gmp
Go 언어의 가장 큰 특징 중 하나는 동시성에 대한 네이티브 지원이며, 단 하나의 키워드만으로 코루틴을 시작할 수 있습니다. 아래 예제에서 보여주는 바와 같습니다.
import (
"fmt"
"sync"
)
func main() {
var wg sync.WaitGroup
wg.Add(2)
go func() {
defer wg.Done()
fmt.Println("hello world!")
}()
go func() {
defer wg.Done()
fmt.Println("hello world too!")
}()
wg.Wait()
}Go 언어의 코루틴 사용은 매우 간단하며, 개발자는 추가 작업을 거의 할 필요가 없습니다. 이것이 Go 가 인기 있는 이유 중 하나입니다. 하지만 간단한 뒤에는 간단하지 않은 동시성 스케줄러가 이를 뒷받침하고 있습니다. 이 이름은 여러분이 어느 정도 들어보셨을 것입니다. 주요 참여자가 각각 G(코루틴), M(시스템 스레드), P(프로세서) 이 세 구성원으로 이루어져 있기 때문에 GMP 스케줄러라고도 불립니다. GMP 스케줄러의 설계는 Go 런타임 전체 설계에 영향을 미쳤으며, GC, 네트워크 폴러 등可以说它就是整个语言最核心的一块,如果对它能够有一定的了解,在日后的工作中说不定会有些许帮助。
역사
Go 언어의 동시성 스케줄 모델은 완전히 독창적인 것은 아니며, 많은 선배들의 경험과 교훈을 흡수하여 끊임없이 발전하고 개선하여 현재의 모습을 갖췄습니다. 영향을 받은 언어는 다음과 같습니다:
- Occam -1983
- Erlang - 1986
- Newsqueak - 1988
- Concurrent ML - 1993
- Alef - 1995
- Limbo - 1996
가장 큰 영향을 준 것은 1978 년 홀이 발표한 CSP(Communicate Sequential Process) 에 관한 논문입니다. 이 논문의 기본 사상은 프로세스 간 통신을 통해 데이터를 교환한다는 것입니다. 위의 여러 프로그래밍 언어는 모두 CSP 사상의 영향을 받았으며, Erlang 은 가장 대표적인 메시지 지향 프로그래밍 언어입니다. 유명한 오픈소스 메시지 큐 미들웨어인 RabbitMQ 는 Erlang 으로 작성되었습니다. 오늘날 컴퓨터와 인터넷의 발전에 따라 동시성 지원은 거의 현대 언어의 표준 구성이 되었으며, CSP 사상을 결합한 Go 언어가 탄생했습니다.
스케줄 모델
먼저 GMP 를 구성하는 세 구성원을 간단히 소개하겠습니다.
- G, Goroutine, Go 언어의 코루틴을 의미합니다.
- M, Machine, 시스템 스레드 또는 작업 스레드 (worker thread) 를 의미하며, 운영체제가 스케줄링을 담당합니다.
- P, Processor, CPU 프로세서를 지칭하는 것이 아니라 Go 가 자체적으로 추상화한 개념으로, 시스템 스레드에서 작동하는 프로세서를 의미하며, 이를 통해 각 시스템 스레드의 코루틴을 스케줄링합니다.
코루틴은 더 가벼운 스레드이며, 규모가 더 작고 필요한 자원도 더 적으며, 생성 및 소멸과 스케줄링 시기는 Go 런타임이 담당하며 운영체제가 아니므로 관리 비용이 스레드보다 훨씬 낮습니다. 하지만 코루틴도 스레드에 의존하며, 코루틴 실행에 필요한 시간 조각은 스레드에서 오고, 스레드의 시간 조각은 운영체제에서 옵니다. 서로 다른 스레드 간 전환에는 일정한 비용이 발생합니다. 코루틴이 스레드의 시간 조각을 어떻게 잘 활용하느냐가 설계의 핵심입니다.
1:N
문제를 해결하는 가장 좋은 방법은 문제를 무시하는 것입니다. 스레드 전환에 비용이 든다면 직접 전환하지 않으면 됩니다. 모든 코루틴을 하나의 커널 스레드에 할당하면 코루틴 간 전환만涉及됩니다.
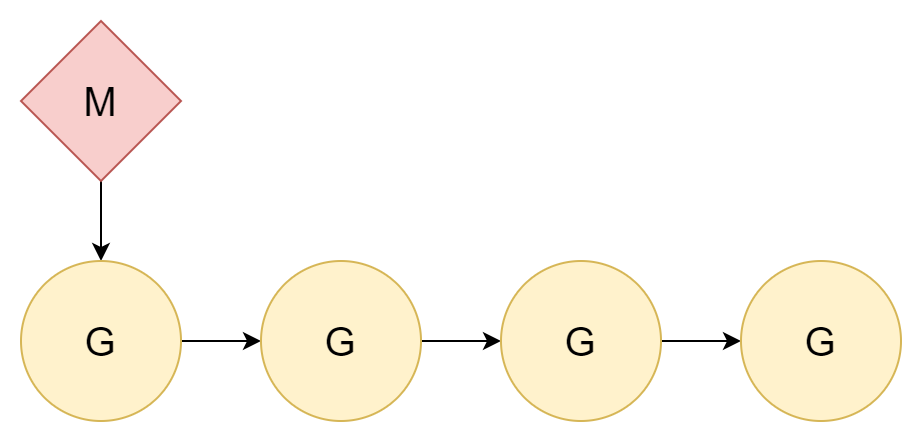
스레드와 코루틴 간 관계는 1:N입니다. 이렇게 하는 데는 매우 명확한 단점이 있습니다. 오늘날 컴퓨터는 거의 대부분 멀티 코어 CPU 인데, 이러한 할당은 멀티 코어 CPU 성능을 충분히 활용할 수 없습니다.
N:N
다른 방법으로, 하나의 스레드가 하나의 코루틴에 대응하면 하나의 코루틴이 해당 스레드의 모든 시간 조각을 즐길 수 있으며, 여러 스레드도 멀티 코어 CPU 성능을 활용할 수 있습니다. 하지만 스레드 생성 및 전환 비용은 비교적 높으며, 1 대 1 관계라면 코루틴의 경량화 장점을 잘 살리지 못한 것입니다.
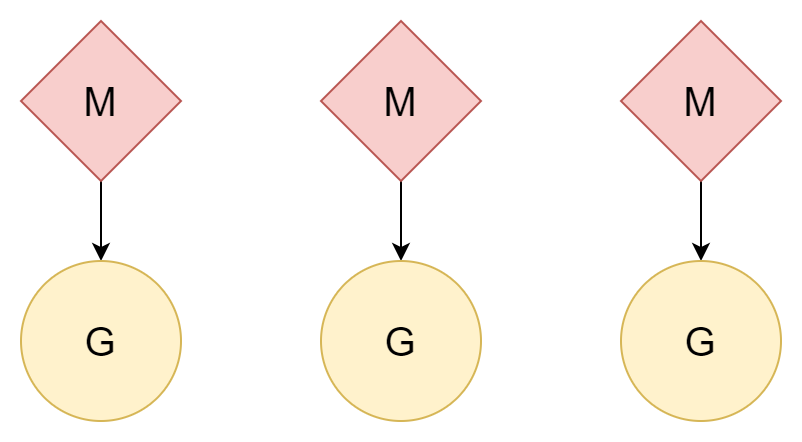
M:N
M 개의 스레드가 N 개의 코루틴에 대응하며, M 은 N 보다 작습니다. 여러 스레드가 여러 코루틴에 대응하며, 각 스레드는若干개의 코루틴에 대응합니다. 프로세서 P 가 코루틴 G 가 스레드의 시간 조각을 어떻게 사용할지 스케줄링합니다. 이 방법이 상대적으로 가장 좋은 방법이며, Go 가 지금까지 계속 사용해 온 스케줄 모델입니다.
M 은 프로세서 P 와 연관된 후에야 작업을 실행할 수 있습니다. Go 는 GOMAXPROCS개의 프로세서를 생성하며, 실제로 작업을 실행할 수 있는 스레드 수는 GOMAXPROCS개입니다. 기본값은 현재 머신의 CPU 논리 코어 수이며, 수동으로 값을 설정할 수도 있습니다.
코드로
runtime.GOMAXPROCS(N)수정, 런타임에 동적으로 조정 가능하며, 호출 후 바로 STW 합니다.환경 변수 설정
export GOMAXPROCS=N, 정적입니다.
실제 상황에서 M 의 수는 P 의 수보다 많습니다. 런타임에 다른 작업을 처리해야 하기 때문입니다. 예를 들어 일부 시스템 호출 등이며, 최대값은 10000 입니다.
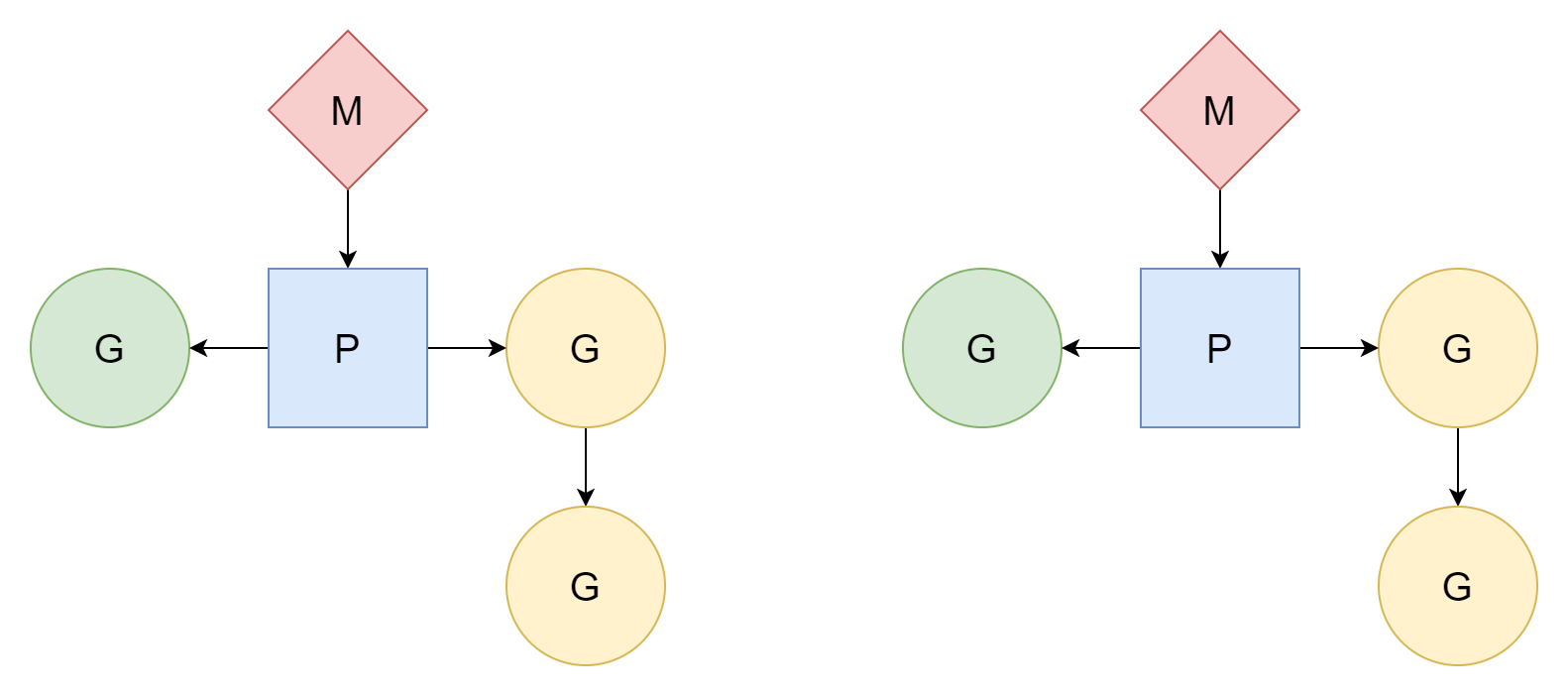
GMP 이 세 참여자와 스케줄러 자체는 런타임에 해당하는 유형 표현이 있으며, 모두 runtime/runtime2.go 파일에 있습니다. 아래에서는 구조를 간단히 소개하여 뒷부분 이해를 돕겠습니다.
G
G 는 런타임에서 runtime.g 구조체로 표현되며, 스케줄 모델의 가장 기본적인 스케줄 단위입니다. 구조는 다음과 같습니다. 이해를 돕기 위해 많은 필드를 삭제했습니다.
type g struct {
stack stack // offset known to runtime/cgo
_panic *_panic // innermost panic - offset known to liblink
_defer *_defer // innermost defer
m *m // current m; offset known to arm liblink
sched gobuf
goid uint64
waitsince int64 // approx time when the g become blocked
waitreason waitReason // if status==Gwaiting
atomicstatus atomic.Uint32
preempt bool // preemption signal, duplicates stackguard0 = stackpreempt
startpc uintptr // pc of goroutine function
parentGoid uint64 // goid of goroutine that created this goroutine
waiting *sudog // sudog structures this g is waiting on (that have a valid elem ptr); in lock order
}첫 번째 필드는 해당 코루틴의 스택 메모리 시작 주소와 종료 주소입니다.
type stack struct {
lo uintptr
hi uintptr
}_panic과 _defer는 각각 panic 스택과 defer 스택을 가리키는 포인터입니다.
_panic *_panic // innermost panic - offset known to liblink
_defer *_defer // innermost deferm은 현재 g 의 코루틴을 실행하는 중입니다.
m *m // current m; offset known to arm liblinkpreempt는 현재 코루틴이 선점될 필요가 있는지를 나타내며, g.stackguard0 = stackpreempt와 동일합니다.
preempt bool // preemption signal, duplicates stackguard0 = stackpreemptatomicstatus는 코루틴 G 의 상태 값을 저장하는 데 사용되며, 다음과 같은 선택 값이 있습니다.
| 이름 | 설명 |
|---|---|
| _Gidle | 갓 할당되었으며 초기화되지 않음 |
| _Grunnable | 현재 코루틴이 실행 가능함을 나타내며, 대기 큐에 있음 |
| _Grunning | 현재 코루틴이 사용자 코드를 실행 중임을 나타냄 |
| _Gsyscall | M 이 할당되어 시스템 호출을 실행하는 중 |
| _Gwaiting | 코루틴이 블럭됨, 블럭 원인은 아래 참조 |
| _Gdead | 현재 코루틴이 사용되지 않음을 나타내며, 갓 종료되었거나 갓 초기화되었을 수 있음 |
| _Gcopystack | 코루틴 스택이 이동 중임을 나타내며, 이 기간 동안 사용자 코드를 실행하지 않으며 대기 큐에도 있지 않음 |
| _Gpreempted | 자체적으로 블럭되어 선점에 진입하며, 선점 측이 깨우기를 기다림 |
| _Gscan | GC 가 코루틴 스택 공간을 스캔하는 중이며, 다른 상태와 공존 가능 |
sched는 코루틴 컨텍스트 정보를 저장하여 코루틴 실행 현장을 복구하는 데 사용됩니다. sp, pc, ret 포인터가 저장되어 있는 것을 볼 수 있습니다.
type gobuf struct {
sp uintptr
pc uintptr
g guintptr
ctxt unsafe.Pointer
ret uintptr
lr uintptr
bp uintptr // for framepointer-enabled architectures
}waiting은 현재 코루틴이 기다리는 코루틴을 나타내며, waitsince는 코루틴이 블럭된 시점을 기록하고, waitreason은 코루틴이 블럭된 원인을 나타냅니다. 선택 값은 다음과 같습니다.
var waitReasonStrings = [...]string{
waitReasonZero: "",
waitReasonGCAssistMarking: "GC assist marking",
waitReasonIOWait: "IO wait",
waitReasonChanReceiveNilChan: "chan receive (nil chan)",
waitReasonChanSendNilChan: "chan send (nil chan)",
waitReasonDumpingHeap: "dumping heap",
waitReasonGarbageCollection: "garbage collection",
waitReasonGarbageCollectionScan: "garbage collection scan",
waitReasonPanicWait: "panicwait",
waitReasonSelect: "select",
waitReasonSelectNoCases: "select (no cases)",
waitReasonGCAssistWait: "GC assist wait",
waitReasonGCSweepWait: "GC sweep wait",
waitReasonGCScavengeWait: "GC scavenge wait",
waitReasonChanReceive: "chan receive",
waitReasonChanSend: "chan send",
waitReasonFinalizerWait: "finalizer wait",
waitReasonForceGCIdle: "force gc (idle)",
waitReasonSemacquire: "semacquire",
waitReasonSleep: "sleep",
waitReasonSyncCondWait: "sync.Cond.Wait",
waitReasonSyncMutexLock: "sync.Mutex.Lock",
waitReasonSyncRWMutexRLock: "sync.RWMutex.RLock",
waitReasonSyncRWMutexLock: "sync.RWMutex.Lock",
waitReasonTraceReaderBlocked: "trace reader (blocked)",
waitReasonWaitForGCCycle: "wait for GC cycle",
waitReasonGCWorkerIdle: "GC worker (idle)",
waitReasonGCWorkerActive: "GC worker (active)",
waitReasonPreempted: "preempted",
waitReasonDebugCall: "debug call",
waitReasonGCMarkTermination: "GC mark termination",
waitReasonStoppingTheWorld: "stopping the world",
}goid와 parentGoid는 현재 코루틴과 부모 코루틴의 고유 식별자이며, startpc는 현재 코루틴 진입 함수의 주소입니다.
M
M은 런타임에서 runtime.m 구조체로 표현되며, 작업 스레드에 대한 추상화입니다.
type m struct {
id int64
g0 *g // goroutine with scheduling stack
curg *g // current running goroutine
gsignal *g // signal-handling g
goSigStack gsignalStack // Go-allocated signal handling stack
p puintptr // attached p for executing go code (nil if not executing go code)
nextp puintptr
oldp puintptr // the p that was attached before executing a syscall
mallocing int32
throwing throwType
preemptoff string // if != "", keep curg running on this m
locks int32
dying int32
spinning bool // m is out of work and is actively looking for work
tls [tlsSlots]uintptr
...
}마찬가지로 M 내부 필드도 많지만, 여기서는 이해를 돕기 위해 일부 필드만 소개합니다.
id, M 의 고유 식별자g0, 스케줄 스택을 가진 코루틴curg, 작업 스레드에서 실행 중인 사용자 코루틴gsignal, 스레드 신호를 처리하는 코루틴goSigStack, Go 가 할당한 신호 처리용 스택 공간p, 프로세서 P 의 주소,oldp는 시스템 호출 실행 전 P 를 가리키며,nextp는 새로 할당된 P 를 가리킵니다.mallocing, 현재 새 메모리 공간을 할당 중인지 여부를 나타냄throwing, M 에서 발생한 오류 유형을 나타냄preemptoff, 선점 식별자, 빈 문자열일 때 현재 실행 중인 코루틴이 선점될 수 있음을 나타냄locks, 현재 M 의 "잠금" 수를 나타내며, 0 이 아닐 때 선점을 금지합니다.dying, M 에서 복구 불가능한panic이 발생했음을 나타내며,[0,3]네 가지 선택 값이 있으며, 낮을수록 심각도가 낮습니다.spinning, M 이 유휴 상태이며随时可用임을 나타냄.tls, 스레드 로컬 저장소
P
P 는 런타임에서 runtime.p로 표현되며, M 과 G 간 작업을 스케줄링하는 것을 담당합니다. 구조는 다음과 같습니다.
type p struct {
id int32
status uint32 // one of pidle/prunning/...
schedtick uint32 // incremented on every scheduler call
syscalltick uint32 // incremented on every system call
sysmontick sysmontick // last tick observed by sysmon
m muintptr // back-link to associated m (nil if idle)
// Queue of runnable goroutines. Accessed without lock.
runqhead uint32
runqtail uint32
runq [256]guintptr
runnext guintptr
// Available G's (status == Gdead)
gFree struct {
gList
n int32
}
// preempt is set to indicate that this P should be enter the
// scheduler ASAP (regardless of what G is running on it).
preempt bool
...
}status는 P 의 상태를 나타내며, 다음과 같은 선택 값이 있습니다.
| 값 | 설명 |
|---|---|
| _Pidle | P 가 유휴 상태에 있으며, 스케줄러가 M 을 할당할 수 있거나 다른 상태 간 전환 중일 수 있음 |
| _Prunning | P 가 M 과 연관되어 있으며 사용자 코드를 실행 중 |
| _Psyscall | P 와 연관된 M 이 시스템 호출을 실행 중이며, 이 기간 동안 P 가 다른 M 에게 선점될 수 있음 |
| _Pgcstop | P 가 GC 로 인해 정지됨 |
| _Pdead | P 의 대부분 자원이 박탈되었으며 더 이상 사용되지 않음 |
다음 몇 가지 필드는 P 의 runq 로컬 큐를 기록합니다. 로컬 큐의 최대 수는 256 임을 볼 수 있습니다. 이 수를 초과하면 G 는 전역 큐에 배치됩니다.
runqhead uint32
runqtail uint32
runq [256]guintptrrunnext는 다음 사용 가능한 G 를 나타냅니다.
runnext guintptr다른 몇 가지 필드 설명은 다음과 같습니다.
id, P 의 고유 식별자schedtick, 코루틴 스케줄 횟수가 증가함에 따라 증가하며,runtime.execute함수에서 볼 수 있습니다.syscalltick, 시스템 호출 횟수가 증가함에 따라 증가합니다.sysmontick, 마지막으로 시스템 모니터링이 관찰한 정보를 기록합니다.m, P 와 연관된 MgFree, 유휴 G 목록preempt, P 가 다시 스케줄에 진입해야 함을 나타냅니다.
전역 큐의 정보는 runtime.schedt 구조체에 저장되며, 스케줄러의 런타임 표현 형식입니다. 다음과 같습니다.
type schedt struct {
...
midle muintptr // idle m's waiting for work
ngsys atomic.Int32 // number of system goroutines
pidle puintptr // idle p's
// Global runnable queue.
runq gQueue
runqsize int32
...
}초기화
스케줄러의 초기화는 Go 프로그램의 부트 단계에 위치하며, Go 프로그램을 부트하는 것은 runtime.rt0_go 함수입니다. 이는 어셈블리로 구현되며 runtime/asm_*.s 파일에 있습니다. 일부 코드는 다음과 같습니다.
TEXT runtime·rt0_go(SB),NOSPLIT|NOFRAME|TOPFRAME,$0
...
...
CALL runtime·check(SB)
MOVL 24(SP), AX // copy argc
MOVL AX, 0(SP)
MOVQ 32(SP), AX // copy argv
MOVQ AX, 8(SP)
CALL runtime·args(SB)
CALL runtime·osinit(SB)
CALL runtime·schedinit(SB)
// create a new goroutine to start program
MOVQ $runtime·mainPC(SB), AX // entry
PUSHQ AX
CALL runtime·newproc(SB)
POPQ AX
// start this M
CALL runtime·mstart(SB)
CALL runtime·abort(SB) // mstart should never return
RET다음 두 줄에서 runtime·osinit과 runtime·schedinit 호출을 볼 수 있습니다.
CALL runtime·osinit(SB)
CALL runtime·schedinit(SB)전자는 운영체제 관련 작업을 초기화하고, 후자는 스케줄러의 초기화를 담당합니다. 즉 runtime·schedinit 함수입니다. 이 함수는 프로그램 시작 시 스케줄러 실행에 필요한 자원을 초기화합니다. 다음은 단순화된 코드입니다.
func schedinit() {
...
gp := getg()
sched.maxmcount = 10000
// The world starts stopped.
worldStopped()
...
stackinit()
mallocinit()
mcommoninit(gp.m, -1)
lock(&sched.lock)
procs := ncpu
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
}
if procresize(procs) != nil {
throw("unknown runnable goroutine during bootstrap")
}
unlock(&sched.lock)
...
// World is effectively started now, as P's can run.
worldStarted()
...
}runtime.getg 함수는 어셈블리로 구현되며, 현재 코루틴의 런타임 표현, 즉 runtime.g 구조체 포인터를 가져오는 기능입니다. sched.maxmcount = 10000을 통해 스케줄러 초기화 시 M 의 최대 수를 10000 으로 설정했음을 볼 수 있습니다. 이 값은 고정되어 있으며 수정할 수 없습니다. 그 후 스택과 힙을 초기화한 다음 runtime.mcommoninit 함수로 M 을 초기화합니다. 함수 구현은 다음과 같습니다.
func mcommoninit(mp *m, id int64) {
gp := getg()
// g0 stack won't make sense for user (and is not necessary unwindable).
if gp != gp.m.g0 {
callers(1, mp.createstack[:])
}
lock(&sched.lock)
if id >= 0 {
mp.id = id
} else {
mp.id = mReserveID()
}
...
mpreinit(mp)
if mp.gsignal != nil {
mp.gsignal.stackguard1 = mp.gsignal.stack.lo + stackGuard
}
// Add to allm so garbage collector doesn't free g->m
// when it is just in a register or thread-local storage.
mp.alllink = allm
// NumCgoCall() iterates over allm w/o schedlock,
// so we need to publish it safely.
atomicstorep(unsafe.Pointer(&allm), unsafe.Pointer(mp))
unlock(&sched.lock)
...
}이 함수는 M 을 사전 초기화하며, 주로 다음 작업을 수행합니다.
- M 의 id 할당
- 스레드 신호 처리를 위해 별도의 G 할당,
runtime.mpreinit함수에서 완료 - 이를 전역 M 링크드 리스트
runtime.allm의 헤드 노드로 추가
다음으로 P 를 초기화하며, 그 수는 기본적으로 CPU 논리 코어 수이며, 그다음은 환경 변수 값입니다.
procs := ncpu
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
}
if procresize(procs) != nil {
throw("unknown runnable goroutine during bootstrap")
}마지막으로 runtime.procresize 함수가 P 초기화를 담당하며, 전달된 수에 따라 모든 P 를 저장하는 전역 슬라이스 runtime.allp를 수정합니다. 먼저 수량 크기에 따라 확장 필요 여부를 판단합니다.
if nprocs > int32(len(allp)) {
// Synchronize with retake, which could be running
// concurrently since it doesn't run on a P.
lock(&allpLock)
if nprocs <= int32(cap(allp)) {
allp = allp[:nprocs]
} else {
nallp := make([]*p, nprocs)
// Copy everything up to allp's cap so we
// never lose old allocated Ps.
copy(nallp, allp[:cap(allp)])
allp = nallp
}
unlock(&allpLock)
}그런 다음 각 P 를 초기화합니다.
// initialize new P's
for i := old; i < nprocs; i++ {
pp := allp[i]
if pp == nil {
pp = new(p)
}
pp.init(i)
atomicstorep(unsafe.Pointer(&allp[i]), unsafe.Pointer(pp))
}현재 코루틴이 사용 중인 P 가 파괴되어야 한다면 allp[0]로 교체하며, runtime.acquirep 함수가 M 과 새 P 의 연관을 완료합니다.
gp := getg()
if gp.m.p != 0 && gp.m.p.ptr().id < nprocs {
gp.m.p.ptr().status = _Prunning
gp.m.p.ptr().mcache.prepareForSweep()
} else {
if gp.m.p != 0 {
gp.m.p.ptr().m = 0
}
gp.m.p = 0
pp := allp[0]
pp.m = 0
pp.status = _Pidle
acquirep(pp)
}이후 더 이상 필요하지 않은 P 를 파괴하며, 파괴 시 P 의 모든 자원을 해제하고 로컬 큐의 모든 G 를 전역 큐에 넣은 후 파괴를 완료한 다음 allp를 슬라이스합니다.
// release resources from unused P's
for i := nprocs; i < old; i++ {
pp := allp[i]
pp.destroy()
// can't free P itself because it can be referenced by an M in syscall
}
// Trim allp.
if int32(len(allp)) != nprocs {
lock(&allpLock)
allp = allp[:nprocs]
unlock(&allpLock)
}마지막으로 유휴 P 를 링크드 리스트로 연결하고 최종적으로 리스트의 헤드 노드를 반환합니다.
var runnablePs *p
for i := nprocs - 1; i >= 0; i-- {
pp := allp[i]
if gp.m.p.ptr() == pp {
continue
}
pp.status = _Pidle
if runqempty(pp) {
pidleput(pp, now)
} else {
pp.m.set(mget())
pp.link.set(runnablePs)
runnablePs = pp
}
}
return runnablePs그 후 스케줄러가 초기화 완료되면 runtime.worldStarted가 모든 P 를 실행 상태로 복구합니다.
MOVQ $runtime·mainPC(SB), AX // entry
PUSHQ AX
CALL runtime·newproc(SB)
POPQ AX
// start this M
CALL runtime·mstart(SB)그런 다음 runtime.newproc 함수를 통해 Go 프로그램을 시작하는 새 코루틴을 생성한 후 runtime.mstart를 호출하여 스케줄러 실행을 정식으로 시작합니다. 이 역시 어셈블리로 구현되며, 내부에서 runtime.mstart0 함수를 호출하여 생성합니다. 이 함수의 일부 코드는 다음과 같습니다.
gp := getg()
osStack := gp.stack.lo == 0
if osStack {
size := gp.stack.hi
if size == 0 {
size = 16384 * sys.StackGuardMultiplier
}
gp.stack.hi = uintptr(noescape(unsafe.Pointer(&size)))
gp.stack.lo = gp.stack.hi - size + 1024
}
gp.stackguard0 = gp.stack.lo + stackGuard
gp.stackguard1 = gp.stackguard0
mstart1()이때 M 은 하나의 코루틴 g0만 가지고 있으며, 이 코루틴은 스레드의 시스템 스택을 사용하며 별도로 할당된 스택 공간이 아닙니다. mstart0 함수는 먼저 G 의 스택 경계를 초기화한 후 mstart1에 넘겨 나머지 초기화 작업을 완료합니다.
gp := getg()
gp.sched.g = guintptr(unsafe.Pointer(gp))
gp.sched.pc = getcallerpc()
gp.sched.sp = getcallersp()
asminit()
minit()
if gp.m == &m0 {
mstartm0()
}
if fn := gp.m.mstartfn; fn != nil {
fn()
}
if gp.m != &m0 {
acquirep(gp.m.nextp.ptr())
gp.m.nextp = 0
}
schedule()시작하기 전에 먼저 현재 실행 현장을 기록합니다. 초기화 성공 후 스케줄 루프에 진입하여 영원히 반환하지 않기 때문입니다. 다른 호출은 실행 현장을 복제하여 mstart1 함수에서 반환하여 스레드 종료 목적을 달성할 수 있습니다. 기록 완료 후 runtime.asminit과 runtime.minit 두 함수가 시스템 스택 초기화를 담당하며, 그 후 runtime.mstartm0 함수가 신호 처리 콜백을 설정합니다. 콜백 함수 m.mstartfn 실행 후 runtime.acquirep 함수가 M 과 이전에 생성된 P 를 연관시키고, 마지막으로 스케줄 루프에 진입합니다.
여기서 호출되는 runtime.schedule은 전체 Go 런타임의 첫 번째 스케줄 루프이며, 스케줄러가 정식으로 작동하기 시작했음을 의미합니다.
스레드
스케줄러에서 G 가 사용자 코드를 실행하려면 P 에 의존해야 하며, P 가 정상적으로 작동하려면 M 과 연관되어야 합니다. M 은 시스템 스레드를 의미합니다.
생성
M 의 생성은 runtime.newm 함수에 의해 완료되며, 이 함수는 함수와 P 그리고 id 를 매개변수로 받습니다. 매개변수인 함수는 클로저일 수 없습니다.
func newm(fn func(), pp *p, id int64) {
acquirem()
mp := allocm(pp, fn, id)
mp.nextp.set(pp)
mp.sigmask = initSigmask
newm1(mp)
releasem(getg().m)
}시작하기 전에 newm은 먼저 runtime.allocm 함수를 호출하여 스레드의 런타임 표현인 M 을 생성합니다. 이 과정에서 runtime.mcommoninit 함수를 사용하여 M 의 스택 경계를 초기화합니다.
func allocm(pp *p, fn func(), id int64) *m {
allocmLock.rlock()
// The caller owns pp, but we may borrow (i.e., acquirep) it. We must
// disable preemption to ensure it is not stolen, which would make the
// caller lose ownership.
acquirem()
gp := getg()
if gp.m.p == 0 {
acquirep(pp) // temporarily borrow p for mallocs in this function
}
mp := new(m)
mp.mstartfn = fn
mcommoninit(mp, id)
mp.g0.m = mp
releasem(gp.m)
allocmLock.runlock()
return mp
}그 후 runtime.newm1이 runtime.newosproc 함수를 호출하여 실제 시스템 스레드 생성을 완료합니다.
func newm1(mp *m) {
execLock.rlock()
newosproc(mp)
execLock.runlock()
}runtime.newosproc의 구현은 운영체제에 따라 다르며, 어떻게 생성하는지는 우리가 관심 있는 사항이 아닙니다. 운영체제가 담당하며, 그 후 runtime.mstart가 M 의 작업을 시작합니다.
종료
runtime.gogo(&mp.g0.sched)초기 부분에서 언급했듯이, mstart1 함수 호출 시 실행 현장을 g0의 sched 필드에 저장했습니다. 이 필드를 runtime.gogo 함수 (어셈블리 구현) 에 전달하면 스레드가 실행 현장으로 점프하여 계속 실행할 수 있습니다. 저장할 때 getcallerpc() 를 사용했으므로, 현장을 복구할 때는 mstart0 함수로 돌아갑니다.
mstart1()
if mStackIsSystemAllocated() {
osStack = true
}
mexit(osStack)실행 현장 복구 후, 실행 순서에 따라 mexit 함수에 진입하여 스레드를 종료합니다.
mp := getg().m
unminit()
lock(&sched.lock)
for pprev := &allm; *pprev != nil; pprev = &(*pprev).alllink {
if *pprev == mp {
*pprev = mp.alllink
}
}
mp.freeWait.Store(freeMWait)
mp.freelink = sched.freem
sched.freem = mp
unlock(&sched.lock)
handoffp(releasep())
mdestroy(mp)
exitThread(&mp.freeWait)이 함수는 주로 다음 몇 가지 주요 작업을 수행합니다.
runtime.unminit을 호출하여runtime.minit의 작업을 취소합니다.- 전역 변수
allm에서 해당 M 을 삭제합니다. - 스케줄러의
freem이 현재 M 을 가리키도록 합니다. runtime.releasep가 P 와 현재 M 의 연관을 해제하고,runtime.handoffp가 P 가 다른 M 과 연관되어 계속 작업하도록 합니다.runtime.destroy가 M 의 자원을 파괴합니다.- 마지막으로 운영체제가 스레드를 종료합니다.
이로써 M 이 성공적으로 종료되었습니다.
일시 정지
스케줄러 스케줄링, GC, 시스템 호출 등의 이유로 M 을 일시 정지해야 할 때 runtime.stopm 함수를 호출하여 스레드를 일시 정지합니다. 다음은 단순화된 코드입니다.
func stopm() {
gp := getg()
lock(&sched.lock)
mput(gp.m)
unlock(&sched.lock)
mPark()
acquirep(gp.m.nextp.ptr())
gp.m.nextp = 0
}먼저 M 을 전역 유휴 M 목록에 넣은 후, mPark() 이 현재 스레드를 notesleep(&gp.m.park) 에서 블럭합니다. 깨어난 후 이 함수가 반환됩니다.
func mPark() {
gp := getg()
notesleep(&gp.m.park)
noteclear(&gp.m.park)
}깨어난 M 은 P 를 찾아 연관시켜 작업을 계속 실행합니다.
코루틴
코루틴의 수명은 코루틴의 몇 가지 상태와 정확히 일치합니다. 코루틴의 수명을 이해하는 것은 스케줄러를 이해하는 데 도움이 됩니다. 전체 스케줄러는 코루틴을 중심으로 설계되었기 때문입니다. 전체 코루틴의 수명은 아래 그림과 같습니다.
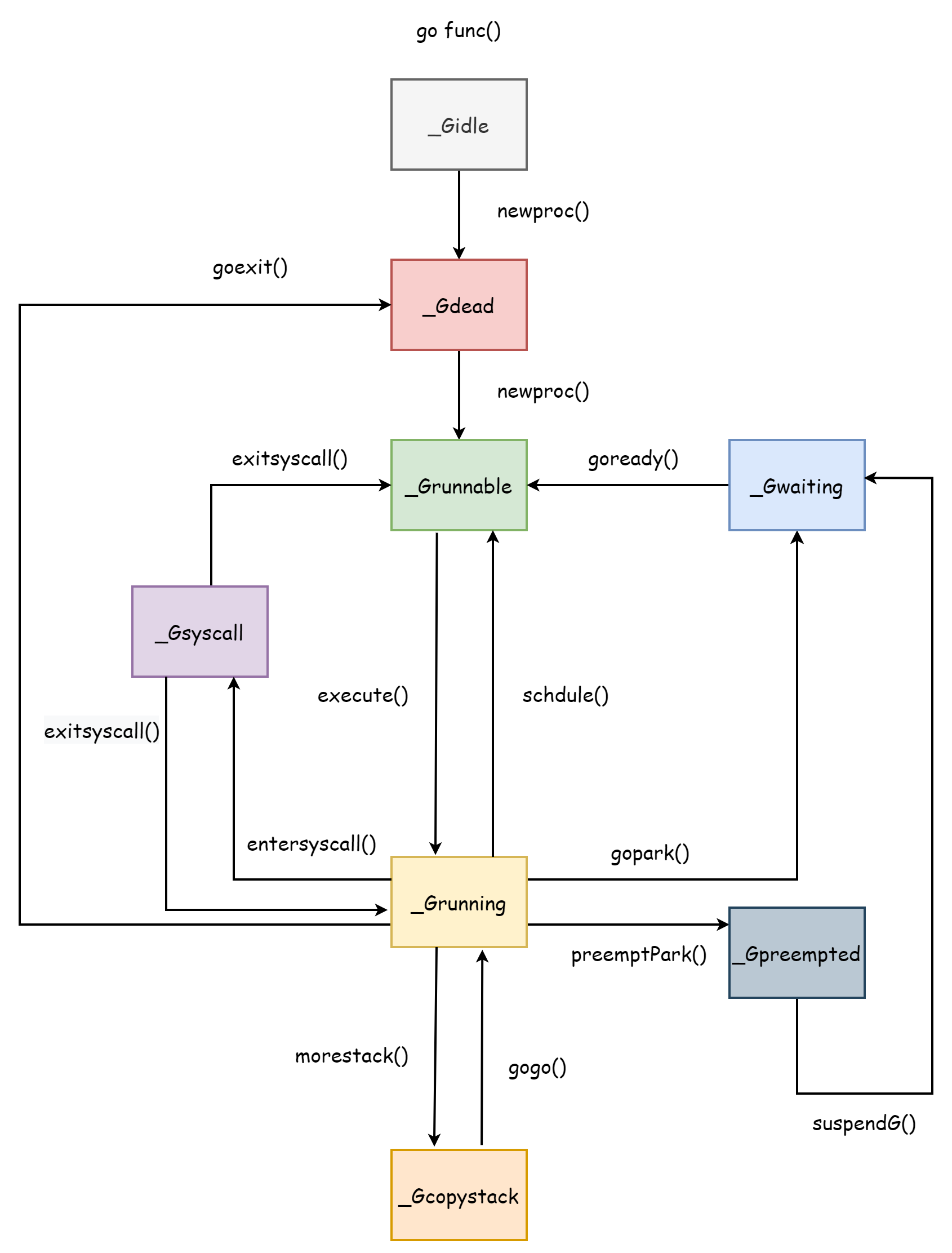
_Gcopystack은 코루틴 스택 확장 시 가지는 상태로, [코루틴 스택](#코루틴 - 스택) 부분에서 설명합니다.
생성
코루틴 생성은 문법적으로 go 키워드와 함수만 있으면 됩니다.
go doSomething()컴파일 후 runtime.newproc 함수 호출로 변환됩니다.
func newproc(fn *funcval) {
gp := getg()
pc := getcallerpc()
systemstack(func() {
newg := newproc1(fn, gp, pc)
pp := getg().m.p.ptr()
runqput(pp, newg, true)
if mainStarted {
wakep()
}
})
}runtime.newproc1이 실제 생성을 완료하며, 생성 시 먼저 M 을 잠그고 선점을 금지한 후 P 의 로컬 gfree 목록에서 유휴 G 를 찾아 재사용합니다. 찾지 못하면 runtime.malg가 새 G 를 생성하고 2kb 의 스택 공간을 할당합니다. 이때 G 의 상태는 _Gdead입니다.
mp := acquirem() // disable preemption because we hold M and P in local vars.
pp := mp.p.ptr()
newg := gfget(pp)
if newg == nil {
newg = malg(stackMin)
casgstatus(newg, _Gidle, _Gdead)
allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack.
}Go 1.18 이후에는 매개변수 복사가 newproc1 함수에 의해 완료되지 않습니다. 그 전에는 runtime.memmove 를 사용하여 함수 매개변수를 복사했습니다. 지금은 코루틴의 스택 공간을 재설정하는 것만 담당하며, runtime.goexit 를 스택 바닥으로 하여 코루틴 종료 처리를 하고, 진입 함수의 PC 를 설정합니다. newg.startpc = fn.fn은 여기서부터 실행됨을 나타냅니다. 설정 완료 후 G 의 상태는 _Grunnable이 됩니다.
totalSize := uintptr(4*goarch.PtrSize + sys.MinFrameSize) // extra space in case of reads slightly beyond frame
totalSize = alignUp(totalSize, sys.StackAlign)
sp := newg.stack.hi - totalSize
spArg := sp
if usesLR {
// caller's LR
*(*uintptr)(unsafe.Pointer(sp)) = 0
prepGoExitFrame(sp)
spArg += sys.MinFrameSize
}
memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched))
newg.sched.sp = sp
newg.stktopsp = sp
newg.sched.pc = abi.FuncPCABI0(goexit) + sys.PCQuantum // +PCQuantum so that previous instruction is in same function
newg.sched.g = guintptr(unsafe.Pointer(newg))
gostartcallfn(&newg.sched, fn)
newg.parentGoid = callergp.goid
newg.gopc = callerpc
newg.ancestors = saveAncestors(callergp)
newg.startpc = fn.fn
casgstatus(newg, _Gdead, _Grunnable)마지막으로 G 의 고유 식별자를 설정한 후 M 을 해제하고 생성된 코루틴 G 를 반환합니다.
newg.goid = pp.goidcache
pp.goidcache++
releasem(mp)
return newg코루틴 생성이 완료된 후 runtime.runqput 함수가 P 의 로컬 큐에 넣으려고 시도하며,放不下이면 전역 큐에 넣습니다. 코루틴 생성 전체 과정에서 상태 변화는 먼저 _Gidle에서 _Gdead로 변하고, 진입 함수 설정 후 _Gdead에서 _Grunnable로 변합니다.
종료
생성 시 Go 는 이미 runtime.goexit 함수를 코루틴의 스택 바닥으로 설정했습니다. 따라서 코루틴 실행이 완료되면 최종적으로 이 함수로 진입하며, 호출 체인 goexit->goexit1->goexit0을 거쳐 최종적으로 runtime.goexit0이 코루틴 종료 작업을 담당합니다.
func goexit0(gp *g) {
mp := getg().m
pp := mp.p.ptr()
...
casgstatus(gp, _Grunning, _Gdead)
...
gp.m = nil
locked := gp.lockedm != 0
gp.lockedm = 0
mp.lockedg = 0
gp.preemptStop = false
gp.paniconfault = false
gp._defer = nil // should be true already but just in case.
gp._panic = nil // non-nil for Goexit during panic. points at stack-allocated data.
gp.writebuf = nil
gp.waitreason = waitReasonZero
gp.param = nil
gp.labels = nil
gp.timer = nil
dropg()
...
gfput(pp, gp)
...
schedule()
}이 함수는 주로 다음 몇 가지 작업을 수행합니다.
- 상태를
_Gdead로 설정합니다. - 필드 값을 재설정합니다.
dropg()이 M 과 G 간의 연관을 차단합니다.gfput(pp, gp)현재 G 를 P 의 로컬 유휴 목록에 넣습니다.schedule()새로운 라운드 스케줄링을 수행하여 M 의 실행권을 다른 G 에게 양도합니다.
종료 후 코루틴의 상태는 _Grunning에서 _Gdead로 변하며, 향후 새 코루틴 생성 시 재사용될 수 있습니다.
시스템 호출
코루틴 G 가 사용자 코드를 실행하는 동안 시스템 호출을 수행하면 시스템 호출을 트리거하는 두 가지 방법이 있습니다.
syscall표준 라이브러리의 시스템 호출- cgo 호출
시스템 호출은 작업 스레드를 블럭하므로, 그 전에 준비 작업이 필요합니다. runtime.entersyscall 함수가 이 과정을 완료하며, 전자는 runtime.reentersyscall 함수에 대한 간단한 호출일 뿐이며, 실제 작업은 후자가 완료합니다. 먼저 현재 M 을 잠그고, 준비 기간 동안 G 는 선점될 수 없으며 스택 확장도 금지됩니다. gp.stackguard0 = stackPreempt를 설정하여 준비 작업 완료 후 P 의 실행권이 다른 G 에게 선점될 것임을 나타냅니다. 그런 다음 코루틴의 실행 현장을 보존하여 시스템 호출 반환 후 복구하기 쉽게 합니다.
gp := getg()
// Disable preemption because during this function g is in Gsyscall status,
// but can have inconsistent g->sched, do not let GC observe it.
gp.m.locks++
// Entersyscall must not call any function that might split/grow the stack.
// (See details in comment above.)
// Catch calls that might, by replacing the stack guard with something that
// will trip any stack check and leaving a flag to tell newstack to die.
gp.stackguard0 = stackPreempt
gp.throwsplit = true
// Leave SP around for GC and traceback.
save(pc, sp)
gp.syscallsp = sp
gp.syscallpc = pc그 후, 장시간 블럭되어 다른 G 의 실행에 영향을 미치는 것을 방지하기 위해 M 과 P 가 분리됩니다. 분리된 후 M 과 G 는 시스템 호출 실행으로 인해 블럭되며, P 는 분리 후 다른 유휴 M 과 연관되어 P 로컬 큐의 다른 G 가 계속 작업할 수 있도록 합니다.
casgstatus(gp, _Grunning, _Gsyscall)
gp.m.syscalltick = gp.m.p.ptr().syscalltick
pp := gp.m.p.ptr()
pp.m = 0
gp.m.oldp.set(pp)
gp.m.p = 0
atomic.Store(&pp.status, _Psyscall)
gp.m.locks--준비 작업 완료 후 M 의 잠금을 해제하며, 이 기간 동안 G 의 상태는 _Grunning에서 _Gsyscall로 변하고, P 의 상태는 _Psyscall로 변합니다.
시스템 호출이 반환된 후 스레드 M 은 더 이상 블럭되지 않으며, 해당 G 도 사용자 코드를 실행하기 위해 다시 스케줄되어야 합니다. runtime.exitsyscall 함수가 이 사후 작업을 완료합니다. 먼저 현재 M 을 잠그고 이전 P 의 참조를 가져옵니다.
gp := getg()
gp.waitsince = 0
oldp := gp.m.oldp.ptr()
gp.m.oldp = 0이때 두 가지 상황으로 나누어 처리합니다. 첫 번째 상황은 사용 가능한 P 가 있는지 여부입니다. runtime.exitsyscallfast 함수는 이전 P 가 사용 가능한지 판단합니다. 즉 P 의 상태가 _Psyscall인지 여부이며, 그렇지 않으면 유휴 P 를 찾습니다.
func exitsyscallfast(oldp *p) bool {
gp := getg()
// Freezetheworld sets stopwait but does not retake P's.
if sched.stopwait == freezeStopWait {
return false
}
// Try to re-acquire the last P.
if oldp != nil && oldp.status == _Psyscall && atomic.Cas(&oldp.status, _Psyscall, _Pidle) {
// There's a cpu for us, so we can run.
wirep(oldp)
exitsyscallfast_reacquired()
return true
}
// Try to get any other idle P.
if sched.pidle != 0 {
var ok bool
systemstack(func() {
ok = exitsyscallfast_pidle()
})
if ok {
return true
}
}
return false
}성공적으로 사용 가능한 P 를 찾으면 M 은 P 와 연관되고, G 는 _Gsyscall 상태에서 _Grunning 상태로 전환된 후 runtime.Gosched 를 통해 G 가主動으로 실행권을 양도하며, P 는 스케줄 루프에 진입하여 다른 사용 가능한 G 를 찾습니다.
oldp := gp.m.oldp.ptr()
gp.m.oldp = 0
if exitsyscallfast(oldp) {
// There's a cpu for us, so we can run.
gp.m.p.ptr().syscalltick++
// We need to cas the status and scan before resuming...
casgstatus(gp, _Gsyscall, _Grunning)
// Garbage collector isn't running (since we are),
// so okay to clear syscallsp.
gp.syscallsp = 0
gp.m.locks--
if gp.preempt {
// restore the preemption request in case we've cleared it in newstack
gp.stackguard0 = stackPreempt
} else {
// otherwise restore the real stackGuard, we've spoiled it in entersyscall/entersyscallblock
gp.stackguard0 = gp.stack.lo + stackGuard
}
gp.throwsplit = false
if sched.disable.user && !schedEnabled(gp) {
// Scheduling of this goroutine is disabled.
Gosched()
}
return
}찾지 못했다면 M 은 G 와 분리되고, G 는 _Gsyscall에서 _Grunnable 상태로 전환된 후 다시 유휴 P 를 찾을 수 있는지 시도합니다. 찾지 못하면 바로 G 를 전역 큐에 넣은 후 새로운 라운드 스케줄 루프에 진입하며, 이전 M 은 runtime.stopm 을 통해 유휴 상태에 진입하여 향후 새 작업을 기다립니다. P 를 찾았다면 이전 M 과 G 가 새 P 와 연관된 후 사용자 코드를 계속 실행하며, 상태는 _Grunnable에서 _Grunning으로 변합니다.
func exitsyscall0(gp *g) {
casgstatus(gp, _Gsyscall, _Grunnable)
dropg()
lock(&sched.lock)
var pp *p
if schedEnabled(gp) {
pp, _ = pidleget(0)
}
var locked bool
if pp == nil {
globrunqput(gp)
}
unlock(&sched.lock)
if pp != nil {
acquirep(pp)
execute(gp, false) // Never returns.
}
stopm()
schedule() // Never returns.
}시스템 호출 종료 후 G 의 상태는 최종적으로 두 가지 결과가 있습니다. 하나는 스케줄을 기다리는 _Grunnable이고, 다른 하나는 계속 실행하는 _Grunning입니다.
일시 정지
현재 코루틴이 몇 가지 이유로 일시 정지될 때 상태는 _Grunnable에서 _Gwaiting으로 변합니다. 일시 정지 이유는 많으며, 채널 블럭, select, 잠금 또는 time.sleep 등일 수 있습니다. 자세한 이유는 G 구조 를 참조하세요. time.Sleep을 예로 들면, 실제로 runtime.timesleep 에 연결되며, 후자의 코드는 다음과 같습니다.
func timeSleep(ns int64) {
if ns <= 0 {
return
}
gp := getg()
t := gp.timer
if t == nil {
t = new(timer)
gp.timer = t
}
t.f = goroutineReady
t.arg = gp
t.nextwhen = nanotime() + ns
if t.nextwhen < 0 { // check for overflow.
t.nextwhen = maxWhen
}
gopark(resetForSleep, unsafe.Pointer(t), waitReasonSleep, traceBlockSleep, 1)
}getg 를 통해 현재 코루틴을 가져온 후 runtime.gopark 를 통해 현재 코루틴을 일시 정지시킵니다. runtime.gopark 는 G 와 M 의 블럭 원인을 업데이트하고 M 의 잠금을 해제합니다.
mp := acquirem()
gp := mp.curg
status := readgstatus(gp)
if status != _Grunning && status != _Gscanrunning {
throw("gopark: bad g status")
}
mp.waitlock = lock
mp.waitunlockf = unlockf
gp.waitreason = reason
mp.waitTraceBlockReason = traceReason
mp.waitTraceSkip = traceskip
releasem(mp)
// can't do anything that might move the G between Ms here.
mcall(park_m)그런 다음 시스템 스택으로 전환하여 runtime.park_m 이 G 의 상태를 _Gwaiting 으로 전환한 후 M 과 G 간의 연관을 차단하고 새로운 스케줄 루프에 진입하여 실행권을 다른 G 에게 양도합니다. 일시 정지 후 G 는 사용자 코드를 실행하지도 않고 로컬 큐에 있지도 않으며, M 과 P 에 대한 참조만 유지합니다.
mp := getg().m
casgstatus(gp, _Grunning, _Gwaiting)
dropg()
schedule()runtime.timesleep 함수에는 다음과 같은 코드가 있어 t.f 값을 지정합니다.
t.f = goroutineReady이 runtime.goroutineReady 함수의 역할은 일시 정지된 코루틴을 깨우는 데 사용되며, runtime.ready 함수를 호출하여 코루틴을 깨웁니다.
status := readgstatus(gp)
// Mark runnable.
mp := acquirem()
casgstatus(gp, _Gwaiting, _Grunnable)
runqput(mp.p.ptr(), gp, next)
wakep()
releasem(mp)깨어난 후 G 의 상태를 _Grunnable 로 전환한 후 G 를 P 의 로컬 큐에 넣어 향후 스케줄을 기다립니다.
코루틴 스택
Go 언어의 코루틴은 전형적인 유스택 코루틴으로, 코루틴을 하나 시작할 때마다 힙에 독립적인 스택 공간을 할당하며, 사용량 변화에 따라 증가하거나 축소됩니다. 스케줄러 초기화 시 runtime.stackinit 함수가 전역 스택 공간 캐시 stackpool 과 stackLarge 를 초기화합니다.
func stackinit() {
if _StackCacheSize&_PageMask != 0 {
throw("cache size must be a multiple of page size")
}
for i := range stackpool {
stackpool[i].item.span.init()
lockInit(&stackpool[i].item.mu, lockRankStackpool)
}
for i := range stackLarge.free {
stackLarge.free[i].init()
lockInit(&stackLarge.lock, lockRankStackLarge)
}
}그 외에도 각 P 는 자체 독립적인 스택 공간 캐시 mcache 를 가지고 있습니다.
type p struct {
...
mcache *mcache
...
}
type mcache struct {
_ sys.NotInHeap
nextSample uintptr
scanAlloc uintptr
tiny uintptr
tinyoffset uintptr
tinyAllocs uintptr
alloc [numSpanClasses]*mspan
stackcache [_NumStackOrders]stackfreelist
flushGen atomic.Uint32
}스레드 캐시 mcache 는 각 스레드마다 독립적이며 힙 메모리에 할당되지 않으므로 액세스 시 잠금이 필요하지 않습니다. 이 세 스택 캐시는 후속 공간 할당 시 사용됩니다.
할당
새 코루틴을 생성할 때 재사용 가능한 코루틴이 없으면 새 스택 공간을 할당합니다. 크기는 기본적으로 2KB 입니다.
newg := gfget(pp)
if newg == nil {
newg = malg(stackMin)
casgstatus(newg, _Gidle, _Gdead)
allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack.
}스택 공간을 할당하는 함수는 runtime.stackalloc 입니다.
func stackalloc(n uint32) stack신청한 스택 메모리 크기가 32KB 보다 작은지 여부에 따라 두 가지 상황으로 나뉩니다. 32KB 는 Go 에서 작은 객체인지 큰 객체인지 판단하는 기준이기도 합니다. 이 값보다 작으면 stackpool 캐시에서 가져옵니다. M 과 P 가 연관되어 있고 M 이 선점될 수 없을 때는 로컬 스레드 캐시에서 가져옵니다.
if n < fixedStack<<_NumStackOrders && n < _StackCacheSize {
order := uint8(0)
n2 := n
for n2 > fixedStack {
order++
n2 >>= 1
}
var x gclinkptr
if stackNoCache != 0 || thisg.m.p == 0 || thisg.m.preemptoff != "" {
lock(&stackpool[order].item.mu)
x = stackpoolalloc(order)
unlock(&stackpool[order].item.mu)
} else {
c := thisg.m.p.ptr().mcache
x = c.stackcache[order].list
if x.ptr() == nil {
stackcacherefill(c, order)
x = c.stackcache[order].list
}
c.stackcache[order].list = x.ptr().next
c.stackcache[order].size -= uintptr(n)
}
v = unsafe.Pointer(x)
}32KB 보다 크면 stackLarge 캐시에서 가져오며, 그래도 부족하면 힙에서 직접 메모리를 할당합니다.
else {
var s *mspan
npage := uintptr(n) >> _PageShift
log2npage := stacklog2(npage)
// Try to get a stack from the large stack cache.
lock(&stackLarge.lock)
if !stackLarge.free[log2npage].isEmpty() {
s = stackLarge.free[log2npage].first
stackLarge.free[log2npage].remove(s)
}
unlock(&stackLarge.lock)
lockWithRankMayAcquire(&mheap_.lock, lockRankMheap)
if s == nil {
// Allocate a new stack from the heap.
s = mheap_.allocManual(npage, spanAllocStack)
if s == nil {
throw("out of memory")
}
osStackAlloc(s)
s.elemsize = uintptr(n)
}
v = unsafe.Pointer(s.base())
}완료 후 스택 공간의 낮은 주소와 높은 주소를 반환합니다.
return stack{uintptr(v), uintptr(v) + uintptr(n)}확장
기본 코루틴 스택 크기는 2KB 로 충분히 가벼워 코루틴 생성 비용이 매우 낮지만, 항상 충분한 것은 아닙니다. 스택 공간이 부족할 때 확장이 필요합니다. 컴파일러는 함수 시작 부분에 runtime.morestack 함수를 삽입하여 현재 코루틴이 스택 확장이 필요한지 확인하며, 필요하면 runtime.newstack 을 호출하여 실제 확장 작업을 완료합니다.
TIP
morestack 은 거의 모든 함수 시작 부분에 삽입되므로, 스택 확장 검사 시기도 코루틴 선점점입니다.
thisg := getg()
gp := thisg.m.curg
// Allocate a bigger segment and move the stack.
oldsize := gp.stack.hi - gp.stack.lo
newsize := oldsize * 2
// The goroutine must be executing in order to call newstack,
// so it must be Grunning (or Gscanrunning).
casgstatus(gp, _Grunning, _Gcopystack)
// The concurrent GC will not scan the stack while we are doing the copy since
// the gp is in a Gcopystack status.
copystack(gp, newsize)
casgstatus(gp, _Gcopystack, _Grunning)
gogo(&gp.sched)계산된 스택 공간 용량은 원래의 두 배이며, runtime.copystack 함수가 스택 복사 작업을 완료합니다. 복사 전 G 의 상태는 _Grunning 에서 _Gcopystack 로 전환됩니다.
func copystack(gp *g, newsize uintptr) {
old := gp.stack
used := old.hi - gp.sched.sp
// allocate new stack
new := stackalloc(uint32(newsize))
// Compute adjustment.
var adjinfo adjustinfo
adjinfo.old = old
adjinfo.delta = new.hi - old.hi
// Copy the stack (or the rest of it) to the new location
memmove(unsafe.Pointer(new.hi-ncopy), unsafe.Pointer(old.hi-ncopy), ncopy)
// Adjust remaining structures that have pointers into stacks.
// We have to do most of these before we traceback the new
// stack because gentraceback uses them.
adjustctxt(gp, &adjinfo)
adjustdefers(gp, &adjinfo)
adjustpanics(gp, &adjinfo)
if adjinfo.sghi != 0 {
adjinfo.sghi += adjinfo.delta
}
// Swap out old stack for new one
gp.stack = new
gp.stackguard0 = new.lo + stackGuard // NOTE: might clobber a preempt request
gp.sched.sp = new.hi - used
gp.stktopsp += adjinfo.delta
// Adjust pointers in the new stack.
var u unwinder
for u.init(gp, 0); u.valid(); u.next() {
adjustframe(&u.frame, &adjinfo)
}
stackfree(old)
}이 함수는 주로 다음 몇 가지 작업을 수행합니다.
- 새 스택 공간을 할당합니다.
- 이전 스택 메모리를
runtime.memmove를 통해 새 스택 공간에 직접 복사합니다. - 스택 포인터를 포함하는 구조를 조정합니다. 예를 들어 defer, panic 등입니다.
- G 의 스택 공간 필드를 업데이트합니다.
runtime.adjustframe을 통해 이전 스택 메모리를 가리키는 포인터를 조정합니다.- 이전 스택의 메모리를 해제합니다.
완료 후 G 의 상태는 _Gcopystack 에서 _Grunning 으로 전환되며, runtime.gogo 함수가 G 가 사용자 코드를 계속 실행하도록 합니다. 바로 코루틴 스택 확장이 존재하기 때문에 Go 의 메모리는 불안정합니다.
축소
G 의 상태가 _Grunnable, _Gsyscall, _Gwaiting 일 때 GC 는 코루틴 스택의 메모리 공간을 스캔합니다.
func scanstack(gp *g, gcw *gcWork) int64 {
switch readgstatus(gp) &^ _Gscan {
case _Grunnable, _Gsyscall, _Gwaiting:
// ok
}
...
if isShrinkStackSafe(gp) {
// Shrink the stack if not much of it is being used.
shrinkstack(gp)
}
...
}실제 스택 축소 작업은 runtime.shrinkstack 에 의해 완료됩니다.
func shrinkstack(gp *g) {
if !isShrinkStackSafe(gp) {
throw("shrinkstack at bad time")
}
oldsize := gp.stack.hi - gp.stack.lo
newsize := oldsize / 2
if newsize < fixedStack {
return
}
avail := gp.stack.hi - gp.stack.lo
if used := gp.stack.hi - gp.sched.sp + stackNosplit; used >= avail/4 {
return
}
copystack(gp, newsize)
}사용된 스택 공간이 기존 1/4 미만일 때 runtime.copystack 을 통해 원래 1/2 로 축소하며, 나머지 작업은 이전과 동일합니다.
분할 스택
copystack 과정에서 볼 수 있듯이, 이전 스택 메모리를 더 큰 스택 공간에 복사합니다. 원래 스택과 새 스택 모두 메모리 주소가 연속적입니다. 그러나 고대 Go 언어에서는 스택 확장 시 현재와 다른 방식을 사용했습니다. 당시에는 메모리 복사가 너무 성능을 소모한다고 생각하여 분할 스택 방식을 채택했습니다. 스택 공간 메모리가 부족하면 새 스택 공간을 신청하고, 기존 스택 공간 메모리는 해제되거나 복사되지 않으며, 서로 포인터로 연결되어 스택 링크드 리스트를 형성했습니다. 이것이 분할 스택의 유래이며, 아래 그림과 같습니다.
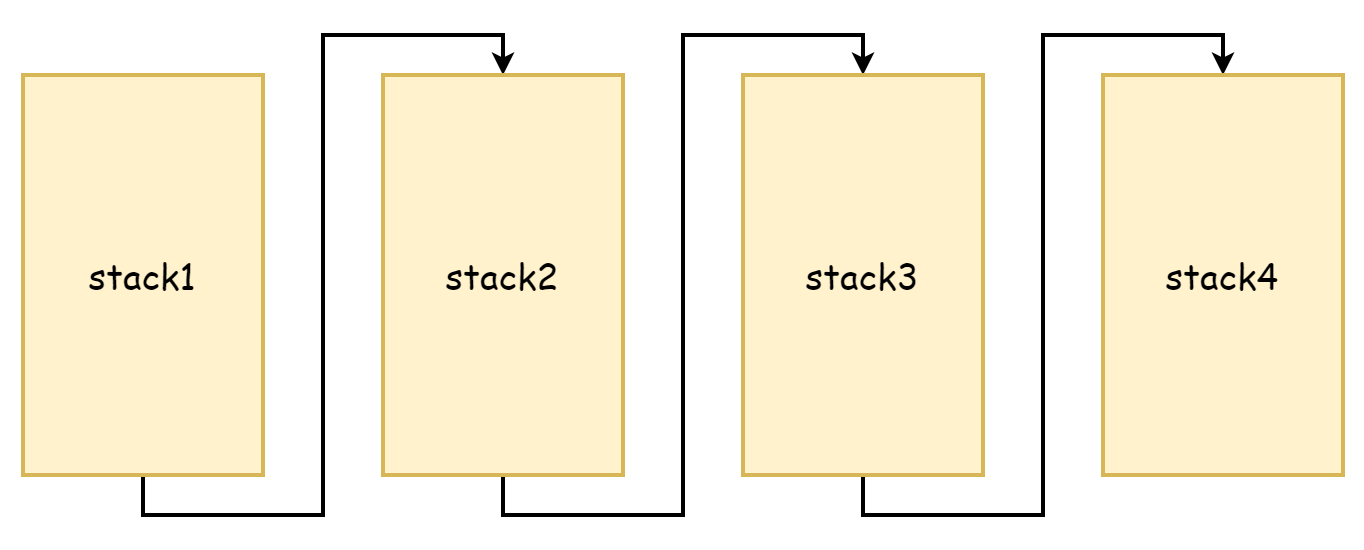
이렇게 하는 장점은 기존 스택을 복사할 필요가 없다는 것이지만, 단점도 매우 명확합니다. 바로 스택 확장과 축소를 매우 빈번하게 트리거한다는 것입니다. 스택 공간의 유휴 메모리가 거의 없을 때 새 함수 호출은 스택 확장을 트리거하며, 이러한 함수가 반환될 때 더 이상 새 스택 공간이 필요하지 않으면 축소를 트리거합니다. 이러한 함수 호출 빈도가 매우 높다면 확장과 축소를 매우 빈번하게 트리거하여 이로 인한 성능 손실이 매우 큽니다.
따라서 Go 1.4 이후 연속 스택으로 변경되었습니다. 연속 스택은 용량이 더 큰 스택 공간을 할당하므로 함수 호출로 인해 사용된 메모리가 임계값에 도달할 때 빈번하게 확장과 축소를 트리거하는 상황이 발생하지 않으며, 메모리 주소가 연속적이므로 캐시의 공간 국소성 원리에 따라 연속 스택이 CPU 캐시에도 더 우호적입니다.
스케줄 루프
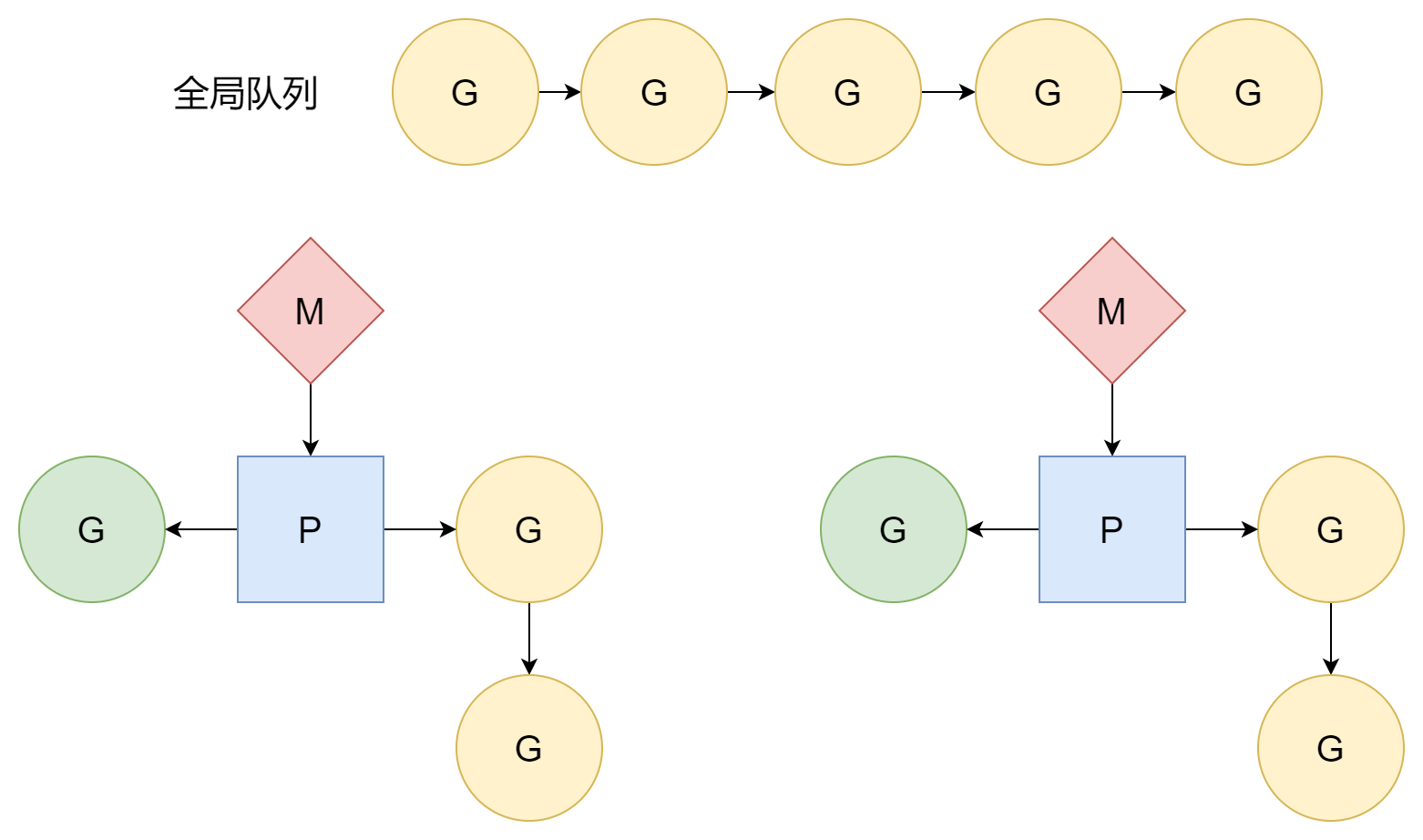
스케줄러 초기화 부분에서 언급했듯이, runtime.mstart1 함수에서 M 과 P 가 성공적으로 연관된 후 첫 번째 runtime.schedule 스케줄 루프에 진입하여 G 를 스케줄링하여 사용자 코드를 실행하기 시작합니다. 스케줄 루프에서 이 부분은 주로 P 가 역할을 합니다. M 은 시스템 스레드에 해당하고, G 는 진입 함수, 즉 사용자 코드에 해당하지만, P 는 M 과 G 와 같이 실체가 있는 것이 아니라 추상적인 개념으로, 중개자로서 M 과 G 간의 관계를 처리합니다.
func schedule() {
mp := getg().m
top:
pp := mp.p.ptr()
pp.preempt = false
if mp.spinning {
resetspinning()
}
gp, inheritTime, tryWakeP := findRunnable() // blocks until work is available
execute(gp, inheritTime)
}위의 코드는 단순화되었으며, 많은 조건 판단이 삭제되었습니다. 가장 핵심적인 점은 runtime.findRunnable 과 runtime.execute 두 가지뿐입니다. 전자는 G 를 찾는 것을 담당하며 반드시 사용 가능한 G 를 반환하고, 후자는 G 가 사용자 코드를 계속 실행하도록 합니다.
findRunnable 함수의 경우, 첫 번째 G 출처는 P 의 로컬 큐입니다.
// local runq
if gp, inheritTime := runqget(pp); gp != nil {
return gp, inheritTime, false
}로컬 큐에 G 가 없으면 전역 큐에서 가져오려고 시도합니다.
// global runq
if sched.runqsize != 0 {
lock(&sched.lock)
gp := globrunqget(pp, 0)
unlock(&sched.lock)
if gp != nil {
return gp, false, false
}
}로컬과 전역 큐 모두에서 찾지 못하면 네트워크 폴러에서 가져오려고 시도합니다.
if netpollinited() && netpollWaiters.Load() > 0 && sched.lastpoll.Load() != 0 {
if list := netpoll(0); !list.empty() { // non-blocking
gp := list.pop()
injectglist(&list)
casgstatus(gp, _Gwaiting, _Grunnable)
if traceEnabled() {
traceGoUnpark(gp, 0)
}
return gp, false, false
}
}그래도 찾지 못하면 결국 다른 P 에서 로컬 큐의 G 를 "훔쳐" 옵니다. 코루틴 생성 시 언급했듯이, P 로컬 큐의 G 의 주요 출처는 현재 코루틴이 파생한 하위 코루틴이지만, 모든 코루틴이 하위 코루틴을 생성하는 것은 아닙니다. 이렇게 되면 일부 P 는 매우 바쁘고, 다른 일부 P 는 유휴 상태인 상황이 발생할 수 있습니다. 이렇게 되면 어떤 G 는 계속 기다려져 실행되지 못하고, 다른 한편의 P 는 매우 한가하여 아무 일도 없는 상황이 발생합니다. 모든 P 를 착취하여 최대 작업 효율을 발휘하게 하기 위해, P 가 G 를 찾지 못할 때 다른 P 의 로컬 큐에서 실행 가능한 G 를 "훔쳐" 옵니다. 이렇게 하면 각 P 가 비교적 균일한 G 큐를 가질 수 있어 P 와 P 간에 방관하는 상황이 거의 발생하지 않습니다.
gp, inheritTime, tnow, w, newWork := stealWork(now)
if gp != nil {
// Successfully stole.
return gp, inheritTime, false
}runtime.stealWork 는 무작위로 P 를 선택하여 훔치며, 실제 훔치는 작업은 runtime.runqgrab 함수가 완료합니다. 이 함수는 해당 P 로컬 큐의 절반 G 를 훔치려고 시도합니다.
for {
h := atomic.LoadAcq(&pp.runqhead) // load-acquire, synchronize with other consumers
t := atomic.LoadAcq(&pp.runqtail) // load-acquire, synchronize with the producer
n := t - h
n = n - n/2
if n > uint32(len(pp.runq)/2) { // read inconsistent h and t
continue
}
for i := uint32(0); i < n; i++ {
g := pp.runq[(h+i)%uint32(len(pp.runq))]
batch[(batchHead+i)%uint32(len(batch))] = g
}
if atomic.CasRel(&pp.runqhead, h, h+n) { // cas-release, commits consume
return n
}
}전체 훔치는 작업은 네 번 수행되며, 네 번 후에도 G 를 훔치지 못하면 반환합니다. 최종적으로 찾을 수 없으면 현재 M 이 runtime.stopm 에 의해 일시 정지되며, 깨어난 후 위의 단계를 반복합니다. G 를 찾아 반환한 후 runtime.execute 에 넘겨 G 를 실행합니다.
mp := getg().m
mp.curg = gp
gp.m = mp
casgstatus(gp, _Grunnable, _Grunning)
gp.waitsince = 0
gp.preempt = false
gp.stackguard0 = gp.stack.lo + stackGuard
gogo(&gp.sched)먼저 M 의 curg 를 업데이트한 후 G 의 상태를 _Grunning 으로 업데이트하고, 마지막으로 runtime.gogo 에 넘겨 G 의 실행을 복구합니다.
전반적으로 스케줄 루프에서 G 의 출처는 우선순위에 따라 네 가지가 있습니다.
- P 의 로컬 큐
- 전역 큐
- 네트워크 폴러
- 다른 P 의 로컬 큐에서 훔침
runtime.execute 는 실행 후 반환하지 않으며, 방금 가져온 G 도 영원히 실행되지 않습니다. 어떤 시기에 스케줄링이 트리거되면 실행권이 박탈되며, 새로운 라운드 스케줄 루프에 진입하여 실행권을 다른 G 에게 양도합니다.
스케줄 전략
다른 G 가 사용자 코드를 실행하는 시간은 다를 수 있습니다. 일부 G 는 시간이 매우 길고, 일부 G 는 시간이 매우 짧습니다. 실행 시간이 긴 G 는 다른 G 가 실행되지 못하게 할 수 있으므로, G 를 교대로 실행하는 것이 올바른 방식입니다. 운영체제에서 이러한 작업 방식을 동시성이라고 합니다.
협력식 스케줄
협력식 스케줄의 기본 아이디어는 G 가自行으로 실행권을 다른 G 에게 양도하는 것입니다. 주로 두 가지 방법이 있습니다.
첫 번째 방법은 사용자 코드에서主動으로 양도하는 것입니다. Go 는 runtime.Gosched() 함수를 제공하여 사용자가 언제 실행권을 양도할지 스스로 결정할 수 있게 하지만, 많은 경우 스케줄러 내부의 작업 세부 사항은 사용자에게 블랙박스이므로 언제主動으로 양도해야 할지 판단하기 어렵습니다. 사용자에 대한 요구가 비교적 높으며, Go 의 스케줄러는 사용자에게 대부분의 세부 사항을 숨기고 더 간단한 사용 방법을 추구합니다. 이러한 상황에서 사용자도 스케줄 작업에 참여시키는 것은 좋은 일이 아닙니다.
두 번째 방법은 선점 표시입니다. 이름에 선점이라는 단어가 있지만, 본질적으로 여전히 협력식 스케줄 전략입니다. 아이디어는 함수头部에 선점 검사 코드 runtime.morestack() 를 삽입하는 것입니다. 삽입 과정은 컴파일 기간에 완료되며, 앞에서 언급했듯이 원래는 스택 확장 검사를 위한 함수였으며, 검사점은 모든 함수 호출이므로 이 또한 선점 검사를 위한 좋은 시기입니다. runtime.newstack 함수의 상반부는 선점 검사를 수행하며, 하반부는 스택 확장 검사를 수행합니다. 앞에서는 방해를 피하기 위해 이 부분을 생략했는데, 지금 이 부분이 무엇을 하는지 살펴보겠습니다. 먼저 gp.stackguard0 에 따라 선점 여부를 판단하며, 필요하지 않으면 사용자 코드를 계속 실행합니다.
stackguard0 := atomic.Loaduintptr(&gp.stackguard0)
preempt := stackguard0 == stackPreempt
if preempt {
if !canPreemptM(thisg.m) {
gp.stackguard0 = gp.stack.lo + stackGuard
gogo(&gp.sched) // never return
}
}g.stackguard0 == stackPreempt 일 때 runtime.canPreemptM() 함수가 코루틴 조건이 선점되어야 하는지 판단합니다. 코드는 다음과 같습니다.
func canPreemptM(mp *m) bool {
return mp.locks == 0 && mp.mallocing == 0 && mp.preemptoff == "" && mp.p.ptr().status == _Prunning
}선점될 수 있으려면 네 가지 조건을 만족해야 합니다.
- M 이 잠기지 않았습니다.
- 메모리를 할당 중이지 않습니다.
- 선점이 금지되지 않았습니다.
- P 가
_Prunning상태입니다.
다음 두 가지 상황에서 g.stackguard0 를 stackPreempt 로 설정합니다.
- 가비지 컬렉션이 필요할 때
- 시스템 호출이 발생할 때
if preempt {
if gp.preemptShrink {
gp.preemptShrink = false
shrinkstack(gp)
}
// Act like goroutine called runtime.Gosched.
gopreempt_m(gp) // never return
}마지막으로 runtime.gopreempt_m() 에 진입하여 현재 코루틴의 실행권을主動으로 양도합니다. 먼저 M 과 G 간의 연관을 차단하고 상태를 _Grunnable 로 만든 후 G 를 전역 큐에 넣고, 마지막으로 스케줄 루프에 진입하여 실행권을 다른 G 에게 양도합니다.
casgstatus(gp, _Grunning, _Grunnable)
dropg()
lock(&sched.lock)
globrunqput(gp)
unlock(&sched.lock)
schedule()이렇게 하면 모든 코루틴이 함수 호출을 수행할 때 해당 함수에 진입하여 선점 검사를 할 수 있습니다. 이러한 전략은 함수 호출이라는 시기에 의존하여 선점을 트리거하고主動으로 양도합니다. 1.14 이전에는 Go 가 계속 이러한 스케줄 전략을 사용했지만, 이렇게 하면 문제가 발생합니다. 함수 호출이 없으면 검사를 할 수 없습니다. 예를 들어 아래 고전적인 코드는 많은 튜토리얼에서出现过입니다.
func main() {
// 限制 P 的数量只能为 1
runtime.GOMAXPROCS(1)
// 协程 1
go func() {
for {
// 该协程不停的空转
}
}()
// 进入系统调用,主协程让权给其它协程
time.Sleep(time.Millisecond)
println("exit")
}코드에서 회전하는 코루틴 1 을 생성한 후 주 코루틴이 시스템 호출로 인해主動으로 양도하며, 이때 코루틴 1 이 스케줄링되고 있습니다. 하지만 함수를 전혀 호출하지 않으므로 선점 검사를 할 수 없습니다. P 가 하나뿐이므로 다른 유휴 P 가 없어 주 코루틴이 영원히 스케줄되지 않으며, exit 도 영원히 출력되지 않습니다. 하지만 이러한 문제는 Go 1.14 이전으로 한정됩니다.
선점식 스케줄
공식적으로 Go 1.14 에 신호 기반의 선점식 스케줄 전략을 추가했습니다. 이는 비동기 선점 전략으로, 비동기 스레드가 신호를发送하는 방식으로 스레드를 선점합니다. 신호 기반의 선점식 스케줄은 현재 두 가지 진입점이 있으며, 각각 시스템 모니터링과 GC 입니다.
시스템 모니터링 루프에서는 각 P 를 순회하며, P 가 스케줄링하는 G 의 실행 시간이 10ms 를 초과하면 강제적으로 선점을 트리거합니다. 이 부분 작업은 runtime.retake 함수가 완료하며, 다음은 단순화된 코드입니다.
func retake(now int64) uint32 {
n := 0
lock(&allpLock)
for i := 0; i < len(allp); i++ {
pp := allp[i]
if pp == nil {
continue
}
pd := &pp.sysmontick
s := pp.status
sysretake := false
if s == _Prunning || s == _Psyscall {
// Preempt G if it's running for too long.
t := int64(pp.schedtick)
if int64(pd.schedtick) != t {
pd.schedtick = uint32(t)
pd.schedwhen = now
} else if pd.schedwhen+forcePreemptNS <= now {
preemptone(pp)
sysretake = true
}
}
}
unlock(&allpLock)
return uint32(n)
}가비지 컬렉션이 필요할 때 G 의 상태가 _Grunning 이면, 즉 여전히 실행 중이면 마찬가지로 선점을 트리거합니다.
func suspendG(gp *g) suspendGState {
for i := 0; ; i++ {
switch s := readgstatus(gp); s {
case _Grunning:
gp.preemptStop = true
gp.preempt = true
gp.stackguard0 = stackPreempt
casfrom_Gscanstatus(gp, _Gscanrunning, _Grunning)
if preemptMSupported && debug.asyncpreemptoff == 0 && needAsync {
now := nanotime()
if now >= nextPreemptM {
nextPreemptM = now + yieldDelay/2
preemptM(asyncM)
}
}
......
......
func preemptM(mp *m) {
if mp.signalPending.CompareAndSwap(0, 1) {
if GOOS == "darwin" || GOOS == "ios" {
pendingPreemptSignals.Add(1)
}
signalM(mp, sigPreempt)
}
}두 선점 진입점은 최종적으로 runtime.preemptM 함수에 진입하며, 이 함수가 선점 신호发送을 완료합니다. 신호가 성공적으로发送된 후 runtime.mstart 시 runtime.initsig 를 통해 등록된 신호 처리기 콜백 함수 runtime.sighandler 가 사용되며, 선점 신호가发送된 것을 감지하면 선점을 시작합니다.
func sighandler(sig uint32, info *siginfo, ctxt unsafe.Pointer, gp *g) {
...
if sig == sigPreempt && debug.asyncpreemptoff == 0 && !delayedSignal {
// Might be a preemption signal.
doSigPreempt(gp, c)
}
...
}doSigPreempt 는 대상 코루틴의 컨텍스트를 수정하여 runtime.asyncPreempt 호출을 주입합니다.
func doSigPreempt(gp *g, ctxt *sigctxt) {
// Check if this G wants to be preempted and is safe to
// preempt.
if wantAsyncPreempt(gp) {
if ok, newpc := isAsyncSafePoint(gp, ctxt.sigpc(), ctxt.sigsp(), ctxt.siglr()); ok {
// Adjust the PC and inject a call to asyncPreempt.
ctxt.pushCall(abi.FuncPCABI0(asyncPreempt), newpc)
}
}
...이렇게 하면 사용자 코드로 다시 전환될 때 대상 코루틴이 runtime.asyncPreempt 함수로 진입하며, 이 함수에서 runtime.asyncPreempt2 호출이涉及됩니다.
TEXT ·asyncPreempt(SB),NOSPLIT|NOFRAME,$0-0
PUSHQ BP
MOVQ SP, BP
// Save flags before clobbering them
PUSHFQ
// obj doesn't understand ADD/SUB on SP, but does understand ADJSP
ADJSP $368
// But vet doesn't know ADJSP, so suppress vet stack checking
...
CALL ·asyncPreempt2(SB)
...
RET이 함수는 현재 코루틴이 작업을 중지하고 새로운 라운드 스케줄 루프를 수행하여 실행권을 다른 코루틴에 양도하도록 합니다.
func asyncPreempt2() {
gp := getg()
gp.asyncSafePoint = true
if gp.preemptStop {
mcall(preemptPark)
} else {
mcall(gopreempt_m)
}
gp.asyncSafePoint = false
}이 전체 과정은 runtime.asyncPreempt 함수에서 발생하며, 어셈블리로 구현됩니다 (runtime/preempt_*.s 에 위치). 스케줄 완료 후 이전에 수정된 코루틴 컨텍스트를 복구하여 해당 코루틴이 향후 정상적으로 복구될 수 있도록 합니다. 비동기 선점 전략을 채택한 후, 이전 예제는 더 이상 주 코루틴을 영구적으로 블럭하지 않습니다. 회전 코루틴이 일정 시간 실행된 후 강제적으로 스케줄 루프를 수행하여 실행권을 주 코루틴에 양도하며, 최종적으로 프로그램이 정상적으로 종료될 수 있습니다.
요약
전반적으로 스케줄을 트리거하는 시기는 다음과 같습니다.
- 함수 호출
- 시스템 호출
- 시스템 모니터링
- 가비지 컬렉션, 가비지 컬렉션은 실행 시간이 너무 긴 코루틴에 대해서도 선점을 수행합니다.
- 코루틴이 파이프, 잠금 등의 이유로 일시 정지됨
스케줄 전략은 주로 두 가지로, 협력식과 선점식입니다. 협력식은主動으로 실행권을 양도하고, 선점식은 비동기로 실행권을 선점합니다. 이 둘이 공존하여 오늘날의 스케줄러를 형성했습니다.