gmp
Uma das maiores características da linguagem Go é seu suporte nativo para concorrência. Basta apenas uma palavra-chave para iniciar uma goroutine, como demonstrado no exemplo abaixo:
import (
"fmt"
"sync"
)
func main() {
var wg sync.WaitGroup
wg.Add(2)
go func() {
defer wg.Done()
fmt.Println("hello world!")
}()
go func() {
defer wg.Done()
fmt.Println("hello world too!")
}()
wg.Wait()
}O uso de goroutines na linguagem Go é tão simples que, para o desenvolvedor, quase não é necessário fazer nenhum trabalho extra. Esta é uma das razões de sua popularidade. Porém, por trás dessa simplicidade, existe um escalonador de concorrência nada simples que sustenta tudo isso. Seu nome, vocês provavelmente já ouviram mais ou menos, pois seus participantes principais são respectivamente G (goroutine), M (thread do sistema), P (processador). Por ser composto por esses três membros, também é chamado de escalonador GMP. O design do escalonador GMP influencia todo o design do runtime da linguagem Go. GC, network poller, pode-se dizer que é a parte mais central de toda a linguagem. Se puder ter algum entendimento sobre ele, talvez possa ajudar em algum momento no trabalho futuro.
História
O modelo de escalonamento de concorrência da linguagem Go não é completamente original. Ele absorveu muitas experiências e lições de predecessores, passando por constante desenvolvimento e melhoria até chegar ao formato atual. As linguagens que influenciaram incluem:
- Occam -1983
- Erlang - 1986
- Newsqueak - 1988
- Concurrent ML - 1993
- Alef - 1995
- Limbo - 1996
A influência mais significativa veio do artigo sobre CSP (Communicate Sequential Process) publicado por Hoare em 1978. A ideia básica do artigo é que processos trocam dados através de comunicação entre eles. Todas as linguagens acima foram influenciadas pela ideia do CSP. Erlang é o exemplo mais típico de linguagem orientada a mensagens. O famoso middleware de mensagens open source RabbitMQ foi escrito em Erlang. Nos dias atuais, com o desenvolvimento da computação e internet, suporte a concorrência quase se tornou padrão em linguagens modernas. A linguagem Go, combinando a ideia do CSP, surgiu assim.
Modelo de Escalonamento
Primeiro, vamos简单介绍 os três componentes do GMP:
- G, Goroutine, refere-se à goroutine na linguagem Go
- M, Machine, refere-se à thread do sistema ou thread de trabalho (worker thread), responsável pelo escalonamento do sistema operacional
- P, Processor, não se refere ao processador CPU, é um conceito abstrato do próprio Go, refere-se ao processador que trabalha em threads do sistema, através dele escalona-se cada goroutine em cada thread do sistema.
Goroutine é um tipo de thread mais leve, com escala menor e recursos necessários também menores. Criação, destruição e momentos de escalonamento são completados pelo runtime da linguagem Go, não pelo sistema operacional. Portanto, seu custo de gerenciamento é muito menor que threads. Porém, goroutines também dependem de threads. O tempo de execução necessário para goroutines vem de threads, e o tempo de threads vem do sistema operacional. A troca entre diferentes threads tem certo custo. Como fazer bom uso do tempo de execução das threads pelas goroutines é a chave do design.
1:N
A melhor maneira de resolver um problema é ignorá-lo. Já que a troca de threads tem custo, basta não fazer troca. Distribua todas as goroutines para um único kernel thread. Assim envolve apenas troca entre goroutines.
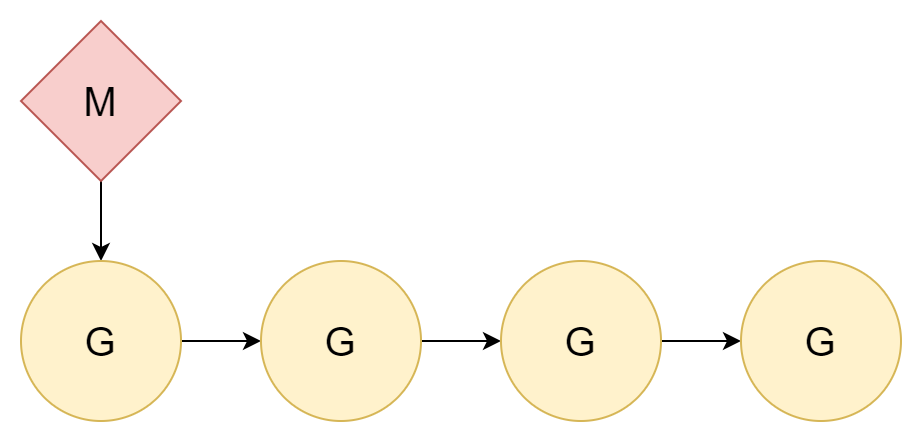
A relação entre threads e goroutines é 1:N. Isso tem uma desvantagem muito óbvia: computadores da era atual são quase todos CPUs multi-core. Tal distribuição não pode aproveitar totalmente o desempenho de CPUs multi-core.
N:N
Outro método: uma thread corresponde a uma goroutine, uma goroutine pode desfrutar de todo o tempo de execução da thread, múltiplas threads também podem aproveitar o desempenho de CPUs multi-core. Porém, o custo de criação e troca de threads é relativamente alto. Se for relação um-para-um, não se aproveita bem a vantagem de leveza das goroutines.
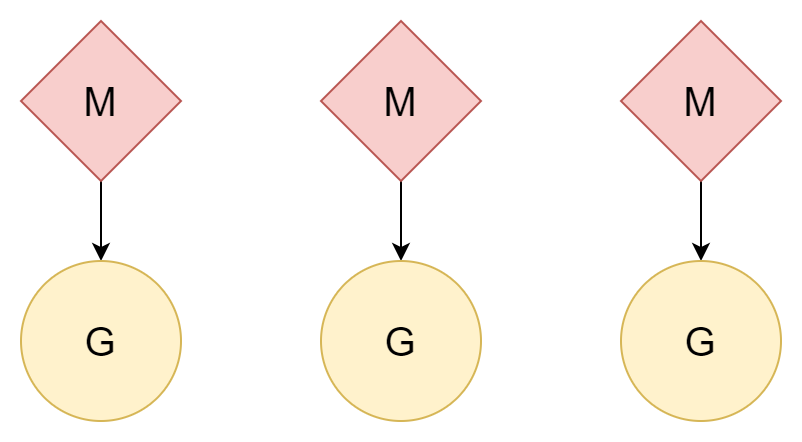
M:N
M threads correspondem a N goroutines, onde M é menor que N. Múltiplas threads correspondem a múltiplas goroutines, cada thread corresponde a várias goroutines, e o processador P é responsável por escalonar como a goroutine G usa o tempo de execução da thread. Este método é relativamente melhor, e é o modelo de escalonamento que Go usa até hoje.
M só pode executar tarefas após se associar com o processador P. Go criará GOMAXPROCS processadores, então o número real de threads que podem executar tarefas é GOMAXPROCS. Seu valor padrão é o número de núcleos lógicos de CPU da máquina atual, mas também podemos definir manualmente seu valor.
- Modificar através de código
runtime.GOMAXPROCS(N), pode ser ajustado dinamicamente em tempo de execução, STW direto após chamada. - Definir variável de ambiente
export GOMAXPROCS=N, estático.
Na prática, o número de M é maior que o número de P, porque em runtime é necessário usá-los para processar outras tarefas, como algumas chamadas de sistema. O valor máximo é 10000.
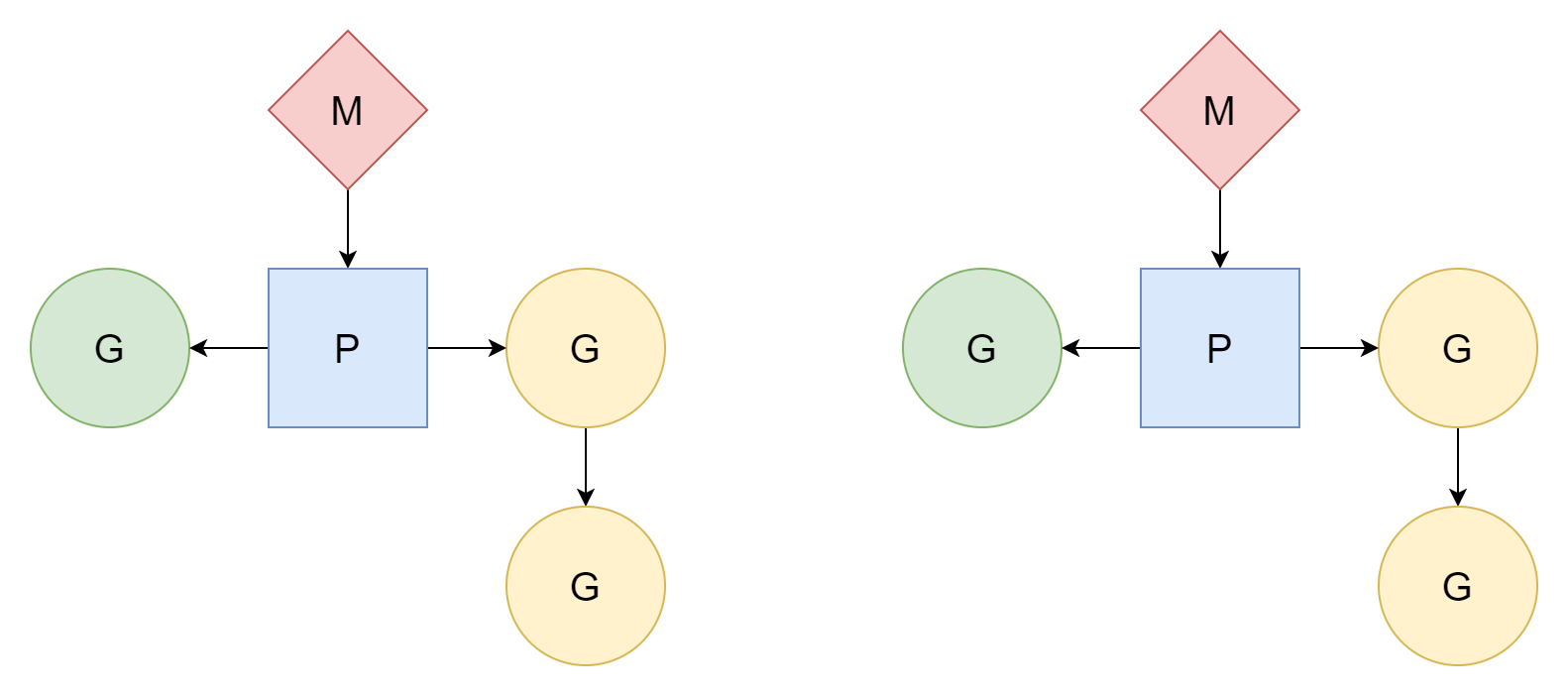
Os três participantes GMP e o próprio escalonador têm suas representações de tipo em tempo de execução, todos localizados no arquivo runtime/runtime2.go. Abaixo será feita uma简单介绍 de suas estruturas para facilitar o entendimento posterior.
G
G se manifesta em tempo de execução como a estrutura runtime.g, que é a unidade básica de escalonamento no modelo de escalonamento. Sua estrutura é conforme abaixo. Para facilitar o entendimento, muitos campos foram removidos:
type g struct {
stack stack // offset conhecido pelo runtime/cgo
_panic *_panic // panic mais interno - offset conhecido pela liblink
_defer *_defer // defer mais interno
m *m // m atual executando g; offset conhecido pela arm liblink
sched gobuf
goid uint64
waitsince int64 // tempo aproximado quando g ficou bloqueado
waitreason waitReason // se status==Gwaiting
atomicstatus atomic.Uint32
preempt bool // sinal de preempção, duplica stackguard0 = stackpreempt
startpc uintptr // pc da função da goroutine
parentGoid uint64 // goid da goroutine que criou esta goroutine
waiting *sudog // estruturas sudog que esta g está aguardando (que têm ponteiro elem válido); em ordem de lock
}O primeiro campo é o endereço inicial e final da memória da stack pertencente a esta goroutine:
type stack struct {
lo uintptr
hi uintptr
}_panic e _defer são ponteiros apontando para a stack de panic e stack de defer:
_panic *_panic // panic mais interno - offset conhecido pela liblink
_defer *_defer // defer mais internom é a goroutine executando a g atual:
m *m // m atual executando g; offset conhecido pela arm liblinkpreempt indica se a goroutine atual precisa ser preemptada, equivalente a g.stackguard0 = stackpreempt:
preempt bool // sinal de preempção, duplica stackguard0 = stackpreemptatomicstatus é usado para armazenar o valor de status da goroutine G, com os seguintes valores opcionais:
| Nome | Descrição |
|---|---|
| _Gidle | Recém alocado, não inicializado |
| _Grunnable | Indica que a goroutine atual pode executar, localizada na fila de espera |
| _Grunning | Indica que a goroutine atual está executando código de usuário |
| _Gsyscall | Alocado um M para executar chamada de sistema |
| _Gwaiting | Goroutine bloqueada, motivo do bloqueio veja abaixo |
| _Gdead | Indica que a goroutine atual não está em uso, pode ter acabado de sair ou acabado de inicializar |
| _Gcopystack | Indica que a stack da goroutine está movendo, durante este período não executa código de usuário, também não está na fila de espera |
| _Gpreempted | Bloqueia-se em preempção, aguarda ser acordado pela parte preemptora |
| _Gscan | GC está escaneando espaço de stack da goroutine, pode coexistir com outros estados |
sched é usado para armazenar informações de contexto da goroutine para recuperar o local de execução da goroutine. Pode-se ver que armazena ponteiros sp, pc, ret:
type gobuf struct {
sp uintptr
pc uintptr
g guintptr
ctxt unsafe.Pointer
ret uintptr
lr uintptr
bp uintptr // para arquiteturas habilitadas para framepointer
}waiting indica a goroutine que a goroutine atual está aguardando, waitsince registra o momento em que a goroutine ficou bloqueada, waitreason indica o motivo do bloqueio da goroutine, com valores opcionais conforme abaixo:
var waitReasonStrings = [...]string{
waitReasonZero: "",
waitReasonGCAssistMarking: "GC assist marking",
waitReasonIOWait: "IO wait",
waitReasonChanReceiveNilChan: "chan receive (nil chan)",
waitReasonChanSendNilChan: "chan send (nil chan)",
waitReasonDumpingHeap: "dumping heap",
waitReasonGarbageCollection: "garbage collection",
waitReasonGarbageCollectionScan: "garbage collection scan",
waitReasonPanicWait: "panicwait",
waitReasonSelect: "select",
waitReasonSelectNoCases: "select (no cases)",
waitReasonGCAssistWait: "GC assist wait",
waitReasonGCSweepWait: "GC sweep wait",
waitReasonGCScavengeWait: "GC scavenge wait",
waitReasonChanReceive: "chan receive",
waitReasonChanSend: "chan send",
waitReasonFinalizerWait: "finalizer wait",
waitReasonForceGCIdle: "force gc (idle)",
waitReasonSemacquire: "semacquire",
waitReasonSleep: "sleep",
waitReasonSyncCondWait: "sync.Cond.Wait",
waitReasonSyncMutexLock: "sync.Mutex.Lock",
waitReasonSyncRWMutexRLock: "sync.RWMutex.RLock",
waitReasonSyncRWMutexLock: "sync.RWMutex.Lock",
waitReasonTraceReaderBlocked: "trace reader (blocked)",
waitReasonWaitForGCCycle: "wait for GC cycle",
waitReasonGCWorkerIdle: "GC worker (idle)",
waitReasonGCWorkerActive: "GC worker (active)",
waitReasonPreempted: "preempted",
waitReasonDebugCall: "debug call",
waitReasonGCMarkTermination: "GC mark termination",
waitReasonStoppingTheWorld: "stopping the world",
}goid e parentGoid representam o identificador único da goroutine atual e da goroutine pai, startpc representa o endereço da função de entrada da goroutine atual.
M
M se manifesta em tempo de execução como a estrutura runtime.m, que é uma abstração da thread de trabalho:
type m struct {
id int64
g0 *g // goroutine com stack de escalonamento
curg *g // goroutine de usuário executando atualmente
gsignal *g // g para tratamento de sinais
goSigStack gsignalStack // stack de tratamento de sinais alocada pelo Go
p puintptr // p associado para executar código go (nil se não estiver executando código go)
nextp puintptr
oldp puintptr // p que estava associado antes de executar chamada de sistema
mallocing int32
throwing throwType
preemptoff string // se != "", mantém curg executando neste m
locks int32
dying int32
spinning bool // m está sem trabalho e ativamente procurando trabalho
tls [tlsSlots]uintptr
...
}Da mesma forma, M também tem muitos campos internos. Aqui apresentamos apenas alguns campos para facilitar o entendimento:
id, identificador único de Mg0, goroutine com stack de escalonamentocurg, goroutine de usuário executando na thread de trabalhogsignal, goroutine responsável por processar sinais da threadgoSigStack, espaço de stack alocado pelo Go para tratamento de sinaisp, endereço do processador P,oldpaponta para P antes de executar chamada de sistema,nextpaponta para novo P alocadomallocing, usado para indicar se está atualmente alocando novo espaço de memóriathrowing, indica o tipo de erro ocorrido em Mpreemptoff, identificador de preempção, quando string vazia indica que a goroutine executando atualmente pode ser preemptadalocks, indica o número atual de "locks" de M, quando diferente de 0 proíbe preempçãodying, indica que M ocorreupanicirrecuperável, tem quatro valores opcionais[0,3], do menor para maior indica severidadespinning, indica que M está em estado ocioso e disponível a qualquer momentotls, armazenamento local da thread
P
P é representado por runtime.p em tempo de execução, responsável por escalonar trabalho entre M e G. Sua estrutura é conforme abaixo:
type p struct {
id int32
status uint32 // um de pidle/prunning/...
schedtick uint32 // incrementado em cada chamada do escalonador
syscalltick uint32 // incrementado em cada chamada de sistema
sysmontick sysmontick // último tick observado pelo sysmon
m muintptr // link de retorno para m associado (nil se ocioso)
// Fila de goroutines executáveis. Acessado sem lock.
runqhead uint32
runqtail uint32
runq [256]guintptr
runnext guintptr
// G's disponíveis (status == Gdead)
gFree struct {
gList
n int32
}
// preempt é definido para indicar que este P deve entrar no
// escalonador o mais rápido possível (independentemente de qual G está executando nele).
preempt bool
...
}status indica o estado de P, com os seguintes valores opcionais:
| Valor | Descrição |
|---|---|
| _Pidle | P está em estado ocioso, pode ser atribuído M pelo escalonador, ou pode estar apenas transitando entre outros estados |
| _Prunning | P associado com M e executando código de usuário |
| _Psyscall | Indica que M associado com P está executando chamada de sistema, durante este período P pode ser preemptado por outros M |
| _Pgcstop | Indica que P parou devido a GC |
| _Pdead | Maioria dos recursos de P foram removidos, não será mais usado |
Os campos abaixo registram a fila local runq em P. Pode-se ver que o número máximo da fila local é 256. Após exceder este número, G será colocado na fila global:
runqhead uint32
runqtail uint32
runq [256]guintptrrunnext indica o próximo G disponível:
runnext guintptrOs outros campos são explicados abaixo:
id, identificador único de Pschedtick, incrementa com o aumento do número de escalonamentos de goroutines, visível na funçãoruntime.executesyscalltick, incrementa com o aumento do número de chamadas de sistemasysmontick, registra informações observadas pela última vez pelo monitor de sistemam, M associado com PgFree, lista de G ociosospreempt, indica que P deve entrar novamente no escalonamento
As informações da fila global são armazenadas na estrutura runtime.schedt, que é a representação do escalonador em tempo de execução:
type schedt struct {
...
midle muintptr // m's ociosos aguardando trabalho
ngsys atomic.Int32 // número de goroutines de sistema
pidle puintptr // p's ociosos
// Fila global de goroutines executáveis.
runq gQueue
runqsize int32
...
}Inicialização
A inicialização do escalonador está localizada na fase de bootstrap do programa Go. A função responsável por guiar o programa Go é runtime.rt0_go, implementada em assembly localizada no arquivo runtime/asm_*.s. Parte do código é conforme abaixo:
TEXT runtime·rt0_go(SB),NOSPLIT|NOFRAME|TOPFRAME,$0
...
...
CALL runtime·check(SB)
MOVL 24(SP), AX // copia argc
MOVL AX, 0(SP)
MOVQ 32(SP), AX // copia argv
MOVQ AX, 8(SP)
CALL runtime·args(SB)
CALL runtime·osinit(SB)
CALL runtime·schedinit(SB)
// cria uma nova goroutine para iniciar programa
MOVQ $runtime·mainPC(SB), AX // entrada
PUSHQ AX
CALL runtime·newproc(SB)
POPQ AX
// inicia este M
CALL runtime·mstart(SB)
CALL runtime·abort(SB) // mstart nunca deve retornar
RETPode-se ver a chamada para runtime·osinit e runtime·schedinit nas duas linhas abaixo:
CALL runtime·osinit(SB)
CALL runtime·schedinit(SB)A primeira é responsável por inicializar trabalhos relacionados ao sistema operacional, a segunda é responsável pela inicialização do escalonador, ou seja, a função runtime·schedinit. Ela é responsável por inicializar recursos necessários para execução do escalonador durante inicialização do programa. Abaixo está o código simplificado:
func schedinit() {
...
gp := getg()
sched.maxmcount = 10000
// O mundo começa parado
worldStopped()
...
stackinit()
mallocinit()
mcommoninit(gp.m, -1)
lock(&sched.lock)
procs := ncpu
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
}
if procresize(procs) != nil {
throw("unknown runnable goroutine during bootstrap")
}
unlock(&sched.lock)
...
// Mundo é efetivamente iniciado agora, pois P's podem executar
worldStarted()
...
}A função runtime.getg é implementada em assembly, sua função é obter a representação em tempo de execução da goroutine atual, ou seja, ponteiro da estrutura runtime.g. Através de sched.maxmcount = 10000 pode-se ver que, durante inicialização do escalonador, já foi definido o número máximo de M como 10000. Este valor é fixo e não pode ser modificado. Depois é inicializada a stack, e então a função runtime.mcommoninit é usada para inicializar M. Sua implementação é conforme abaixo:
func mcommoninit(mp *m, id int64) {
gp := getg()
// stack g0 não fará sentido para usuário (e não é necessário unwindable)
if gp != gp.m.g0 {
callers(1, mp.createstack[:])
}
lock(&sched.lock)
if id >= 0 {
mp.id = id
} else {
mp.id = mReserveID()
}
...
mpreinit(mp)
if mp.gsignal != nil {
mp.gsignal.stackguard1 = mp.gsignal.stack.lo + stackGuard
}
// Adiciona a allm para que garbage collector não libere g->m
// quando está apenas em registro ou armazenamento local da thread
mp.alllink = allm
// NumCgoCall() itera sobre allm sem schedlock,
// então precisamos publicar com segurança
atomicstorep(unsafe.Pointer(&allm), unsafe.Pointer(mp))
unlock(&sched.lock)
...
}Esta função faz pré-inicialização de M, principalmente realizando os seguintes trabalhos:
- Aloca id de M
- Aloca separadamente um G para processar sinais da thread, completado pela função
runtime.mpreinit - O coloca como nó cabeça da lista encadeada global de M
runtime.allm
Em seguida inicializa P, cujo número padrão é o número de núcleos lógicos da CPU, seguido pelo valor da variável de ambiente:
procs := ncpu
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
}
if procresize(procs) != nil {
throw("unknown runnable goroutine during bootstrap")
}Finalmente, a função runtime.procresize é responsável por inicializar P. Ela modifica o slice global runtime.allp que armazena todos os P de acordo com o número passado. Primeiro julga se precisa expandir capacidade de acordo com o tamanho do número:
if nprocs > int32(len(allp)) {
// Sincroniza com retake, que pode estar executando
// concorrentemente pois não executa em P
lock(&allpLock)
if nprocs <= int32(cap(allp)) {
allp = allp[:nprocs]
} else {
nallp := make([]*p, nprocs)
// Copia tudo até capacidade de allp para que
// nunca percamos Ps alocados antigos
copy(nallp, allp[:cap(allp)])
allp = nallp
}
unlock(&allpLock)
}Depois inicializa cada P:
// inicializa novos P's
for i := old; i < nprocs; i++ {
pp := allp[i]
if pp == nil {
pp = new(p)
}
pp.init(i)
atomicstorep(unsafe.Pointer(&allp[i]), unsafe.Pointer(pp))
}Se o P atualmente usado pela goroutine precisar ser destruído, substitui por allp[0]. A função runtime.acquirep completa a associação entre M e novo P:
gp := getg()
if gp.m.p != 0 && gp.m.p.ptr().id < nprocs {
gp.m.p.ptr().status = _Prunning
gp.m.p.ptr().mcache.prepareForSweep()
} else {
if gp.m.p != 0 {
gp.m.p.ptr().m = 0
}
gp.m.p = 0
pp := allp[0]
pp.m = 0
pp.status = _Pidle
acquirep(pp)
}Em seguida destrói P's não mais necessários. Durante destruição, libera todos os recursos de P, coloca todas as G's da fila local na fila global. Após destruição, faz slice em allp:
// libera recursos de P's não utilizados
for i := nprocs; i < old; i++ {
pp := allp[i]
pp.destroy()
// não pode liberar P em si porque pode ser referenciado por M em chamada de sistema
}
// Trim allp
if int32(len(allp)) != nprocs {
lock(&allpLock)
allp = allp[:nprocs]
unlock(&allpLock)
}Finalmente, conecta os P's ociosos em uma lista encadeada e retorna o nó cabeça da lista:
var runnablePs *p
for i := nprocs - 1; i >= 0; i-- {
pp := allp[i]
if gp.m.p.ptr() == pp {
continue
}
pp.status = _Pidle
if runqempty(pp) {
pidleput(pp, now)
} else {
pp.m.set(mget())
pp.link.set(runnablePs)
runnablePs = pp
}
}
return runnablePsDepois, inicialização do escalonador concluída, runtime.worldStarted restaura todos os P para execução:
MOVQ $runtime·mainPC(SB), AX // entrada
PUSHQ AX
CALL runtime·newproc(SB)
POPQ AX
// inicia este M
CALL runtime·mstart(SB)Em seguida, cria uma nova goroutine através da função runtime.newproc para iniciar o programa Go, depois chama runtime.mstart para iniciar oficialmente a execução do escalonador. Também é implementado em assembly, internamente chama a função runtime.mstart0 para criação. Parte do código desta função é conforme abaixo:
gp := getg()
osStack := gp.stack.lo == 0
if osStack {
size := gp.stack.hi
if size == 0 {
size = 16384 * sys.StackGuardMultiplier
}
gp.stack.hi = uintptr(noescape(unsafe.Pointer(&size)))
gp.stack.lo = gp.stack.hi - size + 1024
}
gp.stackguard0 = gp.stack.lo + stackGuard
gp.stackguard1 = gp.stackguard0
mstart1()Neste momento, M possui apenas uma goroutine g0, que usa a stack do sistema da thread, não espaço de stack alocado separadamente. A função mstart0 primeiro inicializa limites de stack de G, depois entrega para mstart1 completar o restante do trabalho de inicialização:
gp := getg()
gp.sched.g = guintptr(unsafe.Pointer(gp))
gp.sched.pc = getcallerpc()
gp.sched.sp = getcallersp()
asminit()
minit()
if gp.m == &m0 {
mstartm0()
}
if fn := gp.m.mstartfn; fn != nil {
fn()
}
if gp.m != &m0 {
acquirep(gp.m.nextp.ptr())
gp.m.nextp = 0
}
schedule()Antes de iniciar, primeiro registra o local de execução atual, porque após inicialização bem-sucedida entrará no loop de escalonamento e nunca retornará. Outras chamadas podem reutilizar o local de execução para retornar de mstart1 com objetivo de sair da thread. Após registro concluído, as funções runtime.asminit e runtime.minit são responsáveis por inicializar a stack do sistema, depois a função runtime.mstartm0 define o callback para processar sinais. Após executar função de callback m.mstartfn, a função runtime.acquirep associa M com P criado anteriormente, finalmente entra no loop de escalonamento.
A chamada runtime.schedule aqui é o primeiro loop de escalonamento de todo o runtime Go, representando o início oficial do trabalho do escalonador.
Thread
No escalonador, G quer executar código de usuário dependendo de P, e P para funcionar normalmente precisa se associar com um M. M refere-se à thread do sistema.
Criação
A criação de M é completada pela função runtime.newm, que aceita uma função e P e id como parâmetros. A função como parâmetro não pode ser closure:
func newm(fn func(), pp *p, id int64) {
acquirem()
mp := allocm(pp, fn, id)
mp.nextp.set(pp)
mp.sigmask = initSigmask
newm1(mp)
releasem(getg().m)
}Antes de iniciar, newm primeiro chama a função runtime.allocm para criar a representação em tempo de execução da thread, ou seja, M. Durante o processo, usa a função runtime.mcommoninit para inicializar limites de stack de M:
func allocm(pp *p, fn func(), id int64) *m {
allocmLock.rlock()
// O chamador possui pp, mas podemos emprestar (ou seja, acquirep) ela. Devemos
// desabilitar preempção para garantir que não seja roubada, o que faria o
// chamador perder propriedade
acquirem()
gp := getg()
if gp.m.p == 0 {
acquirep(pp) // empresta temporariamente p para mallocs nesta função
}
mp := new(m)
mp.mstartfn = fn
mcommoninit(mp, id)
mp.g0.m = mp
releasem(gp.m)
allocmLock.runlock()
return mp
}Depois, runtime.newm1 chama a função runtime.newosproc para completar a criação real da thread do sistema:
func newm1(mp *m) {
execLock.rlock()
newosproc(mp)
execLock.runlock()
}A implementação de runtime.newosproc difere de acordo com o sistema operacional. Como exatamente criar não é nossa preocupação, é responsabilidade do sistema operacional. Depois, runtime.mstart inicia o trabalho de M.
Saída
runtime.gogo(&mp.g0.sched)Na inicialização mencionamos que, ao chamar a função mstart1, o local de execução foi salvo no campo sched de g0. Passando este campo para a função runtime.gogo (implementada em assembly) permite que a thread pule para o local de execução e continue executando. Ao salvar usou-se getcallerpc(), então ao restaurar o local de execução retorna-se à função mstart0:
mstart1()
if mStackIsSystemAllocated() {
osStack = true
}
mexit(osStack)Após restaurar o local de execução, de acordo com a ordem de execução, entra-se na função mexit para sair da thread:
mp := getg().m
unminit()
lock(&sched.lock)
for pprev := &allm; *pprev != nil; pprev = &(*pprev).alllink {
if *pprev == mp {
*pprev = mp.alllink
}
}
mp.freeWait.Store(freeMWait)
mp.freelink = sched.freem
sched.freem = mp
unlock(&sched.lock)
handoffp(releasep())
mdestroy(mp)
exitThread(&mp.freeWait)Ela realiza principalmente os seguintes trabalhos:
- Chama
runtime.uminitpara reverter trabalho deruntime.minit - Remove este M da variável global
allm - Define
freemdo escalonador apontando para M atual runtime.releasepdesassocia P do M atual, eruntime.handoffpfaz P se associar com outros M para continuar trabalhandoruntime.destroyé responsável por destruir recursos de M- Finalmente, sistema operacional sai da thread
Até aqui M saiu com sucesso.
Pausa
Quando é necessário pausar M devido a razões como escalonamento do escalonador, GC, chamadas de sistema etc., chama-se a função runtime.stopm para pausar a thread. Abaixo está o código simplificado:
func stopm() {
gp := getg()
lock(&sched.lock)
mput(gp.m)
unlock(&sched.lock)
mPark()
acquirep(gp.m.nextp.ptr())
gp.m.nextp = 0
}Primeiro coloca M na lista global de M ociosos, depois mPark() bloqueia a thread atual em notesleep(&gp.m.park). Quando acordado, esta função retorna:
func mPark() {
gp := getg()
notesleep(&gp.m.park)
noteclear(&gp.m.park)
}M após ser acordado procura um P para se associar e continuar executando tarefas.
Goroutine
O ciclo de vida da goroutine corresponde exatamente aos vários estados da goroutine. Entender o ciclo de vida da goroutine ajuda a entender o escalonador, afinal todo o escalonador é projetado em torno da goroutine. Todo o ciclo de vida da goroutine é conforme mostrado na figura abaixo:
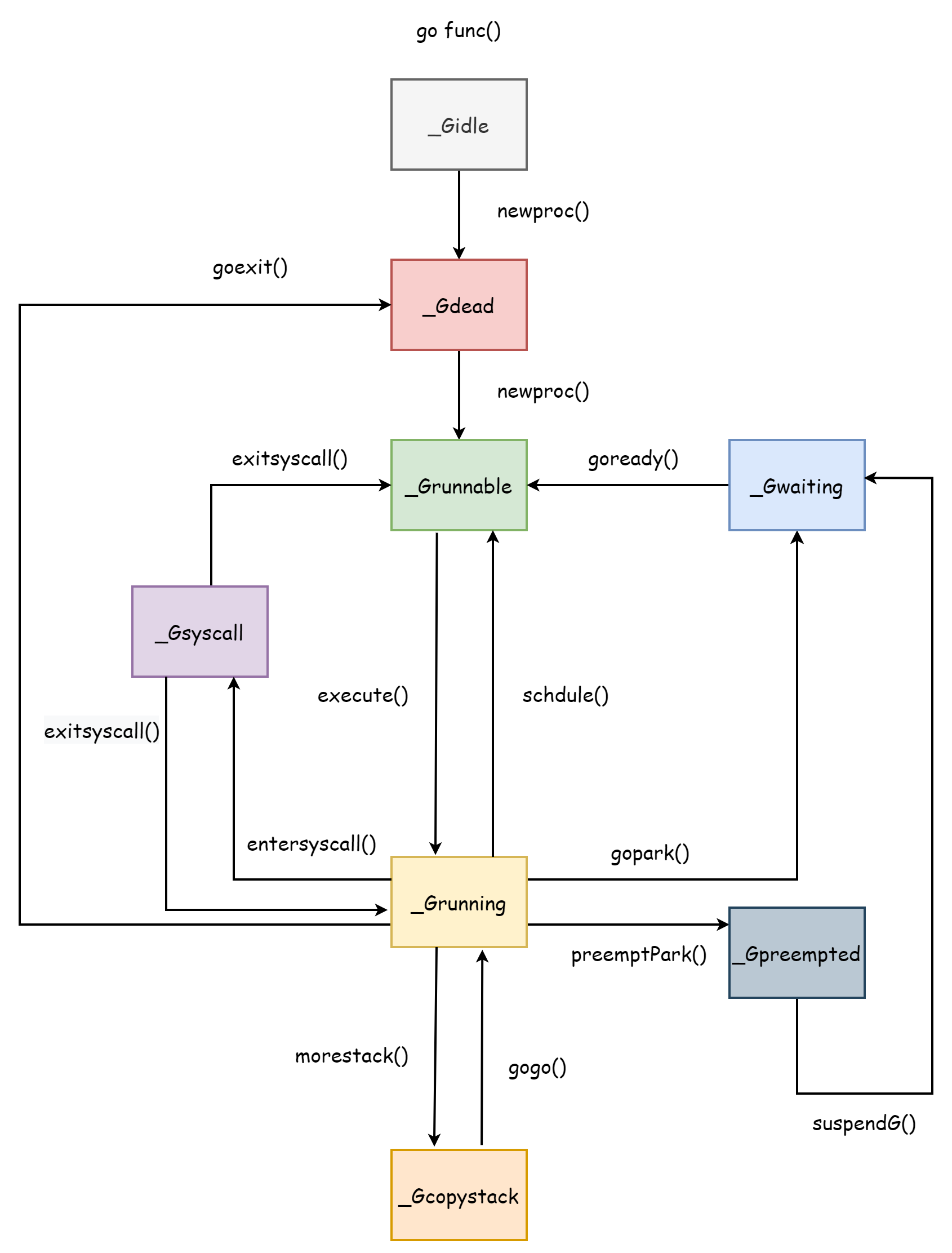
_Gcopystack é o estado que a goroutine possui durante expansão de stack, explicado na parte Stack de Goroutine.
Criação
A criação de goroutine, do ponto de vista sintático, requer apenas uma palavra-chave go e uma função:
go doSomething()Após compilação, se converte em chamada da função runtime.newproc:
func newproc(fn *funcval) {
gp := getg()
pc := getcallerpc()
systemstack(func() {
newg := newproc1(fn, gp, pc)
pp := getg().m.p.ptr()
runqput(pp, newg, true)
if mainStarted {
wakep()
}
})
}runtime.newproc1 completa a criação real. Durante criação, primeiro bloqueia M, proíbe preempção, depois procura G ocioso na lista gfree local de P para reutilizar. Se não encontrar, runtime.malg cria um novo G e aloca espaço de stack de 2kb. Neste momento, o estado de G é _Gdead:
mp := acquirem() // desabilita preempção porque mantemos M e P em variáveis locais
pp := mp.p.ptr()
newg := gfget(pp)
if newg == nil {
newg = malg(stackMin)
casgstatus(newg, _Gidle, _Gdead)
allgadd(newg) // publica com status g->status de Gdead para que scanner GC não olhe stack não inicializada
}Em Go 1.18 e posterior, a cópia de parâmetros não é mais completada pela função newproc1. Antes disso, usava-se runtime.memmove para copiar parâmetros da função. Agora é apenas responsável por resetar espaço de stack da goroutine, definindo runtime.goexit como base da stack para que ele realize o tratamento de saída da goroutine. Depois define PC da função de entrada newg.startpc = fn.fn indicando que começa a executar daqui. Após configuração concluída, o estado de G é _Grunnable:
totalSize := uintptr(4*goarch.PtrSize + sys.MinFrameSize) // espaço extra em caso de leituras ligeiramente além do frame
totalSize = alignUp(totalSize, sys.StackAlign)
sp := newg.stack.hi - totalSize
spArg := sp
if usesLR {
// LR do chamador
*(*uintptr)(unsafe.Pointer(sp)) = 0
prepGoExitFrame(sp)
spArg += sys.MinFrameSize
}
memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched))
newg.sched.sp = sp
newg.stktopsp = sp
newg.sched.pc = abi.FuncPCABI0(goexit) + sys.PCQuantum // +PCQuantum para que instrução anterior esteja na mesma função
newg.sched.g = guintptr(unsafe.Pointer(newg))
gostartcallfn(&newg.sched, fn)
newg.parentGoid = callergp.goid
newg.gopc = callerpc
newg.ancestors = saveAncestors(callergp)
newg.startpc = fn.fn
casgstatus(newg, _Gdead, _Grunnable)Finalmente define identificador único de G, depois libera M e retorna a goroutine G criada:
newg.goid = pp.goidcache
pp.goidcache++
releasem(mp)
return newgApós criação da goroutine, tenta colocá-la na fila local de P através da função runtime.runqput. Se não couber, coloca na fila global. Durante todo o processo de criação da goroutine, sua mudança de estado primeiro é de _Gidle para _Gdead, após configurar função de entrada, de _Gdead para _Grunnable.
Saída
Durante criação, Go já definiu a função runtime.goexit como base da stack da goroutine. Então, quando a goroutine executa completamente, eventualmente entra nesta função. Através da cadeia de chamadas goexit->goexit1->goexit0, finalmente runtime.goexit0 é responsável pelo trabalho de saída da goroutine:
func goexit0(gp *g) {
mp := getg().m
pp := mp.p.ptr()
...
casgstatus(gp, _Grunning, _Gdead)
...
gp.m = nil
locked := gp.lockedm != 0
gp.lockedm = 0
mp.lockedg = 0
gp.preemptStop = false
gp.paniconfault = false
gp._defer = nil // já deveria ser true mas apenas por precaução
gp._panic = nil // não-nil para Goexit durante panic. aponta para dados alocados na stack
gp.writebuf = nil
gp.waitreason = waitReasonZero
gp.param = nil
gp.labels = nil
gp.timer = nil
dropg()
...
gfput(pp, gp)
...
schedule()
}Esta função realiza principalmente os seguintes trabalhos:
- Define estado como
_Gdead - Reseta valores de campos
dropg()corta associação entre M e Ggfput(pp, gp)coloca G atual na lista local ociosa de Pschedule()realiza nova rodada de escalonamento, passa direito de execução de M para outros G
Após saída, estado da goroutine muda de _Grunning para _Gdead. Pode ser reutilizado no futuro ao criar novas goroutines.
Chamada de Sistema
Quando a goroutine G está executando código de usuário e realiza uma chamada de sistema, há dois métodos para acionar chamada de sistema:
- Chamada de sistema da biblioteca padrão
syscall - Chamada cgo
Como chamada de sistema bloqueia a thread de trabalho, é necessário realizar preparativos antes. A função runtime.entersyscall completa este processo, mas a primeira é apenas uma chamada simples para runtime.reentersyscall. O trabalho real é completado pela segunda. Primeiro bloqueia M atual. Durante preparativos, G é proibido de ser preemptado, também proibido expansão de stack. Define gp.stackguard0 = stackPreempt indicando que, após conclusão dos preparativos, direito de execução de P será preemptado por outros G. Depois preserva local de execução da goroutine,方便恢复 após retorno da chamada de sistema:
gp := getg()
// Desabilita preempção porque durante esta função g está em status Gsyscall,
// mas pode ter g->sched inconsistente, não deixe GC observar
gp.m.locks++
// Entersyscall não deve chamar qualquer função que possa split/grow stack
// (Veja detalhes no comentário acima)
// Captura chamadas que podem, substituindo stack guard com algo que
// acionará qualquer verificação de stack e deixando flag para dizer newstack para morrer
gp.stackguard0 = stackPreempt
gp.throwsplit = true
// Deixa SP por perto para GC e traceback
save(pc, sp)
gp.syscallsp = sp
gp.syscallpc = pcDepois, para evitar bloqueio prolongado que afete execução de outros G, M e P se desassociam. M e G desassociados bloqueiam devido à execução de chamada de sistema, enquanto P após desassociação pode se associar com outros M ociosos para que outras G's na fila local de P possam continuar trabalhando:
casgstatus(gp, _Grunning, _Gsyscall)
gp.m.syscalltick = gp.m.p.ptr().syscalltick
pp := gp.m.p.ptr()
pp.m = 0
gp.m.oldp.set(pp)
gp.m.p = 0
atomic.Store(&pp.status, _Psyscall)
gp.m.locks--Após conclusão dos preparativos, libera lock de M. Durante este período, estado de G muda de _Grunning para _Gsyscall, estado de P muda para _Psyscall.
Quando chamada de sistema retorna, thread M não bloqueia mais, e G correspondente também precisa ser escalonado novamente para executar código de usuário. A função runtime.exitsyscall completa este trabalho de finalização. Primeiro bloqueia M atual, obtém referência do P antigo:
gp := getg()
gp.waitsince = 0
oldp := gp.m.oldp.ptr()
gp.m.oldp = 0Neste momento, divide-se em duas situações para processar. Primeira situação: se há P disponível diretamente. A função runtime.exitsyscallfast julga se o P original está disponível, ou seja, se o estado de P é _Psyscall. Caso contrário, procura P ocioso:
func exitsyscallfast(oldp *p) bool {
gp := getg()
// Freezetheworld define stopwait mas não retoma P's
if sched.stopwait == freezeStopWait {
return false
}
// Tenta readquirir último P
if oldp != nil && oldp.status == _Psyscall && atomic.Cas(&oldp.status, _Psyscall, _Pidle) {
// Há cpu para nós, então podemos executar
wirep(oldp)
exitsyscallfast_reacquired()
return true
}
// Tenta obter qualquer outro P ocioso
if sched.pidle != 0 {
var ok bool
systemstack(func() {
ok = exitsyscallfast_pidle()
})
if ok {
return true
}
}
return false
}Se encontrar P disponível com sucesso, M se associa com P, G muda de estado _Gsyscall para _Grunning. Depois, através de runtime.Gosched, G voluntariamente cede direito de execução, P entra no loop de escalonamento para procurar outros G disponíveis:
oldp := gp.m.oldp.ptr()
gp.m.oldp = 0
if exitsyscallfast(oldp) {
// Há cpu para nós, então podemos executar
gp.m.p.ptr().syscalltick++
// Precisamos cas status e scan antes de retomar...
casgstatus(gp, _Gsyscall, _Grunning)
// Garbage collector não está executando (já que estamos),
// então ok limpar syscallsp
gp.syscallsp = 0
gp.m.locks--
if gp.preempt {
// restaura solicitação de preempção no caso de termos limpado em newstack
gp.stackguard0 = stackPreempt
} else {
// caso contrário restaura stackGuard real, estragamos em entersyscall/entersyscallblock
gp.stackguard0 = gp.stack.lo + stackGuard
}
gp.throwsplit = false
if sched.disable.user && !schedEnabled(gp) {
// Escalonamento desta goroutine está desabilitado
Gosched()
}
return
}Se não encontrar, M se desassocia de G, G muda de estado _Gsyscall para _Grunnable. Depois tenta novamente encontrar P ocioso. Se não encontrar, coloca G diretamente na fila global e entra em nova rodada de loop de escalonamento. M antigo entra em estado ocioso através de runtime.stopm, aguardando novas tarefas no futuro. Se P for encontrado, M antigo e G se associam com novo P e continuam executando código de usuário, estado muda de _Grunnable para _Grunning:
func exitsyscall0(gp *g) {
casgstatus(gp, _Gsyscall, _Grunnable)
dropg()
lock(&sched.lock)
var pp *p
if schedEnabled(gp) {
pp, _ = pidleget(0)
}
var locked bool
if pp == nil {
globrunqput(gp)
}
unlock(&sched.lock)
if pp != nil {
acquirep(pp)
execute(gp, false) // Nunca retorna
}
stopm()
schedule() // Nunca retorna
}Após sair da chamada de sistema, estado de G tem finalmente dois resultados: um é _Grunnable aguardando ser escalonado, outro é _Grunning continuando execução.
Suspensão
Quando a goroutine atual suspende por alguns motivos, estado muda de _Grunnable para _Gwaiting. Há muitos motivos para suspensão, pode ser devido a bloqueio de channel, select, lock ou time.sleep. Para mais motivos veja Estrutura G. Usando time.Sleep como exemplo, ele na verdade está ligado a runtime.timesleep. O código deste último é conforme abaixo:
func timeSleep(ns int64) {
if ns <= 0 {
return
}
gp := getg()
t := gp.timer
if t == nil {
t = new(timer)
gp.timer = t
}
t.f = goroutineReady
t.arg = gp
t.nextwhen = nanotime() + ns
if t.nextwhen < 0 { // verifica overflow
t.nextwhen = maxWhen
}
gopark(resetForSleep, unsafe.Pointer(t), waitReasonSleep, traceBlockSleep, 1)
}Pode-se ver que obtém a goroutine atual através de getg, depois faz a goroutine atual suspender através de runtime.gopark. runtime.gopark atualiza motivo de bloqueio de G e M, libera lock de M:
mp := acquirem()
gp := mp.curg
status := readgstatus(gp)
if status != _Grunning && status != _Gscanrunning {
throw("gopark: bad g status")
}
mp.waitlock = lock
mp.waitunlockf = unlockf
gp.waitreason = reason
mp.waitTraceBlockReason = traceReason
mp.waitTraceSkip = traceskip
releasem(mp)
// não pode fazer nada que possa mover G entre Ms aqui
mcall(park_m)Depois muda para stack do sistema e runtime.park_m muda estado de G para _Gwaiting, depois corta associação entre M e G e entra em novo loop de escalonamento para passar direito de execução para outros G. Após suspensão, G não executa código de usuário, também não está na fila local, apenas mantém referência para M e P:
mp := getg().m
casgstatus(gp, _Grunning, _Gwaiting)
dropg()
schedule()Na função runtime.timesleep há esta linha de código, especificando valor de t.f:
t.f = goroutineReadyEsta função runtime.goroutineReady é usada para acordar goroutine suspensa. Ela chama a função runtime.ready para acordar a goroutine:
status := readgstatus(gp)
// Marca como executável
mp := acquirem()
casgstatus(gp, _Gwaiting, _Grunnable)
runqput(mp.p.ptr(), gp, next)
wakep()
releasem(mp)Após acordar, muda estado de G para _Grunnable, depois coloca G na fila local de P aguardando ser escalonado no futuro.
Stack de Goroutine
Goroutines na linguagem Go são típicas goroutines com stack. Cada goroutine iniciada aloca um espaço de stack independente no heap, e ele cresce ou encolhe com mudanças no uso. Durante inicialização do escalonador, a função runtime.stackinit é responsável por inicializar caches globais de espaço de stack stackpool e stackLarge:
func stackinit() {
if _StackCacheSize&_PageMask != 0 {
throw("cache size must be a multiple of page size")
}
for i := range stackpool {
stackpool[i].item.span.init()
lockInit(&stackpool[i].item.mu, lockRankStackpool)
}
for i := range stackLarge.free {
stackLarge.free[i].init()
lockInit(&stackLarge.lock, lockRankStackLarge)
}
}Além disso, cada P tem seu próprio cache de espaço de stack independente mcache:
type p struct {
...
mcache *mcache
...
}
type mcache struct {
_ sys.NotInHeap
nextSample uintptr
scanAlloc uintptr
tiny uintptr
tinyoffset uintptr
tinyAllocs uintptr
alloc [numSpanClasses]*mspan
stackcache [_NumStackOrders]stackfreelist
flushGen atomic.Uint32
}Cache de thread mcache é independente para cada thread e não alocado em memória heap. Ao acessar não é necessário adicionar lock. Estes três caches de stack serão usados durante alocação de espaço subsequente.
Alocação
Ao criar goroutine, se não houver goroutine reutilizável, escolhe-se alocar um novo espaço de stack para ela. Seu tamanho padrão é 2KB:
newg := gfget(pp)
if newg == nil {
newg = malg(stackMin)
casgstatus(newg, _Gidle, _Gdead)
allgadd(newg) // publica com status g->status de Gdead para que scanner GC não olhe stack não inicializada
}A função responsável por alocar espaço de stack é runtime.stackalloc:
func stackalloc(n uint32) stackDe acordo com o tamanho da memória de stack solicitada ser menor que 32KB, divide-se em duas situações. 32KB é também o padrão no Go para julgar se é objeto pequeno ou objeto grande. Se menor que este valor, obtém-se do cache stackpool. Quando M se associa com P e M não pode ser preemptado, obtém-se do cache local de thread:
if n < fixedStack<<_NumStackOrders && n < _StackCacheSize {
order := uint8(0)
n2 := n
for n2 > fixedStack {
order++
n2 >>= 1
}
var x gclinkptr
if stackNoCache != 0 || thisg.m.p == 0 || thisg.m.preemptoff != "" {
lock(&stackpool[order].item.mu)
x = stackpoolalloc(order)
unlock(&stackpool[order].item.mu)
} else {
c := thisg.m.p.ptr().mcache
x = c.stackcache[order].list
if x.ptr() == nil {
stackcacherefill(c, order)
x = c.stackcache[order].list
}
c.stackcache[order].list = x.ptr().next
c.stackcache[order].size -= uintptr(n)
}
v = unsafe.Pointer(x)
}Se maior que 32KB, obtém-se do cache stackLarge. Se ainda não for suficiente, aloca-se memória diretamente no heap:
else {
var s *mspan
npage := uintptr(n) >> _PageShift
log2npage := stacklog2(npage)
// Tenta obter stack do cache de stack grande
lock(&stackLarge.lock)
if !stackLarge.free[log2npage].isEmpty() {
s = stackLarge.free[log2npage].first
stackLarge.free[log2npage].remove(s)
}
unlock(&stackLarge.lock)
lockWithRankMayAcquire(&mheap_.lock, lockRankMheap)
if s == nil {
// Aloca nova stack do heap
s = mheap_.allocManual(npage, spanAllocStack)
if s == nil {
throw("out of memory")
}
osStackAlloc(s)
s.elemsize = uintptr(n)
}
v = unsafe.Pointer(s.base())
}Após conclusão, retorna endereço baixo e alto do espaço de stack:
return stack{uintptr(v), uintptr(v) + uintptr(n)}Expansão
O tamanho padrão de stack de goroutine é 2KB, suficientemente leve, então custo de criar uma goroutine é muito baixo. Mas isso pode não ser suficiente. Quando espaço de stack não é suficiente, é necessário expandir. O compilador insere a função runtime.morestack no início das funções para verificar se a goroutine atual precisa de expansão de stack. Se precisar, chama runtime.newstack para completar a operação real de expansão:
TIP
Como morestack é inserido quase no início de todas as funções, o momento de verificação de expansão de stack é também um ponto de preempção de goroutine.
thisg := getg()
gp := thisg.m.curg
// Aloca segmento maior e move stack
oldsize := gp.stack.hi - gp.stack.lo
newsize := oldsize * 2
// Goroutine deve estar executando para chamar newstack,
// então deve estar Grunning (ou Gscanrunning)
casgstatus(gp, _Grunning, _Gcopystack)
// GC concorrente não escaneará stack enquanto estamos fazendo cópia já que
// gp está em status Gcopystack
copystack(gp, newsize)
casgstatus(gp, _Gcopystack, _Grunning)
gogo(&gp.sched)Pode-se ver que capacidade calculada de stack é duas vezes o original. A função runtime.copystack completa o trabalho de cópia de stack. Antes de copiar, estado de G muda de _Grunning para _Gcopystack:
func copystack(gp *g, newsize uintptr) {
old := gp.stack
used := old.hi - gp.sched.sp
// aloca nova stack
new := stackalloc(uint32(newsize))
// Computa ajuste
var adjinfo adjustinfo
adjinfo.old = old
adjinfo.delta = new.hi - old.hi
// Copia stack (ou resto dela) para nova localização
memmove(unsafe.Pointer(new.hi-ncopy), unsafe.Pointer(old.hi-ncopy), ncopy)
// Ajusta estruturas restantes que têm ponteiros para stacks
// Temos que fazer maioria destes antes de traceback da nova stack porque gentraceback os usa
adjustctxt(gp, &adjinfo)
adjustdefers(gp, &adjinfo)
adjustpanics(gp, &adjinfo)
if adjinfo.sghi != 0 {
adjinfo.sghi += adjinfo.delta
}
// Troca stack antiga por nova
gp.stack = new
gp.stackguard0 = new.lo + stackGuard // NOTA: pode clobber solicitação de preempção
gp.sched.sp = new.hi - used
gp.stktopsp += adjinfo.delta
// Ajusta ponteiros na nova stack
var u unwinder
for u.init(gp, 0); u.valid(); u.next() {
adjustframe(&u.frame, &adjinfo)
}
stackfree(old)
}Esta função realiza principalmente os seguintes trabalhos:
- Aloca novo espaço de stack
- Copia memória de stack antiga diretamente para novo espaço de stack através de
runtime.memmove - Ajusta estruturas contendo ponteiros de stack, como defer, panic etc.
- Atualiza campos de stack de G
- Ajusta ponteiros apontando para memória de stack antiga através de
runtime.adjustframe - Libera memória de stack antiga
Após conclusão, estado de G muda de _Gcopystack para _Grunning, e função runtime.gogo faz G continuar executando código de usuário. É justamente devido à existência de expansão de stack de goroutine que memória em Go é instável.
Contração
Quando estado de G é _Grunnable, _Gsyscall, _Gwaiting, GC escaneará espaço de memória de stack de goroutine:
func scanstack(gp *g, gcw *gcWork) int64 {
switch readgstatus(gp) &^ _Gscan {
case _Grunnable, _Gsyscall, _Gwaiting:
// ok
}
...
if isShrinkStackSafe(gp) {
// Encolhe stack se não muito está sendo usado
shrinkstack(gp)
}
...
}O trabalho real de contração de stack é completado por runtime.shrinkstack:
func shrinkstack(gp *g) {
if !isShrinkStackSafe(gp) {
throw("shrinkstack at bad time")
}
oldsize := gp.stack.hi - gp.stack.lo
newsize := oldsize / 2
if newsize < fixedStack {
return
}
avail := gp.stack.hi - gp.stack.lo
if used := gp.stack.hi - gp.sched.sp + stackNosplit; used >= avail/4 {
return
}
copystack(gp, newsize)
}Quando espaço de stack usado é menor que 1/4 do original, usa-se runtime.copystack para encolher para 1/2 do original. O trabalho posterior é igual ao anterior.
Stack Segmentado
Do processo de copystack pode-se ver que copia memória de stack antiga para espaço de stack maior. Tanto stack original quanto nova têm endereços de memória contínuos. No Go antigo,做法 de expansão de stack era diferente. Naquela época, achava-se que cópia de memória consumia muito desempenho, adotava-se abordagem de stack segmentado. Se memória de stack não era suficiente, solicitava-se novo espaço de stack. Memória de stack original não era liberada nem copiada, ligadas entre si através de ponteiros, formando uma lista encadeada de stacks. Esta é a origem do stack segmentado, conforme mostrado na figura abaixo:
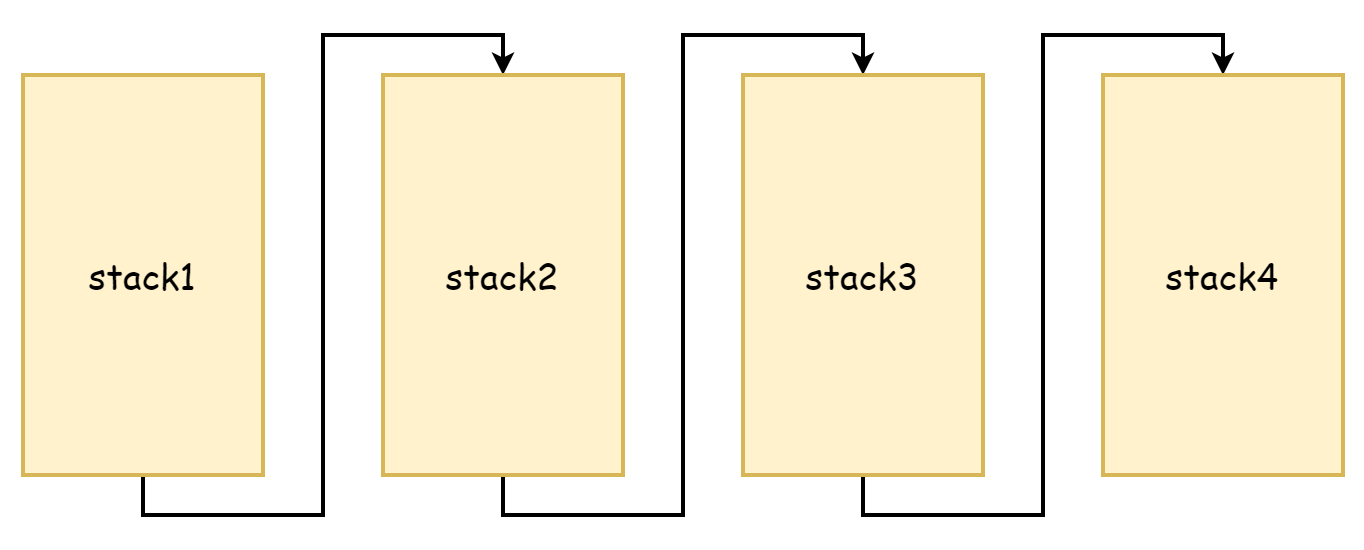
A vantagem disso é não precisar copiar stack original, mas desvantagem também é muito óbvia: aciona muito frequentemente expansão e contração de stack. Quando espaço livre de stack está quase esgotado, nova chamada de função aciona expansão de stack. Quando estas funções retornam, não precisando mais de novo espaço de stack, aciona-se contração. Se frequência destas chamadas de função é muito alta, então aciona-se muito frequentemente expansão e contração. O损耗 de desempenho causado por esta operação é muito grande.
Então, após Go 1.4, mudou-se para stack contínuo. Stack contínuo, por alocar espaço de stack de capacidade maior, não ocorre situação de memória usada atingir valor crítico onde chamada de função aciona frequentemente expansão/contração. E como endereços de memória são contínuos, de acordo com princípio de localidade espacial de cache, stack contínuo também é mais amigável para cache de CPU.
Loop de Escalonamento
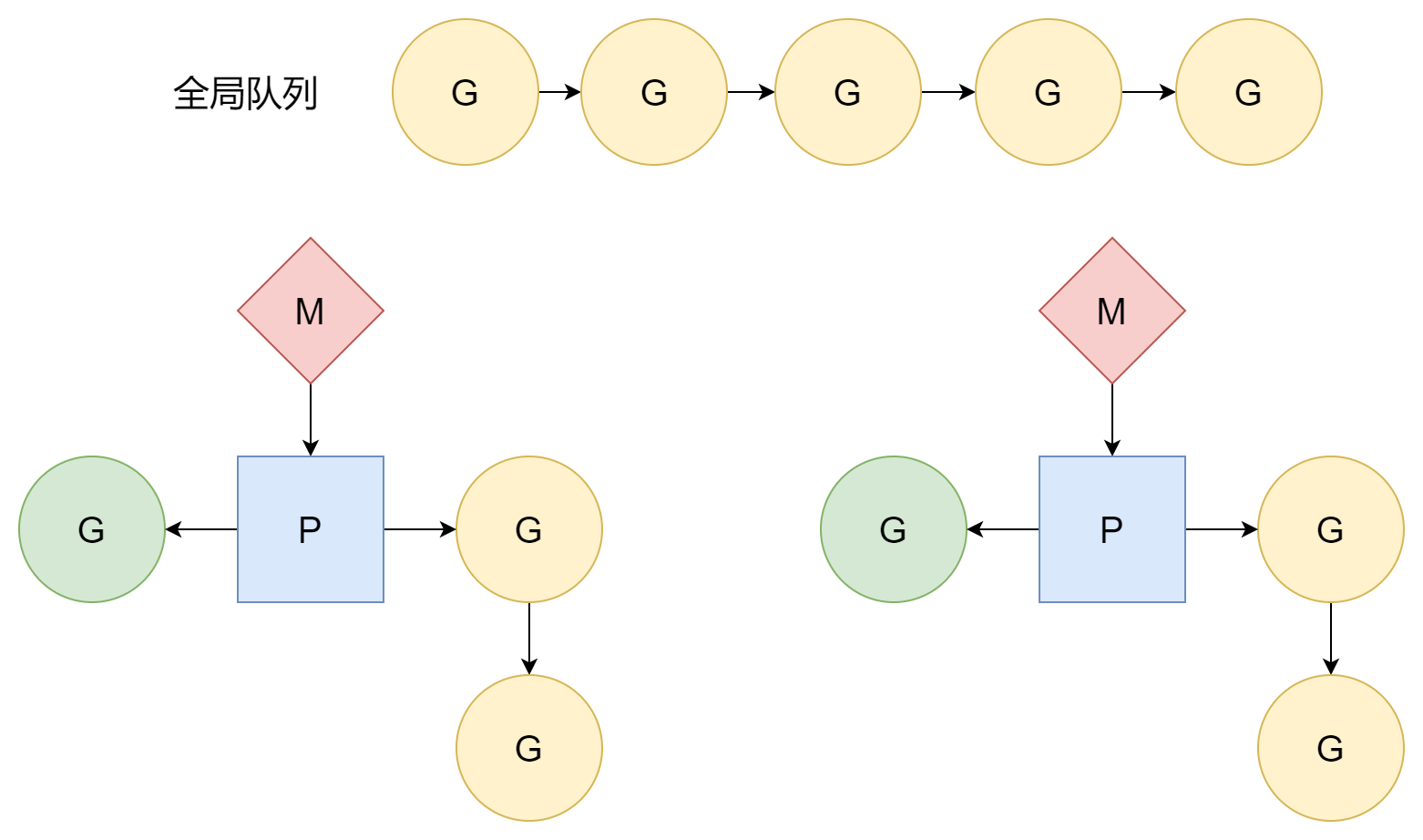
Na parte de inicialização do escalonador mencionamos que, na função runtime.mstart1, após M se associar com sucesso com P, entra no primeiro loop de escalonamento runtime.schedule,正式开始 escalonando G para executar código de usuário. No loop de escalonamento, esta parte é principalmente P desempenhando papel. M corresponde à thread do sistema, G corresponde à função de entrada, ou seja, código de usuário. Mas P não tem entidade correspondente como M e G, é apenas um conceito abstrato, como intermediário processando relação entre M e G:
func schedule() {
mp := getg().m
top:
pp := mp.p.ptr()
pp.preempt = false
if mp.spinning {
resetspinning()
}
gp, inheritTime, tryWakeP := findRunnable() // bloqueia até trabalho estar disponível
execute(gp, inheritTime)
}O código acima foi simplificado, removendo muitos julgamentos de condição. Os pontos mais centrais são apenas dois: runtime.findRunnable e runtime.execute. O primeiro é responsável por encontrar um G, e certamente retorna um G disponível. O segundo é responsável por fazer G continuar executando código de usuário.
Para a função findRunnable, a primeira fonte de G é a fila local de P:
// fila local runq
if gp, inheritTime := runqget(pp); gp != nil {
return gp, inheritTime, false
}Se fila local não tem G, então tenta obter da fila global:
// fila global runq
if sched.runqsize != 0 {
lock(&sched.lock)
gp := globrunqget(pp, 0)
unlock(&sched.lock)
if gp != nil {
return gp, false, false
}
}Se não encontrar na local e global, tenta obter do network poller:
if netpollinited() && netpollWaiters.Load() > 0 && sched.lastpoll.Load() != 0 {
if list := netpoll(0); !list.empty() { // não-bloqueante
gp := list.pop()
injectglist(&list)
casgstatus(gp, _Gwaiting, _Grunnable)
if traceEnabled() {
traceGoUnpark(gp, 0)
}
return gp, false, false
}
}Se ainda não encontrar, finalmente tenta "roubar" G da fila local de outros P. Ao criar goroutine mencionamos que uma grande fonte de G na fila local de P é goroutine filha derivada da goroutine atual. Porém, nem todas as goroutines criam goroutines filhas. Assim pode ocorrer situação onde parte de P está muito ocupada, outra parte de P está ociosa. Isso leva a uma situação: algumas G's por estarem sempre aguardando não conseguem executar, enquanto do outro lado P está muito ocioso, sem nada para fazer. Para poder aproveitar todos os P, fazendo-os trabalhar com máxima eficiência, quando P não encontra G, vai à fila local de outros P "roubar" G executável. Assim, cada P pode ter fila de G relativamente uniforme, raramente ocorre situação de P's observando fogo do outro lado:
gp, inheritTime, tnow, w, newWork := stealWork(now)
if gp != nil {
// Roubou com sucesso
return gp, inheritTime, false
}runtime.stealWork seleciona aleatoriamente um P para roubar. O trabalho real de roubo é completado pela função runtime.runqgrab, que tenta roubar metade das G's da fila local deste P:
for {
h := atomic.LoadAcq(&pp.runqhead) // load-acquire, sincroniza com outros consumidores
t := atomic.LoadAcq(&pp.runqtail) // load-acquire, sincroniza com produtor
n := t - h
n = n - n/2
if n > uint32(len(pp.runq)/2) { // lê h e t inconsistentes
continue
}
for i := uint32(0); i < n; i++ {
g := pp.runq[(h+i)%uint32(len(pp.runq))]
batch[(batchHead+i)%uint32(len(batch))] = g
}
if atomic.CasRel(&pp.runqhead, h, h+n) { // cas-release, commita consumo
return n
}
}Todo trabalho de roubo é realizado quatro vezes. Se após quatro vezes também não conseguir roubar G, então retorna. Se finalmente não conseguir encontrar, M atual é pausado por runtime.stopm, até ser acordado e continuar repetindo passos acima. Quando encontra e retorna um G, entrega para runtime.execute executar G:
mp := getg().m
mp.curg = gp
gp.m = mp
casgstatus(gp, _Grunnable, _Grunning)
gp.waitsince = 0
gp.preempt = false
gp.stackguard0 = gp.stack.lo + stackGuard
gogo(&gp.sched)Primeiro atualiza curg de M, depois atualiza estado de G para _Grunning, finalmente entrega para runtime.gogo restaurar execução de G.
Resumindo, no loop de escalonamento, fontes de G de acordo com prioridade são quatro:
- Fila local de P
- Fila global
- Network poller
- Roubar da fila local de outros P
runtime.execute após executar não retorna, e G recém obtido também não executa para sempre. Em algum momento aciona escalonamento, seu direito de execução é剥夺, depois entra em nova rodada de loop de escalonamento, passa direito de execução para outros G.
Estratégia de Escalonamento
Diferentes G podem ter tempos diferentes executando código de usuário. Parte de G pode consumir muito tempo, parte de G pode consumir pouco tempo. G com tempo de execução longo pode causar que outros G não consigam executar. Então executar G alternadamente é a maneira correta. No sistema operacional, esta forma de trabalho é chamada de concorrência.
Escalonamento Cooperativo
A ideia básica de escalonamento cooperativo é deixar G voluntariamente ceder direito de execução para outros G. Há principalmente dois métodos.
Primeiro método é ceder voluntariamente no código de usuário. Go fornece função runtime.Gosched(), usuário pode decidir por si quando ceder direito de execução. Porém, muitas vezes detalhes internos do trabalho do escalonador são uma caixa preta para usuário, difícil julgar exatamente quando ceder voluntariamente. Requisitos para usuário são relativamente altos. E escalonador do Go busca ocultar maioria dos detalhes para usuário, buscando método de uso mais simples. Neste caso, fazer usuário também participar do trabalho de escalonamento não é algo bom.
Segundo método é marca de preempção. Embora tenha palavra "preempção" no nome, essencialmente ainda é estratégia de escalonamento cooperativo. A ideia é inserir código de detecção de preempção runtime.morestack() no cabeçalho das funções. Inserção é completada durante período de compilação. Mencionamos anteriormente que originalmente é função usada para detecção de expansão de stack. Como seu ponto de detecção é cada chamada de função, este também é bom momento para realizar detecção de preempção. Parte superior da função runtime.newstack está toda realizando detecção de preempção, parte inferior está realizando detecção de expansão de stack. Para evitar interferência anteriormente omitimos esta parte. Agora vamos ver o que esta parte faz. Primeiro julga preempção de acordo com gp.stackguard0. Se não precisar, continua executando código de usuário:
stackguard0 := atomic.Loaduintptr(&gp.stackguard0)
preempt := stackguard0 == stackPreempt
if preempt {
if !canPreemptM(thisg.m) {
gp.stackguard0 = gp.stack.lo + stackGuard
gogo(&gp.sched) // nunca retorna
}
}Quando g.stackguard0 == stackPreempt, função runtime.canPreemptM() julga se condições da goroutine precisam ser preemptadas. Código conforme abaixo:
func canPreemptM(mp *m) bool {
return mp.locks == 0 && mp.mallocing == 0 && mp.preemptoff == "" && mp.p.ptr().status == _Prunning
}Pode-se ver que para ser preemptado precisa satisfazer quatro condições:
- M não está bloqueado
- Não está alocando memória
- Não desabilitou preempção
- P está em estado
_Prunning
E nas duas situações abaixo define-se g.stackguard0 como stackPreempt:
- Quando é necessário realizar garbage collection
- Quando ocorre chamada de sistema
if preempt {
if gp.preemptShrink {
gp.preemptShrink = false
shrinkstack(gp)
}
// Age como goroutine chamou runtime.Gosched
gopreempt_m(gp) // nunca retorna
}Finalmente chega-se a runtime.gopreempt_m() para ceder voluntariamente direito de execução da goroutine atual. Primeiro corta associação entre M e G, estado muda para _Grunnable, depois coloca G na fila global, finalmente entra no loop de escalonamento para ceder direito de execução para outros G:
casgstatus(gp, _Grunning, _Grunnable)
dropg()
lock(&sched.lock)
globrunqput(gp)
unlock(&sched.lock)
schedule()Assim, todas as goroutines ao realizar chamada de função podem entrar nesta função para detecção de preempção. Esta estratégia depende do momento de chamada de função para acionar preempção e ceder voluntariamente. Antes de 1.14, Go sempre usou esta estratégia de escalonamento. Mas isso tem um problema: se não há chamada de função, não pode detectar. Por exemplo, este código clássico, que deve aparecer em muitos tutoriais:
func main() {
// Limita número de P para 1
runtime.GOMAXPROCS(1)
// Goroutine 1
go func() {
for {
// Esta goroutine fica em loop vazio
}
}()
// Entra em chamada de sistema, goroutine principal cede para outras goroutines
time.Sleep(time.Millisecond)
println("exit")
}O código cria uma goroutine 1 em loop vazio, depois goroutine principal voluntariamente cede devido a chamada de sistema. Neste momento, goroutine 1 está sendo escalonada. Mas como根本 não chama função, também não pode realizar detecção de preempção. Como há apenas um P, não há outros P ociosos. Isso leva a que goroutine principal nunca possa ser escalonada, exit também nunca é impresso. Mas este problema é limitado a antes de Go 1.14.
Escalonamento Preemptivo
Oficialmente em Go 1.14 adicionou-se estratégia de escalonamento preemptivo baseado em sinal. Esta é uma estratégia de preempção assíncrona, através de thread assíncrona enviando sinal para realizar preempção de thread. Escalonamento preemptivo baseado em sinal atualmente tem duas entradas: monitor de sistema e GC.
No loop de monitor de sistema, percorre cada P. Se tempo de execução de G escalonado por P excede 10ms, força acionamento de preempção. Este trabalho é completado pela função runtime.retake. Abaixo está código simplificado:
func retake(now int64) uint32 {
n := 0
lock(&allpLock)
for i := 0; i < len(allp); i++ {
pp := allp[i]
if pp == nil {
continue
}
pd := &pp.sysmontick
s := pp.status
sysretake := false
if s == _Prunning || s == _Psyscall {
// Preempt G se estiver executando por tempo muito longo
t := int64(pp.schedtick)
if int64(pd.schedtick) != t {
pd.schedtick = uint32(t)
pd.schedwhen = now
} else if pd.schedwhen+forcePreemptNS <= now {
preemptone(pp)
sysretake = true
}
}
}
unlock(&allpLock)
return uint32(n)
}Quando é necessário realizar garbage collection, se estado de G é _Grunning, ou seja, ainda executando, também aciona preempção:
func suspendG(gp *g) suspendGState {
for i := 0; ; i++ {
switch s := readgstatus(gp); s {
case _Grunning:
gp.preemptStop = true
gp.preempt = true
gp.stackguard0 = stackPreempt
casfrom_Gscanstatus(gp, _Gscanrunning, _Grunning)
if preemptMSupported && debug.asyncpreemptoff == 0 && needAsync {
now := nanotime()
if now >= nextPreemptM {
nextPreemptM = now + yieldDelay/2
preemptM(asyncM)
}
}
......
......
func preemptM(mp *m) {
if mp.signalPending.CompareAndSwap(0, 1) {
if GOOS == "darwin" || GOOS == "ios" {
pendingPreemptSignals.Add(1)
}
signalM(mp, sigPreempt)
}
}Duas entradas de preempção finalmente entram na função runtime.preemptM, que completa envio de sinal de preempção. Quando sinal é enviado com sucesso, callback de processador de sinal registrado através de runtime.initsig em runtime.mstart, função runtime.sighandler, é usado. Se detecta que sinal enviado é sinal de preempção, começa preempção:
func sighandler(sig uint32, info *siginfo, ctxt unsafe.Pointer, gp *g) {
...
if sig == sigPreempt && debug.asyncpreemptoff == 0 && !delayedSignal {
// Pode ser sinal de preempção
doSigPreempt(gp, c)
}
...
}doSigPreempt modifica contexto da goroutine alvo, injeta chamada runtime.asyncPreempt:
func doSigPreempt(gp *g, ctxt *sigctxt) {
// Verifica se este G quer ser preemptado e é seguro
// preemptar
if wantAsyncPreempt(gp) {
if ok, newpc := isAsyncSafePoint(gp, ctxt.sigpc(), ctxt.sigsp(), ctxt.siglr()); ok {
// Ajusta PC e injeta chamada para asyncPreempt
ctxt.pushCall(abi.FuncPCABI0(asyncPreempt), newpc)
}
}
...Assim, quando retorna para código de usuário, goroutine alvo chega à função runtime.asyncPreempt. Esta função envolve chamada para runtime.asyncPreempt2:
TEXT ·asyncPreempt(SB),NOSPLIT|NOFRAME,$0-0
PUSHQ BP
MOVQ SP, BP
// Salva flags antes de clobber
PUSHFQ
// obj não entende ADD/SUB em SP, mas entende ADJSP
ADJSP $368
// Mas vet não conhece ADJSP, então suprime verificação de stack vet
...
CALL ·asyncPreempt2(SB)
...
RETFaz goroutine atual parar trabalho e realizar nova rodada de loop de escalonamento para ceder direito de execução para outras goroutines:
func asyncPreempt2() {
gp := getg()
gp.asyncSafePoint = true
if gp.preemptStop {
mcall(preemptPark)
} else {
mcall(gopreempt_m)
}
gp.asyncSafePoint = false
}Este processo todo ocorre na função runtime.asyncPreempt, implementada em assembly (localizada em runtime/preempt_*.s) e restaura contexto de goroutine modificado anteriormente após conclusão do escalonamento, para que esta goroutine possa normalmente restaurar no futuro. Após adotar estratégia de preempção assíncrona, exemplo anterior não mais bloqueia permanentemente goroutine principal. Quando goroutine em loop vazio executa por certo tempo, é forçada a executar loop de escalonamento, assim cede direito de execução para goroutine principal, finalmente permitindo que programa termine normalmente.
Resumo
Resumindo, momentos que acionam escalonamento incluem:
- Chamada de função
- Chamada de sistema
- Monitor de sistema
- Garbage collection, garbage collection também realiza preempção para goroutines com tempo de execução muito longo
- Goroutine suspende devido a reasons como channel, lock etc.
Estratégias de escalonamento são principalmente duas categorias: cooperativo e preemptivo. Cooperativo é ceder voluntariamente direito de execução, preemptivo é assincronamente preemptar direito de execução. Ambos coexistem para formar o escalonador atual.