後にハッシュバケットにメモリを割り当てます。
if h.B != 0 {
var nextOverflow *bmap
// 割り当てられたハッシュバケットと事前に割り当てられた空きオーバーフローバケット
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
// 事前に空きオーバーフローバケットが割り当てられた場合、それを指す
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}makeBucketArray 関数は B の値に基づいてハッシュバケットに対応するサイズのメモリを割り当て、事前に空きオーバーフローバケットを割り当てます。B が 4 未満の場合、オーバーフローバケットは作成されません。4 より大きい場合、2^B-4 個のオーバーフローバケットが作成されます。runtime.makeBucketArray 関数の以下のコードに対応します。
base := bucketShift(b)
nbuckets := base
// 4 未満ならオーバーフローバケットは作成されない
if b >= 4 {
// 予想バケット数に 1 << (b-4) を加算
nbuckets += bucketShift(b - 4)
// オーバーフローバケットに必要なメモリ
sz := t.Bucket.Size_ * nbuckets
// メモリ空間を切り上げ
up := roundupsize(sz)
if up != sz {
// 等しくない場合は up を使用して再計算
nbuckets = up / t.Bucket.Size_
}
}base は予想されるバケット数で、nbuckets は実際に割り当てられたバケット数で、オーバーフローバケットの数を加えたものです。
if base != nbuckets {
// 最初の利用可能なオーバーフローバケット
nextOverflow = (*bmap)(add(buckets, base*uintptr(t.BucketSize)))
// オーバーフローバケットの追跡コストを削減するため、最後の利用可能なオーバーフローバケットのオーバーフローポインタをハッシュバケットのヘッダーに指す
last := (*bmap)(add(buckets, (nbuckets-1)*uintptr(t.BucketSize)))
// 最後のオーバーフローバケットがハッシュバケットを指す
last.setoverflow(t, (*bmap)(buckets))
}両者が等しくない場合、追加のオーバーフローバケットが割り当てられたことを示します。nextoverflow ポインタは最初の利用可能なオーバーフローバケットを指します。これにより、ハッシュバケットとオーバーフローバケットは実際には同じ連続したメモリ内にあることがわかります。这也是図でハッシュバケット配列とオーバーフローバケット配列が隣接している理由です。
アクセス
構文入門で説明したように、map へのアクセスには 3 つの方法があります。
# 直接値にアクセス
val := dict[key]
# 値とそのキーが存在するかどうかアクセス
val, exist := dict[key]
# map を走査
for key, val := range dict{
}これら 3 つの方法はそれぞれ異なる関数を使用します。その中で for range による map の走査が最も複雑です。
キーバリュー
最初の 2 つの方法は 2 つの関数に対応しています。それぞれ runtime.mapaccess1 と runtime.mapaccess2 です。関数シグネチャは以下の通りです。
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer
func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool)key は map のキーにアクセスするポインタを指し、戻り値もポインタのみを返します。アクセス時、まず key のハッシュ値を計算し、key がどのハッシュバケットにあるかを特定します。
// 境界処理
if h == nil || h.count == 0 {
if t.HashMightPanic() {
t.Hasher(key, 0) // issue 23734 を参照
}
return unsafe.Pointer(&zeroVal[0])
}
// 同時読み書きを防止
if h.flags&hashWriting != 0 {
fatal("concurrent map read and map write")
}
// 指定された型の hasher を使用してハッシュ値を計算
hash := t.Hasher(key, uintptr(h.hash0))
// (1 << B) - 1
m := bucketMask(h.B)
// ポインタを移動して key があるハッシュバケットを特定
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.BucketSize)))アクセスの最初に境界状況の処理を行い、map の同時読み書きを防止します。map が同時読み書き状態にある場合、panic が発生します。その後ハッシュ値を計算し、bucketMask 関数が行うのは (1 << B) - 1 の計算です。hash & m は hash & (1 << B) - 1 と等しく、これは 2 進数の剰余操作で、hash % (1 << B) と等価です。ビット演算を使用する利点はより高速であることです。最後の 3 行のコードが行うのは、key から計算されたハッシュ値を現在の map 内のバケット数で剰余を取り、ハッシュバケットの番号を取得し、番号に基づいてポインタを移動して key があるハッシュバケットポインタを取得します。
key がどのハッシュバケットにあるかがわかった後、検索を開始できます。
// ハッシュ値の上位 8 ビットを取得
top := tophash(hash)
bucketloop:
// bmap リストを走査
for ; b != nil; b = b.overflow(t) {
// bmap 内の要素
for i := uintptr(0); i < bucketCnt; i++ {
// 計算された top と tophash の要素を比較
if b.tophash[i] != top {
// 後続は空で、もうない
if b.tophash[i] == emptyRest {
break bucketloop
}
// 等しくなければオーバーフローバケットを継続して走査
continue
}
// i に基づいてポインタを移動して対応するインデックスのキーを取得
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
// ポインタを処理
if t.IndirectKey() {
k = *((*unsafe.Pointer)(k))
}
// 2 つのキーが等しいか比較
if t.Key.Equal(key, k) {
// 等しい場合、ポインタを移動して k に対応するインデックスの要素を返す
// この行のコードからキーバリューのメモリアドレスが連続していることがわかる
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
if t.IndirectElem() {
e = *((*unsafe.Pointer)(e))
}
return e
}
}
}
// 見つからなければゼロ値を返す
return unsafe.Pointer(&zeroVal[0])ハッシュバケットを特定する際、剰余を使用して特定します。したがって、key がどのハッシュバケットにあるかはハッシュ値の低位に依存します。低位が何ビットかは B のサイズに依存します。ハッシュバケットを見つけた後、その中の tophash はハッシュ値の上位 8 ビットを格納します。低位の剰余値はすべて等しいため、key が等しいかどうかを 1 つずつ比較する必要はなく、ハッシュ値の上位 8 ビットのみを比較すれば十分です。以前に計算されたハッシュ値に基づいてその上位 8 ビットを取得し、bmap 内の tophash 配列で 1 つずつ比較します。上位 8 ビットが等しい場合、キーが等しいかどうかを比較します。キーも等しい場合、要素が見つかったことを示します。等しくない場合、tophash 配列の走査を継続し、それでも見つからない場合、オーバーフローバケット bmap リストの走査を継続し、bmap の tophash[i] が emptyRest になるまでループを終了し、最後に対応する型のゼロ値を返します。
mapaccess2 関数は mapaccess1 関数とロジックが完全に一致しており、要素が存在するかどうかを示すブール戻り値が 1 つ追加されているだけです。
走査
map を走査する構文は以下の通りです。
for key, val := range dict {
// do somthing...
}実際に走査する際、Go は hiter 構造体を使用して走査情報を格納します。hiter は hmap interator の略で、ハッシュテーブルイテレータを意味します。
// A hash iteration structure.
// If you modify hiter, also change cmd/compile/internal/reflectdata/reflect.go
// and reflect/value.go to match the layout of this structure.
type hiter struct {
key unsafe.Pointer // Must be in first position. Write nil to indicate iteration end (see cmd/compile/internal/walk/range.go).
elem unsafe.Pointer // Must be in second position (see cmd/compile/internal/walk/range.go).
t *maptype
h *hmap
buckets unsafe.Pointer // bucket ptr at hash_iter initialization time
bptr *bmap // current bucket
overflow *[]*bmap // keeps overflow buckets of hmap.buckets alive
oldoverflow *[]*bmap // keeps overflow buckets of hmap.oldbuckets alive
startBucket uintptr // bucket iteration started at
offset uint8 // intra-bucket offset to start from during iteration (should be big enough to hold bucketCnt-1)
wrapped bool // already wrapped around from end of bucket array to beginning
B uint8
i uint8
bucket uintptr
checkBucket uintptr
}いくつかのフィールドについて簡単に説明します。
key、elemはfor range走査時に取得されるキーバリューbuckets:イテレータ初期化時に指定され、ハッシュバケットのヘッダーを指すbptr:現在走査中の bmapstartBucket:イテレーション開始時の開始バケット番号offset:バケット内オフセット、範囲は[0, bucketCnt-1]B:hmap の B 値i:バケット内要素インデックスwrapped:ハッシュバケット配列の末尾から先頭に戻ったかどうか
走査を開始する前に、Go は runtime.mapiterinit 関数を通じてイテレータを初期化し、その後 runtime.mapinternext 関数を通じて map を走査します。両方とも hiter 構造体を使用します。
func mapiterinit(t *maptype, h *hmap, it *hiter)
func mapiternext(it *hiter)イテレータ初期化而言、まず map の現在のスナップショットを取得します。
it.t = t
it.h = h
// hmap の現在の状態のスナップショットを記録。B 値のみ保存すればよい
it.B = h.B
it.buckets = h.buckets
if t.Bucket.PtrBytes == 0 {
h.createOverflow()
it.overflow = h.extra.overflow
it.oldoverflow = h.extra.oldoverflow
}後続のイテレーション時に、実際に走査されるのは map のスナップショットであり、実際の map ではありません。そのため、走査プロセス中に追加された要素やバケットは走査されません。同時に並行して走査・書き込みを行うと、fatal がトリガーされる可能性があります。
if h.flags&hashWriting != 0 {
fatal("concurrent map iteration and map write")
}2 番目に、走査の 2 つの開始位置を決定します。1 つ目は開始バケットの位置で、2 つ目はバケット内の開始位置です。これら 2 つはランダムに選択されます。
// r は乱数
var r uintptr
if h.B > 31-bucketCntBits {
r = uintptr(fastrand64())
} else {
r = uintptr(fastrand())
}
// r % (1 << B) で開始バケットの位置を取得
it.startBucket = r & bucketMask(h.B)
// r >> B % 8 で開始バケット内の要素開始位置を取得
it.offset = uint8(r >> h.B & (bucketCnt - 1))
// 現在走査中のバケット番号を記録
it.bucket = it.startBucketfastrand() または fastrand64() で乱数を取得し、2 回の剰余演算でバケット開始位置とバケット内開始位置を取得します。
TIP
map は同時読み書きを許可しませんが、同時走査は許可します。
次に実際に map のイテレーションを開始します。バケットをどのように走査するか、および終了戦略についてです。
// hmap
h := it.h
// maptype
t := it.t
// 走査するバケットの位置
bucket := it.bucket
// 走査する bmap
b := it.bptr
// バケット内番号 i
i := it.i
next:
if b == nil {
// 現在のバケット位置と開始位置が等しい場合、1 周して戻ってきたことを示し、後続は既に走査済み
// 走査終了、終了可能
if bucket == it.startBucket && it.wrapped {
it.key = nil
it.elem = nil
return
}
// バケットインデックスを後方に移動
bucket++
// bucket == 1 << B、ハッシュバケット配列の末尾に到達
if bucket == bucketShift(it.B) {
// 先頭から開始
bucket = 0
it.wrapped = true
}
i = 0
}ハッシュバケットの開始位置の選択はランダムです。走査時、開始位置からバケットスライスの末尾まで逐个イテレーションし、1 << B に到達した後、先頭から開始し、再び開始位置に戻った場合、走査が完了したことを示し、その後終了します。上記のコードは map 内でバケットを走査する方法に関するもので、以下のコードはバケット内でどのように走査するかを説明します。
for ; i < bucketCnt; i++ {
// (i + offset) % 8
offi := (i + it.offset) & (bucketCnt - 1)
// 現在の要素が空ならスキップ
if isEmpty(b.tophash[offi]) || b.tophash[offi] == evacuatedEmpty {
continue
}
// ポインタを移動してキーを取得
k := add(unsafe.Pointer(b), dataOffset+uintptr(offi)*uintptr(t.KeySize))
if t.IndirectKey() {
k = *((*unsafe.Pointer)(k))
}
// ポインタを移動して値を取得
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+uintptr(offi)*uintptr(t.ValueSize))
// 等量拡張の状況を処理。キーバリューが他の位置に疏散された後、キーバリューを再検索する必要がある
if (b.tophash[offi] != evacuatedX && b.tophash[offi] != evacuatedY) ||
!(t.ReflexiveKey() || t.Key.Equal(k, k)) {
it.key = k
if t.IndirectElem() {
e = *((*unsafe.Pointer)(e))
}
it.elem = e
} else {
rk, re := mapaccessK(t, h, k)
if rk == nil {
continue
}
it.key = rk
it.elem = re
}
it.bucket = bucket
it.i = i + 1
return
}
// 見つからなければオーバーフローバケット内で検索
b = b.overflow(t)
i = 0
goto nextTIP
上記の拡張判断条件において、ある式が困惑を招く可能性があります。
t.Key.Equal(k, k)k が自身と等しいかどうかを判断するのは、キーが Nan の状況をフィルタリングするためです。要素のキーが Nan の場合、その要素に正常にアクセスできなくなります。走査でも直接アクセスでも削除でも正常に行えません。Nan != Nan が常に成立するため、このキーを見つけることが永远にできないからです。
まず i 値と offset 値から剰余演算で走査するバケット内インデックスを取得し、ポインタを移動してキーバリューを取得します。map 走査期間中、他の書き込み操作が map の拡張をトリガーする可能性があるため、実際のキーバリューは元の位置にない可能性があります。この場合、mapaccessK 関数を使用して実際のキーバリューを再検索する必要があります。この関数のシグネチャは以下の通りです。
func mapaccessK(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, unsafe.Pointer)その機能は mapaccess1 関数と完全に一致していますが、mapaccessK 関数は key 値と value 値を同時に返す点が異なります。最終的にキーバリューを取得した後、それをイテレータの key、elem に代入し、イテレータのインデックスを更新します。これで 1 回のイテレーションが完了し、コード実行は for range のコードブロックに戻ります。バケット内で見つからない場合、オーバーフローバケット内で検索し、上記の手順を繰り返し、オーバーフローバケットリストの走査が完了した後、次のハッシュバケットのイテレーションを継続します。
修改
map を修改する構文は以下の通りです。
dict[key] = valGo では、map を修改する操作は runtime.mapassign 関数によって完了します。この関数のシグネチャは以下の通りです。
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointerそのアクセスプロセスのロジックは mapaccess1 と同じですが、key が存在しない場合に位置を割り当て、存在すれば更新し、最後に要素のポインタを返します。開始時に、いくつかの準備作業を行う必要があります。
// nil の map への書き込みは許可されない
if h == nil {
panic(plainError("assignment to entry in nil map"))
}
// 同時書き込みを禁止
if h.flags&hashWriting != 0 {
fatal("concurrent map writes")
}
// key のハッシュ値を計算
hash := t.Hasher(key, uintptr(h.hash0))
// hmap の状態を修改
h.flags ^= hashWriting
// ハッシュバケットを初期化
if h.buckets == nil {
h.buckets = newobject(t.Bucket) // newarray(t.Bucket, 1)
}上記のコードでは主に以下のことを行います。
- hmap の状態チェック
- key のハッシュ値を計算
- ハッシュバケットの初期化が必要かチェック
その後、ハッシュ値から剰余演算でハッシュバケットの位置を取得し、key の tophash を計算します。
again:
// hash % (1 << B)
bucket := hash & bucketMask(h.B)
// ポインタを移動して指定位置の bmap を取得
b := (*bmap)(add(h.buckets, bucket*uintptr(t.BucketSize)))
// tophash を計算
top := tophash(hash)これでバケットの位置が確定し、bmap、tophash があれば、要素の検索を開始できます。
// 挿入する tophash
var inserti *uint8
// 挿入する key 値ポインタ
var insertk unsafe.Pointer
// 挿入する value 値ポインタ
var elem unsafe.Pointer
bucketloop:
for {
// バケット内の tophash 配列を走査
for i := uintptr(0); i < bucketCnt; i++ {
// tophash が等しくない
if b.tophash[i] != top {
// 現在のバケット内インデックスが空で、まだ要素が挿入されていない場合、その位置を選択して挿入
if isEmpty(b.tophash[i]) && inserti == nil {
// key に適した位置が見つかった
inserti = &b.tophash[i]
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
}
// 走査し終わればループを終了
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
// tophash が等しい場合、key が既に存在する可能性がある
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
if t.IndirectKey() {
k = *((*unsafe.Pointer)(k))
}
// key が等しいか判断
if !t.Key.Equal(key, k) {
continue
}
// key 値を更新する必要がある場合、key のメモリを k の位置に直接コピー
if t.NeedKeyUpdate() {
typedmemmove(t.Key, k, key)
}
// 要素のポインタを取得
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
// 更新完毕、要素ポインタを返す
goto done
}
// ここに到達すれば key が見つからなかったことを示す。オーバーフローバケットリストを走査して継続検索
ovf := b.overflow(t)
if ovf == nil {
break
}
b = ovf
}
// ここに到達すれば key が map 内に存在しないことを示すが、key に割り当てる適した位置が見つかった可能性もあるし、そうでない可能性もある
// key に割り当てる適した位置が見つからなかった
if inserti == nil {
// 現在のハッシュバケットとそのオーバーフローバケットが満杯であることを示す。新しいオーバーフローバケットを割り当てる
newb := h.newoverflow(t, b)
// オーバーフローバケット内に key に割り当てる位置を確保
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
elem = add(insertk, bucketCnt*uintptr(t.KeySize))
}
// 格納するのが key ポインタの場合
if t.IndirectKey() {
// 新しいメモリを割り当てる。unsafe ポインタを返す
kmem := newobject(t.Key)
*(*unsafe.Pointer)(insertk) = kmem
// insertk に代入し、後で key のメモリコピーを容易にする
insertk = kmem
}
// 格納するのが要素ポインタの場合
if t.IndirectElem() {
// メモリを割り当てる
vmem := newobject(t.Elem)
// ポインタに vmem を指させる
*(*unsafe.Pointer)(elem) = vmem
}
// key のメモリを insertk の位置に直接コピー
typedmemmove(t.Key, insertk, key)
*inserti = top
// 数を 1 つ加算
h.count++
done:
// ここに到達すれば修改プロセスが完了したことを示す
if h.flags&hashWriting == 0 {
fatal("concurrent map writes")
}
h.flags &^= hashWriting
if t.IndirectElem() {
elem = *((*unsafe.Pointer)(elem))
}
// 要素ポインタを返す
return elem上記の長いコードでは、まず for ループに入ってハッシュバケットとオーバーフローバケット内で検索を試みます。検索ロジックは mapaccess と完全に一致します。此时 3 つの可能性があります。
- 1 つ目:map 内に既に存在する key が見つかった場合、直接
doneコードブロックにジャンプし、要素ポインタを返す - 2 つ目:map 内に key に割り当てる位置が見つかった場合、key を指定位置にコピーし、要素ポインタを返す
- 3 つ目:すべてのバケットを検索し終わっても、map 内に key に割り当てる位置が見つからなかった場合、新しいオーバーフローバケットを作成し、key をバケット内に割り当て、key を指定位置にコピーし、要素ポインタを返す
最終的に要素ポインタを取得した後、代入できますが、この操作は mapassign 関数によって完了するわけではありません。それは要素ポインタを返すことのみを担当し、代入操作はコンパイラ期間中に挿入されます。コード内では見えませんが、コンパイル後のコードでは見えます。以下のコードがあるとします。
func main() {
dict := make(map[string]string, 100)
dict["hello"] = "world"
}以下のコマンドでアセンブリコードを取得します。
go tool compile -S -N -l main.go重要な部分は以下の通りです。
0x004e 00078 LEAQ type:map[string]string(SB), AX
0x0055 00085 CALL runtime.mapassign_faststr(SB)
0x005a 00090 MOVQ AX, main..autotmp_2+40(SP)
0x0083 00131 LEAQ go:string."world"(SB), CX
0x008a 00138 MOVQ CX, (AX)runtime.mapassign_faststr が呼び出され、そのロジックは mapassign と完全に類似しています。LEAQ go:string."world"(SB), CX は文字列のアドレスを CX に格納し、MOVQ CX, (AX) はそれを AX に格納します。これで要素の代入が完了します。
削除
Go では、map の要素を削除するには、組み込み関数 delete を使用するしかありません。
delete(dict, "abc")内部では runtime.mapdelete 関数を呼び出します。この関数のシグネチャは以下の通りです。
func mapdelete(t *maptype, h *hmap, key unsafe.Pointer)map 内の指定された key の要素を削除します。要素が map 内に存在するかどうかに関わらず、反応はありません。関数の先頭で準備作業を行うロジックは類似しています。以下のことを行うだけです。
- hmap の状態チェック
- key のハッシュ値を計算
- ハッシュバケットを特定
- tophash を計算
前面には多くの重複する内容があるため、ここでは削除のロジックのみ重点关注します。
bOrig := b
search:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
// 見つからなければループを終了
if b.tophash[i] == emptyRest {
break search
}
continue
}
// ポインタを移動して key の位置を見つける
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
k2 := k
if t.IndirectKey() {
k2 = *((*unsafe.Pointer)(k2))
}
if !t.Key.Equal(key, k2) {
continue
}
// key を削除
if t.IndirectKey() {
*(*unsafe.Pointer)(k) = nil
} else if t.Key.PtrBytes != 0 {
memclrHasPointers(k, t.Key.Size_)
}
// ポインタを移動して要素の位置を見つける
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
// 要素を削除
if t.IndirectElem() {
*(*unsafe.Pointer)(e) = nil
} else if t.Elem.PtrBytes != 0 {
memclrHasPointers(e, t.Elem.Size_)
} else {
memclrNoHeapPointers(e, t.Elem.Size_)
}
notLast:
// 数を 1 つ減算
h.count--
// ハッシュシードをリセットし、衝突発生確率を低減
if h.count == 0 {
h.hash0 = fastrand()
}
break search
}
}上記のコードから、検索ロジックが前面の操作とほぼ完全に一致していることがわかります。要素を見つけて削除し、hmap が記録する数を 1 つ減らします。数が 0 になった場合、ハッシュシードをリセットします。
もう 1 つ注意すべき点は、要素を削除した後、現在のインデックスの tophash 状態を修改する必要があることです。
// 現在の tophash を空としてマーク
b.tophash[i] = emptyOne
// tophash の末尾にある場合
if i == bucketCnt-1 {
// オーバーフローバケットが空でなく、オーバーフローバケット内に要素がある場合、現在の要素が最後ではないことを示す
if b.overflow(t) != nil && b.overflow(t).tophash[0] != emptyRest {
goto notLast
}
} else {
// 隣接要素が空でない
if b.tophash[i+1] != emptyRest {
goto notLast
}
}要素が実際に最後の要素である場合、バケットリスト内の一部のバケットの tophash 配列の値を修正する必要があります。否则、後続の走査時に正しい位置で終了できなくなるためです。map がオーバーフローバケットを作成する際に説明したように、Go はオーバーフローバケットを追跡するコストを削減するため、最後のオーバーフローバケットの overflow ポインタは先頭のハッシュバケットを指しています。したがって、実際には単方向環状リストであり、リストの「先頭」はハッシュバケットです。ここでの b は検索後の b であり、リスト内の特定の 1 つである可能性が高いです。環状リストを逆順に走査して、最後に存在する要素を検索します。コードは正順走査と書かれていますが、リストは環であるため、現在のオーバーフローバケットの 1 つ前まで絶えず正順走査します。結果的には逆順です。その後、バケット内の tophash 配列を逆順に走査し、状態が emptyOne の要素を emptyRest に更新し、最後に存在する要素を見つけるまで続けます。環内に無限に陥るのを避けるため、最初のバケットに戻った場合、つまり bOrig の場合、リスト内に利用可能な要素がないことを示すため、ループを終了できます。
// ここに到達すれば現在の要素の後ろに要素がないことを示す
// 絶えず bmap リストを逆順に走査し、バケット内の tophash を逆順に走査
// 状態が emptyOne のものを emptyRest に更新
for {
b.tophash[i] = emptyRest
if i == 0 {
if b == bOrig {
break
}
c := b
// 現在の bmap リストの 1 つ前を見つける
for b = bOrig; b.overflow(t) != c; b = b.overflow(t) {
}
i = bucketCnt - 1
} else {
i--
}
if b.tophash[i] != emptyOne {
break
}
}クリア
Go 1.21 バージョンでは、組み込み関数 clear が追加され、map 内のすべての要素をクリアするために使用できます。
clear(dict)内部では runtime.mapclear 関数を呼び出します。これは map 内のすべての要素を削除する責任があります。
func mapclear(t *maptype, h *hmap)この関数のロジックは複雑ではありません。まず map 全体を空としてマークする必要があります。
// 各バケットおよびオーバーフローバケットを走査し、すべての tophash 要素を emptyRest に設定
markBucketsEmpty := func(bucket unsafe.Pointer, mask uintptr) {
for i := uintptr(0); i <= mask; i++ {
b := (*bmap)(add(bucket, i*uintptr(t.BucketSize)))
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
b.tophash[i] = emptyRest
}
}
}
}
markBucketsEmpty(h.buckets, bucketMask(h.B))上記のコードが行うのは、各バケットを走査し、バケット内の tophash 配列の要素をすべて emptyRest に設定し、map を空としてマークします。これによりイテレータの継続イテレーションを阻止し、その後 map をクリアします。
// ハッシュシードをリセット
h.hash0 = fastrand()
// extra 構造体をリセット
if h.extra != nil {
*h.extra = mapextra{}
}
// この操作は元の buckets のメモリをクリアし、新しいバケットを再割り当て
_, nextOverflow := makeBucketArray(t, h.B, h.buckets)
if nextOverflow != nil {
// 新しい空きオーバーフローバケットを割り当て
h.extra.nextOverflow = nextOverflow
}makeBucketArray を通じて以前のバケットのメモリをクリアし、その後新しいものを割り当てます。これでバケットのクリアが完了します。その他にもいくつかの詳細があります。例えば count を 0 に設定するなど、他のいくつかの操作については詳しく説明しません。
拡張
以前のすべての操作では、ロジック自体により注目するため、拡張に関連する多くの内容を屏蔽しました。これで簡単になります。拡張のロジックは実際にはより複雑で、最後に配置したのは干渉を生じさせないためです。では、Go が map をどのように拡張するかを見てみましょう。前面で既に言及したように、拡張をトリガーする 2 つの条件があります。
- 負荷因子が 6.5 を超える
- オーバーフローバケットの数が多すぎる
負荷因子が閾値を超えるかどうかを判断する関数は runtime.overLoadFactor 関数で、ハッシュ衝突部分で既に説明済みです。オーバーフローバケットの数が多すぎるかどうかを判断する関数は runtime.tooManyOverflowBuckets で、その動作原理も非常にシンプルです。
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {
if B > 15 {
B = 15
}
return noverflow >= uint16(1)<<(B&15)
}上記のコードは以下の式に簡略化でき、一目で理解できます。
overflow >= 1 << (min(15,B) % 16)ここで、Go にとって「多すぎる」の定義は:オーバーフローバケットの数がハッシュバケットの数とほぼ同じことです。閾値が低すぎると、余分な作業を行うことになり、閾値が高すぎると、拡張時に大量のメモリを占有することになります。要素を修改・削除する際に拡張がトリガーされる可能性があります。拡張が必要かどうかを判断するコードは以下の通りです。
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // テーブルの拡張はすべてを無効にするため、再試行
}これら 3 つの制限条件が見えます。
- 現在拡張中ではないこと
- 負荷因子が 6.5 未満
- オーバーフローバケットの数が多すぎない
拡張を担当する関数は当然 runtime.hashGrow です。
func hashGrow(t *maptype, h *hmap)実際、拡張にも種類があり、異なる条件によってトリガーされる拡張はその型も異なります。以下の 2 つに分かれます。
- 増量拡張
- 等量拡張
増量拡張
負荷因子が大きすぎる場合、つまり要素の数がハッシュバケットの数より大きい場合、ハッシュ衝突が深刻な場合、多くのオーバーフローバケットリストが形成されます。これにより map の読み書きパフォーマンスが低下します。要素を検索するにはより多くのオーバーフローバケットリストを走査する必要があるためです。走査の時間計算量は O(n) です。ハッシュ表の検索の時間計算量は主にハッシュ値の計算時間と走査の時間に依存します。走査の時間がハッシュ計算時間より遠かに小さい場合、検索の時間計算量は O(1) と見なせます。ハッシュ衝突が頻繁に発生し、多くの key が同じハッシュバケットに割り当てられた場合、オーバーフローバケットリストが長くなり走査時間が増大し、検索時間が増大します。増刪改操作はすべてまず検索操作を行う必要があるため、これにより map 全体のパフォーマンスが深刻に低下します。
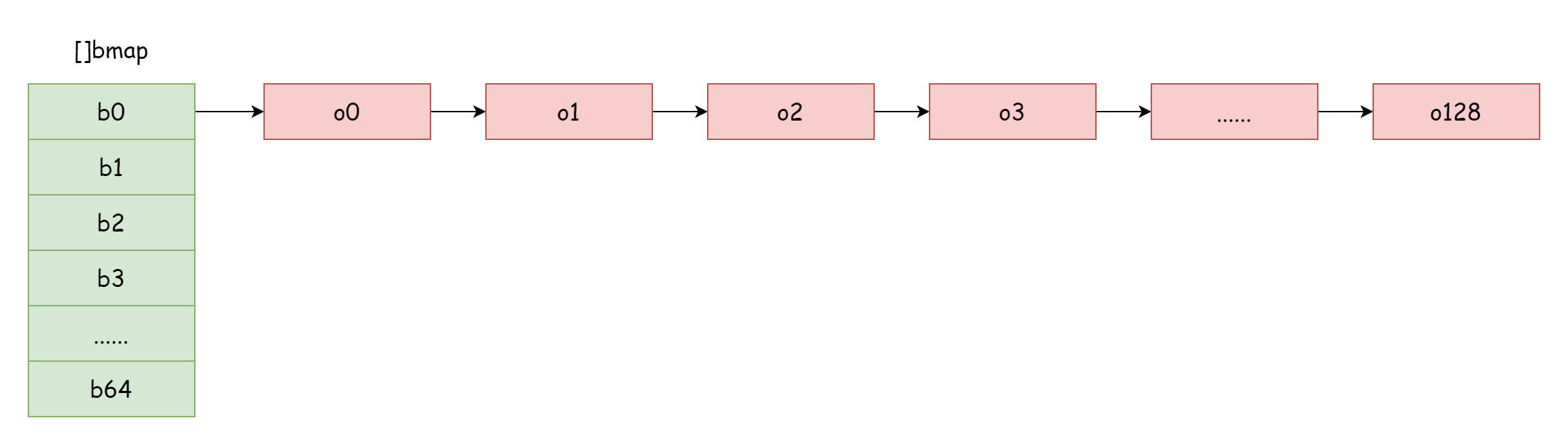
図のような極端な状況では、検索の時間計算量は基本的に O(n) と変わりません。この状況に対処する解決策は、より多くのハッシュバケットを追加し、オーバーフローバケットリストが長くなるのを避けることです。この方法を増量拡張と呼びます。
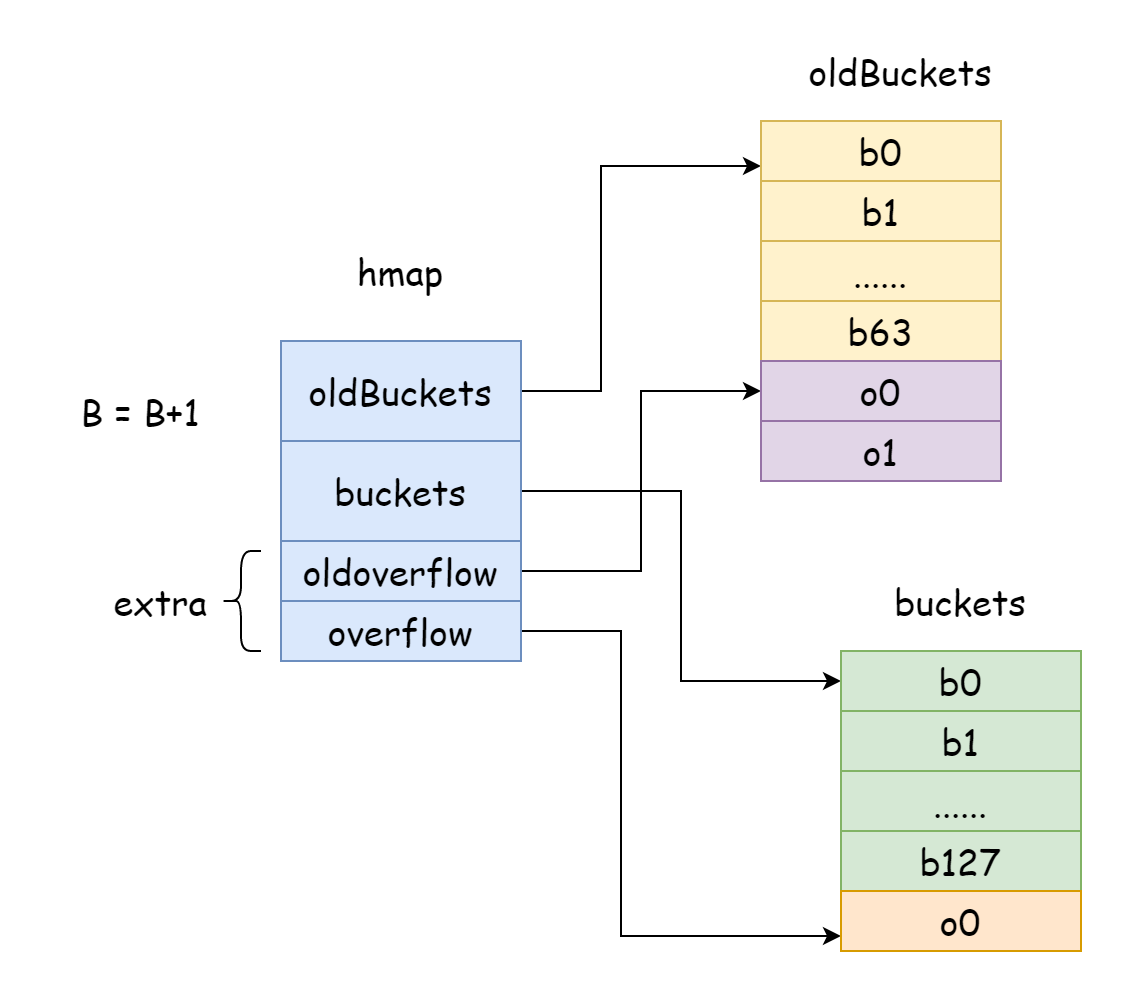
Go では、増量拡張は毎回 B を 1 つ加算します。つまり、ハッシュバケットの規模は毎回 2 倍に拡大します。拡張後、古いデータを新しい map に移動する必要があります。map 内の要素数が数千万または数億単位である場合、一度にすべて移動すると非常に時間がかかるため、Go は段階的に移動する戦略を採用しています。そのため、Go は hamp 内の oldBuckets を元のハッシュバケット配列に指し示させ、これが古いデータであることを示し、その後より大きな容量のハッシュバケット配列を作成し、hmap 内の buckets に新しいハッシュバケット配列を指し示させます。その後、修改・削除操作のたびに、一部の要素を古いバケットから新しいバケットに移動し、移動が完了するまで続けます。古いバケットのメモリはその後解放されます。
func hashGrow(t *maptype, h *hmap) {
// 差
bigger := uint8(1)
// 古いバケット
oldbuckets := h.buckets
// 新しいハッシュバケット
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
flags := h.flags &^ (iterator | oldIterator)
if h.flags&iterator != 0 {
flags |= oldIterator
}
// B+bigger
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
h.nevacuate = 0
h.noverflow = 0
// オーバーフローバケットも古いバケットと新しいバケットを指定
if h.extra != nil && h.extra.overflow != nil {
if h.extra.oldoverflow != nil {
throw("oldoverflow is not nil")
}
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
}
if nextOverflow != nil {
if h.extra == nil {
h.extra = new(mapextra)
}
h.extra.nextOverflow = nextOverflow
}
}上記のコードが行うのは、1 倍大きい容量の新しいハッシュバケットを作成し、ハッシュの新旧バケットの参照、および新旧オーバーフローバケットの参照を指定し、hmap のいくつかの状態を更新することです。実際の移動作業は hashGrow 関数によって完了するわけではありません。それは新旧バケットの指定と hmap のいくつかの状態の更新のみを担当します。これらの作業は実際には runtime.growWork 関数によって完了します。
func growWork(t *maptype, h *hmap, bucket uintptr)これは mapassign 関数と mapdelete 関数内で、以下の形式で呼び出されます。その役割は、現在の map が拡張中である場合、一部の移動作業を行うことです。
if h.growing() {
growWork(t, h, bucket)
}修改・削除操作を行う際、現在拡張中かどうかを判断する必要があります。これは主に hmap.growing メソッドによって完了します。内容は非常にシンプルで、oldbuckets が空でないかどうかを判断します。
func (h *hmap) growing() bool {
return h.oldbuckets != nil
}growWork 関数が何を行ったか見てみましょう。
func growWork(t *maptype, h *hmap, bucket uintptr) {
// bucket % 1 << (B-1)
evacuate(t, h, bucket&h.oldbucketmask())
if h.growing() {
evacuate(t, h, h.nevacuate)
}
}ここで bucket&h.oldbucketmask() 操作は古いバケットの位置を計算し、移動しようとしているのが現在のバケットの古いバケットであることを確認します。関数から、実際に移動作業を担当するのが runtime.evacuate 関数であることがわかります。その中で evaDst 構造体を使用して移動先を表します。主な役割は移動プロセス中に新しいバケットをイテレーションすることです。
type evacDst struct {
b *bmap // 移動先の新しいバケット
i int // バケット内インデックス
k unsafe.Pointer // 新しいキー移動先へのポインタ
e unsafe.Pointer // 新しい値移動先へのポインタ
}移動を開始する前に、Go は 2 つの evacDst 構造体を割り当てます。1 つは新しいハッシュバケットの上半分を指し、もう 1 つは新しいハッシュバケットの下半分を指します。
// 古いバケット内の指定されたハッシュバケットを特定
b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.BucketSize)))
// 古いバケットの長さ = 1 << (B - 1)
newbit := h.noldbuckets()
var xy [2]evacDst
x := &xy[0]
// 新しいバケットの上半分を指す
x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.BucketSize)))
x.k = add(unsafe.Pointer(x.b), dataOffset)
x.e = add(x.k, bucketCnt*uintptr(t.KeySize))
// 等量拡張かどうか判断
if !h.sameSizeGrow() {
y := &xy[1]
// 新しいバケットの下半分を指す
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.BucketSize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.e = add(y.k, bucketCnt*uintptr(t.KeySize))
}古いバケットの移動先は 2 つの新しいバケットです。移動後、バケット内の一部のデータは上半分にあり、もう一部のデータは下半分にあります。これは拡張後のデータがより均一に分布することを望んでいるためです。分布が均一であればあるほど、map の検索パフォーマンスは向上します。Go がデータをどのように 2 つの新しいバケットに移動するかは、以下のコードに対応します。
// オーバーフローバケットリストを走査
for ; b != nil; b = b.overflow(t) {
// 各バケットの最初のキーバリューを取得
k := add(unsafe.Pointer(b), dataOffset)
e := add(k, bucketCnt*uintptr(t.KeySize))
// バケット内の各キーバリューを走査
for i := 0; i < bucketCnt; i, k, e = i+1, add(k, uintptr(t.KeySize)), add(e, uintptr(t.ValueSize)) {
top := b.tophash[i]
// 空ならスキップ
if isEmpty(top) {
b.tophash[i] = evacuatedEmpty
continue
}
// 新しいハッシュバケットは移動状態であってはならない
// 否则 問題が発生したはず
if top < minTopHash {
throw("bad map state")
}
k2 := k
if t.IndirectKey() {
k2 = *((*unsafe.Pointer)(k2))
}
// この変数は現在のキーバリューが上半分还是下半分に移動されるかを決定
// その値は 0 または 1 のみ
var useY uint8
if !h.sameSizeGrow() {
// ハッシュ値を再計算
hash := t.Hasher(k2, uintptr(h.hash0))
// k2 != k2 の特殊状況を処理
if h.flags&iterator != 0 && !t.ReflexiveKey() && !t.Key.Equal(k2, k2) {
useY = top & 1
top = tophash(hash)
} else {
// hash % 1 << (B - 1)
if hash&newbit != 0 {
useY = 1
}
}
}
// 定数の値をチェック
if evacuatedX+1 != evacuatedY || evacuatedX^1 != evacuatedY {
throw("bad evacuatedN")
}
// 古いバケットの tophash を更新し、現在の要素が既に移動されたことを示す
b.tophash[i] = evacuatedX + useY // evacuatedX + 1 == evacuatedY
// 移動先を指定
dst := &xy[useY] // 移動先
// 新しいバケットの容量が不足した場合、オーバーフローバケットを作成
if dst.i == bucketCnt {
dst.b = h.newoverflow(t, dst.b)
dst.i = 0
dst.k = add(unsafe.Pointer(dst.b), dataOffset)
dst.e = add(dst.k, bucketCnt*uintptr(t.KeySize))
}
dst.b.tophash[dst.i&(bucketCnt-1)] = top // dst.i をマスク。境界チェックを避ける最適化
// キーをコピー
if t.IndirectKey() {
*(*unsafe.Pointer)(dst.k) = k2 // ポインタをコピー
} else {
typedmemmove(t.Key, dst.k, k) // 要素をコピー
}
// 値をコピー
if t.IndirectElem() {
*(*unsafe.Pointer)(dst.e) = *(*unsafe.Pointer)(e)
} else {
typedmemmove(t.Elem, dst.e, e)
}
// 次のキーバリューの準備のため、新しいバケットの目的ポインタを後方に移動
dst.i++
dst.k = add(dst.k, uintptr(t.KeySize))
dst.e = add(dst.e, uintptr(t.ValueSize))
}
}上記のコードから、Go が古いバケットリスト内の各バケットの各要素を走査し、その中のデータを新しいバケットに移動することがわかります。データが上半分还是下半分に移動されるかは、再計算後のハッシュ値に依存します。
// hash % 1 << (B - 1)
if hash&newbit != 0 {
useY = 1
}移動後、現在の要素の tophash を evacuatedX または evacuated に設定します。拡張プロセス中にデータの検索を試みた場合、この状態からデータが既に移動されたことがわかり、新しいバケット内で対応するデータを探すことがわかります。この部分のロジックは runtime.mapaccess1 関数の以下のコードに対応します。
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
// 以前は半分のバケットがあった。2 のべき乗を 1 つさらにマスクダウン
m >>= 1
}
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.BucketSize)))
// 古いバケットが既に移動された場合、検索しない
if !evacuated(oldb) {
b = oldb
}
}要素にアクセスする際、現在拡張状態にある場合、まず古いバケット内で検索を試みます。古いバケットが既に移動された場合、古いバケット内で検索しません。移動に戻ると、此时 移動先が確定しています。次にデータを新しいバケットにコピーし、evacDst 構造体に次の移動先を指させる必要があります。
dst := &xy[useY]
dst.b.tophash[dst.i&(bucketCnt-1)] = top
typedmemmove(t.Key, dst.k, k)
typedmemmove(t.Elem, dst.e, e)
if h.flags&oldIterator == 0 && t.Bucket.PtrBytes != 0 {
b := add(h.oldbuckets, oldbucket*uintptr(t.BucketSize))
ptr := add(b, dataOffset)
n := uintptr(t.BucketSize) - dataOffset
memclrHasPointers(ptr, n)
}この操作は現在のバケットがすべて移動し終わるまで続き、その後 Go は現在の古いバケットのキーバリューデータをすべてメモリクリアし、ハッシュバケットの tophash 配列のみを残します(tophash 配列を残すのは、後続で移動状態を判断するためです)。古いバケット内のオーバーフローバケットのメモリは参照されなくなるため、後続で GC によって回収されます。hmap には nevacuate というフィールドがあり、移動進捗を記録するために使用されます。古いハッシュバケットを 1 つ移動し終わるごとに 1 つ加算されます。その値が古いバケットの数と等しくなった場合、map 全体の拡張が完了したことを示します。次に runtime.advanceEvacuationMark 関数によって拡張の仕上げ作業が行われます。
func advanceEvacuationMark(h *hmap, t *maptype, newbit uintptr) {
h.nevacuate++
stop := h.nevacuate + 1024
if stop > newbit {
stop = newbit
}
for h.nevacuate != stop && bucketEvacuated(t, h, h.nevacuate) {
h.nevacuate++
}
if h.nevacuate == newbit { // newbit = len(oldbuckets)
h.oldbuckets = nil
if h.extra != nil {
h.extra.oldoverflow = nil
}
h.flags &^= sameSizeGrow
}
}これは移動済み数量を統計し、古いバケット数と等しいか確認します。等しい場合、すべての古いバケットと古いオーバーフローバケットへの参照をクリアします。これで拡張が完了します。
growWork 関数では、evacuate 関数が 2 回呼び出されます。1 回目は現在アクセス中のバケットの古いバケットを移動し、2 回目は h.nevacuate が指す古いバケットを移動します。合計 2 回移動します。つまり、段階的に移動する際、毎回 2 つのバケットを移動します。
等量拡張
前面で言及したように、等量拡張をトリガーする条件はオーバーフローバケットの数が多すぎることです。map にまず大量の要素が追加され、その後大量に要素が削除された場合、多くのバケットが空になり、一部のバケットに多くの要素がある可能性があります。データの分布が非常に不均一で、相当数のオーバーフローバケットが空で、かなりのメモリを占有しています。このような問題を解決するためには、同等の容量の新しい map を作成し、ハッシュバケットを再割り当てする必要があります。このプロセスを等量拡張と呼びます。したがって、実際には拡張操作ではなく、すべての要素を再分配してデータの分布をより均一にするだけです。等量拡張操作は増量拡張操作に組み込まれており、そのロジックは増量拡張と完全に一致し、新旧 map の容量は完全に等しくなります。
hashGrow 関数では、負荷因子が閾値を超えていない場合、等量拡張が行われます。Go は h.flags の状態を sameSizeGrow に更新し、h.B は 1 つ加算されないため、新しく作成されるハッシュバケットの容量も変化しません。
bigger := uint8(1)
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
h.flags |= sameSizeGrow
}
oldbuckets := h.buckets
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)evacuate 関数では、最初に eavcDst 構造体を作成する際、等量拡張の場合、新しいバケットを指す構造体は 1 つのみ作成されます。
if !h.sameSizeGrow() {
y := &xy[1]
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.BucketSize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.e = add(y.k, bucketCnt*uintptr(t.KeySize))
}また、要素を移動する際、等量拡張はハッシュ値を再計算せず、上半分と下半分の選択もありません。
if !h.sameSizeGrow() {
// ハッシュ値を再計算
hash := t.Hasher(k2, uintptr(h.hash0))
// k2 != k2 の特殊状況を処理
if h.flags&iterator != 0 && !t.ReflexiveKey() && !t.Key.Equal(k2, k2) {
useY = top & 1
top = tophash(hash)
} else {
// hash % 1 << (B - 1)
if hash&newbit != 0 {
useY = 1
}
}
}これらを除けば、他のロジックは増量拡張と完全に一致します。等量拡張によってハッシュバケットが再分配された後、オーバーフローバケットの数は減少し、古いオーバーフローバケットはすべて GC によって回収されます。