gmp
Una de las características más importantes del lenguaje Go es su soporte nativo para concurrencia. Solo se necesita una palabra clave para iniciar una goroutine, como se muestra en el siguiente ejemplo:
import (
"fmt"
"sync"
)
func main() {
var wg sync.WaitGroup
wg.Add(2)
go func() {
defer wg.Done()
fmt.Println("hello world!")
}()
go func() {
defer wg.Done()
fmt.Println("hello world too!")
}()
wg.Wait()
}Las goroutines en Go son muy fáciles de usar. Los desarrolladores casi no necesitan hacer trabajo adicional, lo cual es una de las razones de su popularidad. Sin embargo, detrás de esta simplicidad hay un planificador de concurrencia no trivial que lo respalda todo. Su nombre, GMP, proviene de sus tres componentes principales: G (goroutine), M (hilo del sistema) y P (procesador). El diseño del planificador GMP ha influido en todo el diseño del tiempo de ejecución de Go, incluyendo GC y el poller de red. Se puede decir que es el núcleo más importante del lenguaje. Comprenderlo puede ser de gran ayuda en el trabajo futuro.
Historia
El modelo de planificación de concurrencia de Go no es completamente original. Absorbió las experiencias y lecciones de sus predecesores, evolucionando y mejorando continuamente hasta su forma actual. Los lenguajes que influyeron incluyen:
- Occam - 1983
- Erlang - 1986
- Newsqueak - 1988
- Concurrent ML - 1993
- Alef - 1995
- Limbo - 1996
La influencia más significativa proviene del artículo sobre CSP (Communicating Sequential Processes) publicado por Hoare en 1978. La idea fundamental de CSP es que los procesos intercambian datos mediante comunicación. Todos los lenguajes mencionados anteriormente fueron influenciados por las ideas de CSP. Erlang es el ejemplo más típico de un lenguaje orientado a mensajes. El famoso middleware de cola de mensajes de código abierto RabbitMQ está escrito en Erlang. En la actualidad, con el desarrollo de la informática e Internet, el soporte de concurrencia se ha convertido en un estándar para los lenguajes modernos. Go, combinando las ideas de CSP, surgió en este contexto.
Modelo de Planificación
Presentemos brevemente los tres componentes de GMP:
- G, Goroutine: Se refiere a las goroutines en Go
- M, Machine: Se refiere a hilos del sistema o hilos de trabajo (worker thread), programados por el sistema operativo
- P, Processor: No se refiere a CPU, es un concepto abstracto de Go. Se refiere a procesadores que trabajan en hilos del sistema, programando goroutines en cada hilo.
Las goroutines son hilos más ligeros, con menor escala y menos recursos necesarios. La creación, destrucción y programación son manejadas por el tiempo de ejecución de Go, no por el sistema operativo, por lo que su costo de gestión es mucho menor que el de los hilos. Sin embargo, las goroutines dependen de los hilos. El tiempo de ejecución de las goroutines proviene del tiempo de los hilos, y el tiempo de los hilos proviene del sistema operativo. El cambio entre diferentes hilos tiene cierto costo. La clave del diseño es cómo hacer que las goroutines aprovechen bien el tiempo de los hilos.
1:N
La mejor manera de resolver el problema es ignorarlo. Si el cambio de hilos tiene un costo, simplemente no cambies. Asigna todas las goroutines a un solo hilo del kernel. De esta manera, solo se involucra el cambio entre goroutines.
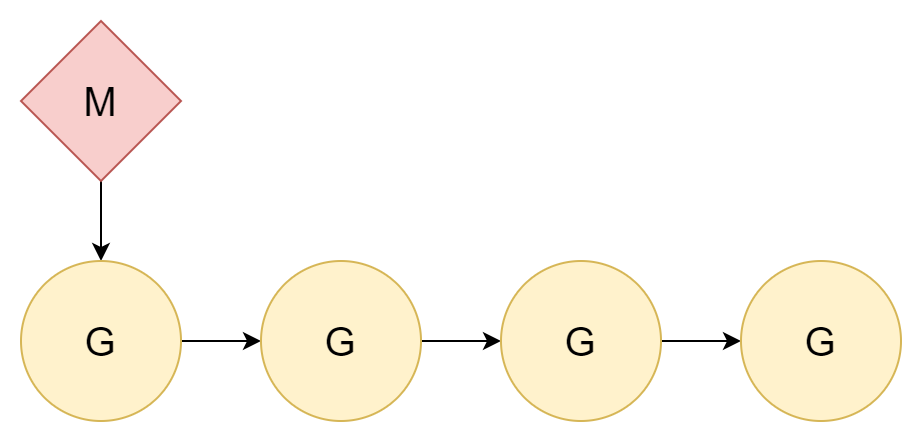
La relación entre hilos y goroutines es 1:N. Esto tiene una desventaja obvia: las computadoras modernas son casi todas CPU multinúcleo, y esta asignación no puede aprovechar completamente el rendimiento de múltiples núcleos.
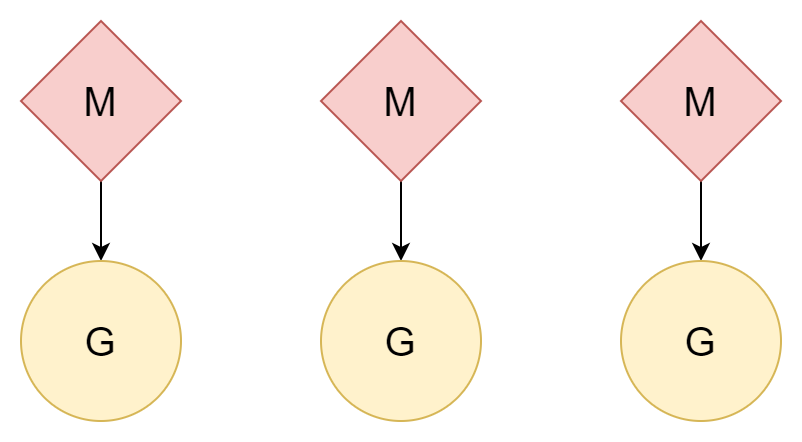
N:N
Otro método es un hilo por goroutine. Una goroutine puede disfrutar de todo el tiempo de un hilo, y múltiples hilos pueden aprovechar múltiples núcleos de CPU. Sin embargo, el costo de creación y cambio de hilos es relativamente alto. Si es una relación uno a uno, no se aprovecha la ventaja de ligereza de las goroutines.
M:N
M hilos corresponden a N goroutines, donde M es menor que N. Múltiples hilos corresponden a múltiples goroutines. Cada hilo corresponde a varias goroutines, y el procesador P es responsable de programar cómo las goroutines G usan el tiempo de los hilos. Este método es relativamente mejor y ha sido el modelo de planificación de Go hasta ahora.
M solo puede ejecutar tareas después de asociarse con el procesador P. Go creará GOMAXPROCS procesadores, por lo que el número real de hilos que pueden ejecutar tareas es GOMAXPROCS. Su valor predeterminado es el número de núcleos lógicos de CPU de la máquina actual, pero también podemos establecerlo manualmente.
- Modificar mediante código
runtime.GOMAXPROCS(N), se puede ajustar dinámicamente en tiempo de ejecución, y llama a STW directamente después de la invocación. - Establecer variable de entorno
export GOMAXPROCS=N, estático.
En la práctica, el número de M es mayor que el número de P, porque se necesitan para manejar otras tareas en tiempo de ejecución, como llamadas al sistema. El valor máximo es 10000.
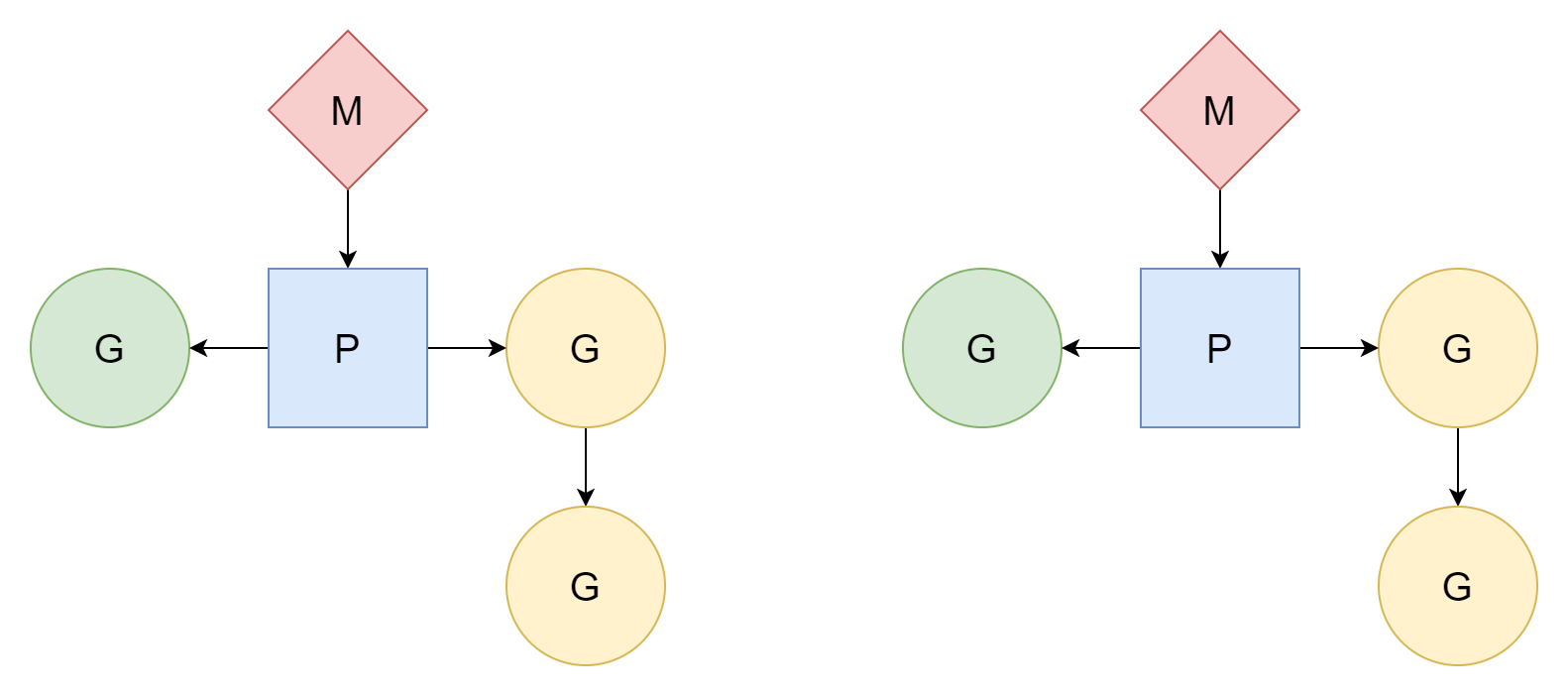
Los tres participantes GMP y el planificador mismo tienen sus representaciones de tipo en tiempo de ejecución, ubicadas en el archivo runtime/runtime2.go. A continuación se presenta una introducción simple a sus estructuras para facilitar la comprensión posterior.
G
G se representa como la estructura runtime.g en tiempo de ejecución, es la unidad de planificación básica en el modelo de planificación. Su estructura es la siguiente. Para facilitar la comprensión, se han eliminado muchos campos.
type g struct {
stack stack // offset known to runtime/cgo
_panic *_panic // innermost panic - offset known to liblink
_defer *_defer // innermost defer
m *m // current m; offset known to arm liblink
sched gobuf
goid uint64
waitsince int64 // approx time when the g become blocked
waitreason waitReason // if status==Gwaiting
atomicstatus atomic.Uint32
preempt bool // preemption signal, duplicates stackguard0 = stackpreempt
startpc uintptr // pc of goroutine function
parentGoid uint64 // goid of goroutine that created this goroutine
waiting *sudog // sudog structures this g is waiting on (that have a valid elem ptr); in lock order
}El primer campo es la dirección de inicio y fin de la memoria del stack perteneciente a la goroutine:
type stack struct {
lo uintptr
hi uintptr
}_panic y _defer son punteros que apuntan al stack de panic y defer respectivamente:
_panic *_panic // innermost panic - offset known to liblink
_defer *_defer // innermost deferm es la goroutine que está ejecutando actualmente la g:
m *m // current m; offset known to arm liblinkpreempt indica si la goroutine actual debe ser preemptada, equivalente a g.stackguard0 = stackpreempt:
preempt bool // preemption signal, duplicates stackguard0 = stackpreemptatomicstatus se usa para almacenar el valor de estado de la goroutine G, con los siguientes valores opcionales:
| Nombre | Descripción |
|---|---|
| _Gidle | Recién asignada, no inicializada |
| _Grunnable | La goroutine puede ejecutarse, está en la cola de espera |
| _Grunning | La goroutine está ejecutando código de usuario |
| _Gsyscall | Se asignó una M para ejecutar llamadas al sistema |
| _Gwaiting | Goroutine bloqueada, la razón del bloqueo se describe más abajo |
| _Gdead | La goroutine no está en uso, puede haber salido o recién inicializada |
| _Gcopystack | El stack de la goroutine se está moviendo, no ejecuta código de usuario ni está en la cola de espera |
| _Gpreempted | Bloqueada en preempt, esperando ser despertada por el preemptor |
| _Gscan | GC está escaneando el stack de la goroutine, puede coexistir con otros estados |
sched almacena la información de contexto de la goroutine para restaurar el sitio de ejecución. Se puede ver que contiene los punteros sp, pc, ret:
type gobuf struct {
sp uintptr
pc uintptr
g guintptr
ctxt unsafe.Pointer
ret uintptr
lr uintptr
bp uintptr // for framepointer-enabled architectures
}waiting indica la goroutine que la actual está esperando. waitsince registra el momento en que la goroutine se bloqueó. waitreason indica la razón del bloqueo de la goroutine, con los siguientes valores opcionales:
var waitReasonStrings = [...]string{
waitReasonZero: "",
waitReasonGCAssistMarking: "GC assist marking",
waitReasonIOWait: "IO wait",
waitReasonChanReceiveNilChan: "chan receive (nil chan)",
waitReasonChanSendNilChan: "chan send (nil chan)",
waitReasonDumpingHeap: "dumping heap",
waitReasonGarbageCollection: "garbage collection",
waitReasonGarbageCollectionScan: "garbage collection scan",
waitReasonPanicWait: "panicwait",
waitReasonSelect: "select",
waitReasonSelectNoCases: "select (no cases)",
waitReasonGCAssistWait: "GC assist wait",
waitReasonGCSweepWait: "GC sweep wait",
waitReasonGCScavengeWait: "GC scavenge wait",
waitReasonChanReceive: "chan receive",
waitReasonChanSend: "chan send",
waitReasonFinalizerWait: "finalizer wait",
waitReasonForceGCIdle: "force gc (idle)",
waitReasonSemacquire: "semacquire",
waitReasonSleep: "sleep",
waitReasonSyncCondWait: "sync.Cond.Wait",
waitReasonSyncMutexLock: "sync.Mutex.Lock",
waitReasonSyncRWMutexRLock: "sync.RWMutex.RLock",
waitReasonSyncRWMutexLock: "sync.RWMutex.Lock",
waitReasonTraceReaderBlocked: "trace reader (blocked)",
waitReasonWaitForGCCycle: "wait for GC cycle",
waitReasonGCWorkerIdle: "GC worker (idle)",
waitReasonGCWorkerActive: "GC worker (active)",
waitReasonPreempted: "preempted",
waitReasonDebugCall: "debug call",
waitReasonGCMarkTermination: "GC mark termination",
waitReasonStoppingTheWorld: "stopping the world",
}goid y parentGoid representan el identificador único de la goroutine actual y la goroutine padre. startpc representa la dirección de la función de entrada de la goroutine actual.
M
M se representa como la estructura runtime.m en tiempo de ejecución, es una abstracción de hilos de trabajo:
type m struct {
id int64
g0 *g // goroutine with scheduling stack
curg *g // current running goroutine
gsignal *g // signal-handling g
goSigStack gsignalStack // Go-allocated signal handling stack
p puintptr // attached p for executing go code (nil if not executing go code)
nextp puintptr
oldp puintptr // the p that was attached before executing a syscall
mallocing int32
throwing throwType
preemptoff string // if != "", keep curg running on this m
locks int32
dying int32
spinning bool // m is out of work and is actively looking for work
tls [tlsSlots]uintptr
...
}De manera similar, M tiene muchos campos internos. Aquí solo se introducen algunos campos para facilitar la comprensión:
id: Identificador único de Mg0: Goroutine con stack de planificacióncurg: Goroutine de usuario ejecutándose en el hilo de trabajogsignal: Goroutine responsable de manejar señales del hilogoSigStack: Stack asignado por Go para manejo de señalesp: Dirección del procesador P,oldpapunta al P antes de ejecutar una llamada al sistema,nextpapunta al nuevo P asignadomallocing: Indica si se está asignando nuevo espacio de memoriathrowing: Indica el tipo de error que ocurrió en Mpreemptoff: Identificador de preemptación. Cuando es una cadena vacía, la goroutine en ejecución puede ser preemptadalocks: Número de "locks" actuales de M. Cuando no es 0, se prohíbe la preemptacióndying: Indica que M ocurrió unpanicirrecuperable. Tiene cuatro valores opcionales[0,3], de menor a mayor indica gravedadspinning: Indica que M está en estado inactivo y disponibletls: Almacenamiento local del hilo
P
P se representa como runtime.p en tiempo de ejecución, responsable de programar el trabajo entre M y G. Su estructura es la siguiente:
type p struct {
id int32
status uint32 // one of pidle/prunning/...
schedtick uint32 // incremented on every scheduler call
syscalltick uint32 // incremented on every system call
sysmontick sysmontick // last tick observed by sysmon
m muintptr // back-link to associated m (nil if idle)
// Queue of runnable goroutines. Accessed without lock.
runqhead uint32
runqtail uint32
runq [256]guintptr
runnext guintptr
// Available G's (status == Gdead)
gFree struct {
gList
n int32
}
// preempt is set to indicate that this P should be enter the
// scheduler ASAP (regardless of what G is running on it).
preempt bool
...
}status indica el estado de P, con los siguientes valores opcionales:
| Valor | Descripción |
|---|---|
| _Pidle | P está inactivo, puede ser asignado a M por el planificador, o puede estar en transición entre otros estados |
| _Prunning | P está asociado con M y está ejecutando código de usuario |
| _Psyscall | M asociado con P está realizando una llamada al sistema. Durante este período, P puede ser preemptado por otros M |
| _Pgcstop | P se detuvo debido a GC |
| _Pdead | La mayoría de los recursos de P fueron eliminados, ya no se usará |
Los siguientes campos registran la cola local runq de P. Se puede ver que el tamaño máximo de la cola local es 256. Después de exceder este número, G se colocará en la cola global.
runqhead uint32
runqtail uint32
runq [256]guintptrrunnext indica la siguiente G disponible:
runnext guintptrLos otros campos se explican a continuación:
id: Identificador único de Pschedtick: Incrementa con cada llamada al planificador, visible en la funciónruntime.executesyscalltick: Incrementa con cada llamada al sistemasysmontick: Registra la información observada por última vez por el monitor del sistemam: M asociado con PgFree: Lista de G inactivaspreempt: Indica que P debe volver a entrar en el planificador
La información de la cola global se almacena en la estructura runtime.schedt, que es la representación del planificador en tiempo de ejecución:
type schedt struct {
...
midle muintptr // idle m's waiting for work
ngsys atomic.Int32 // number of system goroutines
pidle puintptr // idle p's
// Global runnable queue.
runq gQueue
runqsize int32
...
}Inicialización
La inicialización del planificador se encuentra en la fase de arranque del programa Go. La función responsable de iniciar el programa Go es runtime.rt0_go, implementada en ensamblador en el archivo runtime/asm_*.s. Parte del código es el siguiente:
TEXT runtime·rt0_go(SB),NOSPLIT|NOFRAME|TOPFRAME,$0
...
...
CALL runtime·check(SB)
MOVL 24(SP), AX // copy argc
MOVL AX, 0(SP)
MOVQ 32(SP), AX // copy argv
MOVQ AX, 8(SP)
CALL runtime·args(SB)
CALL runtime·osinit(SB)
CALL runtime·schedinit(SB)
// create a new goroutine to start program
MOVQ $runtime·mainPC(SB), AX // entry
PUSHQ AX
CALL runtime·newproc(SB)
POPQ AX
// start this M
CALL runtime·mstart(SB)
CALL runtime·abort(SB) // mstart should never return
RETSe pueden ver las llamadas a runtime·osinit y runtime·schedinit en las siguientes dos líneas:
CALL runtime·osinit(SB)
CALL runtime·schedinit(SB)La primera es responsable de inicializar el trabajo relacionado con el sistema operativo, y la segunda es responsable de la inicialización del planificador, es decir, la función runtime·schedinit. Es responsable de inicializar los recursos necesarios para la ejecución del planificador al inicio del programa. A continuación se muestra el código simplificado:
func schedinit() {
...
gp := getg()
sched.maxmcount = 10000
// The world starts stopped.
worldStopped()
...
stackinit()
mallocinit()
mcommoninit(gp.m, -1)
lock(&sched.lock)
procs := ncpu
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
}
if procresize(procs) != nil {
throw("unknown runnable goroutine during bootstrap")
}
unlock(&sched.lock)
...
// World is effectively started now, as P's can run.
worldStarted()
...
}La función runtime.getg está implementada en ensamblador. Su función es obtener la representación en tiempo de ejecución de la goroutine actual, es decir, el puntero a la estructura runtime.g. A través de sched.maxmcount = 10000, se puede ver que el número máximo de M se establece en 10000 durante la inicialización del planificador. Este valor es fijo y no se puede modificar. Después se inicializa el stack, y luego se usa la función runtime.mcommoninit para inicializar M. La implementación de la función es la siguiente:
func mcommoninit(mp *m, id int64) {
gp := getg()
// g0 stack won't make sense for user (and is not necessary unwindable).
if gp != gp.m.g0 {
callers(1, mp.createstack[:])
}
lock(&sched.lock)
if id >= 0 {
mp.id = id
} else {
mp.id = mReserveID()
}
...
mpreinit(mp)
if mp.gsignal != nil {
mp.gsignal.stackguard1 = mp.gsignal.stack.lo + stackGuard
}
// Add to allm so garbage collector doesn't free g->m
// when it is just in a register or thread-local storage.
mp.alllink = allm
// NumCgoCall() iterates over allm w/o schedlock,
// so we need to publish it safely.
atomicstorep(unsafe.Pointer(&allm), unsafe.Pointer(mp))
unlock(&sched.lock)
...
}Esta función realiza la pre-inicialización de M, principalmente haciendo el siguiente trabajo:
- Asignar el id de M
- Asignar una G separada para manejar señales del hilo, completado por la función
runtime.mpreinit - Agregarlo como el nodo cabeza de la lista enlazada global de M
runtime.allm
A continuación se inicializa P. Su cantidad predeterminada es el número de núcleos lógicos de CPU, seguido del valor de la variable de entorno:
procs := ncpu
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
}
if procresize(procs) != nil {
throw("unknown runnable goroutine during bootstrap")
}Finalmente, la función runtime.procresize es responsable de inicializar P. Modificará el slice global runtime.allp que almacena todos los P según la cantidad ingresada. Primero determina si se necesita expansión según el tamaño:
if nprocs > int32(len(allp)) {
// Synchronize with retake, which could be running
// concurrently since it doesn't run on a P.
lock(&allpLock)
if nprocs <= int32(cap(allp)) {
allp = allp[:nprocs]
} else {
nallp := make([]*p, nprocs)
// Copy everything up to allp's cap so we
// never lose old allocated Ps.
copy(nallp, allp[:cap(allp)])
allp = nallp
}
unlock(&allpLock)
}Luego inicializa cada P:
// initialize new P's
for i := old; i < nprocs; i++ {
pp := allp[i]
if pp == nil {
pp = new(p)
}
pp.init(i)
atomicstorep(unsafe.Pointer(&allp[i]), unsafe.Pointer(pp))
}Si el P que está usando la goroutine actual necesita ser destruido, se reemplaza con allp[0]. La función runtime.acquirep completa la asociación entre M y el nuevo P:
gp := getg()
if gp.m.p != 0 && gp.m.p.ptr().id < nprocs {
gp.m.p.ptr().status = _Prunning
gp.m.p.ptr().mcache.prepareForSweep()
} else {
if gp.m.p != 0 {
gp.m.p.ptr().m = 0
}
gp.m.p = 0
pp := allp[0]
pp.m = 0
pp.status = _Pidle
acquirep(pp)
}Luego destruye los P que ya no se necesitan. Durante la destrucción, se liberan todos los recursos de P, y todas las G en su cola local se colocan en la cola global. Después de la destrucción, se hace slice de allp:
// release resources from unused P's
for i := nprocs; i < old; i++ {
pp := allp[i]
pp.destroy()
// can't free P itself because it can be referenced by an M in syscall
}
// Trim allp.
if int32(len(allp)) != nprocs {
lock(&allpLock)
allp = allp[:nprocs]
unlock(&allpLock)
}Finalmente, los P inactivos se enlazan en una lista enlazada, y finalmente se devuelve el nodo cabeza de la lista:
var runnablePs *p
for i := nprocs - 1; i >= 0; i-- {
pp := allp[i]
if gp.m.p.ptr() == pp {
continue
}
pp.status = _Pidle
if runqempty(pp) {
pidleput(pp, now)
} else {
pp.m.set(mget())
pp.link.set(runnablePs)
runnablePs = pp
}
}
return runnablePsDespués, la inicialización del planificador está completa, y runtime.worldStarted reanuda la ejecución de todos los P:
MOVQ $runtime·mainPC(SB), AX // entry
PUSHQ AX
CALL runtime·newproc(SB)
POPQ AX
// start this M
CALL runtime·mstart(SB)Luego se crea una nueva goroutine a través de la función runtime.newproc para iniciar el programa Go, y luego se llama a runtime.mstart para iniciar oficialmente la operación del planificador. También está implementado en ensamblador, y llama internamente a la función runtime.mstart0 para la creación. Parte del código de esta función es el siguiente:
gp := getg()
osStack := gp.stack.lo == 0
if osStack {
size := gp.stack.hi
if size == 0 {
size = 16384 * sys.StackGuardMultiplier
}
gp.stack.hi = uintptr(noescape(unsafe.Pointer(&size)))
gp.stack.lo = gp.stack.hi - size + 1024
}
gp.stackguard0 = gp.stack.lo + stackGuard
gp.stackguard1 = gp.stackguard0
mstart1()En este momento, M solo tiene una goroutine g0, que usa el stack del sistema del hilo, no un espacio de stack asignado por separado. La función mstart0 primero inicializa los límites del stack de G, luego lo entrega a mstart1 para completar el resto del trabajo de inicialización:
gp := getg()
gp.sched.g = guintptr(unsafe.Pointer(gp))
gp.sched.pc = getcallerpc()
gp.sched.sp = getcallersp()
asminit()
minit()
if gp.m == &m0 {
mstartm0()
}
if fn := gp.m.mstartfn; fn != nil {
fn()
}
if gp.m != &m0 {
acquirep(gp.m.nextp.ptr())
gp.m.nextp = 0
}
schedule()Antes de comenzar, primero se registra el sitio de ejecución actual, porque después de que la inicialización sea exitosa, se entrará en el bucle de planificación y nunca se regresará. Las otras llamadas pueden reutilizar el sitio de ejecución para regresar desde mstart1 y lograr el propósito de salir del hilo. Después de completar el registro, las funciones runtime.asminit y runtime.minit son responsables de inicializar el stack del sistema, y luego la función runtime.mstartm0 establece el callback para manejar señales. Después de ejecutar la función de callback m.mstartfn, la función runtime.acquirep asocia M con el P creado anteriormente, y finalmente entra en el bucle de planificación.
La llamada runtime.schedule aquí es el primer bucle de planificación en todo el tiempo de ejecución de Go, lo que representa el inicio oficial del trabajo del planificador.
Hilos
En el planificador, G depende de P para ejecutar código de usuario, y P debe funcionar normalmente asociándose con un M. M se refiere a los hilos del sistema.
Creación
La creación de M es completada por la función runtime.newm. Acepta una función, P e id como parámetros. La función como parámetro no puede ser un closure:
func newm(fn func(), pp *p, id int64) {
acquirem()
mp := allocm(pp, fn, id)
mp.nextp.set(pp)
mp.sigmask = initSigmask
newm1(mp)
releasem(getg().m)
}Antes de comenzar, newm primero llama a la función runtime.allocm para crear la representación en tiempo de ejecución del hilo, es decir, M. Durante el proceso, se usa la función runtime.mcommoninit para inicializar los límites del stack de M:
func allocm(pp *p, fn func(), id int64) *m {
allocmLock.rlock()
// The caller owns pp, but we may borrow (i.e., acquirep) it. We must
// disable preemption to ensure it is not stolen, which would make the
// caller lose ownership.
acquirem()
gp := getg()
if gp.m.p == 0 {
acquirep(pp) // temporarily borrow p for mallocs in this function
}
mp := new(m)
mp.mstartfn = fn
mcommoninit(mp, id)
mp.g0.m = mp
releasem(gp.m)
allocmLock.runlock()
return mp
}Luego, runtime.newm1 llama a la función runtime.newosproc para completar la creación real del hilo del sistema:
func newm1(mp *m) {
execLock.rlock()
newosproc(mp)
execLock.runlock()
}La implementación de runtime.newosproc varía según el sistema operativo. Cómo se crea exactamente no es nuestra preocupación. Es responsabilidad del sistema operativo. Luego, runtime.mstart inicia el trabajo de M.
Salida
runtime.gogo(&mp.g0.sched)Al inicio se mencionó que al llamar a la función mstart1, el sitio de ejecución se guardó en el campo sched de g0. Pasar este campo a la función runtime.gogo (implementada en ensamblador) permite que el hilo salte al sitio de ejecución y continúe ejecutándose. Al guardar se usó getcallerpc(), por lo que al restaurar el sitio de ejecución se regresa a la función mstart0.
mstart1()
if mStackIsSystemAllocated() {
osStack = true
}
mexit(osStack)Después de restaurar el sitio de ejecución, según el orden de ejecución se entrará en la función mexit para salir del hilo:
mp := getg().m
unminit()
lock(&sched.lock)
for pprev := &allm; *pprev != nil; pprev = &(*pprev).alllink {
if *pprev == mp {
*pprev = mp.alllink
}
}
mp.freeWait.Store(freeMWait)
mp.freelink = sched.freem
sched.freem = mp
unlock(&sched.lock)
handoffp(releasep())
mdestroy(mp)
exitThread(&mp.freeWait)Hace principalmente las siguientes cosas:
- Llama a
runtime.unminitpara deshacer el trabajo deruntime.minit - Elimina este M de la variable global
allm - Hace que
freemdel planificador apunte al M actual runtime.releasepdesvincula P del M actual, yruntime.handoffphace que P se asocie con otro M para continuar trabajandoruntime.destroyes responsable de destruir los recursos de M- Finalmente, el sistema operativo sale del hilo
Hasta aquí, M ha salido exitosamente.
Pausa
Cuando se necesita pausar M debido a planificación del planificador, GC, llamadas al sistema u otras razones, se llama a la función runtime.stopm para pausar el hilo. A continuación se muestra el código simplificado:
func stopm() {
gp := getg()
lock(&sched.lock)
mput(gp.m)
unlock(&sched.lock)
mPark()
acquirep(gp.m.nextp.ptr())
gp.m.nextp = 0
}Primero coloca M en la lista global de M inactivos, luego mPark() bloquea el hilo actual en notesleep(&gp.m.park). Cuando se despierta, esta función retorna:
func mPark() {
gp := getg()
notesleep(&gp.m.park)
noteclear(&gp.m.park)
}El M despertado buscará un P para asociarse y continuar ejecutando tareas.
Goroutines
El ciclo de vida de una goroutine corresponde exactamente a sus varios estados. Comprender el ciclo de vida de las goroutines es muy útil para entender el planificador, después de todo, todo el planificador está diseñado alrededor de las goroutines. El ciclo de vida completo de una goroutine se muestra en la siguiente figura:
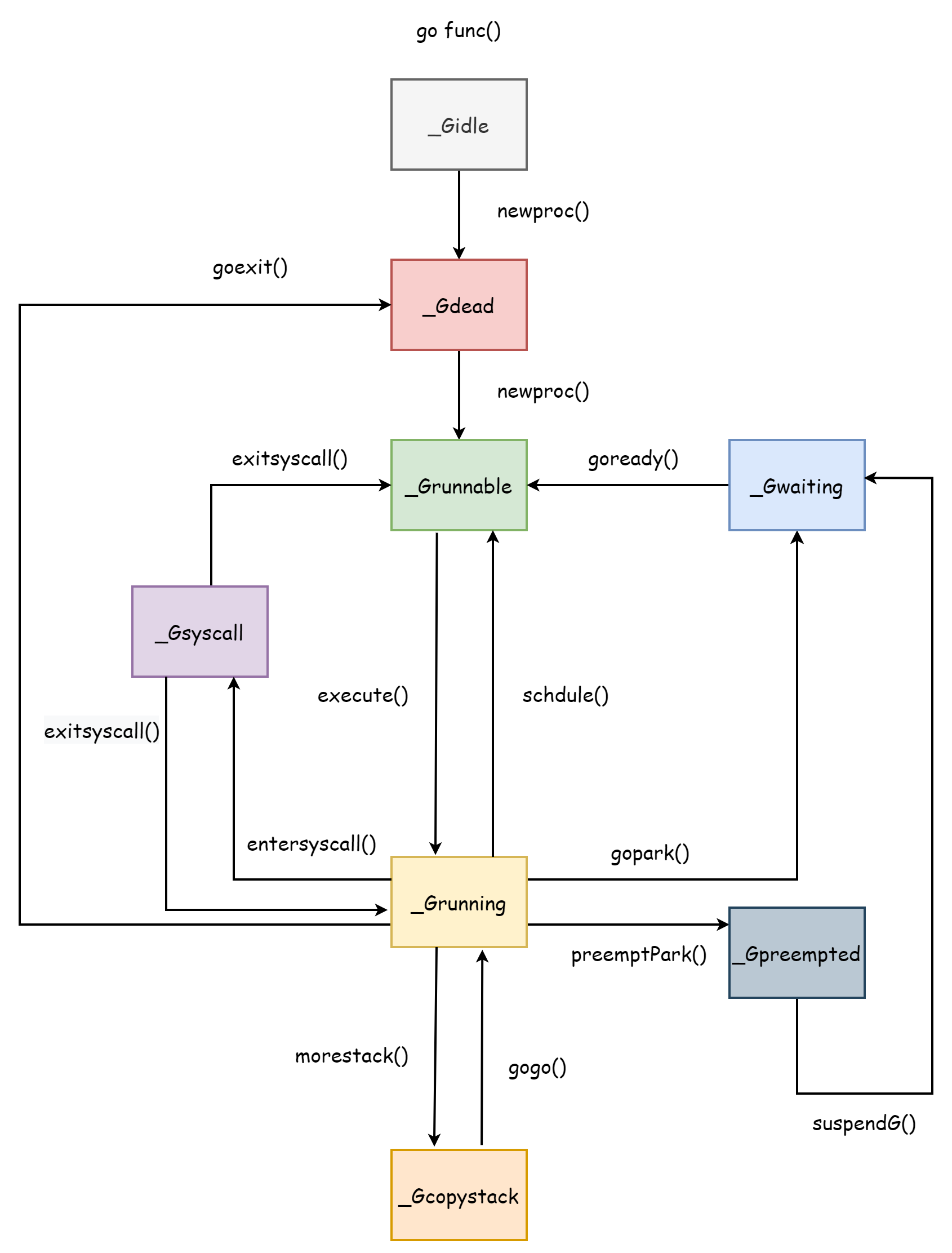
_Gcopystack es el estado que tiene una goroutine cuando su stack se expande, se explica en la sección Stack de Goroutine.
Creación
La creación de una goroutine, desde la perspectiva de la sintaxis, solo requiere una palabra clave go y una función:
go doSomething()Después de la compilación, se convierte en una llamada a la función runtime.newproc:
func newproc(fn *funcval) {
gp := getg()
pc := getcallerpc()
systemstack(func() {
newg := newproc1(fn, gp, pc)
pp := getg().m.p.ptr()
runqput(pp, newg, true)
if mainStarted {
wakep()
}
})
}runtime.newproc1 completa la creación real. Al crear, primero bloquea M, prohíbe la preemptación, y luego busca G inactivas en la lista local gfree de P para reutilizar. Si no se encuentra, runtime.malg crea una nueva G y le asigna 2KB de espacio de stack. En este momento, el estado de G es _Gdead:
mp := acquirem() // disable preemption because we hold M and P in local vars.
pp := mp.p.ptr()
newg := gfget(pp)
if newg == nil {
newg = malg(stackMin)
casgstatus(newg, _Gidle, _Gdead)
allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack.
}En Go 1.18 y versiones posteriores, la copia de parámetros ya no la completa la función newproc1. Antes de esto, se usaba runtime.memmove para copiar los parámetros de la función. Ahora solo es responsable de restablecer el espacio de stack de la goroutine, estableciendo runtime.goexit como la base del stack para manejar la salida de la goroutine. Luego establece el PC de la función de entrada newg.startpc = fn.fn, indicando que la ejecución comienza desde aquí. Después de completar la configuración, el estado de G es _Grunnable:
totalSize := uintptr(4*goarch.PtrSize + sys.MinFrameSize) // extra space in case of reads slightly beyond frame
totalSize = alignUp(totalSize, sys.StackAlign)
sp := newg.stack.hi - totalSize
spArg := sp
if usesLR {
// caller's LR
*(*uintptr)(unsafe.Pointer(sp)) = 0
prepGoExitFrame(sp)
spArg += sys.MinFrameSize
}
memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched))
newg.sched.sp = sp
newg.stktopsp = sp
newg.sched.pc = abi.FuncPCABI0(goexit) + sys.PCQuantum // +PCQuantum so that previous instruction is in same function
newg.sched.g = guintptr(unsafe.Pointer(newg))
gostartcallfn(&newg.sched, fn)
newg.parentGoid = callergp.goid
newg.gopc = callerpc
newg.ancestors = saveAncestors(callergp)
newg.startpc = fn.fn
casgstatus(newg, _Gdead, _Grunnable)Finalmente, establece el identificador único de G, luego libera M y retorna la goroutine G creada:
newg.goid = pp.goidcache
pp.goidcache++
releasem(mp)
return newgDespués de crear la goroutine, la función runtime.runqput intenta colocarla en la cola local de P. Si no cabe, se coloca en la cola global. Durante todo el proceso de creación de la goroutine, su estado cambia primero de _Gidle a _Gdead, y después de establecer la función de entrada, cambia de _Gdead a _Grunnable.
Salida
Al crear, Go ya ha establecido la función runtime.goexit como la base del stack de la goroutine. Cuando la goroutine termina de ejecutarse, finalmente entra en esta función. A través de la cadena de llamadas goexit->goexit1->goexit0, finalmente runtime.goexit0 es responsable del trabajo de salida de la goroutine:
func goexit0(gp *g) {
mp := getg().m
pp := mp.p.ptr()
...
casgstatus(gp, _Grunning, _Gdead)
...
gp.m = nil
locked := gp.lockedm != 0
gp.lockedm = 0
mp.lockedg = 0
gp.preemptStop = false
gp.paniconfault = false
gp._defer = nil // should be true already but just in case.
gp._panic = nil // non-nil for Goexit during panic. points at stack-allocated data.
gp.writebuf = nil
gp.waitreason = waitReasonZero
gp.param = nil
gp.labels = nil
gp.timer = nil
dropg()
...
gfput(pp, gp)
...
schedule()
}Esta función hace principalmente las siguientes cosas:
- Establece el estado a
_Gdead - Restablece los valores de los campos
dropg()corta la asociación entre M y Ggfput(pp, gp)coloca la G actual en la lista local de inactivas de Pschedule()realiza una nueva ronda de planificación, cediendo el derecho de ejecución de M a otras G
Después de salir, el estado de la goroutine cambia de _Grunning a _Gdead, y puede ser reutilizada en el futuro al crear nuevas goroutines.
Llamadas al Sistema
Cuando una goroutine G ejecuta código de usuario y realiza una llamada al sistema, hay dos métodos para activar una llamada al sistema:
- Llamadas al sistema de la biblioteca estándar
syscall - Llamadas cgo
Como las llamadas al sistema bloquearán el hilo de trabajo, se necesita preparación antes de esto. La función runtime.entersyscall completa este proceso, pero la primera es solo una llamada simple a la función runtime.reentersyscall. El trabajo real lo completa esta última. Primero bloquea el M actual. Durante la preparación, G no puede ser preemptada y no se permite la expansión del stack. Establece gp.stackguard0 = stackPreempt, indicando que después de completar la preparación, el derecho de ejecución de P será preemptado por otras G. Luego guarda el sitio de ejecución de la goroutine para facilitar la recuperación después de que la llamada al sistema retorne:
gp := getg()
// Disable preemption because during this function g is in Gsyscall status,
// but can have inconsistent g->sched, do not let GC observe it.
gp.m.locks++
// Entersyscall must not call any function that might split/grow the stack.
// (See details in comment above.)
// Catch calls that might, by replacing the stack guard with something that
// will trip any stack check and leaving a flag to tell newstack to die.
gp.stackguard0 = stackPreempt
gp.throwsplit = true
// Leave SP around for GC and traceback.
save(pc, sp)
gp.syscallsp = sp
gp.syscallpc = pcLuego, para evitar bloquear durante mucho tiempo y afectar la ejecución de otras G, M y P se desvinculan. Después de desvincularse, M y G se bloquearán debido a la ejecución de la llamada al sistema, y P, después de desvincularse, puede asociarse con otros M inactivos para permitir que otras G en la cola local de P continúen trabajando:
casgstatus(gp, _Grunning, _Gsyscall)
gp.m.syscalltick = gp.m.p.ptr().syscalltick
pp := gp.m.p.ptr()
pp.m = 0
gp.m.oldp.set(pp)
gp.m.p = 0
atomic.Store(&pp.status, _Psyscall)
gp.m.locks--Después de completar la preparación, se libera el bloqueo de M. Durante este período, el estado de G cambia de _Grunning a _Gsyscall, y el estado de P cambia a _Psyscall.
Cuando la llamada al sistema retorna, el hilo M ya no está bloqueado, y la G correspondiente también necesita ser programada nuevamente para ejecutar código de usuario. La función runtime.exitsyscall completa este trabajo de seguimiento. Primero bloquea el M actual y obtiene la referencia del P anterior:
gp := getg()
gp.waitsince = 0
oldp := gp.m.oldp.ptr()
gp.m.oldp = 0En este momento se divide en dos situaciones. La primera es si hay un P disponible directamente. La función runtime.exitsyscallfast determina si el P original está disponible, es decir, si el estado de P es _Psyscall. De lo contrario, buscará P inactivos:
func exitsyscallfast(oldp *p) bool {
gp := getg()
// Freezetheworld sets stopwait but does not retake P's.
if sched.stopwait == freezeStopWait {
return false
}
// Try to re-acquire the last P.
if oldp != nil && oldp.status == _Psyscall && atomic.Cas(&oldp.status, _Psyscall, _Pidle) {
// There's a cpu for us, so we can run.
wirep(oldp)
exitsyscallfast_reacquired()
return true
}
// Try to get any other idle P.
if sched.pidle != 0 {
var ok bool
systemstack(func() {
ok = exitsyscallfast_pidle()
})
if ok {
return true
}
}
return false
}Si se encuentra un P disponible, M se asociará con P, G cambiará del estado _Gsyscall al estado _Grunning, y luego a través de runtime.Gosched, G cederá activamente el derecho de ejecución, y P entrará en el bucle de planificación para buscar otras G disponibles:
oldp := gp.m.oldp.ptr()
gp.m.oldp = 0
if exitsyscallfast(oldp) {
// There's a cpu for us, so we can run.
gp.m.p.ptr().syscalltick++
// We need to cas the status and scan before resuming...
casgstatus(gp, _Gsyscall, _Grunning)
// Garbage collector isn't running (since we are),
// so okay to clear syscallsp.
gp.syscallsp = 0
gp.m.locks--
if gp.preempt {
// restore the preemption request in case we've cleared it in newstack
gp.stackguard0 = stackPreempt
} else {
// otherwise restore the real stackGuard, we've spoiled it in entersyscall/entersyscallblock
gp.stackguard0 = gp.stack.lo + stackGuard
}
gp.throwsplit = false
if sched.disable.user && !schedEnabled(gp) {
// Scheduling of this goroutine is disabled.
Gosched()
}
return
}Si no se encuentra, M se desvinculará de G, G cambiará del estado _Gsyscall al estado _Grunnable, y luego intentará nuevamente encontrar P inactivos. Si no se encuentra, se coloca G directamente en la cola global, y luego se entra en una nueva ronda de planificación. El M anterior entra en estado inactivo mediante runtime.stopm, esperando nuevas tareas en el futuro. Si se encuentra P, el M y G anteriores se asocian con el nuevo P, y luego continúan ejecutando código de usuario. El estado cambia de _Grunnable a _Grunning:
func exitsyscall0(gp *g) {
casgstatus(gp, _Gsyscall, _Grunnable)
dropg()
lock(&sched.lock)
var pp *p
if schedEnabled(gp) {
pp, _ = pidleget(0)
}
var locked bool
if pp == nil {
globrunqput(gp)
}
unlock(&sched.lock)
if pp != nil {
acquirep(pp)
execute(gp, false) // Never returns.
}
stopm()
schedule() // Never returns.
}Después de salir de la llamada al sistema, el estado de G tiene dos resultados posibles: uno es _Grunnable esperando ser programado, y el otro es _Grunning continuando la ejecución.
Suspensión
Cuando la goroutine actual se suspende por alguna razón, el estado cambia de _Grunnable a _Gwaiting. Hay muchas razones para la suspensión, puede ser debido a bloqueo de canales, select, locks o time.Sleep. Para más razones, ver Estructura G. Tomemos time.Sleep como ejemplo. En realidad, está vinculado a runtime.timesleep. El código de este último es el siguiente:
func timeSleep(ns int64) {
if ns <= 0 {
return
}
gp := getg()
t := gp.timer
if t == nil {
t = new(timer)
gp.timer = t
}
t.f = goroutineReady
t.arg = gp
t.nextwhen = nanotime() + ns
if t.nextwhen < 0 { // check for overflow.
t.nextwhen = maxWhen
}
gopark(resetForSleep, unsafe.Pointer(t), waitReasonSleep, traceBlockSleep, 1)
}Se puede ver que obtiene la goroutine actual a través de getg, y luego hace que la goroutine actual se suspenda a través de runtime.gopark. runtime.gopark actualiza la razón de bloqueo de G y M, y libera el bloqueo de M:
mp := acquirem()
gp := mp.curg
status := readgstatus(gp)
if status != _Grunning && status != _Gscanrunning {
throw("gopark: bad g status")
}
mp.waitlock = lock
mp.waitunlockf = unlockf
gp.waitreason = reason
mp.waitTraceBlockReason = traceReason
mp.waitTraceSkip = traceskip
releasem(mp)
// can't do anything that might move the G between Ms here.
mcall(park_m)Luego cambia al stack del sistema y usa runtime.park_m para cambiar el estado de G a _Gwaiting, luego corta la asociación entre M y G y entra en un nuevo bucle de planificación para ceder el derecho de ejecución a otras G. Después de suspenderse, G no ejecuta código de usuario ni está en la cola local, solo mantiene una referencia a M y P:
mp := getg().m
casgstatus(gp, _Grunning, _Gwaiting)
dropg()
schedule()En la función runtime.timesleep hay esta línea de código que especifica el valor de t.f:
t.f = goroutineReadyLa función runtime.goroutineReady se usa para despertar la goroutine suspendida. Llama a la función runtime.ready para despertar la goroutine:
status := readgstatus(gp)
// Mark runnable.
mp := acquirem()
casgstatus(gp, _Gwaiting, _Grunnable)
runqput(mp.p.ptr(), gp, next)
wakep()
releasem(mp)Después de despertar, cambia el estado de G a _Grunnable, y luego coloca G en la cola local de P, esperando ser programada en el futuro.
Stack de Goroutine
Las goroutines en Go son típicamente goroutines con stack. Cada goroutine tiene un espacio de stack independiente asignado en el heap, y crece o se reduce con los cambios en el uso. Durante la inicialización del planificador, la función runtime.stackinit es responsable de inicializar el caché global de espacio de stack stackpool y stackLarge:
func stackinit() {
if _StackCacheSize&_PageMask != 0 {
throw("cache size must be a multiple of page size")
}
for i := range stackpool {
stackpool[i].item.span.init()
lockInit(&stackpool[i].item.mu, lockRankStackpool)
}
for i := range stackLarge.free {
stackLarge.free[i].init()
lockInit(&stackLarge.lock, lockRankStackLarge)
}
}Además, cada P tiene su propio caché de espacio de stack independiente mcache:
type p struct {
...
mcache *mcache
...
}
type mcache struct {
_ sys.NotInHeap
nextSample uintptr
scanAlloc uintptr
tiny uintptr
tinyoffset uintptr
tinyAllocs uintptr
alloc [numSpanClasses]*mspan
stackcache [_NumStackOrders]stackfreelist
flushGen atomic.Uint32
}El caché de hilos mcache es independiente para cada hilo y no está asignado en la memoria del heap. No se requiere bloqueo al acceder. Estos tres cachés de stack se usarán en la asignación de espacio posterior.
Asignación
Al crear una goroutine, si no hay goroutines reutilizables, se le asignará un nuevo espacio de stack. Su tamaño predeterminado es 2KB:
newg := gfget(pp)
if newg == nil {
newg = malg(stackMin)
casgstatus(newg, _Gidle, _Gdead)
allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack.
}La función responsable de asignar el espacio de stack es runtime.stackalloc:
func stackalloc(n uint32) stackSe divide en dos situaciones según si el tamaño de la memoria de stack solicitada es menor que 32KB. 32KB es también el estándar en Go para determinar si un objeto es pequeño o grande. Si es menor que este valor, se obtendrá del caché stackpool. Cuando M está asociado con P y M no puede ser preemptado, se obtendrá del caché local de hilos:
if n < fixedStack<<_NumStackOrders && n < _StackCacheSize {
order := uint8(0)
n2 := n
for n2 > fixedStack {
order++
n2 >>= 1
}
var x gclinkptr
if stackNoCache != 0 || thisg.m.p == 0 || thisg.m.preemptoff != "" {
lock(&stackpool[order].item.mu)
x = stackpoolalloc(order)
unlock(&stackpool[order].item.mu)
} else {
c := thisg.m.p.ptr().mcache
x = c.stackcache[order].list
if x.ptr() == nil {
stackcacherefill(c, order)
x = c.stackcache[order].list
}
c.stackcache[order].list = x.ptr().next
c.stackcache[order].size -= uintptr(n)
}
v = unsafe.Pointer(x)
}Si es mayor que 32KB, se obtendrá del caché stackLarge. Si aún no es suficiente, se asignará memoria directamente en el heap:
else {
var s *mspan
npage := uintptr(n) >> _PageShift
log2npage := stacklog2(npage)
// Try to get a stack from the large stack cache.
lock(&stackLarge.lock)
if !stackLarge.free[log2npage].isEmpty() {
s = stackLarge.free[log2npage].first
stackLarge.free[log2npage].remove(s)
}
unlock(&stackLarge.lock)
lockWithRankMayAcquire(&mheap_.lock, lockRankMheap)
if s == nil {
// Allocate a new stack from the heap.
s = mheap_.allocManual(npage, spanAllocStack)
if s == nil {
throw("out of memory")
}
osStackAlloc(s)
s.elemsize = uintptr(n)
}
v = unsafe.Pointer(s.base())
}Finalmente, retorna la dirección baja y alta del espacio de stack:
return stack{uintptr(v), uintptr(v) + uintptr(n)}Expansión
El tamaño predeterminado del stack de goroutine es 2KB, lo suficientemente ligero, por lo que el costo de crear una goroutine es muy bajo, pero esto puede no ser suficiente. Cuando el espacio de stack no es suficiente, se necesita expansión. El compilador insertará la función runtime.morestack al inicio de las funciones para verificar si la goroutine actual necesita expansión de stack. Si es necesario, llama a runtime.newstack para completar la operación real de expansión:
TIP
Dado que morestack se inserta casi al inicio de todas las funciones, el momento de verificación de expansión de stack también es un punto de preemptación de goroutine.
thisg := getg()
gp := thisg.m.curg
// Allocate a bigger segment and move the stack.
oldsize := gp.stack.hi - gp.stack.lo
newsize := oldsize * 2
// The goroutine must be executing in order to call newstack,
// so it must be Grunning (or Gscanrunning).
casgstatus(gp, _Grunning, _Gcopystack)
// The concurrent GC will not scan the stack while we are doing the copy since
// the gp is in a Gcopystack status.
copystack(gp, newsize)
casgstatus(gp, _Gcopystack, _Grunning)
gogo(&gp.sched)Se puede ver que la capacidad calculada del espacio de stack es el doble del original. La función runtime.copystack completa el trabajo de copia del stack. Antes de copiar, el estado de G cambia de _Grunning a _Gcopystack:
func copystack(gp *g, newsize uintptr) {
old := gp.stack
used := old.hi - gp.sched.sp
// allocate new stack
new := stackalloc(uint32(newsize))
// Compute adjustment.
var adjinfo adjustinfo
adjinfo.old = old
adjinfo.delta = new.hi - old.hi
// Copy the stack (or the rest of it) to the new location
memmove(unsafe.Pointer(new.hi-ncopy), unsafe.Pointer(old.hi-ncopy), ncopy)
// Adjust remaining structures that have pointers into stacks.
// We have to do most of these before we traceback the new
// stack because gentraceback uses them.
adjustctxt(gp, &adjinfo)
adjustdefers(gp, &adjinfo)
adjustpanics(gp, &adjinfo)
if adjinfo.sghi != 0 {
adjinfo.sghi += adjinfo.delta
}
// Swap out old stack for new one
gp.stack = new
gp.stackguard0 = new.lo + stackGuard // NOTE: might clobber a preempt request
gp.sched.sp = new.hi - used
gp.stktopsp += adjinfo.delta
// Adjust pointers in the new stack.
var u unwinder
for u.init(gp, 0); u.valid(); u.next() {
adjustframe(&u.frame, &adjinfo)
}
stackfree(old)
}Esta función hace principalmente el siguiente trabajo:
- Asigna un nuevo espacio de stack
- Copia directamente la memoria del stack antiguo al nuevo espacio de stack a través de
runtime.memmove - Ajusta las estructuras que contienen punteros de stack, como defer, panic, etc.
- Actualiza los campos de espacio de stack de G
- Ajusta los punteros que apuntan a la memoria del stack antiguo a través de
runtime.adjustframe - Libera la memoria del stack antiguo
Después de completar, el estado de G cambia de _Gcopystack a _Grunning, y la función runtime.gogo permite que G continúe ejecutando código de usuario. Precisamente debido a la existencia de la expansión del stack de goroutine, la memoria en Go es inestable.
Contracción
Cuando el estado de G es _Grunnable, _Gsyscall o _Gwaiting, GC escaneará el espacio de memoria del stack de la goroutine:
func scanstack(gp *g, gcw *gcWork) int64 {
switch readgstatus(gp) &^ _Gscan {
case _Grunnable, _Gsyscall, _Gwaiting:
// ok
}
...
if isShrinkStackSafe(gp) {
// Shrink the stack if not much of it is being used.
shrinkstack(gp)
}
...
}El trabajo real de contracción de stack lo completa runtime.shrinkstack:
func shrinkstack(gp *g) {
if !isShrinkStackSafe(gp) {
throw("shrinkstack at bad time")
}
oldsize := gp.stack.hi - gp.stack.lo
newsize := oldsize / 2
if newsize < fixedStack {
return
}
avail := gp.stack.hi - gp.stack.lo
if used := gp.stack.hi - gp.sched.sp + stackNosplit; used >= avail/4 {
return
}
copystack(gp, newsize)
}Cuando el espacio de stack usado es menos de 1/4 del original, se reduce a la mitad del original a través de runtime.copystack. El resto del trabajo es similar al anterior.
Stack Segmentado
Desde el proceso de copystack, se puede ver que copia la memoria del stack antiguo a un espacio de stack más grande. Tanto el stack original como el nuevo tienen direcciones de memoria continuas. En las versiones antiguas de Go, la práctica de expansión de stack era diferente. En ese entonces, se pensaba que la copia de memoria consumía demasiado rendimiento, por lo que se adoptó el enfoque de stack segmentado. Si la memoria del espacio de stack no era suficiente, se solicitaba un nuevo espacio de stack. La memoria del espacio de stack original no se liberaba ni se copiaba, y se enlazaban entre sí a través de punteros, formando una lista enlazada de stacks. Este es el origen del stack segmentado, como se muestra en la siguiente figura:
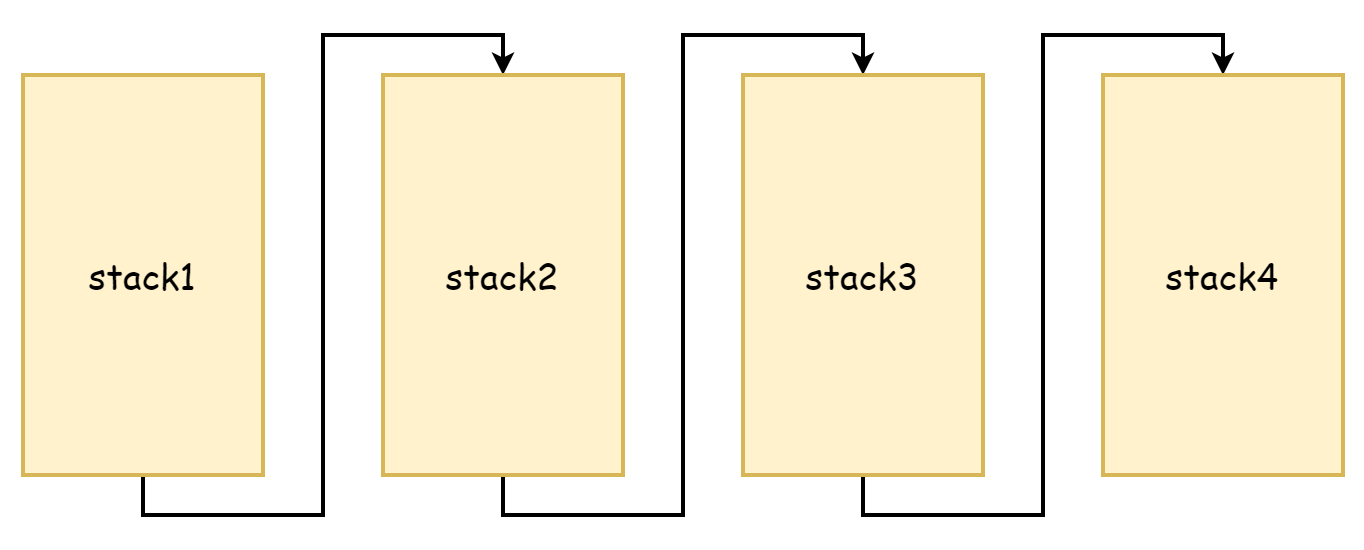
La ventaja de hacer esto es que no es necesario copiar el stack original, pero la desventaja también es muy obvia: se activan muy frecuentemente la expansión y contracción del stack. Cuando queda poca memoria libre en el espacio de stack, una nueva llamada a función activa la expansión del stack. Cuando estas funciones retornan y ya no se necesita el nuevo espacio de stack, se activa la contracción. Si la frecuencia de estas llamadas a función es muy alta, la expansión y contracción frecuentes causan un gran损耗 de rendimiento.
Por lo tanto, después de Go 1.4, se cambió a stack continuo. El stack continuo, debido a que asigna un espacio de stack de mayor capacidad, no alcanza la situación donde la memoria usada alcanza el valor crítico y las llamadas a función activan frecuentes expansiones y contracciones. Además, debido a que las direcciones de memoria son continuas, según el principio de localidad espacial del caché, el stack continuo también es más amigable para el caché de CPU.
Bucle de Planificación
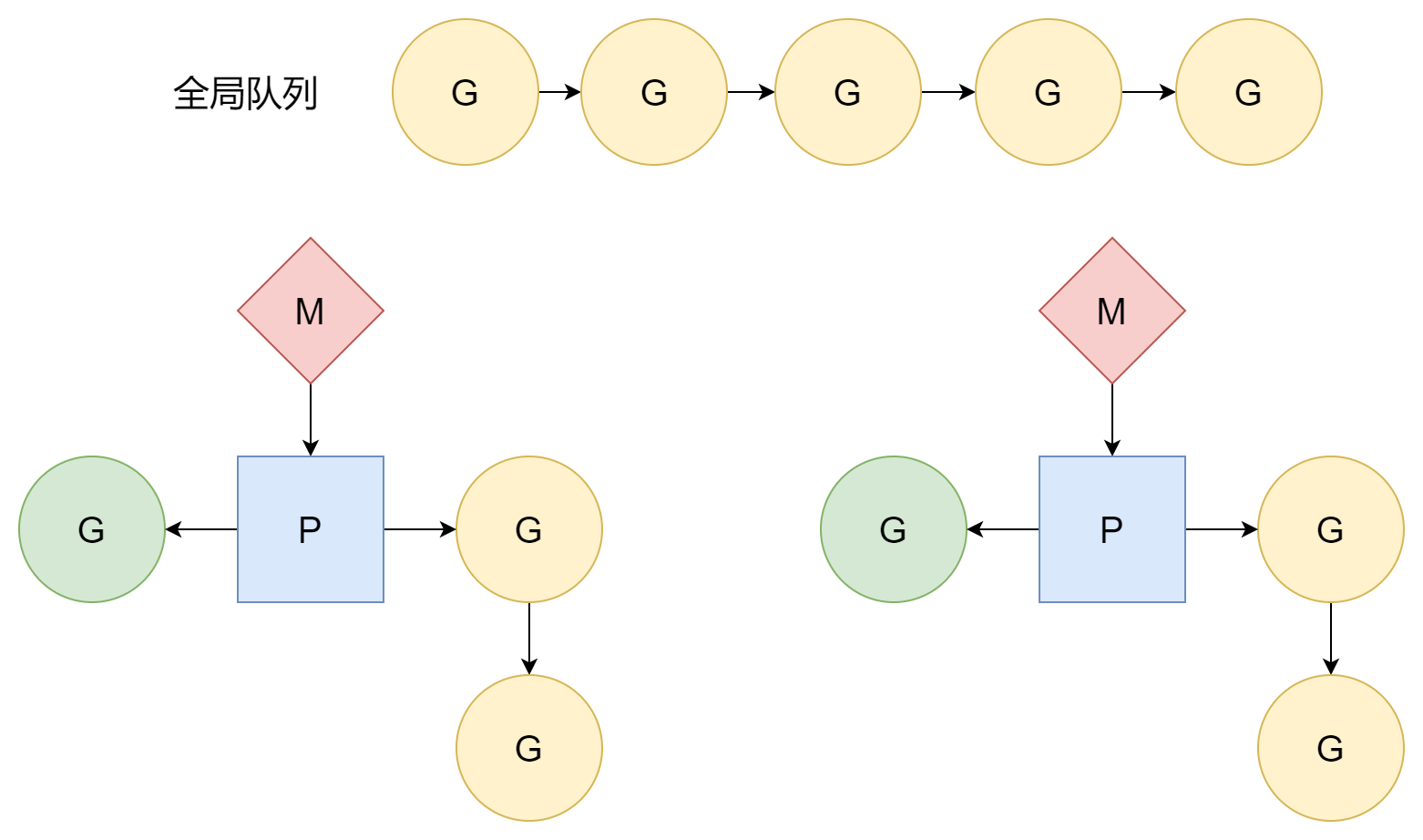
En la sección de inicialización del planificador se mencionó que en la función runtime.mstart1, después de que M y P se asocian exitosamente, se entra en el primer bucle de planificación runtime.schedule,正式开始计划 G 以执行用户代码。在计划循环中,这部分主要是 P 在发挥作用。M 对应着系统线程,G 对应着入口函数也就是用户代码,但 P 并不像 M 和 G 一样有着对应的实体,它只是一个抽象的概念,作为中间人处理着 M 和 G 之间的关系。
func schedule() {
mp := getg().m
top:
pp := mp.p.ptr()
pp.preempt = false
if mp.spinning {
resetspinning()
}
gp, inheritTime, tryWakeP := findRunnable() // blocks until work is available
execute(gp, inheritTime)
}El código anterior ha sido simplificado, eliminando muchas condiciones. Los puntos centrales son solo dos: runtime.findRunnable y runtime.execute. El primero es responsable de encontrar una G, y definitivamente retornará una G disponible. El segundo es responsable de hacer que G continúe ejecutando código de usuario.
Para la función findRunnable, la primera fuente de G es la cola local de P:
// local runq
if gp, inheritTime := runqget(pp); gp != nil {
return gp, inheritTime, false
}Si no hay G en la cola local, se intenta obtener de la cola global:
// global runq
if sched.runqsize != 0 {
lock(&sched.lock)
gp := globrunqget(pp, 0)
unlock(&sched.lock)
if gp != nil {
return gp, false, false
}
}Si no se encuentra en la cola local ni global, se intenta obtener del poller de red:
if netpollinited() && netpollWaiters.Load() > 0 && sched.lastpoll.Load() != 0 {
if list := netpoll(0); !list.empty() { // non-blocking
gp := list.pop()
injectglist(&list)
casgstatus(gp, _Gwaiting, _Grunnable)
if traceEnabled() {
traceGoUnpark(gp, 0)
}
return gp, false, false
}
}Si aún no se encuentra, finalmente se robará G de la cola local de otros P. Al crear goroutines, se mencionó que una gran fuente de G en la cola local de P son las goroutines hijas derivadas de la goroutine actual. Sin embargo, no todas las goroutines crearán goroutines hijas. Esto puede llevar a una situación donde algunas P están muy ocupadas y otras P están inactivas. Esto puede causar que algunas G esperen y no puedan ejecutarse, mientras que otras P están muy libres sin nada que hacer. Para aprovechar todas las P y hacer que funcionen con la máxima eficiencia, cuando P no encuentra G, irá a la cola local de otros P a "robar" G que pueden ejecutarse. De esta manera, cada P puede tener una cola de G más uniforme, y es menos probable que ocurra una situación donde P observan pasivamente a otras P:
gp, inheritTime, tnow, w, newWork := stealWork(now)
if gp != nil {
// Successfully stole.
return gp, inheritTime, false
}runtime.stealWork seleccionará aleatoriamente un P para robar. El trabajo real de robo lo completa la función runtime.runqgrab, que intentará robar la mitad de las G de la cola local de ese P:
for {
h := atomic.LoadAcq(&pp.runqhead) // load-acquire, synchronize with other consumers
t := atomic.LoadAcq(&pp.runqtail) // load-acquire, synchronize with the producer
n := t - h
n = n - n/2
if n > uint32(len(pp.runq)/2) { // read inconsistent h and t
continue
}
for i := uint32(0); i < n; i++ {
g := pp.runq[(h+i)%uint32(len(pp.runq))]
batch[(batchHead+i)%uint32(len(batch))] = g
}
if atomic.CasRel(&pp.runqhead, h, h+n) { // cas-release, commits consume
return n
}
}El trabajo de robo se realizará cuatro veces. Si después de cuatro veces no se puede robar G, se retorna. Si finalmente no se puede encontrar, el M actual se pausa con runtime.stopm, hasta que se despierta y continúa repitiendo los pasos anteriores. Cuando se encuentra y retorna una G, se entrega a runtime.execute para ejecutar G:
mp := getg().m
mp.curg = gp
gp.m = mp
casgstatus(gp, _Grunnable, _Grunning)
gp.waitsince = 0
gp.preempt = false
gp.stackguard0 = gp.stack.lo + stackGuard
gogo(&gp.sched)Primero se actualiza curg de M, luego se actualiza el estado de G a _Grunning, y finalmente se entrega a runtime.gogo para restaurar la ejecución de G.
En resumen, en el bucle de planificación, las fuentes de G según la prioridad son cuatro:
- Cola local de P
- Cola global
- Poller de red
- Robar de la cola local de otros P
runtime.execute no retorna después de ejecutar, y la G recién obtenida no se ejecutará para siempre. En algún momento se activará la planificación, se le privará del derecho de ejecución, y luego se entrará en una nueva ronda de planificación, cediendo el derecho de ejecución a otras G.
Estrategias de Planificación
Diferentes G pueden tener diferentes duraciones de ejecución de código de usuario. Algunas G pueden tomar mucho tiempo, y otras G pueden tomar poco tiempo. Las G que toman mucho tiempo pueden causar que otras G no puedan ejecutarse. Por lo tanto, la forma correcta es alternar la ejecución de G. En los sistemas operativos, esta forma de trabajo se denomina concurrencia.
Planificación Cooperativa
La idea básica de la planificación cooperativa es permitir que G ceda activamente el derecho de ejecución a otras G. Hay dos métodos principales.
El primer método es ceder activamente en el código de usuario. Go proporciona la función runtime.Gosched(), y los usuarios pueden decidir cuándo ceder el derecho de ejecución. Sin embargo, en muchas ocasiones, los detalles internos del trabajo del planificador son una caja negra para los usuarios, y es difícil determinar cuándo ceder activamente el derecho de ejecución. Esto requiere más de los usuarios, y el planificador de Go busca ocultar la mayoría de los detalles a los usuarios y追求 un uso más simple. En este caso, hacer que los usuarios también participen en el trabajo de planificación no es algo bueno.
El segundo método es la marca de preemptación. Aunque su nombre tiene la palabra "preemptación", en esencia sigue siendo una estrategia de planificación cooperativa. La idea es insertar código de detección de preemptación runtime.morestack() al inicio de las funciones. El proceso de inserción se completa durante la compilación. Se mencionó anteriormente que originalmente era una función para detectar la expansión del stack, porque su punto de detección es cada llamada a función, lo cual también es un buen momento para realizar la detección de preemptación. La parte superior de la función runtime.newstack está realizando la detección de preemptación, y la parte inferior está realizando la detección de expansión del stack. Para evitar interferencias, se omitió esta parte anteriormente. Ahora veamos qué hace esta parte. Primero se juzga la preemptación según gp.stackguard0. Si no se necesita, se continúa ejecutando el código de usuario:
stackguard0 := atomic.Loaduintptr(&gp.stackguard0)
preempt := stackguard0 == stackPreempt
if preempt {
if !canPreemptM(thisg.m) {
gp.stackguard0 = gp.stack.lo + stackGuard
gogo(&gp.sched) // never return
}
}Cuando g.stackguard0 == stackPreempt, la función runtime.canPreemptM() juzga si las condiciones de la goroutine necesitan ser preemptadas. El código es el siguiente:
func canPreemptM(mp *m) bool {
return mp.locks == 0 && mp.mallocing == 0 && mp.preemptoff == "" && mp.p.ptr().status == _Prunning
}Se puede ver que para ser preemptado se deben cumplir cuatro condiciones:
- M no está bloqueado
- No se está asignando memoria
- No se ha deshabilitado la preemptación
- P está en estado
_Prunning
En las siguientes dos situaciones, g.stackguard0 se establece en stackPreempt:
- Cuando se necesita recolección de basura
- Cuando ocurre una llamada al sistema
if preempt {
if gp.preemptShrink {
gp.preemptShrink = false
shrinkstack(gp)
}
// Act like goroutine called runtime.Gosched.
gopreempt_m(gp) // never return
}Finalmente se llega a runtime.gopreempt_m() para ceder activamente el derecho de ejecución de la goroutine actual. Primero corta la conexión entre M y G, el estado cambia a _Grunnable, luego se coloca G en la cola global, y finalmente se entra en el bucle de planificación para ceder el derecho de ejecución a otras G:
casgstatus(gp, _Grunning, _Grunnable)
dropg()
lock(&sched.lock)
globrunqput(gp)
unlock(&sched.lock)
schedule()De esta manera, todas las goroutines pueden entrar en esta función para la detección de preemptación al realizar llamadas a función. Esta estrategia depende del momento de la llamada a función para activar la preemptación y ceder activamente el derecho de ejecución. Antes de 1.14, Go siempre usó esta estrategia de planificación, pero esto tiene un problema: si no hay llamadas a función, no se puede detectar. Por ejemplo, el siguiente código clásico, que debería aparecer en muchos tutoriales:
func main() {
// Limitar la cantidad de P a 1
runtime.GOMAXPROCS(1)
// Goroutine 1
go func() {
for {
// Esta goroutine gira constantemente
}
}()
// Entrar en llamada al sistema, la goroutine principal cede el derecho a otras goroutines
time.Sleep(time.Millisecond)
println("exit")
}El código crea una goroutine 1 que gira constantemente, y luego la goroutine principal cede activamente el derecho debido a una llamada al sistema. En este momento, la goroutine 1 está siendo planificada, pero como no llama a funciones en absoluto, no se puede realizar la detección de preemptación. Como solo hay un P, no hay otros P inactivos, lo que puede causar que la goroutine principal nunca pueda ser planificada, y exit nunca se imprimirá. Sin embargo, este problema solo ocurre antes de Go 1.14.
Planificación por Preemptación
Los oficiales agregaron la estrategia de planificación por preemptación basada en señales en Go 1.14. Esta es una estrategia de preemptación asíncrona, que realiza la preemptación de hilos mediante el envío de señales a través de hilos asíncronos. La planificación por preemptación basada en señales tiene actualmente dos entradas: el monitor del sistema y GC.
En el bucle del monitor del sistema, se recorre cada P. Si el tiempo de ejecución de G planificado por P excede los 10ms, se fuerza la activación de la preemptación. Este trabajo lo completa la función runtime.retake. A continuación se muestra el código simplificado:
func retake(now int64) uint32 {
n := 0
lock(&allpLock)
for i := 0; i < len(allp); i++ {
pp := allp[i]
if pp == nil {
continue
}
pd := &pp.sysmontick
s := pp.status
sysretake := false
if s == _Prunning || s == _Psyscall {
// Preempt G if it's running for too long.
t := int64(pp.schedtick)
if int64(pd.schedtick) != t {
pd.schedtick = uint32(t)
pd.schedwhen = now
} else if pd.schedwhen+forcePreemptNS <= now {
preemptone(pp)
sysretake = true
}
}
}
unlock(&allpLock)
return uint32(n)
}Cuando se necesita realizar la recolección de basura, si el estado de G es _Grunning, es decir, aún se está ejecutando, también se activará la preemptación:
func suspendG(gp *g) suspendGState {
for i := 0; ; i++ {
switch s := readgstatus(gp); s {
case _Grunning:
gp.preemptStop = true
gp.preempt = true
gp.stackguard0 = stackPreempt
casfrom_Gscanstatus(gp, _Gscanrunning, _Grunning)
if preemptMSupported && debug.asyncpreemptoff == 0 && needAsync {
now := nanotime()
if now >= nextPreemptM {
nextPreemptM = now + yieldDelay/2
preemptM(asyncM)
}
}
......
......
func preemptM(mp *m) {
if mp.signalPending.CompareAndSwap(0, 1) {
if GOOS == "darwin" || GOOS == "ios" {
pendingPreemptSignals.Add(1)
}
signalM(mp, sigPreempt)
}
}Las dos entradas de preemptación finalmente entrarán en la función runtime.preemptM, que es responsable de enviar la señal de preemptación. Cuando la señal se envía exitosamente, el callback del manejador de señales registrado a través de runtime.initsig en runtime.mstart, es decir, runtime.sighandler, será útil. Si se detecta que se envía una señal de preemptación, se comenzará la preemptación:
func sighandler(sig uint32, info *siginfo, ctxt unsafe.Pointer, gp *g) {
...
if sig == sigPreempt && debug.asyncpreemptoff == 0 && !delayedSignal {
// Might be a preemption signal.
doSigPreempt(gp, c)
}
...
}doSigPreempt modificará el contexto de la goroutine objetivo, inyectando la llamada a runtime.asyncPreempt:
func doSigPreempt(gp *g, ctxt *sigctxt) {
// Check if this G wants to be preempted and is safe to
// preempt.
if wantAsyncPreempt(gp) {
if ok, newpc := isAsyncSafePoint(gp, ctxt.sigpc(), ctxt.sigsp(), ctxt.siglr()); ok {
// Adjust the PC and inject a call to asyncPreempt.
ctxt.pushCall(abi.FuncPCABI0(asyncPreempt), newpc)
}
}
...De esta manera, cuando se vuelve a cambiar al código de usuario, la goroutine objetivo llegará a la función runtime.asyncPreempt, que involucra la llamada a runtime.asyncPreempt2:
TEXT ·asyncPreempt(SB),NOSPLIT|NOFRAME,$0-0
PUSHQ BP
MOVQ SP, BP
// Save flags before clobbering them
PUSHFQ
// obj doesn't understand ADD/SUB on SP, but does understand ADJSP
ADJSP $368
// But vet doesn't know ADJSP, so suppress vet stack checking
...
CALL ·asyncPreempt2(SB)
...
RETHará que la goroutine actual detenga el trabajo y realice una nueva ronda de planificación para ceder el derecho de ejecución a otras goroutines:
func asyncPreempt2() {
gp := getg()
gp.asyncSafePoint = true
if gp.preemptStop {
mcall(preemptPark)
} else {
mcall(gopreempt_m)
}
gp.asyncSafePoint = false
}Este proceso ocurre en la función runtime.asyncPreempt, implementada en ensamblador (ubicada en runtime/preempt_*.s), y restaurará el contexto de la goroutine modificado anteriormente después de completar la planificación, para permitir que la goroutine se recupere normalmente en el futuro. Después de adoptar la estrategia de preemptación asíncrona, el ejemplo anterior ya no bloqueará permanentemente la goroutine principal. Cuando la goroutine que gira ha estado ejecutándose durante cierto tiempo, se forzará la ejecución del bucle de planificación, cediendo así el derecho de ejecución a la goroutine principal, permitiendo finalmente que el programa termine normalmente.
Resumen
En resumen, los momentos que activan la planificación son los siguientes:
- Llamadas a función
- Llamadas al sistema
- Monitor del sistema
- Recolección de basura, que también preempta goroutines que se ejecutan durante mucho tiempo
- Goroutines que se suspenden debido a canales, locks u otras razones
Las estrategias de planificación son principalmente dos categorías: cooperativa y por preemptación. La cooperativa cede activamente el derecho de ejecución, y la por preemptación asíncrona preempta el derecho de ejecución. Ambas coexisten para formar el planificador actual.