map
A differenza di altri linguaggi, Go fornisce il supporto per le tabelle di mappatura tramite la parola chiave map, non come libreria standard. Le mappe sono una struttura dati molto utilizzata con diverse implementazioni possibili. Le due più comuni sono gli alberi rosso-nero e le tabelle hash. Go utilizza le tabelle hash.
TIP
L'implementazione delle map coinvolge numerose operazioni di spostamento puntatori, quindi la lettura di questo articolo richiede conoscenze della libreria standard unsafe.
Struttura Interna
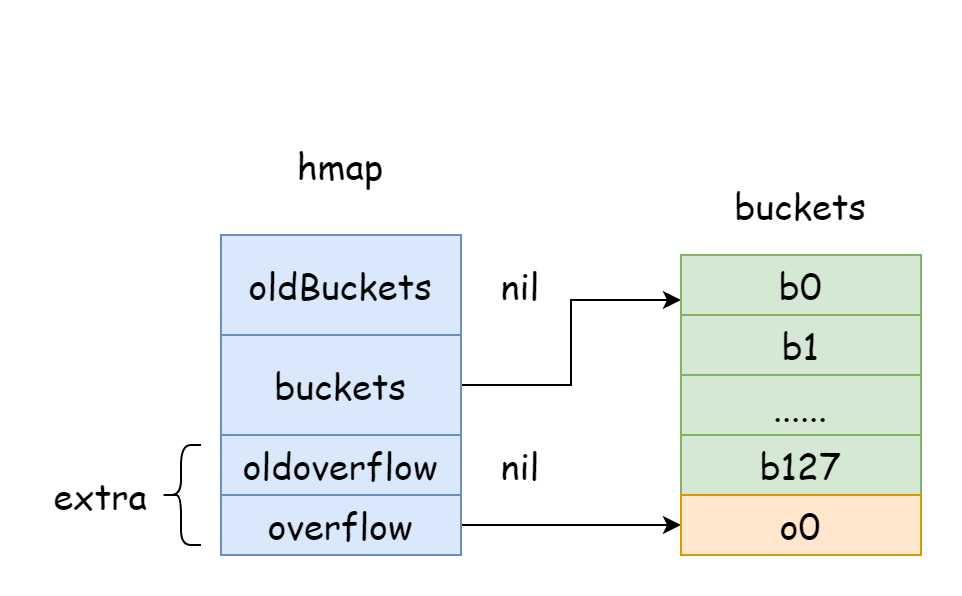
La struttura runtime.hmap rappresenta una map in Go. Come le slice, anche le map sono implementate internamente come strutture.
// A header for a Go map.
type hmap struct {
// Nota: il formato di hmap è anche codificato in cmd/compile/internal/reflectdata/reflect.go.
// Assicurarsi che sia sincronizzato con la definizione del compilatore.
count int // # celle live == dimensione della map. Deve essere primo (usato da len() builtin)
flags uint8
B uint8 // log_2 del numero di bucket (può contenere fino a loadFactor * 2^B elementi)
noverflow uint16 // numero approssimativo di bucket di overflow; vedere incrnoverflow per dettagli
hash0 uint32 // seed hash
buckets unsafe.Pointer // array di 2^B Bucket. può essere nil se count==0.
oldbuckets unsafe.Pointer // array di bucket precedente di metà dimensione, non-nil solo durante la crescita
nevacuate uintptr // contatore di progresso per l'evacuazione (i bucket minori di questo sono stati evacuati)
extra *mapextra // campi opzionali
}Le note in inglese sono già molto chiare. Di seguito alcune spiegazioni sui campi più importanti:
count: numero di elementi in hmap, equivalente alen(map).flags: flag di stato di hmap, indica lo stato corrente. Possibili valori:goconst ( iterator = 1 // un iteratore sta usando il bucket oldIterator = 2 // un iteratore sta usando il vecchio bucket hashWriting = 4 // una goroutine sta scrivendo su hmap sameSizeGrow = 8 // crescita di stessa dimensione in corso )B: numero di bucket hash in hmap è1 << B.noverflow: numero approssimativo di bucket di overflow in hmap.hash0: seed hash, specificato alla creazione di hmap, usato per calcolare i valori hash.buckets: puntatore all'array di bucket hash.oldbuckets: puntatore all'array di bucket hash prima dell'espansione.extra: contiene i bucket di overflow di hmap. I bucket di overflow sono nuovi bucket creati quando un bucket è pieno.
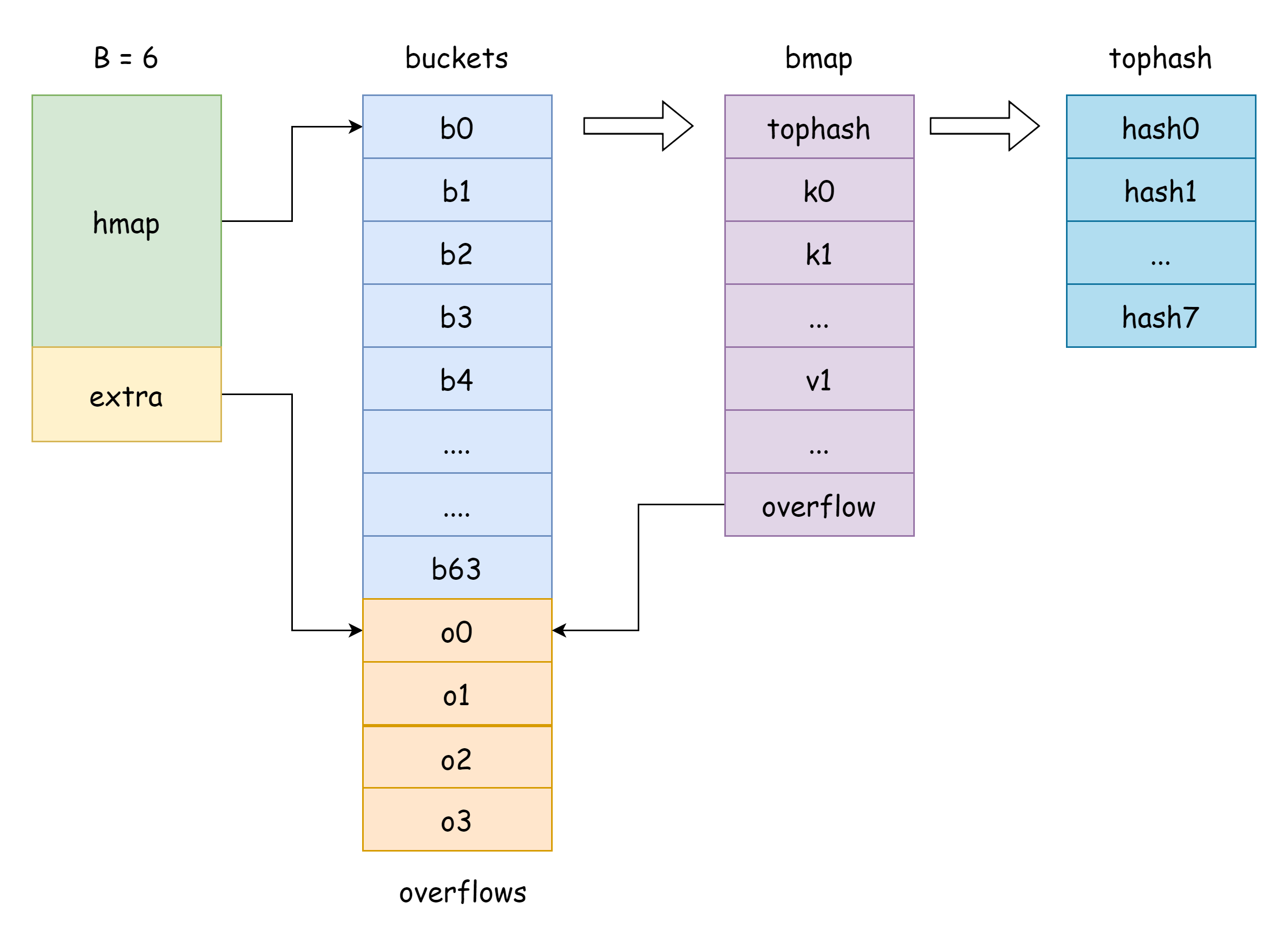
Il campo buckets in hmap è un puntatore a una slice di bucket. In Go, la struttura corrispondente è runtime.bmap:
// A bucket for a Go map.
type bmap struct {
tophash [bucketCnt]uint8
}Come si può vedere, ha solo un campo tophash, usato per memorizzare gli otto bit più alti di ogni chiave. In realtà, bmap ha più campi di questi, ma poiché le map possono memorizzare coppie chiave-valore di vari tipi, è necessario dedurre lo spazio di memoria occupato in base al tipo durante la compilazione. La funzione MapBucketType in cmd/compile/internal/reflectdata/reflect.go costruisce bmap durante la compilazione, eseguendo una serie di controlli, ad esempio se il tipo di chiave è comparable.
// MapBucketType make the map bucket type given the type of the map.
func MapBucketType(t *types.Type) *types.TypeQuindi, in realtà, la struttura di bmap è la seguente, ma questi campi non sono visibili. Go li accede effettivamente spostando puntatori unsafe:
type bmap struct {
tophash [BUCKETSIZE]uint8
keys [BUCKETSIZE]keyType
elems [BUCKETSIZE]elemType
overflow *bucket
}Alcune spiegazioni sui campi:
tophash: memorizza il valore degli otto bit più alti di ogni chiave. Per un elemento tophash, ci sono diversi valori speciali:goconst ( emptyRest = 0 // l'elemento corrente è vuoto e non ci sono più chiavi disponibili dopo questo elemento emptyOne = 1 // l'elemento corrente è vuoto, ma ci sono chiavi disponibili dopo questo elemento evacuatedX = 2 // appare durante l'espansione, solo in oldbuckets, indica che l'elemento è stato trasferito alla metà superiore del nuovo array di bucket evacuatedY = 3 // appare durante l'espansione, solo in oldbuckets, indica che l'elemento è stato trasferito alla metà inferiore del nuovo array di bucket evacuatedEmpty = 4 // appare durante l'espansione, l'elemento era vuoto ed è stato marcato durante il trasferimento minTopHash = 5 // valore minimo di tophash per una chiave normale )Se il valore di
tophash[i]è maggiore diminTopHash, significa che esiste una chiave-valore normale all'indice corrispondente.keys: array che memorizza chiavi del tipo specificato.elems: array che memorizza valori del tipo specificato.overflow: puntatore al bucket di overflow.
Poiché le chiavi non possono essere accessibili direttamente tramite i campi della struttura, Go dichiara in anticipo una costante dataoffset, che rappresenta l'offset di memoria dei dati in bmap:
const dataOffset = unsafe.Offsetof(struct {
b bmap
v int64
}{}.v)In realtà, le chiavi e i valori sono memorizzati in un indirizzo di memoria continuo, simile alla seguente struttura. Questo è fatto per evitare sprechi di spazio dovuti all'allineamento della memoria:
k1,k2,k3,k4,k5,k6...v1,v2,v3,v4,v5,v6...Quindi, per un bmap, spostando il puntatore di dataoffset e poi di i*sizeof(keyType) si ottiene l'indirizzo della i-esima chiave:
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))Allo stesso modo, per ottenere l'indirizzo del i-esimo valore:
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))Il puntatore buckets in hmap punta al primo bucket hash. Per ottenere l'indirizzo del i-esimo bucket hash, l'offset è i*sizeof(bucket):
b := (*bmap)(add(h.buckets, i*uintptr(t.BucketSize)))Queste operazioni appariranno molto frequentemente nei contenuti successivi.
Hash
Conflitti
In hmap, c'è un campo extra dedicato a memorizzare le informazioni sui bucket di overflow. Punta alla slice che contiene i bucket di overflow, la cui struttura è la seguente:
type mapextra struct {
// slice di puntatori ai bucket di overflow
overflow *[]*bmap
// slice di puntatori ai vecchi bucket di overflow prima dell'espansione
oldoverflow *[]*bmap
// puntatore al prossimo bucket di overflow libero
nextOverflow *bmap
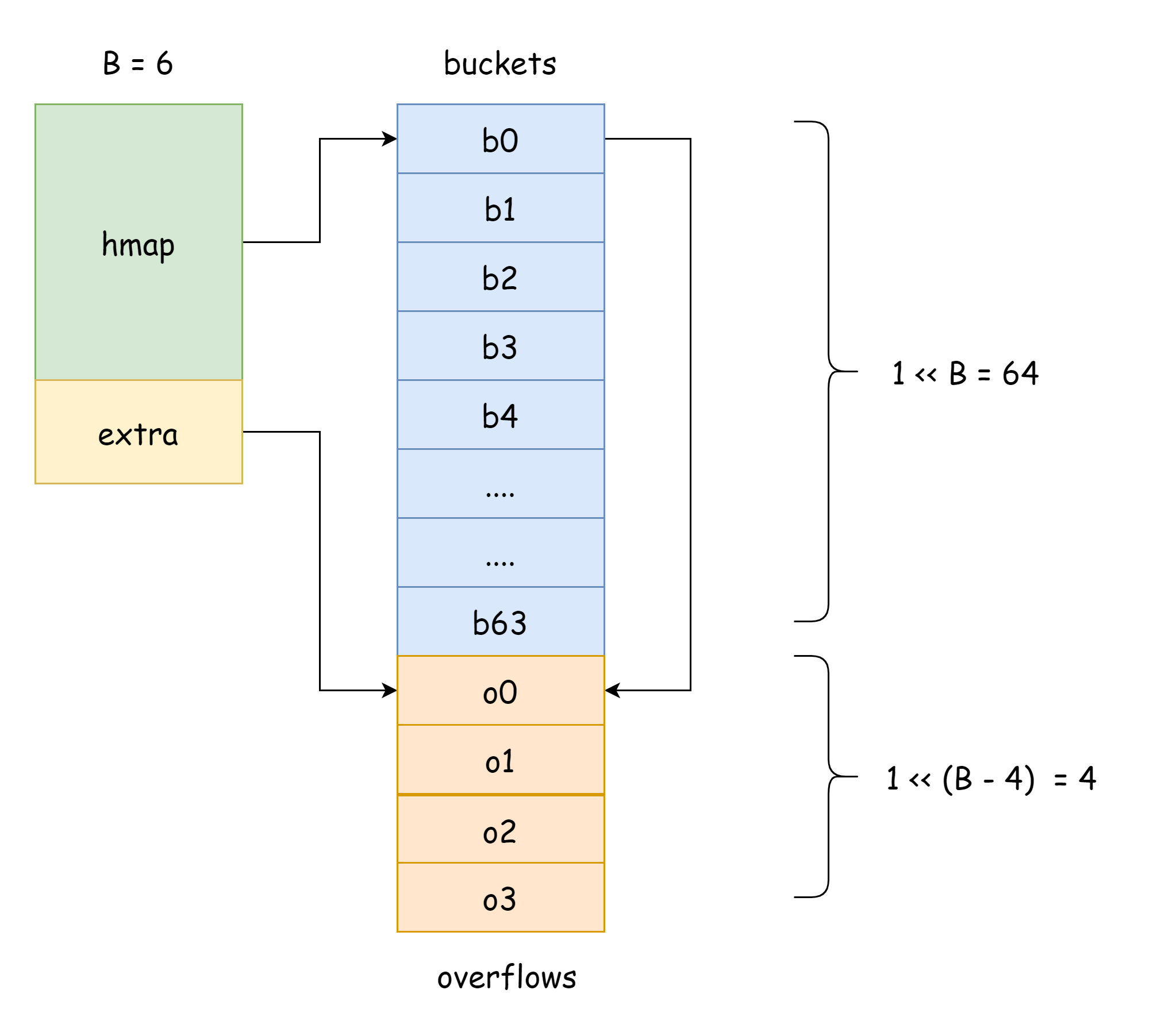
}
TIP
Nella figura sopra, la parte blu è l'array di bucket hash, la parte arancione è l'array di bucket di overflow hash. I bucket di overflow saranno chiamati semplicemente bucket di overflow di seguito.
La figura sopra mostra bene la struttura approssimativa di hmap: buckets punta all'array di bucket hash, extra punta all'array di bucket di overflow, il bucket bucket0 punta al bucket di overflow overflow0. Due tipi diversi di bucket sono memorizzati in due slice separate, e la memoria di entrambi i tipi di bucket è continua. Quando due chiavi vengono assegnate allo stesso bucket dopo l'hashing, si verifica un conflitto hash. Go risolve i conflitti hash con il chaining. Quando il numero di chiavi in conflitto supera la capacità del bucket (generalmente 8, valore che dipende da internal/abi.MapBucketCount), viene creato un nuovo bucket per memorizzare queste chiavi. Questo nuovo bucket è chiamato bucket di overflow, il che significa che il bucket originale non poteva più contenere gli elementi, che sono stati "traboccati" in questo nuovo bucket. Dopo la creazione, il bucket hash avrà un puntatore che punta al nuovo bucket di overflow. I puntatori di questi bucket formano una lista concatenata bmap.
Per il chaining, si usa il fattore di carico per misurare i conflitti della tabella hash, con la seguente formula:
loadfactor := len(elems) / len(buckets)Quando il fattore di carico è maggiore, ci sono più conflitti hash, cioè più bucket di overflow. Quindi, per leggere e scrivere la tabella hash, è necessario attraversare più liste di bucket di overflow per trovare la posizione specificata, il che riduce le prestazioni. Per migliorare questa situazione, si dovrebbe aumentare il numero di bucket, ovvero espandere la capacità. Per hmap, ci sono due condizioni che triggerano l'espansione:
- Il fattore di carico supera la soglia
bucketCnt*13/16, che è almeno 6.5. - Troppi bucket di overflow
Quando il fattore di carico è minore, significa che hmap ha un basso utilizzo della memoria e occupa più memoria. La funzione usata da Go per calcolare il fattore di carico è runtime.overLoadFactor:
func overLoadFactor(count int, B uint8) bool {
return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)
}Dove loadFactorNum e loadFactorDen sono costanti, bucketshift calcola 1 << B, e si sa che:
loadFactorNum = (bucketCnt * 13 / 16) * loadFactorDenQuindi semplificando si ottiene:
count > bucketCnt && uintptr(count) / 1 << B > (bucketCnt * 13 / 16)Dove (bucketCnt * 13 / 16) è 6.5, 1 << B è il numero di bucket hash. Quindi questa funzione serve a calcolare se il numero di elementi diviso il numero di bucket è maggiore del fattore di carico 6.5.
Calcolo
La funzione interna di Go per calcolare l'hash si trova nel file runtime/alg.go come f32hash:
func f32hash(p unsafe.Pointer, h uintptr) uintptr {
f := *(*float32)(p)
switch {
case f == 0:
return c1 * (c0 ^ h) // +0, -0
case f != f:
return c1 * (c0 ^ h ^ uintptr(fastrand())) // any kind of NaN
default:
return memhash(p, h, 4)
}
}Come si può vedere, il metodo di calcolo hash delle map non è basato sul tipo ma sulla memoria, e alla fine arriva alla funzione memhash, implementata in assembly, con la logica situata in runtime/asm*.s. I valori hash basati sulla memoria non dovrebbero essere persistiti, poiché dovrebbero essere usati solo a runtime; non è possibile garantire che la distribuzione della memoria sia identica ad ogni esecuzione.
Nello stesso file c'è anche una funzione chiamata typehash, che calcola i valori hash per diversi tipi, ma le map non usano questa funzione per calcolare l'hash:
func typehash(t *_type, p unsafe.Pointer, h uintptr) uintptrQuesta implementazione è più lenta di quella precedente, ma più generica, usata principalmente per la reflection e la generazione di funzioni a compile-time, ad esempio:
//go:linkname reflect_typehash reflect.typehash
func reflect_typehash(t *_type, p unsafe.Pointer, h uintptr) uintptr {
return typehash(t, p, h)
}Creazione
Ci sono due modi per inizializzare una map, come già illustrato nell'introduzione al linguaggio: uno è usare direttamente la parola chiave map, l'altro è usare la funzione make. Indipendentemente dal metodo usato, alla fine è runtime.makemap che crea la map. La firma della funzione è:
func makemap(t *maptype, hint int, h *hmap) *hmapDove i parametri sono:
t: il tipo della map, diversi tipi richiedono occupazioni di memoria diversehint: il secondo parametro della funzionemake, la capacità prevista degli elementi della maph: puntatore ahmap, può esserenil
Il valore di ritorno è un puntatore a hmap inizializzato. Durante il processo di inizializzazione, questa funzione svolge diversi lavori principali. Per prima cosa calcola se la memoria prevista per l'allocazione supera la memoria massima allocabile:
// Moltiplica la capacità prevista per la dimensione del tipo di bucket
mem, overflow := math.MulUintptr(uintptr(hint), t.Bucket.Size_)
// Overflow numerico o supera la memoria massima allocabile
if overflow || mem > maxAlloc {
hint = 0
}Come menzionato nella struttura interna, hmap è composto da bucket. Nel caso di minimo utilizzo della memoria, un bucket ha un solo elemento, occupando la massima memoria. Quindi l'occupazione massima prevista è il numero di elementi moltiplicato per l'occupazione di memoria del tipo corrispondente. Quando il risultato del calcolo overflowa o supera la memoria massima allocabile, hint viene impostato a 0, poiché successivamente hint sarà usato per calcolare la capacità dell'array di bucket.
Il secondo passo è inizializzare hmap e calcolare un seed hash casuale:
// Inizializza
if h == nil {
h = new(hmap)
}
// Ottieni un seed hash casuale
h.hash0 = fastrand()Poi calcola la capacità dei bucket hash in base al valore di hint:
B := uint8(0)
// Continua a iterare finché hint / 1 << B < 6.5
for overLoadFactor(hint, B) {
B++
}
// Assegna a hmap
h.B = BIterando continuamente trova il primo valore B che soddisfa (hint / 1 << B) < 6.5 e lo assegna a hmap. Saputa la capacità dei bucket hash, infine alloca memoria per i bucket hash:
if h.B != 0 {
var nextOverflow *bmap
// Bucket hash allocati e bucket di overflow liberi preallocati
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
// Se sono stati preallocati bucket di overflow liberi, punta a questi
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}La funzione makeBucketArray alloca memoria di dimensione corrispondente in base al valore di B per i bucket hash e prealloca bucket di overflow liberi. Quando B è minore di 4, non vengono creati bucket di overflow; se maggiore di 4, vengono creati 2^B-4 bucket di overflow. Questo corrisponde al seguente codice nella funzione runtime.makeBucketArray:
base := bucketShift(b)
nbuckets := base
// Non crea bucket di overflow se minore di 4
if b >= 4 {
// Numero previsto di bucket più 1 << (b-4)
nbuckets += bucketShift(b - 4)
// Memoria necessaria per i bucket di overflow
sz := t.Bucket.Size_ * nbuckets
// Arrotonda per eccesso lo spazio di memoria
up := roundupsize(sz)
if up != sz {
// Se non uguali, ricalcola usando up
nbuckets = up / t.Bucket.Size_
}
}base è il numero previsto di bucket da allocare, nbuckets è il numero effettivo di bucket allocati, che include il numero di bucket di overflow.
if base != nbuckets {
// Primo bucket di overflow disponibile
nextOverflow = (*bmap)(add(buckets, base*uintptr(t.BucketSize)))
// Per ridurre il costo di tracciamento dei bucket di overflow, il puntatore di overflow dell'ultimo bucket di overflow disponibile punta all'inizio dei bucket hash
last := (*bmap)(add(buckets, (nbuckets-1)*uintptr(t.BucketSize)))
// L'ultimo bucket di overflow punta ai bucket hash
last.setoverflow(t, (*bmap)(buckets))
}Quando i due non sono uguali, significa che sono stati allocati bucket di overflow aggiuntivi. Il puntatore nextoverflow punta al primo bucket di overflow disponibile. Come si può vedere, i bucket hash e i bucket di overflow sono effettivamente nella stessa memoria continua. Questo è il motivo per cui nella figura l'array di bucket hash e l'array di bucket di overflow sono adiacenti.
Accesso
Come menzionato nell'introduzione alla sintassi, ci sono tre modi per accedere a una map:
# Accesso diretto al valore
val := dict[key]
# Accesso al valore e verifica se la chiave esiste
val, exist := dict[key]
# Iterazione sulla map
for key, val := range dict{
}Questi tre modi usano funzioni diverse. L'iterazione for range su una map è la più complessa.
Chiave-Valore
I primi due modi corrispondono a due funzioni: runtime.mapaccess1 e runtime.mapaccess2. Le firme delle funzioni sono:
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer
func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool)La chiave è un puntatore alla chiave di accesso della map, e il ritorno restituisce solo un puntatore. Durante l'accesso, per prima cosa si calcola il valore hash della chiave e si individua in quale bucket hash si trova la chiave:
// Gestione dei casi limite
if h == nil || h.count == 0 {
if t.HashMightPanic() {
t.Hasher(key, 0) // vedi issue 23734
}
return unsafe.Pointer(&zeroVal[0])
}
// Previene lettura e scrittura concorrente
if h.flags&hashWriting != 0 {
fatal("concurrent map read and map write")
}
// Usa hasher del tipo specificato per calcolare l'hash
hash := t.Hasher(key, uintptr(h.hash0))
// (1 << B) - 1
m := bucketMask(h.B)
// Sposta il puntatore per individuare il bucket hash della chiave
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.BucketSize)))All'inizio dell'accesso, gestisce i casi limite e previene la lettura/scrittura concorrente della map. Quando la map è in stato di lettura/scrittura concorrente, si verifica un panic. Poi calcola il valore hash. La funzione bucketMask calcola (1 << B) - 1, quindi hash & m equivale a hash & (1 << B) - 1, che è un'operazione di modulo binario, equivalente a hash % (1 << B). Usare operazioni bit a bit è più veloce. Le ultime tre righe di codice calcolano il numero del bucket hash prendendo il valore hash ottenuto dalla chiave modulo il numero di bucket nella map corrente, quindi spostano il puntatore in base al numero per ottenere il puntatore al bucket hash della chiave.
Saputo in quale bucket hash si trova la chiave, si può procedere con la ricerca:
// Ottieni gli otto bit più alti del valore hash
top := tophash(hash)
bucketloop:
// Itera sulla lista concatenata bmap
for ; b != nil; b = b.overflow(t) {
// Elementi in bmap
for i := uintptr(0); i < bucketCnt; i++ {
// Confronta top calcolato con gli elementi in tophash
if b.tophash[i] != top {
// I successivi sono tutti vuoti, non c'è più nulla.
if b.tophash[i] == emptyRest {
break bucketloop
}
// Se non uguali, continua a iterare sui bucket di overflow
continue
}
// Sposta il puntatore per ottenere la chiave all'indice corrispondente
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
// Gestisci il puntatore
if t.IndirectKey() {
k = *((*unsafe.Pointer)(k))
}
// Confronta se le due chiavi sono uguali
if t.Key.Equal(key, k) {
// Se uguali, sposta il puntatore per restituire l'elemento corrispondente a k
// Da questa riga si può vedere che gli indirizzi di memoria di chiavi e valori sono continui
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
if t.IndirectElem() {
e = *((*unsafe.Pointer)(e))
}
return e
}
}
}
// Non trovato, restituisce il valore zero.
return unsafe.Pointer(&zeroVal[0])Nel localizzare il bucket hash, si usa il modulo, quindi in quale bucket si trova la chiave dipende dai bit bassi del valore hash. Quanti bit bassi dipendono dalla dimensione di B. Trovato il bucket hash, tophash memorizza gli otto bit più alti del valore hash. Poiché i valori del modulo dei bit bassi sono gli stessi, non è necessario confrontare le chiavi una per una; basta confrontare gli otto bit più alti del valore hash. In base al valore hash calcolato, si ottengono gli otto bit più alti e si confrontano uno per uno con l'array tophash in bmap. Se gli otto bit più alti sono uguali, si confronta se le chiavi sono uguali. Se anche le chiavi sono uguali, significa che è stato trovato l'elemento. Se non sono uguali, si continua a iterare sull'array tophash. Se ancora non si trova, si continua a iterare sulla lista concatenata bmap dei bucket di overflow, fino a quando tophash[i] di bmap è emptyRest, si esce dal ciclo. Infine, si restituisce il valore zero del tipo corrispondente.
La funzione mapaccess2 ha la stessa logica di mapaccess1, solo con un valore di ritorno booleano in più per indicare se l'elemento esiste.
Iterazione
La sintassi per iterare su una map è:
for key, val := range dict {
// do somthing...
}Durante l'iterazione effettiva, Go usa la struttura hiter per memorizzare le informazioni di iterazione. hiter è l'abbreviazione di hmap iterator, ovvero iteratore di tabella hash:
// A hash iteration structure.
// If you modify hiter, also change cmd/compile/internal/reflectdata/reflect.go
// and reflect/value.go to match the layout of this structure.
type hiter struct {
key unsafe.Pointer // Deve essere in prima posizione. Scrivere nil per indicare la fine dell'iterazione (vedi cmd/compile/internal/walk/range.go).
elem unsafe.Pointer // Deve essere in seconda posizione (vedi cmd/compile/internal/walk/range.go).
t *maptype
h *hmap
buckets unsafe.Pointer // puntatore al bucket al momento dell'inizializzazione dell'iteratore
bptr *bmap // bucket corrente
overflow *[]*bmap // mantiene vivi i bucket di overflow di hmap.buckets
oldoverflow *[]*bmap // mantiene vivi i bucket di overflow di hmap.oldbuckets
startBucket uintptr // bucket da cui è iniziata l'iterazione
offset uint8 // offset intra-bucket da cui iniziare durante l'iterazione (deve essere abbastanza grande da contenere bucketCnt-1)
wrapped bool // già tornato dall'inizio dell'array di bucket alla fine
B uint8
i uint8
bucket uintptr
checkBucket uintptr
}Di seguito alcune spiegazioni sui campi:
key,elem: sono la chiave e il valore ottenuti durante l'iterazionefor rangebuckets: specificato durante l'inizializzazione dell'iteratore, punta all'inizio dei bucket hashbptr: il bmap attualmente in iterazionestartBucket: numero del bucket di inizio all'inizio dell'iterazioneoffset: offset intra-bucket, intervallo[0, bucketCnt-1]B: è il valore B di hmapi: indice dell'elemento intra-bucketwrapped: se è tornato dalla fine dell'array di bucket hash all'inizio
Prima di iniziare l'iterazione, Go inizializza l'iteratore tramite la funzione runtime.mapiterinit, poi itera sulla map tramite la funzione runtime.mapiternext. Entrambe le funzioni usano la struttura hiter. Le firme delle funzioni sono:
func mapiterinit(t *maptype, h *hmap, it *hiter)
func mapiternext(it *hiter)Per l'inizializzazione dell'iteratore, per prima cosa si ottiene uno snapshot corrente della map:
it.t = t
it.h = h
// Registra uno snapshot dello stato corrente di hmap, basta salvare il valore B.
it.B = h.B
it.buckets = h.buckets
if t.Bucket.PtrBytes == 0 {
h.createOverflow()
it.overflow = h.extra.overflow
it.oldoverflow = h.extra.oldoverflow
}Durante l'iterazione successiva, si itera effettivamente su uno snapshot della map, non sulla map effettiva. Quindi gli elementi e i bucket aggiunti durante l'iterazione non verranno iterati, e la scrittura concorrente durante l'iterazione potrebbe triggerare un fatal:
if h.flags&hashWriting != 0 {
fatal("concurrent map iteration and map write")
}Il secondo passo è decidere due posizioni di inizio per l'iterazione: la prima è la posizione del bucket di inizio, la seconda è la posizione di inizio intra-bucket. Entrambe sono scelte casualmente:
// r è un numero casuale
var r uintptr
if h.B > 31-bucketCntBits {
r = uintptr(fastrand64())
} else {
r = uintptr(fastrand())
}
// r % (1 << B) ottiene la posizione del bucket di inizio
it.startBucket = r & bucketMask(h.B)
// r >> B % 8 ottiene la posizione di inizio dell'elemento intra-bucket
it.offset = uint8(r >> h.B & (bucketCnt - 1))
// Registra il numero del bucket attualmente in iterazione
it.bucket = it.startBucketOttiene un numero casuale tramite fastrand() o fastrand64(), e due operazioni di modulo ottengono la posizione di inizio del bucket e la posizione di inizio intra-bucket.
TIP
Le map non permettono la lettura/scrittura concorrente simultanea, ma permettono l'iterazione concorrente simultanea.
Poi inizia effettivamente l'iterazione della map, come iterare sui bucket e la strategia di uscita:
// hmap
h := it.h
// maptype
t := it.t
// Posizione del bucket da iterare
bucket := it.bucket
// bmap attualmente in iterazione
b := it.bptr
// Indice intra-bucket i
i := it.i
next:
if b == nil {
// Se la posizione del bucket corrente è uguale alla posizione di inizio, significa che è tornato al punto di partenza, il resto è già stato iterato
// Iterazione terminata, si può uscire
if bucket == it.startBucket && it.wrapped {
it.key = nil
it.elem = nil
return
}
// Sposta l'indice del bucket in avanti
bucket++
// bucket == 1 << B, significa che è arrivata alla fine dell'array di bucket hash
if bucket == bucketShift(it.B) {
// Ricomincia dall'inizio
bucket = 0
it.wrapped = true
}
i = 0
}La posizione di inizio dei bucket hash è scelta casualmente. Durante l'iterazione, si itera dalla posizione di inizio verso la fine della slice di bucket uno per uno. Quando si arriva a 1 << B, si ricomincia dall'inizio. Quando si torna alla posizione di inizio, significa che l'iterazione è completata e si esce. Il codice sopra riguarda come iterare sui bucket in una map. Il codice seguente descrive come iterare all'interno di un bucket:
for ; i < bucketCnt; i++ {
// (i + offset) % 8
offi := (i + it.offset) & (bucketCnt - 1)
// Se l'elemento corrente è vuoto, salta
if isEmpty(b.tophash[offi]) || b.tophash[offi] == evacuatedEmpty {
continue
}
// Sposta il puntatore per ottenere la chiave
k := add(unsafe.Pointer(b), dataOffset+uintptr(offi)*uintptr(t.KeySize))
if t.IndirectKey() {
k = *((*unsafe.Pointer)(k))
}
// Sposta il puntatore per ottenere il valore
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+uintptr(offi)*uintptr(t.ValueSize))
// Gestisci il caso di espansione di stessa dimensione. Quando la chiave-valore è stata疏散ata in altre posizioni, è necessario cercare nuovamente la chiave-valore.
if (b.tophash[offi] != evacuatedX && b.tophash[offi] != evacuatedY) ||
!(t.ReflexiveKey() || t.Key.Equal(k, k)) {
it.key = k
if t.IndirectElem() {
e = *((*unsafe.Pointer)(e))
}
it.elem = e
} else {
rk, re := mapaccessK(t, h, k)
if rk == nil {
continue
}
it.key = rk
it.elem = re
}
it.bucket = bucket
it.i = i + 1
return
}
// Se non trovato, cerca nei bucket di overflow
b = b.overflow(t)
i = 0
goto nextTIP
Nella condizione di判断 dell'espansione sopra, un'espressione potrebbe creare confusione:
t.Key.Equal(k, k)Il motivo per判断 se k è uguale a se stesso è per filtrare il caso in cui la chiave è Nan. Se la chiave di un elemento è Nan, non sarà possibile accedere normalmente a quell'elemento, né durante l'iterazione né durante l'accesso diretto o l'eliminazione, perché Nan != Nan è sempre vero, quindi non sarà mai possibile trovare questa chiave.
Per prima cosa, tramite l'operazione di modulo tra il valore i e offset, si ottiene l'indice intra-bucket da iterare. Spostando il puntatore si ottengono le chiavi e i valori. Poiché durante l'iterazione della map ci possono essere altre operazioni di scrittura che triggerano l'espansione della map, la chiave-valore effettiva potrebbe non essere più nella posizione originale. In questo caso, è necessario usare la funzione mapaccessK per ottenere nuovamente la chiave-valore effettiva. La firma di questa funzione è:
func mapaccessK(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, unsafe.Pointer)La sua funzione è completamente identica a mapaccess1, con la differenza che mapaccessK restituisce sia il valore della chiave che il valore. Alla fine, ottenute le chiavi e i valori, li assegna a key e elem dell'iteratore, poi aggiorna l'indice dell'iteratore. Così si completa un'iterazione e l'esecuzione del codice torna al blocco di codice for range. Se non si trova nel bucket, si cerca nei bucket di overflow, ripetendo i passaggi sopra. Finché l'iterazione della lista concatenata dei bucket di overflow non è completata, si continua a iterare sul prossimo bucket hash.
Modifica
La sintassi per modificare una map è:
dict[key] = valIn Go, l'operazione di modifica di una map è completata dalla funzione runtime.mapassign:
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.PointerLa logica del processo di accesso è la stessa di mapaccess1, ma quando la chiave non esiste, le viene assegnata una posizione; se esiste, viene aggiornata. Infine, restituisce un puntatore all'elemento. All'inizio, è necessario fare alcuni preparativi:
// Non permette la scrittura su map nil
if h == nil {
panic(plainError("assignment to entry in nil map"))
}
// Vieta la scrittura concorrente simultanea
if h.flags&hashWriting != 0 {
fatal("concurrent map writes")
}
// Calcola il valore hash della chiave
hash := t.Hasher(key, uintptr(h.hash0))
// Modifica lo stato di hmap
h.flags ^= hashWriting
// Inizializza i bucket hash
if h.buckets == nil {
h.buckets = newobject(t.Bucket) // newarray(t.Bucket, 1)
}Il codice sopra fa le seguenti cose:
- Controllo dello stato di hmap
- Calcolo del valore hash della chiave
- Controllo se i bucket hash devono essere inizializzati
Poi, tramite il valore hash e l'operazione di modulo, si ottiene la posizione del bucket hash e il tophash della chiave:
again:
// hash % (1 << B)
bucket := hash & bucketMask(h.B)
// Sposta il puntatore per ottenere il bmap nella posizione specificata
b := (*bmap)(add(h.buckets, bucket*uintptr(t.BucketSize)))
// Calcola tophash
top := tophash(hash)Ora determinata la posizione del bucket, bmap e tophash, si può iniziare a cercare l'elemento:
// tophash da inserire
var inserti *uint8
// Puntatore al valore della chiave da inserire
var insertk unsafe.Pointer
// Puntatore al valore del valore da inserire
var elem unsafe.Pointer
bucketloop:
for {
// Itera sull'array tophash nel bucket
for i := uintptr(0); i < bucketCnt; i++ {
// tophash non uguale
if b.tophash[i] != top {
// Se l'indice corrente nel bucket è vuoto e non è stato ancora inserito un elemento, seleziona questa posizione per l'inserimento
if isEmpty(b.tophash[i]) && inserti == nil {
// Trovata una posizione adatta per assegnare alla chiave
inserti = &b.tophash[i]
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
}
// Se l'iterazione è completata, esci dal ciclo
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
// Se tophash è uguale, significa che la chiave potrebbe già esistere
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
if t.IndirectKey() {
k = *((*unsafe.Pointer)(k))
}
//判断 se la chiave è uguale
if !t.Key.Equal(key, k) {
continue
}
// Se è necessario aggiornare il valore della chiave, copia la memoria della chiave in k
if t.NeedKeyUpdate() {
typedmemmove(t.Key, k, key)
}
// Ottieni il puntatore all'elemento
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
// Aggiornamento completato, restituisci il puntatore all'elemento
goto done
}
// Se arrivato qui significa che non è stata trovata la chiave, itera sulla lista concatenata dei bucket di overflow e continua a cercare
ovf := b.overflow(t)
if ovf == nil {
break
}
b = ovf
}
// Se arrivato qui significa che la chiave non esiste nella map, ma potrebbe essere stata trovata una posizione adatta per la chiave, o potrebbe non esserlo
// Non è stata trovata una posizione adatta per la chiave
if inserti == nil {
// Significa che il bucket hash corrente e i suoi bucket di overflow sono pieni, alloca un nuovo bucket di overflow
newb := h.newoverflow(t, b)
// Assegna una posizione per la chiave nel bucket di overflow
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
elem = add(insertk, bucketCnt*uintptr(t.KeySize))
}
// Se memorizza un puntatore alla chiave
if t.IndirectKey() {
// Alloca nuova memoria, restituisce un puntatore unsafe
kmem := newobject(t.Key)
*(*unsafe.Pointer)(insertk) = kmem
// Assegna a insertk per facilitare la copia della memoria della chiave successivamente
insertk = kmem
}
// Se memorizza un puntatore all'elemento
if t.IndirectElem() {
// Alloca memoria
vmem := newobject(t.Elem)
// Fa puntare il puntatore a vmem
*(*unsafe.Pointer)(elem) = vmem
}
// Copia direttamente la memoria della chiave nella posizione di insertk
typedmemmove(t.Key, insertk, key)
*inserti = top
// Incrementa il conteggio di uno
h.count++
done:
// Se arrivato qui significa che il processo di modifica è completato
if h.flags&hashWriting == 0 {
fatal("concurrent map writes")
}
h.flags &^= hashWriting
if t.IndirectElem() {
elem = *((*unsafe.Pointer)(elem))
}
// Restituisce il puntatore all'elemento
return elemNel grande blocco di codice sopra, per prima cosa entra nel ciclo for e cerca nel bucket hash e nei bucket di overflow. La logica di ricerca è completamente identica a mapaccess. A questo punto ci sono tre possibilità:
- Primo, trova una chiave già esistente nella map, salta direttamente al blocco di codice
donee restituisce il puntatore all'elemento - Secondo, trova una posizione nella map da assegnare alla chiave, copia la chiave nella posizione specificata e restituisce il puntatore all'elemento
- Terzo, tutti i bucket sono stati cercati, non è stata trovata una posizione da assegnare alla chiave nella map, crea un nuovo bucket di overflow, assegna la chiave nel bucket, poi copia la chiave nella posizione specificata e restituisce il puntatore all'elemento
Alla fine, ottenuto il puntatore all'elemento, si può assegnare il valore. Tuttavia, questa operazione non è completata dalla funzione mapassign, che si occupa solo di restituire il puntatore all'elemento. L'operazione di assegnazione è inserita durante la compilazione, non visibile nel codice, ma visibile nel codice compilato. Supponiamo di avere il seguente codice:
func main() {
dict := make(map[string]string, 100)
dict["hello"] = "world"
}Tramite il comando seguente si ottiene il codice assembly:
go tool compile -S -N -l main.goLe parti chiave sono queste:
0x004e 00078 LEAQ type:map[string]string(SB), AX
0x0055 00085 CALL runtime.mapassign_faststr(SB)
0x005a 00090 MOVQ AX, main..autotmp_2+40(SP)
0x0083 00131 LEAQ go:string."world"(SB), CX
0x008a 00138 MOVQ CX, (AX)Come si può vedere, chiama runtime.mapassign_faststr, la cui logica è completamente simile a mapassign. LEAQ go:string."world"(SB), CX memorizza l'indirizzo della stringa su CX, MOVQ CX, (AX) lo memorizza su AX, completando così l'assegnazione dell'elemento.
Eliminazione
In Go, per eliminare un elemento di una map, si può usare solo la funzione built-in delete:
delete(dict, "abc")Internamente chiama la funzione runtime.mapdelete:
func mapdelete(t *maptype, h *hmap, key unsafe.Pointer)Elimina l'elemento con la chiave specificata nella map. Indipendentemente dal fatto che l'elemento esista o meno nella map, non reagirà in alcun modo. La logica dei preparativi all'inizio della funzione è simile,无非 le seguenti cose:
- Controllo dello stato di hmap
- Calcolo del valore hash della chiave
- Localizzazione del bucket hash
- Calcolo di tophash
Ci sono molti contenuti ripetuti prima, non li ripeterò. Qui mi concentro solo sulla logica di eliminazione. La parte corrispondente del codice è la seguente:
bOrig := b
search:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
// Se non trovato, esci dal ciclo
if b.tophash[i] == emptyRest {
break search
}
continue
}
// Sposta il puntatore per trovare la posizione della chiave
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
k2 := k
if t.IndirectKey() {
k2 = *((*unsafe.Pointer)(k2))
}
if !t.Key.Equal(key, k2) {
continue
}
// Elimina la chiave
if t.IndirectKey() {
*(*unsafe.Pointer)(k) = nil
} else if t.Key.PtrBytes != 0 {
memclrHasPointers(k, t.Key.Size_)
}
// Sposta il puntatore per trovare la posizione dell'elemento
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
// Elimina l'elemento
if t.IndirectElem() {
*(*unsafe.Pointer)(e) = nil
} else if t.Elem.PtrBytes != 0 {
memclrHasPointers(e, t.Elem.Size_)
} else {
memclrNoHeapPointers(e, t.Elem.Size_)
}
notLast:
// Decrementa il conteggio di uno
h.count--
// Reimposta il seed hash, riduce la probabilità di conflitti
if h.count == 0 {
h.hash0 = fastrand()
}
break search
}
}Come si può vedere dal codice sopra, la logica di ricerca è quasi completamente identica alle operazioni precedenti. Trova l'elemento, poi lo elimina, decrementa il conteggio registrato da hmap di uno. Quando il conteggio scende a 0, reimposta il seed hash.
Un altro punto da notare è che dopo aver eliminato l'elemento, è necessario modificare lo stato tophash dell'indice corrente. La parte corrispondente del codice è la seguente. Quando i è alla fine del bucket,判断 in base al prossimo bucket di overflow se l'elemento corrente è l'ultimo elemento disponibile. Altrimenti, controlla direttamente lo stato hash degli elementi adiacenti. Se l'elemento corrente non è l'ultimo disponibile, imposta lo stato a emptyOne:
// Marca il tophash corrente come vuoto
b.tophash[i] = emptyOne
// Se alla fine di tophash
if i == bucketCnt-1 {
// Se il bucket di overflow non è vuoto e contiene elementi, significa che l'elemento corrente non è l'ultimo
if b.overflow(t) != nil && b.overflow(t).tophash[0] != emptyRest {
goto notLast
}
} else {
// Se l'elemento adiacente non è vuoto
if b.tophash[i+1] != emptyRest {
goto notLast
}
}Se l'elemento è effettivamente l'ultimo elemento, è necessario correggere i valori dell'array tophash di alcuni bucket nella lista concatenata dei bucket. Altrimenti, durante le iterazioni successive, non sarà possibile uscire nella posizione corretta. Quando si crea un bucket di overflow in una map, è stato detto che Go, per ridurre il costo di tracciamento dei bucket di overflow, il puntatore overflow dell'ultimo bucket di overflow punta al bucket hash iniziale. Quindi è effettivamente una lista concatenata circolare singola. La "testa" della lista concatenata è il bucket hash. Qui b è il bmap dopo la ricerca, molto probabilmente uno qualsiasi nella metà della lista concatenata. Itera all'indietro sulla lista concatenata circolare per cercare l'ultimo elemento esistente. Sebbene il codice scriva un'iterazione in avanti, poiché la lista concatenata è un anello, continua a iterare in avanti fino al bucket precedente al bucket di overflow corrente. Dal risultato, è effettivamente all'indietro. Poi itera all'indietro sull'array tophash nel bucket, aggiornando gli elementi con stato emptyOne a emptyRest, fino a trovare l'ultimo elemento esistente. Per evitare di rimanere bloccati all'infinito nell'anello, quando si torna al bucket iniziale, cioè bOrig, significa che non ci sono più elementi disponibili nella lista concatenata, e si può uscire dal ciclo:
// Se arrivato qui significa che non ci sono elementi dopo l'elemento corrente
// Itera continuamente all'indietro sulla lista concatenata bmap, all'indietro sull'array tophash nel bucket
// Aggiorna gli elementi con stato emptyOne a emptyRest
for {
b.tophash[i] = emptyRest
if i == 0 {
if b == bOrig {
break
}
c := b
// Trova il precedente nella lista bmap corrente
for b = bOrig; b.overflow(t) != c; b = b.overflow(t) {
}
i = bucketCnt - 1
} else {
i--
}
if b.tophash[i] != emptyOne {
break
}
}Pulizia
Nella versione go1.21, è stata aggiunta la funzione built-in clear, che può essere usata per pulire tutti gli elementi in una map:
clear(dict)Internamente chiama la funzione runtime.mapclear, che si occupa di eliminare tutti gli elementi nella map. La firma della funzione è:
func mapclear(t *maptype, h *hmap)La logica di questa funzione non è complessa. Per prima cosa è necessario marcare l'intera map come vuota:
// Itera su ogni bucket e bucket di overflow, imposta tutti gli elementi tophash a emptyRest
markBucketsEmpty := func(bucket unsafe.Pointer, mask uintptr) {
for i := uintptr(0); i <= mask; i++ {
b := (*bmap)(add(bucket, i*uintptr(t.BucketSize)))
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
b.tophash[i] = emptyRest
}
}
}
}
markBucketsEmpty(h.buckets, bucketMask(h.B))Il codice sopra itera su ogni bucket e imposta tutti gli elementi dell'array tophash nel bucket a emptyRest, marcando la map come vuota. Questo impedisce all'iteratore di continuare l'iterazione. Poi pulisce la map:
// Reimposta il seed hash
h.hash0 = fastrand()
// Reimposta la struttura extra
if h.extra != nil {
*h.extra = mapextra{}
}
// Questa operazione pulisce la memoria dei bucket precedenti e rialloca nuovi bucket
_, nextOverflow := makeBucketArray(t, h.B, h.buckets)
if nextOverflow != nil {
// Alloca nuovi bucket di overflow liberi
h.extra.nextOverflow = nextOverflow
}Tramite makeBucketArray pulisce la memoria dei bucket precedenti, poi ne alloca di nuovi. In questo modo si completa la pulizia dei bucket. Oltre a questo, ci sono alcuni dettagli, come impostare count a 0 e altre operazioni che non descriverò in dettaglio.
Espansione
In tutte le operazioni precedenti, per concentrarsi meglio sulla logica stessa, sono stati nascosti molti contenuti relativi all'espansione, il che semplifica molto le cose. La logica di espansione è in realtà piuttosto complessa. È posta alla fine per non creare interferenze. Ora vediamo come Go esegue l'espansione di una map. Come menzionato prima, ci sono due condizioni che triggerano l'espansione:
- Il fattore di carico supera 6.5
- Il numero di bucket di overflow è troppo elevato
La funzione per判断 se il fattore di carico supera la soglia è runtime.overLoadFactor, già illustrata nella parte sui conflitti hash. La funzione per判断 se il numero di bucket di overflow è troppo elevato è runtime.tooManyOverflowBuckets. Il suo principio di funzionamento è molto semplice:
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {
if B > 15 {
B = 15
}
return noverflow >= uint16(1)<<(B&15)
}Il codice sopra può essere semplificato nella seguente espressione, comprensibile a colpo d'occhio:
overflow >= 1 << (min(15,B) % 16)Qui, la definizione di "too many" da parte di Go è: il numero di bucket di overflow è circa uguale al numero di bucket hash. Se la soglia è bassa, si fa lavoro extra; se è alta, si occupa molta memoria durante l'espansione. Durante le operazioni di modifica ed eliminazione, è possibile triggerare l'espansione. Il codice per判断 se è necessaria l'espansione è il seguente:
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // Growing the table invalidates everything, so try again
}Come si può vedere, ci sono tre condizioni limitanti:
- Non deve essere in corso un'espansione
- Il fattore di carico deve essere minore di 6.5
- Il numero di bucket di overflow non deve essere troppo elevato
La funzione responsabile dell'espansione è naturalmente runtime.hashGrow:
func hashGrow(t *maptype, h *hmap)In realtà, l'espansione si divide in tipi diversi a seconda delle condizioni che la triggerano:
- Espansione incrementale
- Espansione di stessa dimensione
Espansione Incrementale
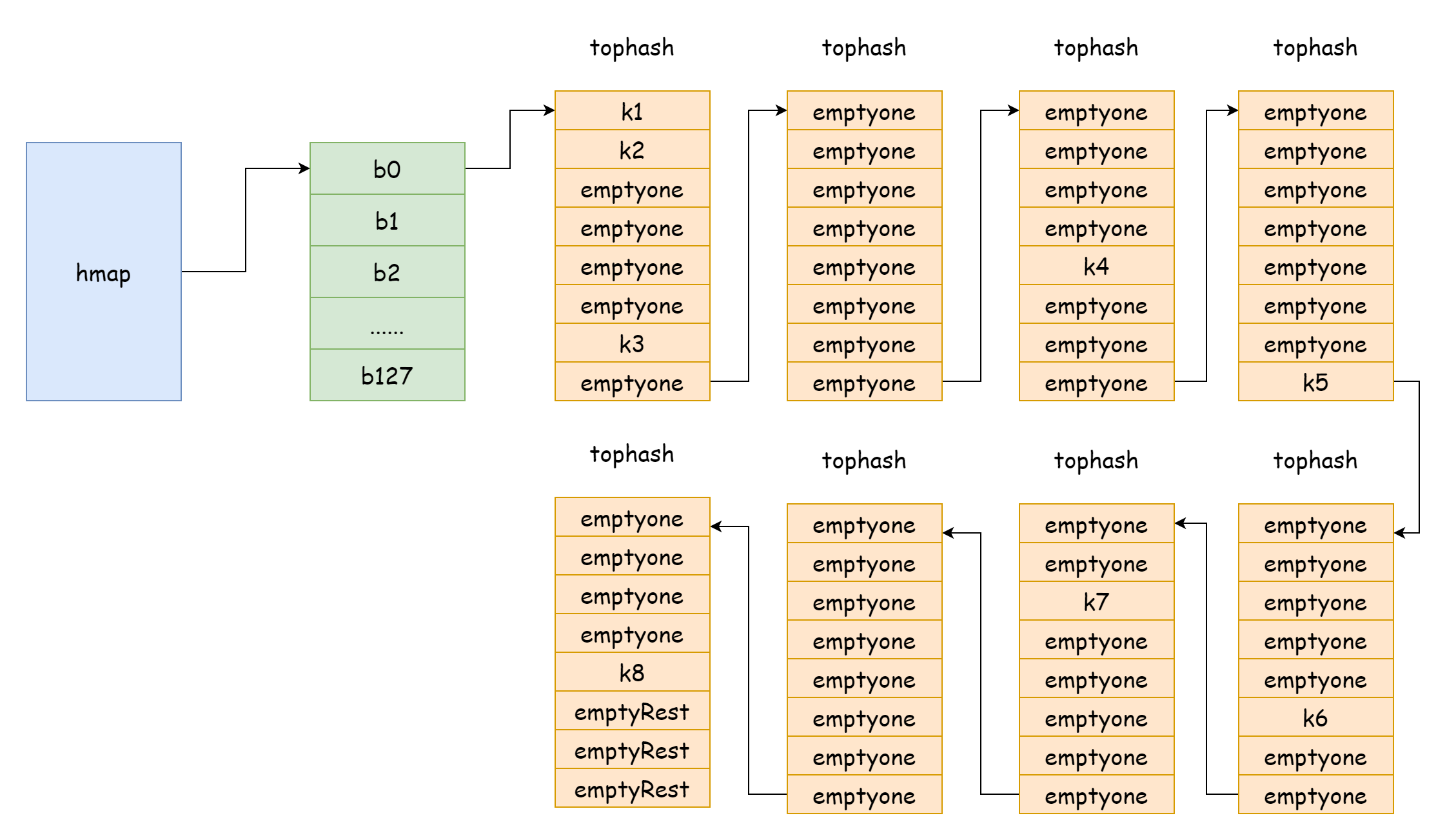
Quando il fattore di carico è troppo grande, cioè il numero di elementi è maggiore del numero di bucket hash, e i conflitti hash sono gravi, si formano molte liste concatenate di bucket di overflow. Questo porta a una diminuzione delle prestazioni di lettura e scrittura della map, perché per trovare un elemento è necessario iterare su più liste di bucket di overflow. Il tempo di iterazione è O(n). Il tempo di ricerca di una tabella hash dipende principalmente dal tempo di calcolo del valore hash e dal tempo di iterazione. Quando il tempo di iterazione è molto minore del tempo di calcolo dell'hash, la complessità temporale di ricerca può essere considerata O(1). Se i conflitti hash sono frequenti e troppe chiavi vengono assegnate allo stesso bucket hash, la lista concatenata di bucket di overflow troppo lunga aumenta il tempo di iterazione, portando a un aumento del tempo di ricerca. Poiché le operazioni di inserimento, eliminazione e modifica richiedono prima un'operazione di ricerca, questo porta a una grave diminuzione delle prestazioni dell'intera map.
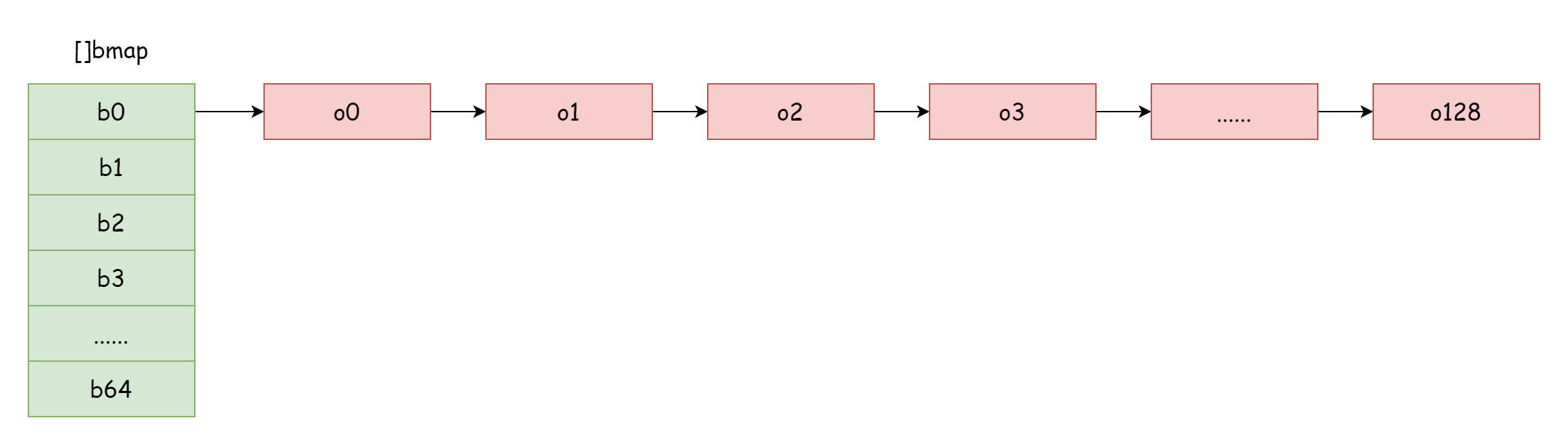
In una situazione estrema come quella nella figura, la complessità temporale di ricerca è praticamente uguale a O(n). Per affrontare questa situazione, la soluzione è aggiungere più bucket hash per evitare la formazione di liste concatenate di bucket di overflow troppo lunghe. Questo metodo è anche chiamato espansione incrementale.
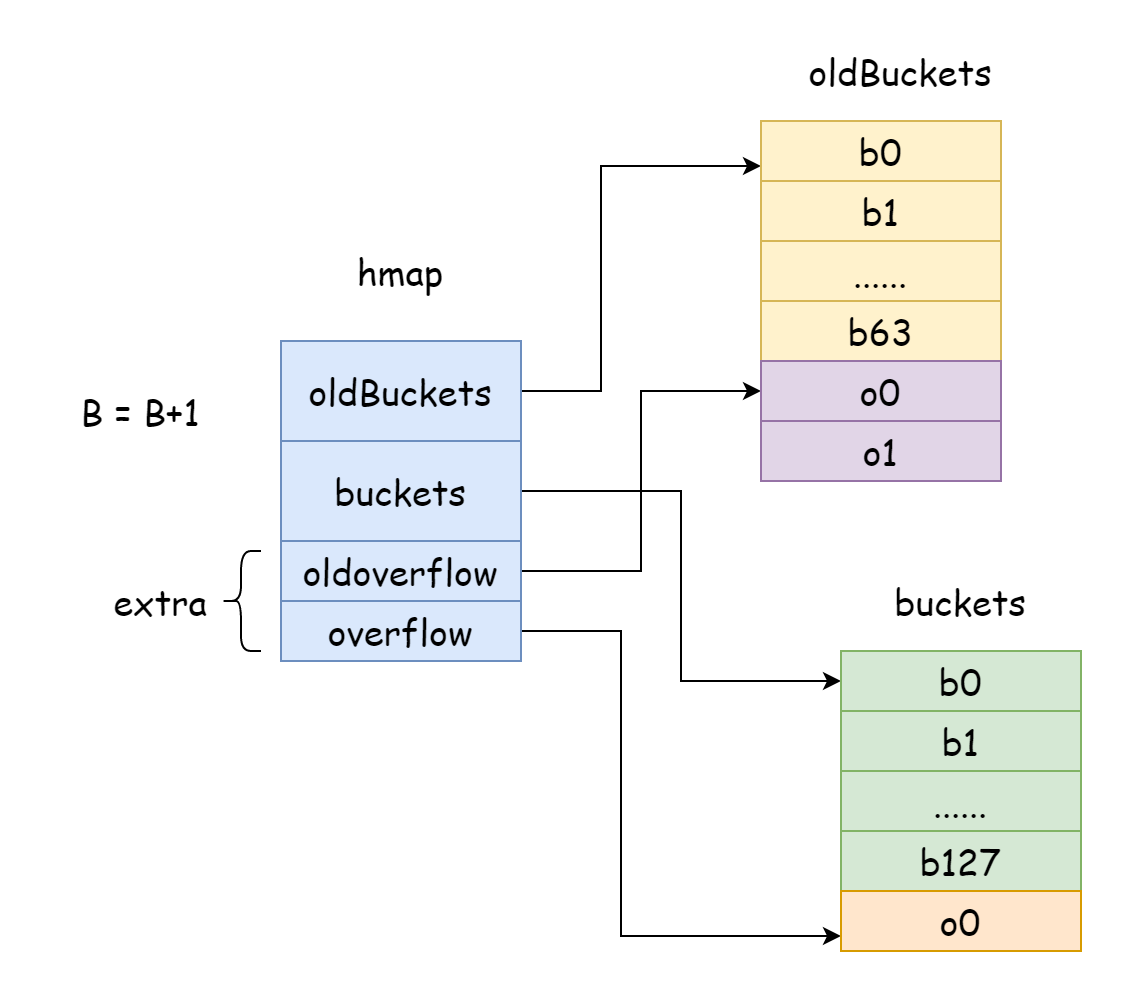
In Go, l'espansione incrementale aggiunge 1 a B ogni volta, cioè la scala dei bucket hash raddoppia ogni volta. Dopo l'espansione, è necessario trasferire i vecchi dati nella nuova map. Se il numero di elementi nella map è dell'ordine di decine di milioni o centinaia di milioni, trasferirli tutti in una volta richiederebbe molto tempo. Quindi Go adotta una strategia di trasferimento graduale. Per questo motivo, Go fa puntare oldBuckets in hamp all'array di bucket hash originale, indicando che questi sono i vecchi dati. Poi crea un array di bucket hash di capacità maggiore e fa puntare buckets in hmap al nuovo array di bucket hash. Durante ogni modifica ed eliminazione, trasferisce parzialmente gli elementi dai vecchi bucket ai nuovi bucket. Finché il trasferimento non è completato, la memoria dei vecchi bucket non viene rilasciata.
func hashGrow(t *maptype, h *hmap) {
// Differenza
bigger := uint8(1)
// Vecchi bucket
oldbuckets := h.buckets
// Nuovi bucket hash
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
flags := h.flags &^ (iterator | oldIterator)
if h.flags&iterator != 0 {
flags |= oldIterator
}
// B+bigger
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
h.nevacuate = 0
h.noverflow = 0
// Anche i bucket di overflow devono specificare vecchi e nuovi bucket
if h.extra != nil && h.extra.overflow != nil {
if h.extra.oldoverflow != nil {
throw("oldoverflow is not nil")
}
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
}
if nextOverflow != nil {
if h.extra == nil {
h.extra = new(mapextra)
}
h.extra.nextOverflow = nextOverflow
}
}Il codice sopra crea nuovi bucket hash con capacità doppia, poi specifica i riferimenti ai vecchi e nuovi bucket hash, nonché ai vecchi e nuovi bucket di overflow. Il lavoro effettivo di trasferimento non è completato dalla funzione hashGrow, che si occupa solo di specificare i vecchi e nuovi bucket e aggiornare alcuni stati di hmap. Questi lavori sono effettivamente completati dalla funzione runtime.growWork:
func growWork(t *maptype, h *hmap, bucket uintptr)Viene chiamata nelle funzioni mapassign e mapdelete nella seguente forma. Il suo ruolo è: se la map corrente è in espansione, esegue un trasferimento parziale:
if h.growing() {
growWork(t, h, bucket)
}Durante le operazioni di modifica ed eliminazione, è necessario判断 se si è in espansione. Questo è principalmente completato dal metodo hmap.growing, il cui contenuto è molto semplice:判断 se oldbuckets non è vuoto:
func (h *hmap) growing() bool {
return h.oldbuckets != nil
}Vediamo cosa fa la funzione growWork:
func growWork(t *maptype, h *hmap, bucket uintptr) {
// bucket % 1 << (B-1)
evacuate(t, h, bucket&h.oldbucketmask())
if h.growing() {
evacuate(t, h, h.nevacuate)
}
}L'operazione bucket&h.oldbucketmask() calcola la posizione del vecchio bucket, assicurandosi che il vecchio bucket da trasferire sia quello corrente. Come si può vedere dalla funzione, il lavoro effettivo di trasferimento è completato dalla funzione runtime.evacuate. Usa la struttura evaDst per rappresentare la destinazione del trasferimento. Il suo ruolo principale è iterare sui nuovi bucket durante il processo di trasferimento. La sua struttura è la seguente:
type evacDst struct {
b *bmap // Nuovo bucket di destinazione del trasferimento
i int // Indice intra-bucket
k unsafe.Pointer // Puntatore alla destinazione della nuova chiave
e unsafe.Pointer // Puntatore alla destinazione del nuovo valore
}Prima di iniziare il trasferimento, Go alloca due strutture evacDst, una punta alla metà superiore del nuovo bucket hash, l'altra punta alla metà inferiore del nuovo bucket hash:
// Localizza il bucket hash specificato nei vecchi bucket
b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.BucketSize)))
// Lunghezza dei vecchi bucket = 1 << (B - 1)
newbit := h.noldbuckets()
var xy [2]evacDst
x := &xy[0]
// Punta alla metà superiore del nuovo bucket
x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.BucketSize)))
x.k = add(unsafe.Pointer(x.b), dataOffset)
x.e = add(x.k, bucketCnt*uintptr(t.KeySize))
//判断 se è un'espansione di stessa dimensione
if !h.sameSizeGrow() {
y := &xy[1]
// Punta alla metà inferiore del nuovo bucket
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.BucketSize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.e = add(y.k, bucketCnt*uintptr(t.KeySize))
}La destinazione di trasferimento dei vecchi bucket sono due nuovi bucket. Dopo il trasferimento, parte dei dati del bucket sarà nella metà superiore e l'altra parte nella metà inferiore. Questo è fatto per sperare che i dati dopo l'espansione siano distribuiti più uniformemente. Più uniforme è la distribuzione, migliori saranno le prestazioni di ricerca della map. Come Go trasferisce i dati in due nuovi bucket corrisponde al codice seguente:
// Itera sulla lista concatenata dei bucket di overflow
for ; b != nil; b = b.overflow(t) {
// Ottieni la prima coppia chiave-valore di ogni bucket
k := add(unsafe.Pointer(b), dataOffset)
e := add(k, bucketCnt*uintptr(t.KeySize))
// Itera su ogni coppia chiave-valore nel bucket
for i := 0; i < bucketCnt; i, k, e = i+1, add(k, uintptr(t.KeySize)), add(e, uintptr(t.ValueSize)) {
top := b.tophash[i]
// Se vuoto, salta
if isEmpty(top) {
b.tophash[i] = evacuatedEmpty
continue
}
// Il nuovo bucket hash non dovrebbe essere in stato di trasferimento
// Altrimenti c'è sicuramente un problema
if top < minTopHash {
throw("bad map state")
}
k2 := k
if t.IndirectKey() {
k2 = *((*unsafe.Pointer)(k2))
}
// Questa variabile decide se la coppia chiave-valore corrente viene trasferita alla metà superiore o inferiore
// Il suo valore può essere solo 0 o 1
var useY uint8
if !h.sameSizeGrow() {
// Ricalcola il valore hash
hash := t.Hasher(k2, uintptr(h.hash0))
// Gestisci il caso speciale k2 != k2
if h.flags&iterator != 0 && !t.ReflexiveKey() && !t.Key.Equal(k2, k2) {
useY = top & 1
top = tophash(hash)
} else {
// hash % 1 << (B - 1)
if hash&newbit != 0 {
useY = 1
}
}
}
// Controlla il valore della costante
if evacuatedX+1 != evacuatedY || evacuatedX^1 != evacuatedY {
throw("bad evacuatedN")
}
// Aggiorna tophash del vecchio bucket, indicando che l'elemento corrente è stato trasferito
b.tophash[i] = evacuatedX + useY // evacuatedX + 1 == evacuatedY
// Specifica la destinazione del trasferimento
dst := &xy[useY] // destinazione di evacuazione
// Se la capacità del nuovo bucket non è sufficiente, crea un bucket di overflow
if dst.i == bucketCnt {
dst.b = h.newoverflow(t, dst.b)
dst.i = 0
dst.k = add(unsafe.Pointer(dst.b), dataOffset)
dst.e = add(dst.k, bucketCnt*uintptr(t.KeySize))
}
dst.b.tophash[dst.i&(bucketCnt-1)] = top // maschera dst.i come ottimizzazione, per evitare un controllo dei limiti
// Copia la chiave
if t.IndirectKey() {
*(*unsafe.Pointer)(dst.k) = k2 // copia puntatore
} else {
typedmemmove(t.Key, dst.k, k) // copia elemento
}
// Copia il valore
if t.IndirectElem() {
*(*unsafe.Pointer)(dst.e) = *(*unsafe.Pointer)(e)
} else {
typedmemmove(t.Elem, dst.e, e)
}
// Sposta il puntatore di destinazione del nuovo bucket in avanti, preparandosi per la prossima chiave-valore
dst.i++
dst.k = add(dst.k, uintptr(t.KeySize))
dst.e = add(dst.e, uintptr(t.ValueSize))
}
}Dal codice sopra si può vedere che Go itera su ogni elemento di ogni bucket nella lista concatenata dei vecchi bucket, trasferendo i dati nei nuovi bucket. Se i dati vanno nella metà superiore o inferiore dipende dal valore hash ricalcolato:
// hash % 1 << (B - 1)
if hash&newbit != 0 {
useY = 1
}Dopo il trasferimento, il tophash dell'elemento corrente viene impostato a evacuatedX o evacuatedY. Se si tenta di cercare dati durante l'espansione, questo stato indica che i dati sono stati trasferiti e si sa che bisogna cercare i dati corrispondenti nei nuovi bucket. Questa logica corrisponde al seguente codice nella funzione runtime.mapaccess1:
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
// C'erano la metà dei bucket; maschera un'altra potenza di due.
m >>= 1
}
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.BucketSize)))
// Se il vecchio bucket è già stato trasferito, non cercare più
if !evacuated(oldb) {
b = oldb
}
}Quando si accede a un elemento, se si è in stato di espansione, si prova prima a cercare nei vecchi bucket. Se i vecchi bucket sono già stati trasferiti, non si cerca più nei vecchi bucket. Tornando al trasferimento, ora determinata la destinazione del trasferimento, il prossimo passo è copiare i dati nel nuovo bucket, poi far puntare la struttura evacDst alla prossima destinazione:
dst := &xy[useY]
dst.b.tophash[dst.i&(bucketCnt-1)] = top
typedmemmove(t.Key, dst.k, k)
typedmemmove(t.Elem, dst.e, e)
if h.flags&oldIterator == 0 && t.Bucket.PtrBytes != 0 {
b := add(h.oldbuckets, oldbucket*uintptr(t.BucketSize))
ptr := add(b, dataOffset)
n := uintptr(t.BucketSize) - dataOffset
memclrHasPointers(ptr, n)
}Questa operazione continua finché il bucket corrente non è completamente trasferito. Poi Go pulisce tutti i dati chiave-valore del vecchio bucket, lasciando solo un array tophash del bucket hash (lasciato perché successivamente si basa sull'array tophash per判断 lo stato di trasferimento). La memoria dei bucket di overflow nei vecchi bucket, non essendo più referenziata, verrà recuperata dal GC successivamente. In hmap c'è un campo nevacuate usato per registrare il progresso del trasferimento. Ogni volta che un vecchio bucket hash viene trasferito, viene incrementato di uno. Quando il suo valore è uguale al numero di vecchi bucket, significa che l'espansione dell'intera map è completata. Successivamente, la funzione runtime.advanceEvacuationMark esegue il lavoro di收尾 dell'espansione:
func advanceEvacuationMark(h *hmap, t *maptype, newbit uintptr) {
h.nevacuate++
stop := h.nevacuate + 1024
if stop > newbit {
stop = newbit
}
for h.nevacuate != stop && bucketEvacuated(t, h, h.nevacuate) {
h.nevacuate++
}
if h.nevacuate == newbit { // newbit = len(oldbuckets)
h.oldbuckets = nil
if h.extra != nil {
h.extra.oldoverflow = nil
}
h.flags &^= sameSizeGrow
}
}Conta il numero trasferito e conferma se è uguale al numero di vecchi bucket. Se uguale, rimuove tutti i riferimenti ai vecchi bucket e ai vecchi bucket di overflow. A questo punto l'espansione è completata.
Nella funzione growWork, la funzione evacuate viene chiamata due volte in totale. La prima volta trasferisce il vecchio bucket del bucket attualmente in accesso, la seconda volta trasferisce il vecchio bucket puntato da h.nevacuate. In totale vengono trasferiti due bucket, il che significa che durante il trasferimento graduale, ogni volta vengono trasferiti due bucket.
Espansione di Stessa Dimensione
Come menzionato prima, la condizione di trigger per l'espansione di stessa dimensione è il numero eccessivo di bucket di overflow. Supponiamo che una map prima aggiunga un gran numero di elementi, poi elimini un gran numero di elementi. In questo caso, molti bucket potrebbero essere vuoti, mentre alcuni bucket potrebbero avere molti elementi. La distribuzione dei dati è molto不均匀, e molti bucket di overflow sono vuoti, occupando molta memoria. Per risolvere questo tipo di problema, è necessario creare una nuova map di stessa capacità, riallocare i bucket hash e ridistribuire gli elementi. Questo processo è chiamato espansione di stessa dimensione. Quindi in realtà non è un'operazione di espansione, ma una ridistribuzione di tutti gli elementi per rendere la distribuzione dei dati più uniforme. L'operazione di espansione di stessa dimensione è integrata nell'operazione di espansione incrementale, con la logica completamente identica e la capacità della nuova map uguale a quella vecchia.
Nella funzione hashGrow, se il fattore di carico non supera la soglia, viene eseguita l'espansione di stessa dimensione. Go aggiorna lo stato di h.flags a sameSizeGrow, e h.B non viene incrementato di uno. Quindi la capacità dei nuovi bucket hash creati non cambia:
bigger := uint8(1)
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
h.flags |= sameSizeGrow
}
oldbuckets := h.buckets
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)Nella funzione evacuate, quando si crea inizialmente la struttura eavcDst, se è un'espansione di stessa dimensione, viene creata solo una struttura che punta al nuovo bucket:
if !h.sameSizeGrow() {
y := &xy[1]
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.BucketSize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.e = add(y.k, bucketCnt*uintptr(t.KeySize))
}E durante il trasferimento degli elementi, l'espansione di stessa dimensione non ricalcola i valori hash e non c'è scelta tra metà superiore e inferiore:
if !h.sameSizeGrow() {
// Ricalcola il valore hash
hash := t.Hasher(k2, uintptr(h.hash0))
// Gestisci il caso speciale k2 != k2
if h.flags&iterator != 0 && !t.ReflexiveKey() && !t.Key.Equal(k2, k2) {
useY = top & 1
top = tophash(hash)
} else {
// hash % 1 << (B - 1)
if hash&newbit != 0 {
useY = 1
}
}
}A parte questo, le altre logiche sono completamente identiche all'espansione incrementale. Dopo l'espansione di stessa dimensione e la riallocazione dei bucket hash, il numero di bucket di overflow diminuisce. I vecchi bucket di overflow vengono recuperati dal GC.