Go 구조체
구조체는 서로 다른 타입의 데이터 그룹을 저장할 수 있는 복합 타입입니다. Go 는 클래스와 상속을 버렸으며 생성자 메서드도 버렸습니다. 객체 지향 기능을 의도적으로 약화시켰으며 Go 는 전통적인 OOP 언어가 아니지만 OOP 의 흔적이 남아있으며 구조체와 메서드를 통해 클래스를 모방할 수 있습니다. 다음은 간단한 구조체 예시입니다.
type Programmer struct {
Name string
Age int
Job string
Language []string
}선언
구조체 선언은 매우 간단합니다. 예시는 다음과 같습니다.
type Person struct {
name string
age int
}구조체 자체와 내부 필드는 모두 대소문자 명명 규칙을 따릅니다. 동일한 타입의 인접한 필드는 타입을 반복해서 선언할 필요가 없습니다. 다음과 같습니다.
type Rectangle struct {
height, width, area int
color string
}TIP
구조체 필드를 선언할 때 필드명은 메서드명과 중복될 수 없습니다.
인스턴스화
Go 에는 생성자 메서드가 없으며, 대부분의 경우 다음과 같은 방식으로 구조체를 인스턴스화합니다. 초기화할 때는 map 처럼 필드명을 지정한 후 필드값을 초기화합니다.
programmer := Programmer{
Name: "jack",
Age: 19,
Job: "coder",
Language: []string{"Go", "C++"},
}필드명을 생략할 수도 있습니다. 필드명을 생략할 때는 모든 필드를 초기화해야 합니다. 일반적으로 가독성이 나쁘므로 이 방식을 권장하지 않습니다.
programmer := Programmer{
"jack",
19,
"coder",
[]string{"Go", "C++"}}인스턴스화 과정이 복잡하다면 구조체를 인스턴스화하는 함수를 작성할 수 있습니다. 다음과 같습니다. 이를 생성자 함수로 이해할 수도 있습니다.
type Person struct {
Name string
Age int
Address string
Salary float64
}
func NewPerson(name string, age int, address string, salary float64) *Person {
return &Person{Name: name, Age: age, Address: address, Salary: salary}
}하지만 Go 는 함수와 메서드 오버로드를 지원하지 않으므로 동일한 함수나 메서드에 서로 다른 매개변수를 정의할 수 없습니다. 다양한 방식으로 구조체를 인스턴스화하려면 여러 생성자 함수를 만들거나 options 패턴을 사용하는 것을 권장합니다.
옵션 패턴
옵션 패턴은 Go 언어에서 매우 흔한 디자인 패턴으로, 구조체를 더 유연하게 인스턴스화할 수 있으며 확장성이 뛰어나고 생성자 함수의 시그니처를 변경할 필요가 없습니다. 다음과 같은 구조체가 있다고 가정합니다.
type Person struct {
Name string
Age int
Address string
Salary float64
Birthday string
}PersonOptions 타입을 선언합니다. 이는 *Person 타입 매개변수를 받으며, 반드시 포인터여야 합니다. 클로저에서 Person 에 값을 할당해야 하기 때문입니다.
type PersonOptions func(p *Person)다음으로 옵션 함수를 생성합니다. 이들은 일반적으로 With 로 시작하며 반환값은 클로저 함수입니다.
func WithName(name string) PersonOptions {
return func(p *Person) {
p.Name = name
}
}
func WithAge(age int) PersonOptions {
return func(p *Person) {
p.Age = age
}
}
func WithAddress(address string) PersonOptions {
return func(p *Person) {
p.Address = address
}
}
func WithSalary(salary float64) PersonOptions {
return func(p *Person) {
p.Salary = salary
}
}실제로 선언된 생성자 함수 시그니처는 다음과 같습니다. 이는 가변 길이 PersonOptions 타입 매개변수를 받습니다.
func NewPerson(options ...PersonOptions) *Person {
// options 우선 적용
p := &Person{}
for _, option := range options {
option(p)
}
// 기본값 처리
if p.Age < 0 {
p.Age = 0
}
......
return p
}이렇게 하면 서로 다른 인스턴스화 요구사항에 대해 하나의 생성자 함수로 완료할 수 있으며, 서로 다른 Options 함수만 전달하면 됩니다.
func main() {
p1 := NewPerson(
WithName("John Doe"),
WithAge(25),
WithAddress("123 Main St"),
WithSalary(10000.00),
)
p2 := NewPerson(
WithName("Mike jane"),
WithAge(30),
)
}함수형 옵션 패턴은 많은 오픈소스 프로젝트에서 볼 수 있으며, gRPC Server 의 인스턴스화 방식도 이 디자인 패턴을 채택했습니다. 함수형 옵션 패턴은 복잡한 인스턴스화에 적합합니다. 매개변수가 간단한 몇 개뿐이라면 일반적인 생성자 함수를 사용하는 것을 권장합니다.
조합
Go 에서 구조체 간의 관계는 조합을 통해 표현되며, 명시적 조합과 익명 조합이 있습니다. 후자는 상속과 더 유사하게 사용되지만 본질적으로 변화는 없습니다. 예를 들어:
명시적 조합 방식
type Person struct {
name string
age int
}
type Student struct {
p Person
school string
}
type Employee struct {
p Person
job string
}사용할 때는 명시적으로 필드 p 를 지정해야 합니다.
student := Student{
p: Person{name: "jack", age: 18},
school: "lili school",
}
fmt.Println(student.p.name)익명 조합은 필드를 명시적으로 지정할 필요가 없습니다.
type Person struct {
name string
age int
}
type Student struct {
Person
school string
}
type Employee struct {
Person
job string
}익명 필드의 이름은 기본적으로 타입명이며, 호출자는 해당 타입의 필드와 메서드에 직접 액세스할 수 있습니다. 첫 번째 방식보다 더 편리할 뿐 다른 차이점은 없습니다.
student := Student{
Person: Person{name: "jack",age: 18},
school: "lili school",
}
fmt.Println(student.name)포인터
구조체 포인터의 경우 역참조 없이도 구조체 내용에 직접 액세스할 수 있습니다. 예시는 다음과 같습니다.
p := &Person{
name: "jack",
age: 18,
}
fmt.Println(p.age,p.name)컴파일 시 (*p).name, (*p).age 로 변환됩니다. 실제로는 역참조가 필요하지만 코딩 시 생략할 수 있어 일종의 문법 설탕입니다.
태그
구조체 태그는 메타프로그래밍의 한 형태로, 리플렉션과 결합하여 다양한 기능을 구현할 수 있습니다. 형식은 다음과 같습니다.
`key1:"val1" key2:"val2"`태그는 키 - 값 쌍 형태로 공백으로 구분됩니다. 구조체 태그의 내결함성은 매우 낮아 올바른 형식으로 작성하지 않으면 태그를 정상적으로 읽을 수 없지만, 컴파일 시에는 오류가 발생하지 않습니다. 다음은 사용 예시입니다.
type Programmer struct {
Name string `json:"name"`
Age int `yaml:"age"`
Job string `toml:"job"`
Language []string `properties:"language"`
}구조체 태그는 다양한 직렬화 형식에서 별칭 정의로 가장 널리 사용됩니다. 태그 사용은 리플렉션과 결합해야만 완전한 기능을 발휘할 수 있습니다.
메모리 정렬
Go 구조체 필드의 메모리 분포는 메모리 정렬 규칙을 따릅니다. 이렇게 하면 CPU 의 메모리 액세스 횟수를 줄일 수 있지만,相应으로 더 많은 메모리를 차지합니다. 이는 공간으로 시간을 교환하는 일종의 방법입니다. 다음과 같은 구조체가 있다고 가정합니다.
type Num struct {
A int64
B int32
C int16
D int8
E int32
}이들 타입의 바이트 점유량을 알고 있습니다.
int64는 8 바이트 차지int32는 4 바이트 차지int16는 2 바이트 차지int8는 1 바이트 차지
전체 구조체의 메모리 점유량은 8+4+2+1+4=19 바이트일까요? 물론 아닙니다. 메모리 정렬 규칙에 따르면 구조체의 메모리 점유 길이는 최대 필드의 정수배여야 하며, 부족하면 채웁니다. 해당 구조체에서 가장 큰 것은 int64 로 8 바이트를 차지하므로 메모리 분포는 아래 그림과 같습니다.
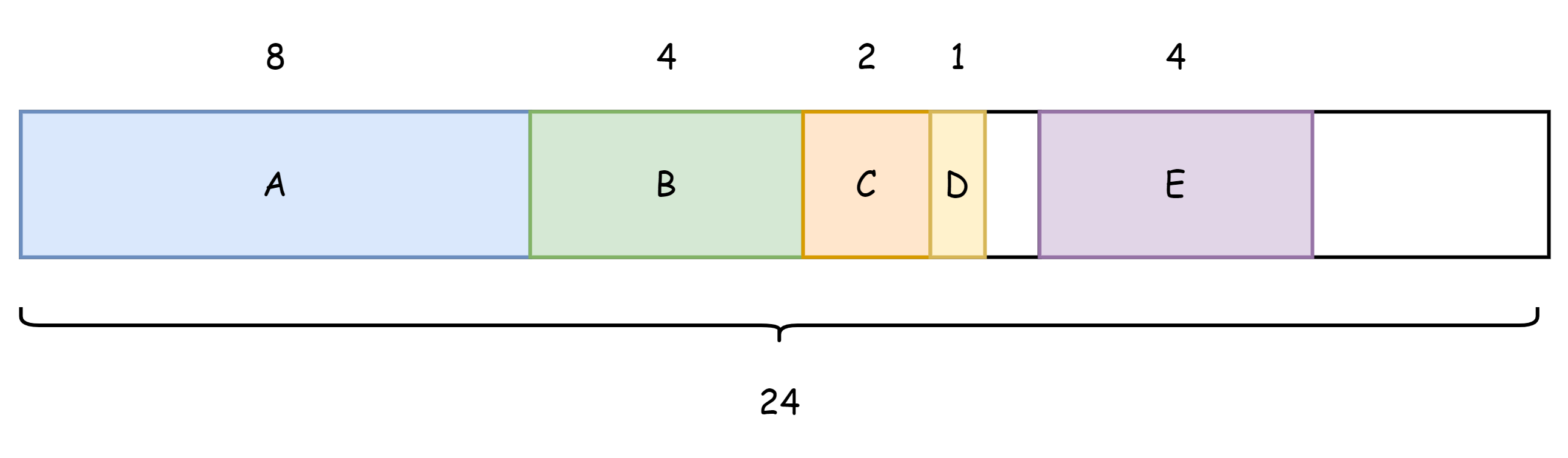
따라서 실제로는 24 바이트를 차지하며, 이 중 5 바이트는 무용입니다.
다음 구조체를 보겠습니다.
type Num struct {
A int8
B int64
C int8
}위의 규칙을 이해하면 메모리 점유량이 24 바이트임을 빠르게 이해할 수 있습니다. 필드가 세 개뿐이지만 14 바이트나 낭비됩니다.

하지만 필드를 조정하여 다음과 같은 순서로 변경할 수 있습니다.
type Num struct {
A int8
C int8
B int64
}이렇게 하면 점유 메모리가 16 바이트로 줄어들며 6 바이트만 낭비되어 8 바이트의 메모리 낭비를 줄였습니다.
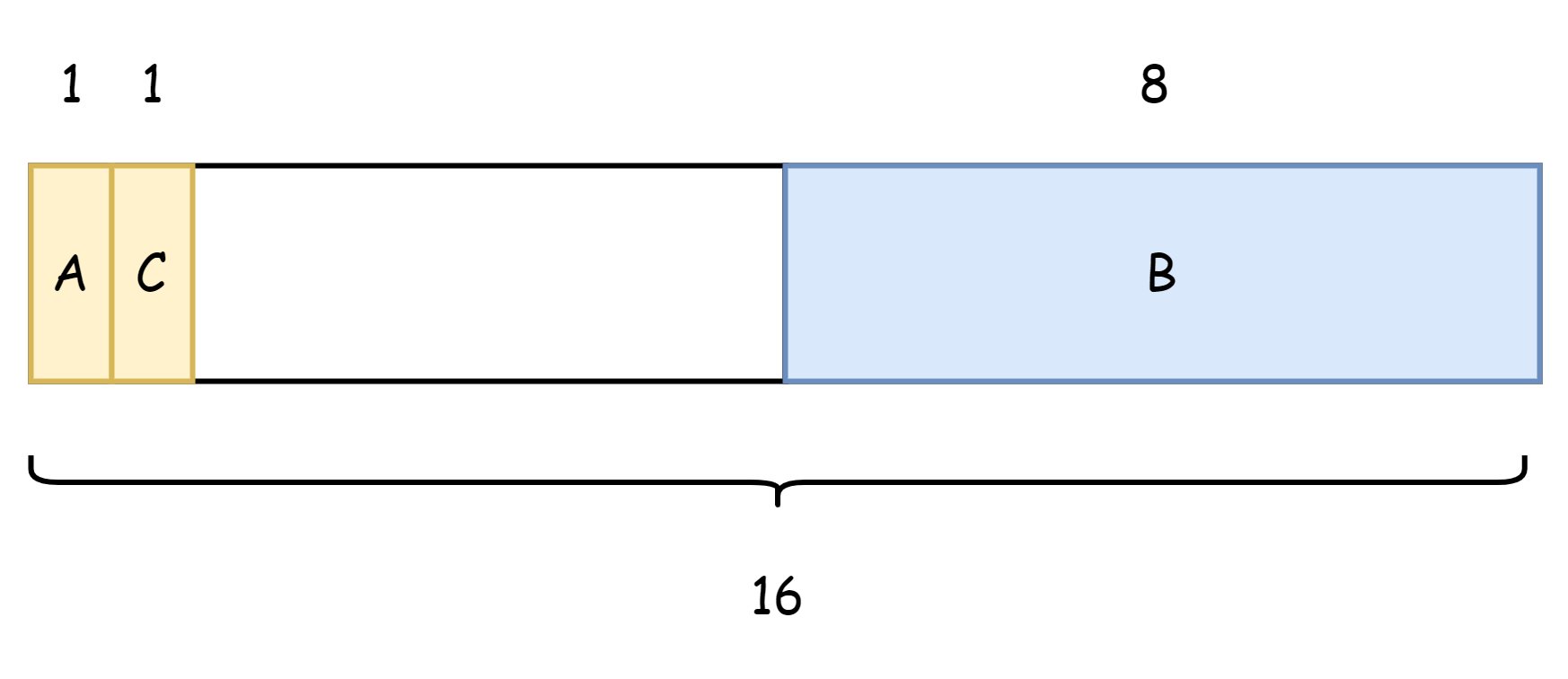
이론적으로는 구조체의 필드를 합리적인 순서로 배치하면 메모리 점유량을 줄일 수 있습니다. 하지만 실제 코딩 과정에서는 이를 위해 필드를 재배열할 필요는 없습니다. 메모리 점유량 감소 측면에서 실질적인 개선을 가져오지 않을 뿐만 아니라 개발자의 부담과 인지 부하를 반드시 증가시키기 때문입니다. 특히 비즈니스에서 일부 구조체의 필드 수가 수십 개 또는 수백 개에 달할 수 있으므로 이해만 하면 됩니다.
TIP
정말로 이러한 방법으로 메모리를 절약하고 싶다면 다음 두 라이브러리를 참고하세요.
이들은 소스 코드의 구조체를 검사하고 계산하여 구조체 필드를 재배열하여 구조체가 점유하는 메모리를 최소화합니다.
빈 구조체
빈 구조체는 필드가 없으며 메모리 공간을 차지하지 않습니다. unsafe.Sizeof 함수를 사용하여 점유 바이트 크기를 계산할 수 있습니다.
func main() {
type Empty struct {}
fmt.Println(unsafe.Sizeof(Empty{}))
}출력
0빈 구조체의 사용 시나리오는 다양합니다. 예를 들어 앞서 언급한 바와 같이 map 의 값 타입으로 사용하여 map 을 set 으로 사용할 수 있으며, 또는 채널 타입으로 사용하여 알림 전용 채널을 나타낼 수도 있습니다.