map
Go 는 다른 언어와 달리 맵 지원이 map 키워드로 제공되며 표준 라이브러리로 캡슐화되지 않습니다. 맵은 사용 사례가 매우 많은 데이터 구조로, 다양한 구현 방식이 있으며 가장 일반적인 두 가지 방식은 레드블랙 트리와 해시 테이블입니다. Go 는 해시 테이블 구현 방식을 채택했습니다.
TIP
map 구현에는 많은 포인터 이동 작업이 포함되어 있으므로 본 문서를 읽으려면 unsafe 표준 라이브러리에 대한 지식이 필요합니다.
내부 구조
runtime.hmap 구조체는 Go 의 map 을 나타내며, 슬라이스처럼 map 의 내부 구현도 구조체입니다.
// A header for a Go map.
type hmap struct {
// Note: the format of the hmap is also encoded in cmd/compile/internal/reflectdata/reflect.go.
// Make sure this stays in sync with the compiler's definition.
count int // # live cells == size of map. Must be first (used by len() builtin)
flags uint8
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields
}영어 주석이 이미 매우 명확하게 설명하고 있으며, 아래에서 비교적 중요한 필드에 대해 간단히 설명하겠습니다.
count, hmap 의 요소 수를 나타내며, 결과는len(map)과 동일합니다.flags, hmap 의 플래그로, hmap 이 어떤 상태에 있는지 나타내는 데 사용되며 다음과 같은 가능성이 있습니다.goconst ( iterator = 1 // 이터레이터가 버킷 사용 중 oldIterator = 2 // 이터레이터가 이전 버킷 사용 중 hashWriting = 4 // 하나의 고루틴이 hmap 에 쓰기 중 sameSizeGrow = 8 // 동일 용량 확장 중 )B, hmap 의 해시 버킷 수가1 << B입니다.noverflow, hmap 의 오버플로 버킷 대략적인 수입니다.hash0, 해시 시드로, hmap 생성 시 지정되며 해시 값을 계산하는 데 사용됩니다.buckets, 해시 버킷 배열 포인터를 저장합니다.oldbuckets, hmap 확장 전 해시 버킷 배열 포인터를 저장합니다.extra, hmap 의 오버플로 버킷을 저장하는 선택적 필드로, 오버플로 버킷은 현재 버킷이 가득 찼을 때 요소를 저장하기 위해 생성되는 새 버킷입니다.
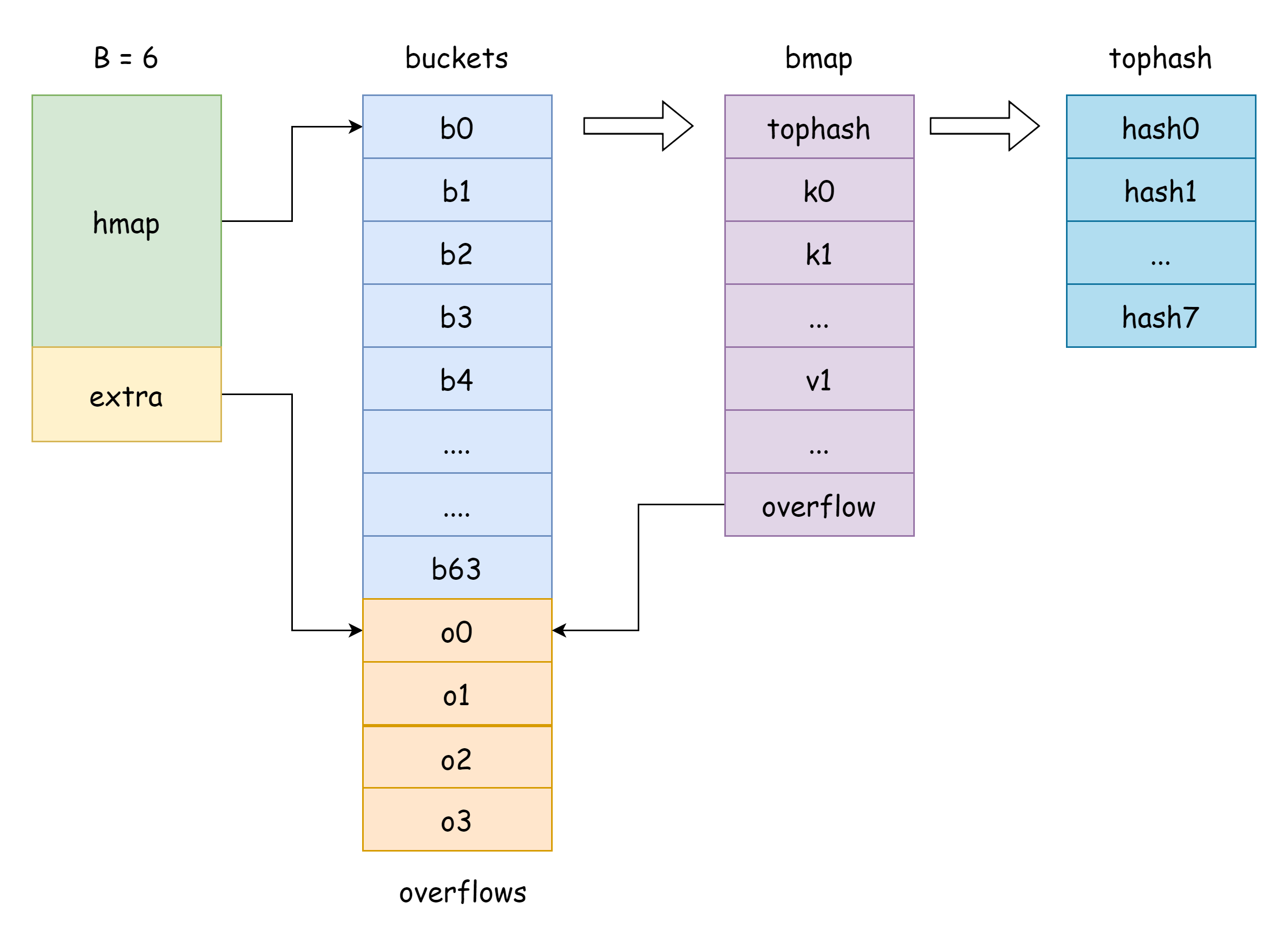
hmap 의 buckets 는 버킷 슬라이스 포인터로, Go 에서 해당하는 구조체는 runtime.bmap 입니다.
// A bucket for a Go map.
type bmap struct {
tophash [bucketCnt]uint8
}위에서 볼 수 있듯이 tophash 필드만 있으며, 이 필드는 각 키의 상위 8 비트를 저장하는 데 사용됩니다. 그러나 실제로 bmap 의 필드는 이보다 더 많습니다. map 이 다양한 유형의 키 - 값 쌍을 저장할 수 있기 때문에 컴파일 시점에 유형에 따라 메모리 공간을 추론해야 합니다. cmd/compile/internal/reflectdata/reflect.go 의 MapBucketType 함수는 컴파일 시점에 bmap 을 구성하며, 키 유형이 comparable 인지 확인하는 일련의 검사를 수행합니다.
// MapBucketType makes the map bucket type given the type of the map.
func MapBucketType(t *types.Type) *types.Type따라서 실제로 bmap 의 구조는 다음과 같지만 이러한 필드는 우리에게 보이지 않으며, Go 는 실제로 unsafe 포인터를 이동하여 액세스합니다.
type bmap struct {
tophash [BUCKETSIZE]uint8
keys [BUCKETSIZE]keyType
elems [BUCKETSIZE]elemType
overflow *bucket
}일부 설명은 다음과 같습니다.
tophash, 각 키의 상위 8 비트 값을 저장하며, tophash 요소에 대해 다음과 같은 특수 값이 있습니다.goconst ( emptyRest = 0 // 현재 요소가 비어있고 이 요소 뒤에 더 이상 사용 가능한 키가 없음 emptyOne = 1 // 현재 요소가 비어있지만 이 요소 뒤에 사용 가능한 키가 있음 evacuatedX = 2 // 확장 시 나타나며 oldbuckets 에만 나타날 수 있음, 현재 요소가 새 해시 버킷 배열의 상단 영역으로 이동되었음을 나타냄 evacuatedY = 3 // 확장 시 나타나며 oldbuckets 에만 나타날 수 있음, 현재 요소가 새 해시 버킷 배열의 하단 영역으로 이동되었음을 나타냄 evacuatedEmpty = 4 // 확장 시 나타나며, 요소 자체가 비어있고 이동 시 표시됨 minTopHash = 5 // 정상적인 키 - 값에 대한 tophash 의 최소값 )tophash[i]값이minTopHash보다 크면 해당 인덱스에 정상 키 - 값이 존재함을 의미합니다.keys, 지정된 유형 키를 저장하는 배열입니다.elems, 지정된 유형 값을 저장하는 배열입니다.overflow, 오버플로 버킷을 가리키는 포인터입니다.
키 - 값이 구조체 필드를 통해 직접 액세스할 수 없으므로, Go 는 사전에 dataoffset 상수를 선언하며, 이는 bmap 에서 데이터의 메모리 오프셋을 나타냅니다.
const dataOffset = unsafe.Offsetof(struct {
b bmap
v int64
}{}.v)실제로 키 - 값은 연속된 메모리 주소에 저장되며, 다음과 같은 구조로 메모리 정렬로 인한 공간 낭비를 피하기 위함입니다.
k1,k2,k3,k4,k5,k6...v1,v2,v3,v4,v5,v6...따라서 bmap 에 대해 포인터가 dataoffset 만큼 이동한 후 i*sizeof(keyType) 만큼 이동하면 i 번째 key 의 주소가 됩니다.
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))i 번째 value 의 주소를 얻는 것도 마찬가지입니다.
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))hmap 의 buckets 포인터는 첫 번째 해시 버킷 주소를 가리키며, i 번째 해시 버킷 주소를 얻으려면 오프셋은 i*sizeof(bucket) 입니다.
b := (*bmap)(add(h.buckets, i*uintptr(t.BucketSize)))이후 내용에서 이러한 작업이 매우 자주 나타납니다.
해시
충돌
hmap 에는 오버플로 버킷 정보를 저장하는 데 사용되는 extra 필드가 있으며, 오버플로 버킷 슬라이스를 가리킵니다. 그 구조는 다음과 같습니다.
type mapextra struct {
// 오버플로 버킷 포인터 슬라이스
overflow *[]*bmap
// 확장 전 이전 오버플로 버킷 포인터 슬라이스
oldoverflow *[]*bmap
// 다음 빈 오버플로 버킷을 가리키는 포인터
nextOverflow *bmap
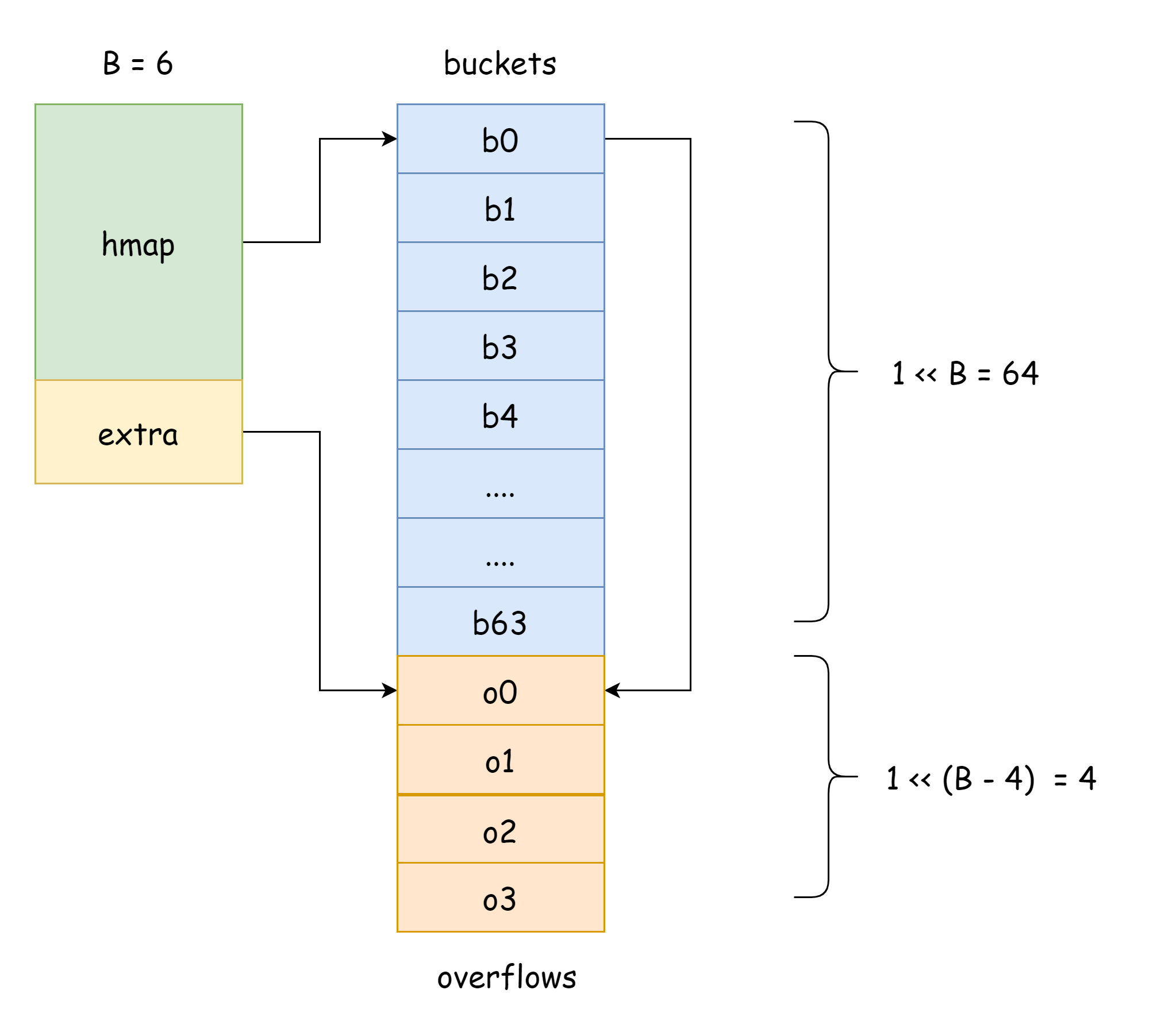
}
TIP
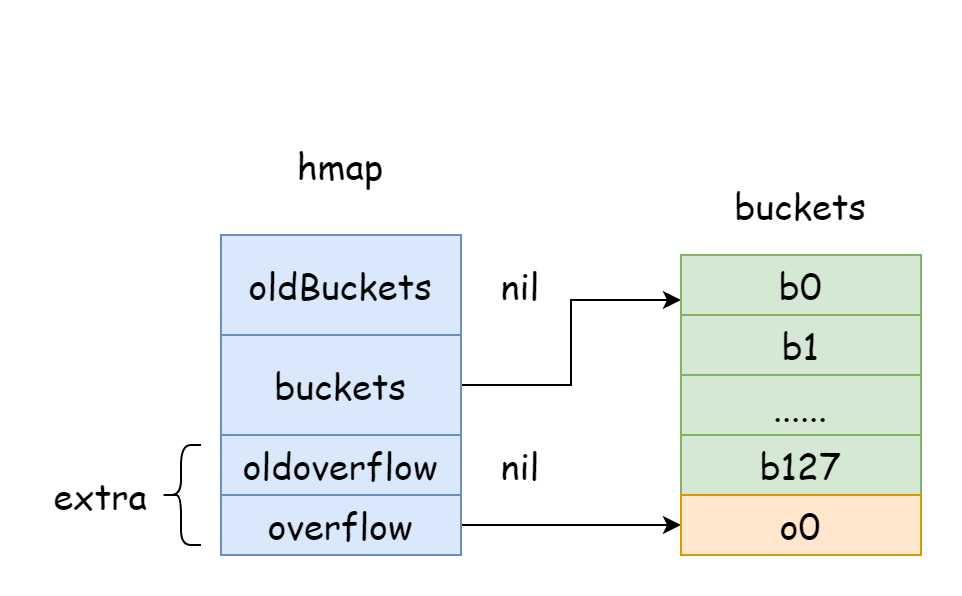
위 그림에서 파란색 부분은 해시 버킷 배열이고 주황색 부분은 오버플로 해시 버킷 배열이며, 오버플로 해시 버킷은 이하 오버플로 버킷으로 통칭합니다.
위 그림은 hmap 의 대략적인 구조를 잘 보여줍니다. buckets 는 해시 버킷 배열을 가리키고 extra 는 오버플로 버킷 배열을 가리킵니다. 버킷 bucket0 은 오버플로 버킷 overflow0 을 가리키며, 두 가지 다른 버킷은 각각 두 슬라이스에 저장되고 두 버킷의 메모리는 연속됩니다. 두 키가 해시 후 동일한 bucket 에 할당되면 이를 해시 충돌이라고 합니다. Go 에서 해시 충돌을 해결하는 방식은 체이닝법이며, 충돌된 키의 수가 버킷 용량 (일반적으로 8 개, internal/abi.MapBucketCount 에 따라 결정됨) 을 초과하면 이러한 키를 저장하기 위해 새 버킷을 생성하며, 이 버킷을 오버플로 버킷이라고 합니다. 원래 버킷에 담을 수 없어 요소가 새 버킷으로 넘쳤다는 의미입니다. 생성이 완료되면 해시 버킷에는 새 오버플로 버킷을 가리키는 포인터가 있으며, 이 버킷들의 포인터를 연결하면 bmap 링크드 리스트가 형성됩니다.
체이닝법의 경우 부하 인자를 사용하여 해시 테이블의 충돌 상황을 측정하며, 계산식은 다음과 같습니다.
loadfactor := len(elems) / len(buckets)부하 인자가 클수록 해시 충돌이 많아 오버플로 버킷 수가 많아지므로, 해시 테이블을 읽고 쓸 때 지정된 위치를 찾기 위해 더 많은 오버플로 버킷 링크드 리스트를 순회해야 하므로 성능이 저하됩니다. 이러한 상황을 개선하기 위해 buckets 버킷 수를 늘려야 하며, 이를 확장이라고 합니다. hmap 의 경우 두 가지 상황에서 확장이 트리거됩니다.
- 부하 인자가 임계값
bucketCnt*13/16을 초과할 때, 값은 최소 6.5 입니다. - 오버플로 버킷 수가 너무 많을 때
부하 인자가 작을수록 hmap 의 메모리 이용률이 낮고 점유하는 메모리가 커집니다. Go 에서 부하 인자를 계산하는 함수는 runtime.overLoadFactor이며, 코드는 다음과 같습니다.
func overLoadFactor(count int, B uint8) bool {
return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)
}여기서 loadFactorNum과 loadFactorDen은 상수이며, bucketshift 는 1 << B 를 계산하며, 다음과 같습니다.
loadFactorNum = (bucketCnt * 13 / 16) * loadFactorDen따라서 간소화하면 다음과 같습니다.
count > bucketCnt && uintptr(count) / 1 << B > (bucketCnt * 13 / 16)여기서 (bucketCnt * 13 / 16) 값은 6.5 이고, 1 << B 는 해시 버킷 수이므로, 이 함수의 역할은 요소 수를 버킷 수로 나눈 값이 부하 인자 6.5 보다 큰지 계산하는 것입니다.
계산
Go 내부에서 해시를 계산하는 함수는 runtime/alg.go 파일의 f32hash 에 있으며, 다음과 같이 NaN 과 0 두 가지 상황에 대한 처리가 포함되어 있습니다.
func f32hash(p unsafe.Pointer, h uintptr) uintptr {
f := *(*float32)(p)
switch {
case f == 0:
return c1 * (c0 ^ h) // +0, -0
case f != f:
return c1 * (c0 ^ h ^ uintptr(fastrand())) // any kind of NaN
default:
return memhash(p, h, 4)
}
}map 해시 계산 방법은 유형 기반이 아닌 메모리 기반이며, 최종적으로 memhash 함수로 이동합니다. 이 함수는 어셈블리로 구현되며 로직은 runtime/asm*.s 에 있습니다. 메모리 기반 해시 값은 영구적으로 저장되어서는 안 되며, 런타임에만 사용되어야 하고 매번 실행 시 메모리 분포가 완전히 일치한다고 보장할 수 없기 때문입니다.
이 파일에는 typehash 라는 함수도 있으며, 이 함수는 다양한 유형에 따라 해시 값을 계산하지만 map 은 이 함수를 사용하여 해시를 계산하지 않습니다.
func typehash(t *_type, p unsafe.Pointer, h uintptr) uintptr이 구현은 위보다 느리지만 더 일반적이며, 주로 리플렉션 및 컴파일 시 함수 생성에 사용됩니다. 예를 들어 다음 함수와 같습니다.
//go:linkname reflect_typehash reflect.typehash
func reflect_typehash(t *_type, p unsafe.Pointer, h uintptr) uintptr {
return typehash(t, p, h)
}생성
map 초기화에는 두 가지 방식이 있으며, 이는 언어 입문에서 이미 설명했습니다. 하나는 map 키워드를 직접 사용하는 것이고 다른 하나는 make 함수를 사용하는 것입니다. 어떤 방식으로 초기화하든 최종적으로 runtime.makemap 이 map 을 생성하며, 함수 시그니처는 다음과 같습니다.
func makemap(t *maptype, hint int, h *hmap) *hmap파라미터는 다음과 같습니다.
t, map 의 유형을 나타내며, 다른 유형은 다른 메모리 점유를 필요로 합니다.hint,make함수의 두 번째 파라미터로, map 예상 요소 용량입니다.h,hmap포인터로,nil일 수 있습니다.
반환 값은 초기화가 완료된 hmap 포인터입니다. 이 함수는 초기화 과정에서 몇 가지 주요 작업을 수행합니다. 먼저 예상 할당 메모리가 최대 할당 메모리를 초과하는지 계산하며, 해당 코드는 다음과 같습니다.
// 예상 용량과 버킷 유형의 메모리 크기를 곱함
mem, overflow := math.MulUintptr(uintptr(hint), t.Bucket.Size_)
// 값이 오버플로되거나 최대 할당 메모리를 초과함
if overflow || mem > maxAlloc {
hint = 0
}이전 내부 구조에서 hmap 은 버킷으로 구성된다고 언급했습니다. 메모리 이용률이 가장 낮은 경우 한 버킷에 하나의 요소만 있으며 메모리를 가장 많이 점유하므로, 예상 최대 메모리 점유는 요소 수에 해당 유형의 메모리 점유 크기를 곱한 것입니다. 계산 결과가 값 오버플로되거나 최대 할당 메모리를 초과하면 hint 를 0 으로 설정합니다. 이후 hint 를 사용하여 버킷 배열 용량을 계산해야 하기 때문입니다.
두 번째로 hmap 을 초기화하고 무작위 해시 시드를 계산하며, 해당 코드는 다음과 같습니다.
// 초기화
if h == nil {
h = new(hmap)
}
// 무작위 해시 시드 획득
h.hash0 = fastrand()그런 다음 hint 값에 따라 해시 버킷 용량을 계산하며, 해당 코드는 다음과 같습니다.
B := uint8(0)
// hint / 1 << B < 6.5 가 될 때까지 계속 순환
for overLoadFactor(hint, B) {
B++
}
// hmap 에 할당
h.B = B(hint / 1 << B) < 6.5 를 만족하는 첫 번째 B 값을 계속 찾아 hmap 에 할당합니다. 해시 버킷 용량을 알게 된 후 마지막으로 해시 버킷에 메모리를 할당합니다.
if h.B != 0 {
var nextOverflow *bmap
// 할당된 해시 버킷과 미리 할당된 빈 오버플로 버킷
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
// 미리 할당된 빈 오버플로 버킷이 있으면 해당 오버플로 버킷을 가리킴
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}makeBucketArray 함수는 B 값에 따라 해시 버킷에 해당 크기의 메모리를 할당하고 미리 빈 오버플로 버킷을 할당합니다. B 가 4 보다 작으면 오버플로 버킷을 생성하지 않으며, 4 보다 크면 2^B-4 개의 오버플로 버킷을 생성합니다. 이는 runtime.makeBucketArray 함수의 다음 코드에 해당합니다.
base := bucketShift(b)
nbuckets := base
// 4 보다 작으면 오버플로 버킷 생성 안 함
if b >= 4 {
// 예상 버킷 수에 1 << (b-4) 추가
nbuckets += bucketShift(b - 4)
// 오버플로 버킷에 필요한 메모리
sz := t.Bucket.Size_ * nbuckets
// 메모리 공간을 올림
up := roundupsize(sz)
if up != sz {
// 같지 않으면 up 을 사용하여 다시 계산
nbuckets = up / t.Bucket.Size_
}
}base 는 예상 할당 버킷 수를 나타내고 nbuckets 는 실제 할당 버킷 수로, 오버플로 버킷 수를 더한 것입니다.
if base != nbuckets {
// 첫 번째 사용 가능한 오버플로 버킷
nextOverflow = (*bmap)(add(buckets, base*uintptr(t.BucketSize)))
// 오버플로 버킷 추적 오버헤드를 줄이기 위해 마지막 사용 가능한 오버플로 버킷의 오버플로 포인터를 해시 버킷 헤더로 가리킴
last := (*bmap)(add(buckets, (nbuckets-1)*uintptr(t.BucketSize)))
// 마지막 오버플로 버킷이 해시 버킷을 가리킴
last.setoverflow(t, (*bmap)(buckets))
}두 값이 같지 않으면 추가 오버플로 버킷이 할당되었음을 의미하며, nextoverflow 포인터는 첫 번째 사용 가능한 오버플로 버킷을 가리킵니다. 이를 통해 해시 버킷과 오버플로 버킷이 실제로 동일한 연속 메모리에 있음을 알 수 있습니다. 이것이 그림에서 해시 버킷 배열과 오버플로 버킷 배열이 인접한 이유입니다.
액세스
문법 입문에서 map 액세스에는 세 가지 방식이 있다고 언급했습니다. 다음과 같습니다.
# 값 직접 액세스
val := dict[key]
# 값 및 키 존재 여부 액세스
val, exist := dict[key]
# map 순회
for key, val := range dict{
}이 세 가지 방식은 모두 다른 함수를 사용하며, for range 로 map 을 순회하는 것이 가장 복잡합니다.
키 - 값
처음 두 가지 방식은 각각 runtime.mapaccess1 과 runtime.mapaccess2 두 함수에 해당하며, 함수 시그니처는 다음과 같습니다.
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer
func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool)여기서 key 는 map 에 액세스하는 키를 가리키는 포인터이며, 반환 시에도 포인터만 반환합니다. 액세스 시 먼저 key 의 해시 값을 계산하여 key 가 어느 해시 버킷에 있는지 위치하며, 해당 코드는 다음과 같습니다.
// 경계 처리
if h == nil || h.count == 0 {
if t.HashMightPanic() {
t.Hasher(key, 0) // issue 23734 참조
}
return unsafe.Pointer(&zeroVal[0])
}
// 동시 읽기 - 쓰기 방지
if h.flags&hashWriting != 0 {
fatal("concurrent map read and map write")
}
// 지정 유형의 hasher 를 사용하여 해시 값 계산
hash := t.Hasher(key, uintptr(h.hash0))
// (1 << B) - 1
m := bucketMask(h.B)
// 포인터 이동을 통해 key 가 있는 해시 버킷 위치
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.BucketSize)))액세스 시작 시 먼저 경계 상황을 처리하고 map 의 동시 읽기 - 쓰기를 방지합니다. map 이 동시 읽기 - 쓰기 상태일 때 panic 이 발생합니다. 그런 다음 해시 값을 계산하고, bucketMask 함수가 수행하는 작업은 (1 << B) - 1을 계산하는 것이며, hash & m 은 hash & (1 << B) - 1과 같아 이진수 나머지 연산으로, hash % (1 << B)와 동일합니다. 비트 연산을 사용하는 이점은 더 빠르다는 것입니다. 마지막 세 줄 코드는 key 로 계산된 해시 값을 현재 map 의 버킷 수로 나누어 해시 버킷 번호를 얻은 후, 번호에 따라 포인터를 이동하여 key 가 있는 해시 버킷 포인터를 얻습니다.
key 가 어느 해시 버킷에 있는지 알게 된 후 검색을 시작할 수 있으며, 이 부분은 다음 코드에 해당합니다.
// 해시 값의 상위 8 비트 획득
top := tophash(hash)
bucketloop:
// bmap 링크드 리스트 순회
for ; b != nil; b = b.overflow(t) {
// bmap 의 요소
for i := uintptr(0); i < bucketCnt; i++ {
// 계산된 top 과 tophash 의 요소 비교
if b.tophash[i] != top {
// 이후가 모두 비어있음
if b.tophash[i] == emptyRest {
break bucketloop
}
// 같지 않으면 오버플로 버킷 계속 순회
continue
}
// i 에 따라 포인터 이동하여 해당 인덱스의 키 획득
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
// 포인터 처리
if t.IndirectKey() {
k = *((*unsafe.Pointer)(k))
}
// 두 키가 같은지 비교
if t.Key.Equal(key, k) {
// 같으면 k 에 해당하는 인덱스의 요소 반환
// 이 코드에서 키 - 값 메모리 주소가 연속적임을 알 수 있음
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
if t.IndirectElem() {
e = *((*unsafe.Pointer)(e))
}
return e
}
}
}
// 찾지 못하면 0 값 반환
return unsafe.Pointer(&zeroVal[0])해시 버킷 위치는 나머지를 통해 결정되므로 key 가 어느 해시 버킷에 있는지는 해시 값의 하위에 따라 결정됩니다. 하위 몇 비트인지는 B 크기에 따라 결정됩니다. 해시 버킷을 찾은 후 tophash 에 저장된 것은 해시 값의 상위 8 비트입니다. 하위 나머지 값이 모두 같기 때문에 키가 같은지 하나씩 비교할 필요가 없고 해시 값 상위 8 비트만 비교하면 됩니다. 앞서 계산된 해시 값에 따라 상위 8 비트를 얻고, bmap 의 tophash 배열에서 하나씩 비교합니다. 상위 8 비트가 같으면 키가 같은지 비교하고, 키도 같으면 요소를 찾은 것입니다. 같지 않으면 tophash 배열을 계속 순회하고, 여전히 찾지 못하면 오버플로 버킷 bmap 링크드 리스트를 계속 순회하며, bmap 의 tophash[i] 가 emptyRest 일 때 루프를 종료하고 마지막으로 해당 유형의 0 값을 반환합니다.
mapaccess2 함수는 mapaccess1 함수 로직과 완전히 동일하며, 요소가 존재하는지 나타내는 불리언 반환 값만 추가되었습니다.
순회
map 을 순회하는 문법은 다음과 같습니다.
for key, val := range dict {
// do something...
}실제 순회 시 Go 는 hiter 구조체를 사용하여 순회 정보를 저장합니다. hiter 는 hmap iterator 의 약자로, 해시 테이블 이터레이터를 의미하며 구조는 다음과 같습니다.
// A hash iteration structure.
// If you modify hiter, also change cmd/compile/internal/reflectdata/reflect.go
// and reflect/value.go to match the layout of this structure.
type hiter struct {
key unsafe.Pointer // Must be in first position. Write nil to indicate iteration end (see cmd/compile/internal/walk/range.go).
elem unsafe.Pointer // Must be in second position (see cmd/compile/internal/walk/range.go).
t *maptype
h *hmap
buckets unsafe.Pointer // bucket ptr at hash_iter initialization time
bptr *bmap // current bucket
overflow *[]*bmap // keeps overflow buckets of hmap.buckets alive
oldoverflow *[]*bmap // keeps overflow buckets of hmap.oldbuckets alive
startBucket uintptr // bucket iteration started at
offset uint8 // intra-bucket offset to start from during iteration (should be big enough to hold bucketCnt-1)
wrapped bool // already wrapped around from end of bucket array to beginning
B uint8
i uint8
bucket uintptr
checkBucket uintptr
}다음은 몇 가지 필드에 대한 간단한 설명입니다.
key,elem은for range순회 시 얻은 키 - 값입니다.buckets, 이터레이터 초기화 시 지정되며 해시 버킷 헤더를 가리킵니다.bptr, 현재 순회 중인 bmap 입니다.startBucket, 순회 시작 시 시작 버킷 번호입니다.offset, 버킷 내 오프셋으로 범위는[0, bucketCnt-1]입니다.B, hmap 의 B 값입니다.i, 버킷 내 요소 인덱스입니다.wrapped, 해시 버킷 배열 끝에서 시작으로 돌아왔는지 여부입니다.
순회 시작 전 Go 는 runtime.mapiterinit 함수를 통해 이터레이터를 초기화한 후 runtime.mapiternext 함수를 통해 map 을 순회하며, 두 함수 모두 hiter 구조체가 필요합니다. 두 함수 시그니처는 다음과 같습니다.
func mapiterinit(t *maptype, h *hmap, it *hiter)
func mapiternext(it *hiter)이터레이터 초기화의 경우 먼저 map 의 현재 스냅샷을 얻으며, 해당 코드는 다음과 같습니다.
it.t = t
it.h = h
// hmap 현재 상태의 스냅샷 기록, B 값만 저장하면 됨.
it.B = h.B
it.buckets = h.buckets
if t.Bucket.PtrBytes == 0 {
h.createOverflow()
it.overflow = h.extra.overflow
it.oldoverflow = h.extra.oldoverflow
}이후 순회 시 실제로 순회하는 것은 map 의 스냅샷이지 실제 map 이 아니므로, 순회 중 추가된 요소와 버킷은 순회되지 않으며, 동시에 순회하며 요소를 작성하면 fatal 이 트리거될 수 있습니다.
if h.flags&hashWriting != 0 {
fatal("concurrent map iteration and map write")
}두 번째로 순회의 두 시작 위치를 결정합니다. 첫 번째는 시작 버킷 위치이고 두 번째는 버킷 내 시작 위치로, 이 두 위치는 모두 무작위로 선택됩니다. 해당 코드는 다음과 같습니다.
// r 은 난수
var r uintptr
if h.B > 31-bucketCntBits {
r = uintptr(fastrand64())
} else {
r = uintptr(fastrand())
}
// r % (1 << B) 시작 버킷 위치 획득
it.startBucket = r & bucketMask(h.B)
// r >> B % 8 시작 버킷 내 요소 시작 위치 획득
it.offset = uint8(r >> h.B & (bucketCnt - 1))
// 현재 순회 중인 버킷 번호 기록
it.bucket = it.startBucketfastrand() 또는 fastrand64() 를 통해 난수를 얻고, 두 번의 나머지 연산을 통해 버킷 시작 위치와 버킷 내 시작 위치를 얻습니다.
TIP
map 은 동시 읽기 - 쓰기를 허용하지 않지만 동시 순회는 허용합니다.
다음으로 실제로 map 을 순회하며, 버킷을 어떻게 순회하고 종료 전략은 무엇인지에 대한 내용은 아래 코드에 해당합니다.
// hmap
h := it.h
// maptype
t := it.t
// 순회할 버킷 위치
bucket := it.bucket
// 순회할 bmap
b := it.bptr
// 버킷 내 인덱스 i
i := it.i
next:
if b == nil {
// 현재 버킷 위치와 시작 위치가 같으면 한 바퀴 돌아온 것이므로 이후는 이미 순회 완료
// 순회 종료, 종료 가능
if bucket == it.startBucket && it.wrapped {
it.key = nil
it.elem = nil
return
}
// 버킷 인덱스 후진
bucket++
// bucket == 1 << B, 해시 버킷 배열 끝에 도달
if bucket == bucketShift(it.B) {
// 처음부터 시작
bucket = 0
it.wrapped = true
}
i = 0
}해시 버킷 시작 위치 선택은 무작위이며, 순회 시 시작 위치에서 버킷 슬라이스 끝까지逐个 순회하고, 1 << B 에 도달한 후 처음부터 시작하며, 다시 시작 위치로 돌아오면 순회가 완료되었음을 의미하고 종료합니다. 위 코드는 map 에서 버킷을 순회하는 방법에 대한 것이며, 아래 코드는 버킷 내에서 어떻게 순회하는지 설명합니다.
for ; i < bucketCnt; i++ {
// (i + offset) % 8
offi := (i + it.offset) & (bucketCnt - 1)
// 현재 요소가 비어있으면 건너뜀
if isEmpty(b.tophash[offi]) || b.tophash[offi] == evacuatedEmpty {
continue
}
// 포인터 이동하여 키 획득
k := add(unsafe.Pointer(b), dataOffset+uintptr(offi)*uintptr(t.KeySize))
if t.IndirectKey() {
k = *((*unsafe.Pointer)(k))
}
// 포인터 이동하여 값 획득
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+uintptr(offi)*uintptr(t.ValueSize))
// 동일 용량 확장 상황 처리, 키 - 값이 다른 위치로 분산된 후 키 - 값을 다시 찾아야 함.
if (b.tophash[offi] != evacuatedX && b.tophash[offi] != evacuatedY) ||
!(t.ReflexiveKey() || t.Key.Equal(k, k)) {
it.key = k
if t.IndirectElem() {
e = *((*unsafe.Pointer)(e))
}
it.elem = e
} else {
rk, re := mapaccessK(t, h, k)
if rk == nil {
continue
}
it.key = rk
it.elem = re
}
it.bucket = bucket
it.i = i + 1
return
}
// 찾지 못하면 오버플로 버킷에서 찾음
b = b.overflow(t)
i = 0
goto nextTIP
위 확장 판단 조건에서 하나의 표현식이 혼란을 줄 수 있습니다. 다음과 같습니다.
t.Key.Equal(k, k)k 가 자신과 같은지 판단하는 이유는 Nan 인 키 상황을 필터링하기 위함입니다. 요소의 키가 Nan 이면 해당 요소를 정상적으로 액세스할 수 없으며, 순회든 직접 액세스든 삭제든 정상적으로 수행할 수 없습니다. Nan != Nan 이 항상 성립하므로 이 키를 절대 찾을 수 없기 때문입니다.
먼저 i 값과 offset 값을 나머지 연산하여 순회할 버킷 내 인덱스를 얻고, 포인터 이동을 통해 키 - 값을 얻습니다. map 순회 중 다른 쓰기 작업이 map 확장을 트리거할 수 있으므로 실제 키 - 값은 원래 위치에 없을 수 있습니다. 이 경우 mapaccessK 함수를 사용하여 실제 키 - 값을 다시 찾아야 합니다. 이 함수 시그니처는 다음과 같습니다.
func mapaccessK(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, unsafe.Pointer)이 함수의 기능은 mapaccess1 함수와 완전히 동일하며, 차이점은 mapaccessK 함수가 키 값과 값 값을 동시에 반환한다는 것입니다. 최종적으로 키 - 값을 얻은 후 이터레이터의 key, elem 에 할당하고 이터레이터 인덱스를 업데이트하여 한 번의 순회를 완료합니다. 코드 실행이 for range 코드 블록으로 돌아갑니다. 버킷 내에서 찾지 못하면 오버플로 버킷에서 계속 찾아 위의 단계를 반복하며, 오버플로 버킷 링크드 리스트 순회가 완료된 후 계속 다음 해시 버킷을 순회합니다.
수정
map 을 수정하는 문법은 다음과 같습니다.
dict[key] = valGo 에서 map 수정 작업은 runtime.mapassign 함수로 완료하며, 함수 시그니처는 다음과 같습니다.
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer액세스 과정 로직은 mapaccess1 과 동일하지만, key 가 존재하지 않을 때 위치를 할당하고 존재하면 업데이트하며, 마지막으로 요소 포인터를 반환합니다. 시작 시 몇 가지 준비 작업을 해야 하며, 해당 코드는 다음과 같습니다.
// nil map 에 쓰기 불가
if h == nil {
panic(plainError("assignment to entry in nil map"))
}
// 동시 쓰기 금지
if h.flags&hashWriting != 0 {
fatal("concurrent map writes")
}
// key 해시 값 계산
hash := t.Hasher(key, uintptr(h.hash0))
// hmap 상태 수정
h.flags ^= hashWriting
// 해시 버킷 초기화
if h.buckets == nil {
h.buckets = newobject(t.Bucket) // newarray(t.Bucket, 1)
}위 코드는 다음 몇 가지 작업을 수행합니다.
- hmap 상태 검사
- key 해시 값 계산
- 해시 버킷 초기화 필요 여부 확인
그 후 해시 값을 나머지 연산하여 해시 버킷 위치를 얻고, key 의 tophash 를 계산하며, 코드는 다음과 같습니다.
again:
// hash % (1 << B)
bucket := hash & bucketMask(h.B)
// 포인터 이동하여 지정 위치 bmap 획득
b := (*bmap)(add(h.buckets, bucket*uintptr(t.BucketSize)))
// tophash 계산
top := tophash(hash)이제 버킷 위치, bmap, tophash 를 결정했으므로 요소 검색을 시작할 수 있으며, 이 부분 코드는 다음과 같습니다.
// 삽입할 tophash
var inserti *uint8
// 삽입할 key 값 포인터
var insertk unsafe.Pointer
// 삽입할 value 값 포인터
var elem unsafe.Pointer
bucketloop:
for {
// 버킷 내 tophash 배열 순회
for i := uintptr(0); i < bucketCnt; i++ {
// tophash 이 같지 않음
if b.tophash[i] != top {
// 현재 버킷 내 인덱스가 비어있고 아직 요소 삽입 안 했으면 해당 위치 선택하여 삽입
if isEmpty(b.tophash[i]) && inserti == nil {
// key 에 적합한 위치 찾음
inserti = &b.tophash[i]
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
}
// 순회 완료하면 루프 종료
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
// tophash 이 같으면 key 가 이미 존재할 수 있음
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
if t.IndirectKey() {
k = *((*unsafe.Pointer)(k))
}
// key 가 같은지 판단
if !t.Key.Equal(key, k) {
continue
}
// key 값 업데이트 필요하면 key 메모리를 k 위치에 직접 복사
if t.NeedKeyUpdate() {
typedmemmove(t.Key, k, key)
}
// 요소 포인터 획득
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
// 업데이트 완료, 요소 포인터 반환
goto done
}
// 여기까지 실행되면 key 를 찾지 못한 것, 오버플로 버킷 링크드 리스트 순회하며 계속 찾음
ovf := b.overflow(t)
if ovf == nil {
break
}
b = ovf
}
// 여기까지 실행되면 map 에서 key 를 찾지 못한 것, 하지만 key 에 적합한 위치를 찾았을 수도 있고 찾지 못했을 수도 있음
// key 에 적합한 위치를 찾지 못함
if inserti == nil {
// 현재 해시 버킷과 그 오버플로 버킷이 모두 가득 참, 새 오버플로 버킷 할당
newb := h.newoverflow(t, b)
// 오버플로 버킷에서 key 에 위치 할당
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
elem = add(insertk, bucketCnt*uintptr(t.KeySize))
}
// key 포인터를 저장하는 경우
if t.IndirectKey() {
// 새 메모리 할당, unsafe 포인터 반환
kmem := newobject(t.Key)
*(*unsafe.Pointer)(insertk) = kmem
// insertk 에 할당, 이후 key 메모리 복사 용이
insertk = kmem
}
// 요소 포인터를 저장하는 경우
if t.IndirectElem() {
// 메모리 할당
vmem := newobject(t.Elem)
// 포인터가 vmem 을 가리키게 함
*(*unsafe.Pointer)(elem) = vmem
}
// key 메모리를 insertk 위치에 직접 복사
typedmemmove(t.Key, insertk, key)
*inserti = top
// 수량 1 증가
h.count++
done:
// 여기까지 실행되면 수정 과정 완료
if h.flags&hashWriting == 0 {
fatal("concurrent map writes")
}
h.flags &^= hashWriting
if t.IndirectElem() {
elem = *((*unsafe.Pointer)(elem))
}
// 요소 포인터 반환
return elem위 긴 코드에서 먼저 for 루프에 들어가 해시 버킷과 오버플로 버킷에서 찾기를 시도하며, 검색 로직은 mapaccess 와 완전히 동일합니다. 이때 세 가지 가능성이 있습니다.
- 첫 번째, map 에서 이미 존재하는 key 를 찾으면
done코드 블록으로 이동하여 요소 포인터를 반환합니다. - 두 번째, map 에서 key 에 할당할 위치를 찾으면 key 를 지정 위치에 복사하고 요소 포인터를 반환합니다.
- 세 번째, 모든 버킷을 찾았지만 map 에서 key 에 할당할 위치를 찾지 못하면 새 오버플로 버킷을 생성하고 key 를 버킷에 할당한 후 key 를 지정 위치에 복사하고 요소 포인터를 반환합니다.
최종적으로 요소 포인터를 얻은 후 할당할 수 있지만, 이 작업은 mapassign 함수로 완료되지 않으며, 이 함수는 요소 포인터만 반환하고 할당 작업은 컴파일러 기간에 삽입됩니다. 코드에서는 볼 수 없지만 컴파일된 코드에서는 볼 수 있습니다. 다음 코드가 있다고 가정합니다.
func main() {
dict := make(map[string]string, 100)
dict["hello"] = "world"
}다음 명령을 통해 어셈블리 코드를 얻습니다.
go tool compile -S -N -l main.go핵심적인 부분은 다음과 같습니다.
0x004e 00078 LEAQ type:map[string]string(SB), AX
0x0055 00085 CALL runtime.mapassign_faststr(SB)
0x005a 00090 MOVQ AX, main..autotmp_2+40(SP)
0x0083 00131 LEAQ go:string."world"(SB), CX
0x008a 00138 MOVQ CX, (AX)runtime.mapassign_faststr 을 호출하는 것을 볼 수 있으며, 로직은 mapassign 과 완전히 유사합니다. LEAQ go:string."world"(SB), CX 는 문자열 주소를 CX 에 저장하고, MOVQ CX, (AX) 는 이를 AX 에 저장하여 요소 할당을 완료합니다.
삭제
Go 에서 map 요소를 삭제하려면 내장 함수 delete 만 사용할 수 있습니다. 다음과 같습니다.
delete(dict, "abc")내부적으로 runtime.mapdelete 함수를 호출하며, 함수 시그니처는 다음과 같습니다.
func mapdelete(t *maptype, h *hmap, key unsafe.Pointer)이 함수는 map 에서 지정 key 의 요소를 삭제하며, 요소가 map 에 존재하는지 여부와 관계없이 아무 반응도 없습니다. 함수 시작 부분의 준비 작업 로직은 비슷하며, 다음 몇 가지 작업만 수행합니다.
- hmap 상태 검사
- key 해시 값 계산
- 해시 버킷 위치 지정
- tophash 계산
앞에 많은 반복적인 내용이 있으므로 더 이상 자세히 설명하지 않으며, 여기서는 삭제 로직만关注합니다. 해당 부분 코드는 다음과 같습니다.
bOrig := b
search:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
// 찾지 못하면 루프 종료
if b.tophash[i] == emptyRest {
break search
}
continue
}
// 포인터 이동하여 key 위치 찾음
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
k2 := k
if t.IndirectKey() {
k2 = *((*unsafe.Pointer)(k2))
}
if !t.Key.Equal(key, k2) {
continue
}
// key 삭제
if t.IndirectKey() {
*(*unsafe.Pointer)(k) = nil
} else if t.Key.PtrBytes != 0 {
memclrHasPointers(k, t.Key.Size_)
}
// 포인터 이동하여 요소 위치 찾음
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
// 요소 삭제
if t.IndirectElem() {
*(*unsafe.Pointer)(e) = nil
} else if t.Elem.PtrBytes != 0 {
memclrHasPointers(e, t.Elem.Size_)
} else {
memclrNoHeapPointers(e, t.Elem.Size_)
}
notLast:
// 수량 1 감소
h.count--
// 해시 시드 리셋, 충돌 발생 확률 감소
if h.count == 0 {
h.hash0 = fastrand()
}
break search
}
}위 코드를 통해 검색 로직이 앞선 작업과 거의 완전히 동일함을 알 수 있습니다. 요소를 찾은 후 삭제하고, hmap 이 기록한 수량을 1 감소시키며, 수량이 0 으로 감소하면 해시 시드를 리셋합니다.
또 다른 주의할 점은 요소 삭제 후 현재 인덱스의 tophash 상태를 수정해야 한다는 것입니다. 이 부분 코드는 다음과 같습니다. i 가 버킷 끝에 있을 때 다음 오버플로 버킷에 따라 현재 요소가 마지막 사용 가능한 요소인지 판단하고, 그렇지 않으면 인접 요소의 해시 상태를 직접 확인합니다. 현재 요소가 마지막 사용 가능한 요소가 아니면 상태를 emptyOne 으로 설정합니다.
// 현재 tophash 를 empty 로 표시
b.tophash[i] = emptyOne
// tophash 끝에 있으면
if i == bucketCnt-1 {
// 오버플로 버킷이 비어있지 않고 오버플로 버킷 내에 요소가 있으면 현재 요소가 마지막이 아님
if b.overflow(t) != nil && b.overflow(t).tophash[0] != emptyRest {
goto notLast
}
} else {
// 인접 요소가 비어있지 않음
if b.tophash[i+1] != emptyRest {
goto notLast
}
}요소가 실제로 마지막 요소라면 버킷 링크드 리스트의 일부 버킷 tophash 배열 값을 수정해야 합니다. 그렇지 않으면 이후 순회 시 올바른 위치에서 종료할 수 없기 때문입니다. map 오버플로 버킷 생성에서 언급했듯이, Go 는 오버플로 버킷 추적 비용을 줄이기 위해 마지막 오버플로 버킷의 overflow 포인터를 헤더 해시 버킷으로 가리키므로, 실제로는 단방향 원형 링크드 리스트이며, 리스트의 "헤더" 는 해시 버킷입니다. 여기서 b 는 검색 후의 b 로, 링크드 리스트 중간某一个 오버플로 버킷일 가능성이 높으므로, 원형 링크드 리스트를 역순으로 순회하여 마지막 존재하는 요소를 찾습니다. 코드는 정순 순회로 작성되었지만, 링크드 리스트가 원형이므로 현재 오버플로 버킷 이전까지 계속 정순 순회하므로 결과적으로는 역순입니다. 그런 다음 버킷 내 tophash 배열을 역순으로 순회하며 emptyOne 상태의 요소를 emptyRest 로 업데이트하고, 마지막 존재하는 요소를 찾을 때까지 계속합니다. 링에서 무한히 빠지는 것을 피하기 위해, 처음 버킷으로 돌아오면, 즉 bOrig 가 되면, 링크드 리스트에 더 이상 사용 가능한 요소가 없으므로 루프를 종료할 수 있습니다.
// 여기까지 실행되면 현재 요소 뒤에 요소가 없음
// bmap 링크드 리스트를 역순으로 순회하고, 버킷 내 tophash 를 역순으로 순회
// emptyOne 상태를 emptyRest 로 업데이트
for {
b.tophash[i] = emptyRest
if i == 0 {
if b == bOrig {
break
}
c := b
// 현재 bmap 링크드 리스트의 이전 것을 찾음
for b = bOrig; b.overflow(t) != c; b = b.overflow(t) {
}
i = bucketCnt - 1
} else {
i--
}
if b.tophash[i] != emptyOne {
break
}
}비우기
go1.21 버전에서 map 의 모든 요소를 비우는 데 사용할 수 있는 내장 함수 clear 가 추가되었으며, 문법은 다음과 같습니다.
clear(dict)내부적으로 runtime.mapclear 함수를 호출하며, 이 함수는 map 의 모든 요소를 삭제하는 역할을 합니다. 함수 시그니처는 다음과 같습니다.
func mapclear(t *maptype, h *hmap)이 함수의 로직은 복잡하지 않으며, 먼저 전체 map 을 empty 로 표시해야 합니다. 해당 코드는 다음과 같습니다.
// 모든 버킷과 오버플로 버킷 순회하며 모든 tophash 요소를 emptyRest 로 설정
markBucketsEmpty := func(bucket unsafe.Pointer, mask uintptr) {
for i := uintptr(0); i <= mask; i++ {
b := (*bmap)(add(bucket, i*uintptr(t.BucketSize)))
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
b.tophash[i] = emptyRest
}
}
}
}
markBucketsEmpty(h.buckets, bucketMask(h.B))위 코드가 수행하는 작업은 모든 버킷을 순회하며 버킷의 tophash 배열 요소를 모두 emptyRest 로 설정하여 map 을 empty 로 표시합니다. 이렇게 하면 이터레이터가 계속 순회하는 것을 방지한 후 map 을 비웁니다. 해당 코드는 다음과 같습니다.
// 해시 시드 리셋
h.hash0 = fastrand()
// extra 구조체 리셋
if h.extra != nil {
*h.extra = mapextra{}
}
// 이 작업은 이전 buckets 메모리를クリア하고 새 버킷을 재할당합니다.
_, nextOverflow := makeBucketArray(t, h.B, h.buckets)
if nextOverflow != nil {
// 새 빈 오버플로 버킷 할당
h.extra.nextOverflow = nextOverflow
}makeBucketArray 를 통해 이전 버킷 메모리를クリア한 후 새로 할당합니다. 이렇게 하면 버킷 삭제가 완료됩니다. 그 외에도 count 를 0 으로 설정하는 등 몇 가지 세부 사항이 있지만, 기타 작업은 자세히 설명하지 않습니다.
확장
이전 모든 작업에서 로직에 더 집중하기 위해 확장과 관련된 많은 내용을 생략했습니다. 이렇게 하면 훨씬 간단해집니다. 확장 로직은 실제로 복잡하며, 마지막에 배치한 것은 간섭을 받지 않기 위함입니다. 이제 Go 가 map 을 어떻게 확장하는지 살펴보겠습니다. 앞서 확장을 트리거하는 두 가지 조건이 있다고 언급했습니다.
- 부하 인자가 6.5 를 초과
- 오버플로 버킷 수가 너무 많음
부하 인자가 임계값을 초과하는지 판단하는 함수는 runtime.overLoadFactor 함수로, 해시 충돌 부분에서 이미 설명했습니다. 오버플로 버킷 수가 너무 많은지 판단하는 함수는 runtime.tooManyOverflowBuckets 으로, 작동 원리도 매우 간단하며 코드는 다음과 같습니다.
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {
if B > 15 {
B = 15
}
return noverflow >= uint16(1)<<(B&15)
}위 코드는 다음과 같이 간소화할 수 있어 한눈에 이해할 수 있습니다.
overflow >= 1 << (min(15,B) % 16)여기서 Go 가 too many 를 정의한 것은 오버플로 버킷 수가 해시 버킷 수와 비슷할 때입니다. 임계값이 낮으면 불필요한 작업을 하게 되고, 임계값이 높으면 확장 시 많은 메모리를 차지하게 됩니다. 요소 수정 및 삭제 시 확장이 트리거될 수 있으며, 확장 필요 여부를 판단하는 코드는 다음과 같습니다.
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // 테이블 확장하면 모든 것이 무효화되므로 다시 시도
}이 세 가지 제한 조건을 볼 수 있습니다.
- 현재 확장 중이 아니어야 함
- 부하 인자가 6.5 미만
- 오버플로 버킷 수가 너무 많지 않아야 함
확장을 담당하는 함수는 자연스럽게 runtime.hashGrow이며, 함수 시그니처는 다음과 같습니다.
func hashGrow(t *maptype, h *hmap)실제로 확장에도 종류가 있으며, 다른 조건에 따라 트리거되는 확장 유형도 다릅니다. 다음 두 가지로 나뉩니다.
- 증량 확장
- 등량 확장
증량 확장
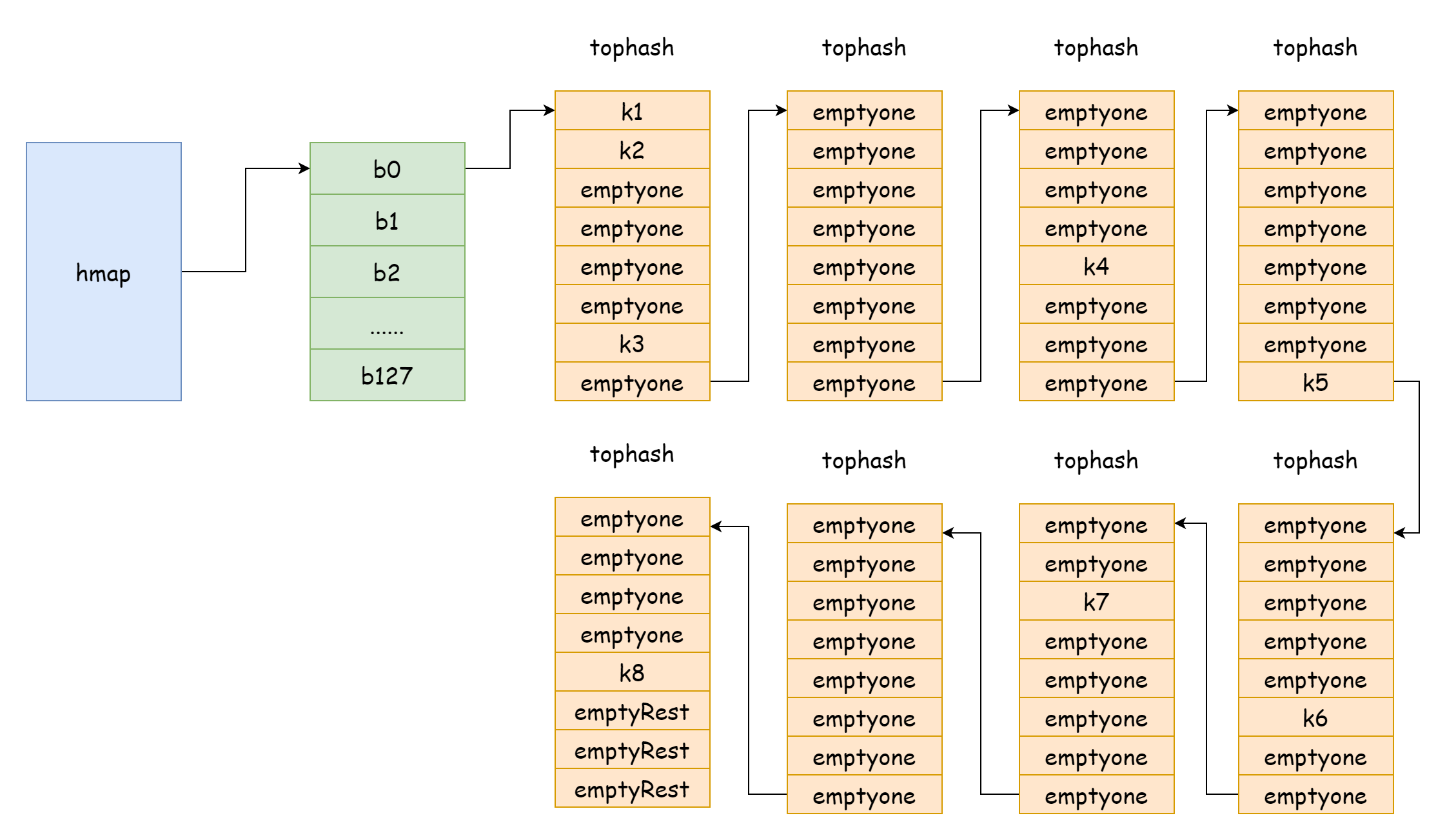
부하 인자가 너무 클 때, 즉 요소 수가 해시 버킷 수보다 클 때, 해시 충돌이 심각하면 많은 오버플로 버킷 링크드 리스트가 형성됩니다. 이렇게 되면 map 읽기 - 쓰기 성능이 저하됩니다. 요소를 찾으려면 더 많은 오버플로 버킷 링크드 리스트를 순회해야 하기 때문입니다. 순회 시간 복잡도는 O(n) 이며, 해시 테이블 검색 시간 복잡도는 해시 값 계산 시간과 순회 시간에 따라 결정됩니다. 순회 시간이 해시 계산 시간보다 훨씬 작을 때 검색 시간 복잡도를 O(1) 이라고 할 수 있습니다. 해시 충돌이 빈번하고 너무 많은 key 가 동일한 해시 버킷에 할당되면 오버플로 버킷 링크드 리스트가 길어져 순회 시간이 증가하고, 검색 시간이 증가하며, 증삭개 작업은 모두 먼저 검색 작업을 수행해야 하므로 전체 map 성능이 심각하게 저하됩니다.
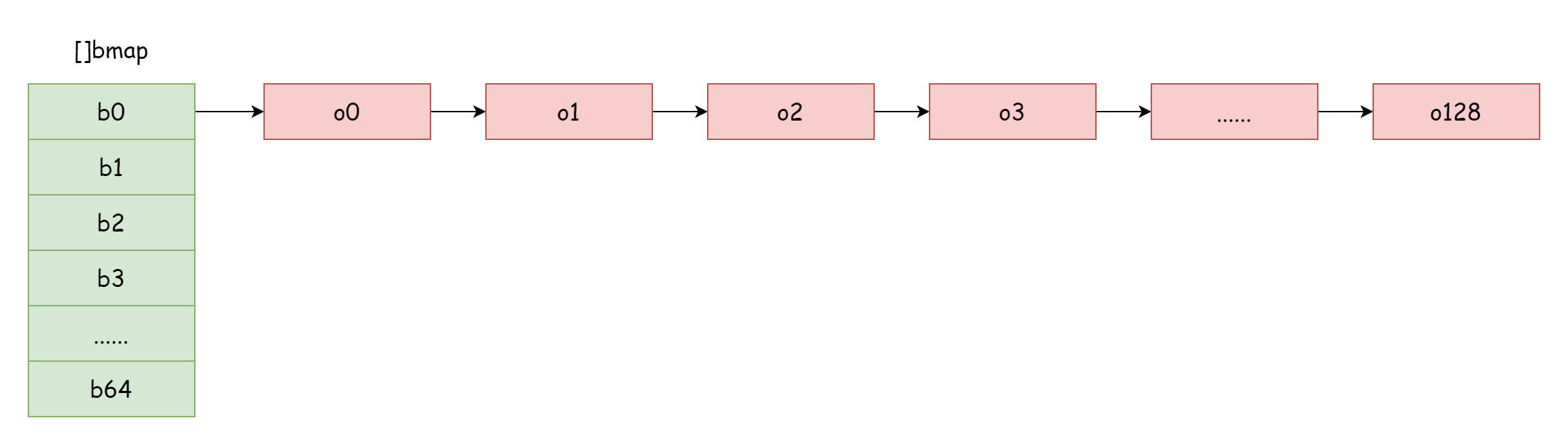
위 그림과 같은 극단적인 경우 검색 시간 복잡도는 기본적으로 O(n) 과 차이가 없습니다. 이러한 상황에 직면하여 해결책은 더 많은 해시 버킷을 추가하여 오버플로 버킷 링크드 리스트가 너무 길어지는 것을 피하는 것입니다. 이 방법을 증량 확장이라고도 합니다.
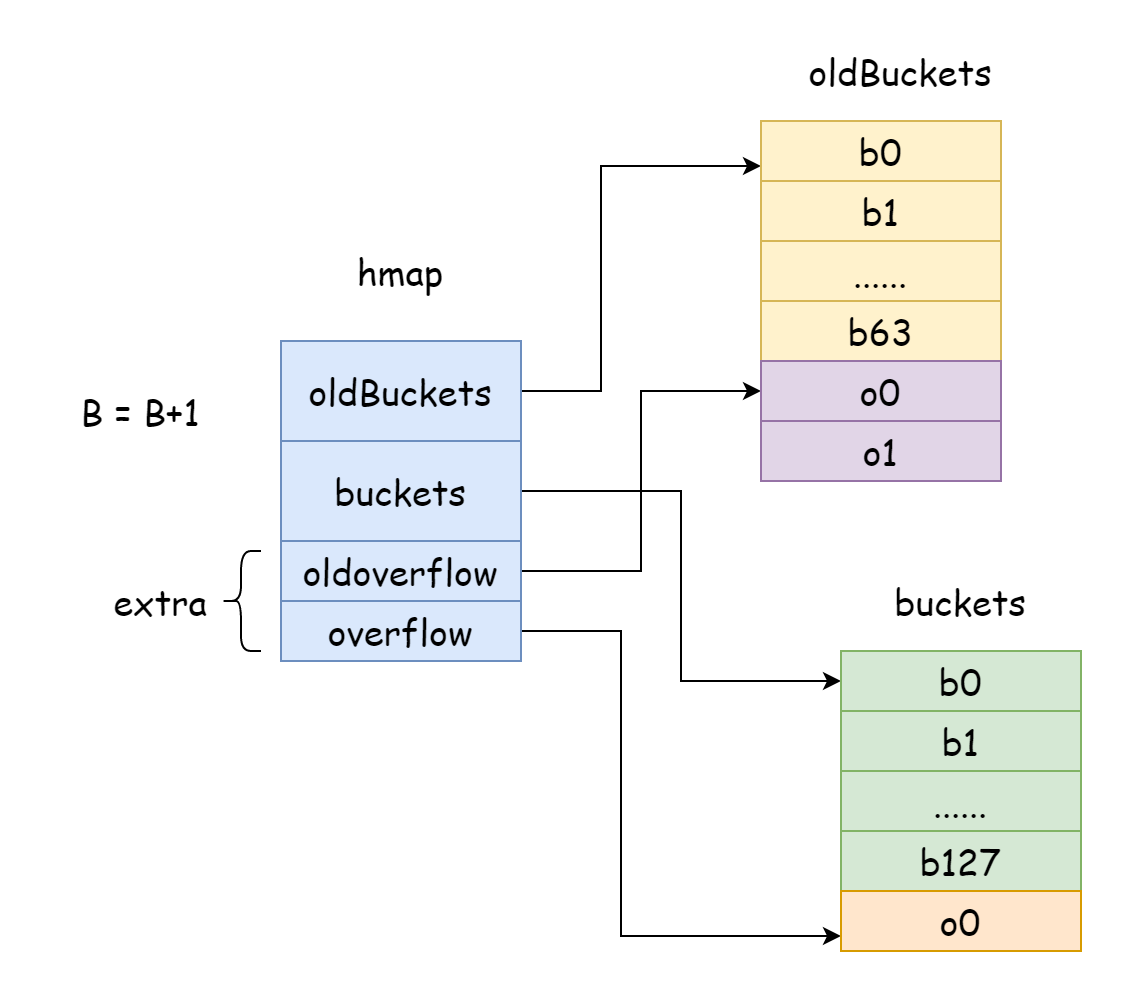
Go 에서 증량 확장은 매번 B 를 1 증가시킵니다. 즉, 해시 버킷 규모를 매번 두 배로 확장합니다. 확장 후 이전 데이터를 새 map 으로 이동해야 합니다. map 의 요소 수가 천만 또는 억 단위로 계산되면 한 번에 모두 이동하는 데 시간이 오래 걸리므로, Go 는 점진적 이동 전략을 채택합니다. 이를 위해 hmap 의 oldBuckets 를 원래 해시 버킷 배열로 가리켜 이전 데이터임을 나타내고, 더 큰 용량의 해시 버킷 배열을 생성하여 hmap 의 buckets 가 새 해시 버킷 배열을 가리키게 합니다. 그런 다음 매번 수정 및 삭제 작업 시 일부 요소를 이전 버킷에서 새 버킷으로 이동하며, 이동이 완료될 때까지 이전 버킷 메모리가 해제되지 않습니다.
func hashGrow(t *maptype, h *hmap) {
// 차이
bigger := uint8(1)
// 이전 버킷
oldbuckets := h.buckets
// 새 해시 버킷
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
flags := h.flags &^ (iterator | oldIterator)
if h.flags&iterator != 0 {
flags |= oldIterator
}
// B+bigger
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
h.nevacuate = 0
h.noverflow = 0
// 오버플로 버킷도 이전 버킷과 새 버킷 지정 필요
if h.extra != nil && h.extra.overflow != nil {
if h.extra.oldoverflow != nil {
throw("oldoverflow is not nil")
}
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
}
if nextOverflow != nil {
if h.extra == nil {
h.extra = new(mapextra)
}
h.extra.nextOverflow = nextOverflow
}
}위 코드가 수행하는 작업은 두 배 용량의 새 해시 버킷을 생성한 후 해시 이전 - 새 버킷 참조 및 오버플로 이전 - 새 버킷 참조를 지정하고, hmap 의 일부 상태를 업데이트하는 것입니다. 실제 이동 작업은 hashGrow 함수로 완료되지 않으며, 이 함수는 이전 - 새 버킷만 지정하고 hmap 의 일부 상태만 업데이트합니다. 이 작업은 실제로 runtime.growWork 함수로 완료되며, 함수 시그니처는 다음과 같습니다.
func growWork(t *maptype, h *hmap, bucket uintptr)이 함수는 mapassign 함수와 mapdelete 함수에서 다음 형태로 호출되며, 역할은 현재 map 이 확장 중이면 일부 이동 작업을 수행하는 것입니다.
if h.growing() {
growWork(t, h, bucket)
}수정 및 삭제 작업 시 현재 확장 중인지 판단해야 하며, 이는 주로 hmap.growing 메서드로 완료됩니다. 내용은 매우 간단하며, oldbuckets 가 비어있지 않은지 판단하는 것입니다. 해당 코드는 다음과 같습니다.
func (h *hmap) growing() bool {
return h.oldbuckets != nil
}growWork 함수가 무엇을 하는지 살펴보겠습니다.
func growWork(t *maptype, h *hmap, bucket uintptr) {
// bucket % 1 << (B-1)
evacuate(t, h, bucket&h.oldbucketmask())
if h.growing() {
evacuate(t, h, h.nevacuate)
}
}여기서 bucket&h.oldbucketmask() 작업은 이전 버킷 위치를 계산하여 이동할 버킷이 현재 버킷의 이전 버킷인지 확인합니다. 함수에서 실제 이동 작업을 담당하는 것은 runtime.evacuate 함수이며, 이동 중 새 버킷을 순회하는 데 사용되는 evaDst 구조체를 사용합니다. 구조는 다음과 같습니다.
type evacDst struct {
b *bmap // 이동 목적지 새 버킷
i int // 버킷 내 인덱스
k unsafe.Pointer // 새 키 목적지를 가리키는 포인터
e unsafe.Pointer // 새 값 목적지를 가리키는 포인터
}이동 시작 전 Go 는 두 개의 evacDst 구조체를 할당합니다. 하나는 새 해시 버킷의 상단 영역을 가리키고, 다른 하나는 새 해시 버킷의 하단 영역을 가리킵니다. 해당 코드는 다음과 같습니다.
// 이전 버킷에서 지정된 해시 버킷 위치
b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.BucketSize)))
// 이전 버킷 길이 = 1 << (B - 1)
newbit := h.noldbuckets()
var xy [2]evacDst
x := &xy[0]
// 새 버킷 상단 영역 가리킴
x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.BucketSize)))
x.k = add(unsafe.Pointer(x.b), dataOffset)
x.e = add(x.k, bucketCnt*uintptr(t.KeySize))
// 등량 확장인지 판단
if !h.sameSizeGrow() {
y := &xy[1]
// 새 버킷 하단 영역 가리킴
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.BucketSize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.e = add(y.k, bucketCnt*uintptr(t.KeySize))
}이전 버킷의 이동 목적지는 두 개의 새 버킷이며, 이동 후 버킷의 일부 데이터는 상단 영역에 있고, 다른 일부 데이터는 하단 영역에 있습니다. 이렇게 하는 것은 확장 후 데이터가 더 균일하게 분포되기를 바라며, 더 균일하게 분포될수록 map 검색 성능이 더 좋아집니다. Go 가 데이터를 어떻게 두 개의 새 버킷으로 이동하는지는 아래 코드에 해당합니다.
// 오버플로 버킷 링크드 리스트 순회
for ; b != nil; b = b.overflow(t) {
// 각 버킷의 첫 번째 키 - 값 쌍 획득
k := add(unsafe.Pointer(b), dataOffset)
e := add(k, bucketCnt*uintptr(t.KeySize))
// 버킷 내 모든 키 - 값 쌍 순회
for i := 0; i < bucketCnt; i, k, e = i+1, add(k, uintptr(t.KeySize)), add(e, uintptr(t.ValueSize)) {
top := b.tophash[i]
// 비어있으면 건너뜀
if isEmpty(top) {
b.tophash[i] = evacuatedEmpty
continue
}
// 새 해시 버킷은 이동 상태에 있으면 안 됨
// 그렇지 않으면 문제 발생
if top < minTopHash {
throw("bad map state")
}
k2 := k
if t.IndirectKey() {
k2 = *((*unsafe.Pointer)(k2))
}
// 이 변수는 현재 키 - 값 쌍이 상단 영역으로 이동하는지 하단 영역으로 이동하는지 결정
// 값은 0 또는 1 이어야 함
var useY uint8
if !h.sameSizeGrow() {
// 해시 값 다시 계산
hash := t.Hasher(k2, uintptr(h.hash0))
// k2 != k2 특수 상황 처리,
if h.flags&iterator != 0 && !t.ReflexiveKey() && !t.Key.Equal(k2, k2) {
useY = top & 1
top = tophash(hash)
} else {
// hash % 1 << (B - 1)
if hash&newbit != 0 {
useY = 1
}
}
}
// 상수 값 확인
if evacuatedX+1 != evacuatedY || evacuatedX^1 != evacuatedY {
throw("bad evacuatedN")
}
// 이전 버킷 tophash 업데이트, 현재 요소가 이동되었음을 나타냄
b.tophash[i] = evacuatedX + useY // evacuatedX + 1 == evacuatedY
// 이동 목적지 지정
dst := &xy[useY] // evacuation destination
// 새 버킷 용량 부족하면 오버플로 버킷 생성
if dst.i == bucketCnt {
dst.b = h.newoverflow(t, dst.b)
dst.i = 0
dst.k = add(unsafe.Pointer(dst.b), dataOffset)
dst.e = add(dst.k, bucketCnt*uintptr(t.KeySize))
}
dst.b.tophash[dst.i&(bucketCnt-1)] = top // mask dst.i as an optimization, to avoid a bounds check
// 키 복사
if t.IndirectKey() {
*(*unsafe.Pointer)(dst.k) = k2 // copy pointer
} else {
typedmemmove(t.Key, dst.k, k) // copy elem
}
// 값 복사
if t.IndirectElem() {
*(*unsafe.Pointer)(dst.e) = *(*unsafe.Pointer)(e)
} else {
typedmemmove(t.Elem, dst.e, e)
}
// 다음 키 - 값 준비를 위해 새 버킷 목적 포인터 후진
dst.i++
dst.k = add(dst.k, uintptr(t.KeySize))
dst.e = add(dst.e, uintptr(t.ValueSize))
}
}위 코드에서 Go 는 이전 버킷 링크드 리스트의 모든 버킷의 모든 요소를 순회하며, 그 데이터를 새 버킷으로 이동합니다. 데이터가 상단 영역으로 이동하는지 하단 영역으로 이동하는지는 다시 계산된 해시 값에 따라 결정됩니다.
// hash % 1 << (B - 1)
if hash&newbit != 0 {
useY = 1
}이동 후 현재 요소의 tophash 를 evacuatedX 또는 evacuated 로 설정합니다. 확장 중 데이터를 검색하려고 하면 이 상태를 통해 데이터가 이동되었음을 알 수 있고, 새 버킷에서 해당 데이터를 찾아야 함을 알 수 있습니다. 이 부분 로직은 runtime.mapaccess1 함수의 다음 코드에 해당합니다.
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
// 이전에는 버킷이 절반이었음; 2 의 거듭제곱을 하나 더 낮춤
m >>= 1
}
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.BucketSize)))
// 이전 버킷이 이미 이동되었으면 찾지 않음
if !evacuated(oldb) {
b = oldb
}
}요소 액세스 시 현재 확장 상태이면 먼저 이전 버킷에서 찾기를 시도하며, 이전 버킷이 이미 이동되었으면 이전 버킷에서 찾지 않습니다. 이동 부분으로 돌아가면 이제 이동 목적지를 결정했으므로 데이터를 새 버킷으로 복사한 후 evacDst 구조체가 다음 목적지를 가리키게 합니다.
dst := &xy[useY]
dst.b.tophash[dst.i&(bucketCnt-1)] = top
typedmemmove(t.Key, dst.k, k)
typedmemmove(t.Elem, dst.e, e)
if h.flags&oldIterator == 0 && t.Bucket.PtrBytes != 0 {
b := add(h.oldbuckets, oldbucket*uintptr(t.BucketSize))
ptr := add(b, dataOffset)
n := uintptr(t.BucketSize) - dataOffset
memclrHasPointers(ptr, n)
}이렇게 작업하여 현재 버킷이 모두 이동될 때까지 진행한 후, Go 는 현재 이전 버킷 키 - 값 데이터를 모두 메모리에서クリア하며, 해시 버킷 tophash 배열만 남깁니다 (tophash 배열을 남기는 이유는 이후 tophash 배열로 이동 상태를 판단하기 위함입니다). 이전 버킷의 오버플로 버킷 메모리는 더 이상 참조되지 않으므로 이후 GC 에 의해 회수됩니다. hmap 에는 nevacuate 필드가 있어 이동 진행 상황을 기록하며, 이전 해시 버킷을 이동할 때마다 1 씩 증가합니다. 이 값이 이전 버킷 수와 같아지면 전체 map 확장이 완료된 것이며, 다음으로 runtime.advanceEvacuationMark 함수가 확장 마무리 작업을 수행합니다.
func advanceEvacuationMark(h *hmap, t *maptype, newbit uintptr) {
h.nevacuate++
stop := h.nevacuate + 1024
if stop > newbit {
stop = newbit
}
for h.nevacuate != stop && bucketEvacuated(t, h, h.nevacuate) {
h.nevacuate++
}
if h.nevacuate == newbit { // newbit = len(oldbuckets)
h.oldbuckets = nil
if h.extra != nil {
h.extra.oldoverflow = nil
}
h.flags &^= sameSizeGrow
}
}이 함수는 이동된 수량을 통계하고 이전 버킷 수와 같은지 확인하며, 같으면 모든 이전 버킷과 이전 오버플로 버킷에 대한 참조를クリア합니다.至此 확장 완료입니다.
growWork 함수에서 총 두 번 evacuate 함수를 호출합니다. 첫 번째는 현재 액세스 중인 버킷의 이전 버킷을 이동하고, 두 번째는 h.nevacuate 가 가리키는 이전 버킷을 이동합니다. 총 두 개의 버킷을 이동하므로, 점진적 이동 시 매번 두 개의 버킷을 이동합니다.
등량 확장
앞서 언급했듯이 등량 확장은 오버플로 버킷 수가 너무 많을 때 트리거됩니다. map 에 먼저 많은 요소가 추가된 후 많은 요소를 삭제하면 많은 버킷이 비어있을 수 있으며, 일부 버킷에는 많은 요소가 있어 데이터 분포가 매우 불균일하고, 상당수의 오버플로 버킷이 비어있어 많은 메모리를 차지합니다. 이러한 문제를 해결하기 위해 동일한 용량의 새 map 을 생성하고 해시 버킷을 다시 할당해야 합니다. 이 과정을 등량 확장이라고 합니다. 따라서 실제로는 확장 작업이 아니며, 모든 요소를 다시 할당하여 데이터 분포를 더 균일하게 만드는 것입니다. 등량 확장 작업은 증량 확장 작업에 통합되며, 이전 - 새 map 용량이 완전히 동일합니다.
hashGrow 함수에서 부하 인자가 임계값을 초과하지 않으면 등량 확장을 수행합니다. Go 는 h.flags 상태를 sameSizeGrow 로 업데이트하며, h.B 는 1 증가하지 않으므로 새로 생성된 해시 버킷 용량도 변하지 않습니다. 해당 코드는 다음과 같습니다.
bigger := uint8(1)
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
h.flags |= sameSizeGrow
}
oldbuckets := h.buckets
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)evacuate 함수에서刚开始 eavcDst 구조체를 생성할 때 등량 확장이라면 새 버킷을 가리키는 구조체만 하나 생성합니다. 해당 코드는 다음과 같습니다.
if !h.sameSizeGrow() {
y := &xy[1]
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.BucketSize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.e = add(y.k, bucketCnt*uintptr(t.KeySize))
}그리고 요소 이동 시 등량 확장은 해시 값을 다시 계산하지 않으며, 상단 - 하단 영역 선택도 없습니다.
if !h.sameSizeGrow() {
// 해시 값 다시 계산
hash := t.Hasher(k2, uintptr(h.hash0))
// k2 != k2 특수 상황 처리,
if h.flags&iterator != 0 && !t.ReflexiveKey() && !t.Key.Equal(k2, k2) {
useY = top & 1
top = tophash(hash)
} else {
// hash % 1 << (B - 1)
if hash&newbit != 0 {
useY = 1
}
}
}이 외의 다른 로직은 증량 확장과 완전히 동일합니다. 등량 확장을 통해 해시 버킷이 다시 할당된 후 오버플로 버킷 수가 감소하며, 이전 오버플로 버킷은 모두 GC 에 의해 회수됩니다.