gmp
Одной из главных особенностей языка Go является его нативная поддержка конкурентности. Всего с одним ключевым словом можно запустить корутину, как показано в примере ниже.
import (
"fmt"
"sync"
)
func main() {
var wg sync.WaitGroup
wg.Add(2)
go func() {
defer wg.Done()
fmt.Println("hello world!")
}()
go func() {
defer wg.Done()
fmt.Println("hello world too!")
}()
wg.Wait()
}Корутины в языке Go настолько просты в использовании, что разработчикам практически не нужно выполнять дополнительную работу, что является одной из причин его популярности. Однако за этой простотой скрывается нетривиальный конкурентный планировщик, поддерживающий всё. Его название, я уверен, многие из вас в той или иной степени слышали. Поскольку его основными участниками являются G (корутина), M (системный поток) и P (процессор), он также известен как планировщик GMP. Дизайн планировщика GMP влияет на весь дизайн runtime Go, включая GC и сетевой опросник. Можно сказать, что это самая ядровая часть всего языка. Иметь некоторое представление о нём может быть полезно в будущей работе.
История
Модель конкурентного планирования языка Go не является полностью оригинальной. Она впитала уроки и опыт предшественников, эволюционируя и совершенствуясь до текущего состояния. Языки, которые она использовала для вдохновения, включают:
- Occam - 1983
- Erlang - 1986
- Newsqueak - 1988
- Concurrent ML - 1993
- Alef - 1995
- Limbo - 1996
Наибольшее влияние оказала статья Хоара 1978 года о CSP (Communicating Sequential Processes). Фундаментальная идея статьи заключается в том, что процессы обмениваются данными через коммуникацию. Все упомянутые выше языки программирования были под влиянием идей CSP. Erlang — это типичный язык ориентированный на сообщения, и известная открытая система очередей сообщений RabbitMQ написана на Erlang. Сегодня, с развитием компьютеров и интернета, поддержка конкурентности почти стала стандартной функцией современных языков. Язык Go, сочетающий идеи CSP, родился соответственно.
Модель планирования
Сначала кратко представим три компонента GMP:
- G, Goroutine: Относится к корутинам в языке Go
- M, Machine: Относится к системным потокам или рабочим потокам, планируемым операционной системой
- P, Processor: Не относится к процессорам CPU, а является абстрактным понятием от Go, относящимся к процессорам, работающим на системных потоках, используемым для планирования корутин на каждом системном потоке.
Корутины — это более лёгкая форма потоков, с меньшим масштабом и требующая меньше ресурсов. Создание, уничтожение и время планирования — всё это обрабатывается runtime Go, а не операционной системой, поэтому их стоимость управления намного ниже, чем у потоков. Однако корутины зависят от потоков. Кванты времени выполнения корутин поступают от потоков, а кванты времени потоков поступают от операционной системы. Переключение между разными потоками имеет определённую стоимость. Как хорошо использовать кванты времени потоков для корутин — это ключ к дизайну.
1:N
Лучший способ решить проблему — игнорировать её. Поскольку переключение потоков имеет стоимость, просто не переключайте. Выделите все корутины одному ядру потока, так что будет задействовано только переключение корутин.
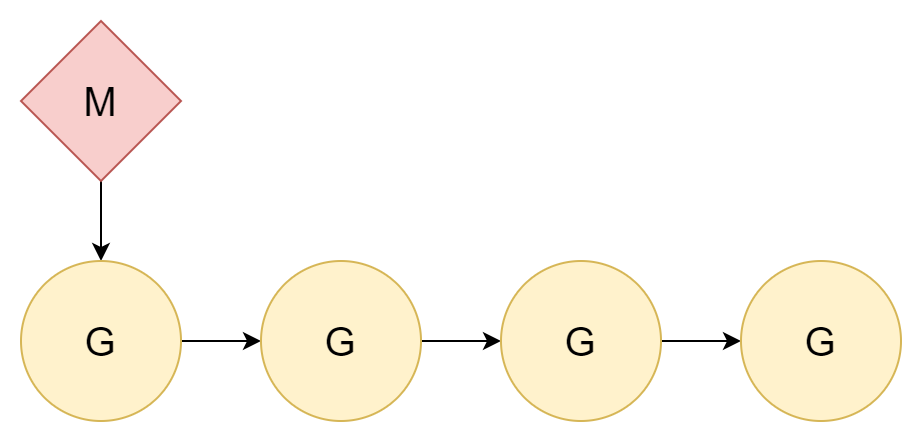
Отношение между потоками и корутинами — 1:N. Этот подход имеет очень очевидный недостаток: сегодняшние компьютеры почти все многоядерные CPU, и такое выделение не может полностью использовать производительность многоядерных CPU.
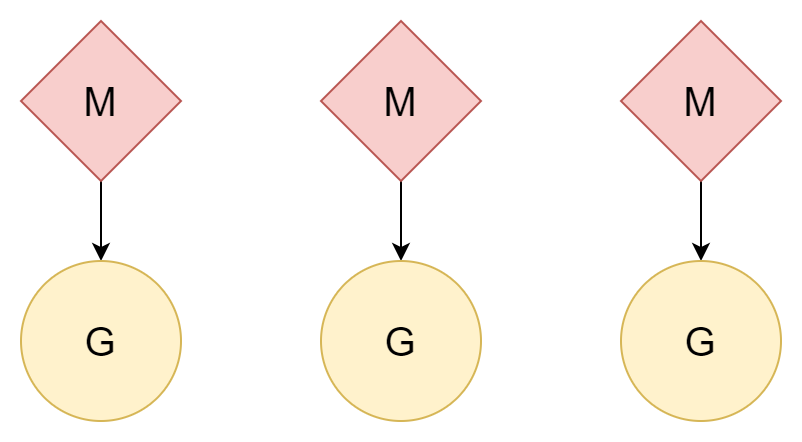
N:N
Другой подход: один поток соответствует одной корутине, и одна корутина может наслаждаться всеми квантами времени этого потока. Несколько потоков также могут использовать производительность многоядерных CPU. Однако стоимость создания и переключения потоков относительно высока. Если это отношение один к одному, это не хорошо использует лёгкость корутин.
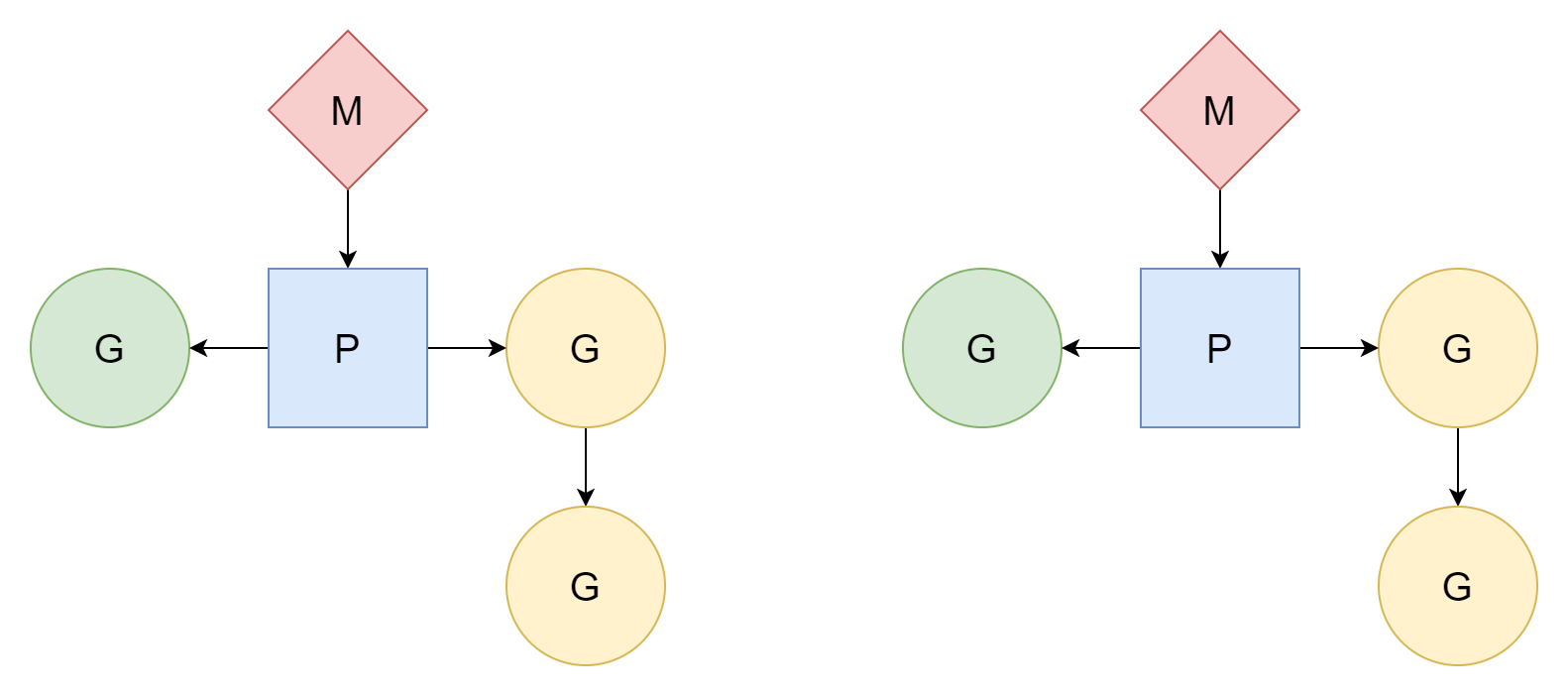
M:N
M потоков соответствуют N корутинам, где M меньше N. Несколько потоков соответствуют нескольким корутинам, с каждым потоком, соответствующим нескольким корутинам. Процессор P отвечает за планирование того, как корутины G используют кванты времени потоков. Этот метод относительно лучше и является моделью планирования, которую Go использовал до сегодняшнего дня.
M может выполнять задачи только после ассоциации с процессором P. Go создаёт GOMAXPROCS процессоров, поэтому фактическое количество потоков, доступных для выполнения задач, — GOMAXPROCS. Его значение по умолчанию — количество логических ядер CPU на текущей машине, но мы также можем вручную установить его значение.
- Изменить через код
runtime.GOMAXPROCS(N), и это может быть динамически настроено во время выполнения. Вызов этого вызывает немедленный STW. - Установить переменную окружения
export GOMAXPROCS=N, статично.
В фактических ситуациях количество M больше количества P, потому что во время выполнения им нужно обрабатывать другие задачи, такие как некоторые системные вызовы. Максимальное значение — 10000.
GMP, эти три участника, и сам планировщик имеют свои соответствующие представления типов во время выполнения. Они все находятся в файле runtime/runtime2.go. Ниже приведено краткое введение в их структуры для облегчения понимания далее.
G
Представление G во время выполнения — структура runtime.g, которая является самым основным блоком планирования в модели планирования. Её структура следующая (многие поля опущены для облегчения понимания).
type g struct {
stack stack // смещение известно runtime/cgo
_panic *_panic // внутренний panic - смещение известно liblink
_defer *_defer // внутренний defer
m *m // текущий m; смещение известно arm liblink
sched gobuf
goid uint64
waitsince int64 // приблизительное время, когда g стал заблокированным
waitreason waitReason // если status==Gwaiting
atomicstatus atomic.Uint32
preempt bool // сигнал вытеснения, дублирует stackguard0 = stackpreempt
startpc uintptr // pc функции goroutine
parentGoid uint64 // goid goroutine, которая создала эту goroutine
waiting *sudog // структуры sudog, которые эта g ожидает (которые имеют действительный указатель elem); в порядке блокировки
}Первое поле — это начальный и конечный адреса памяти стека, принадлежащего этой корутине:
type stack struct {
lo uintptr
hi uintptr
}_panic и _defer — это указатели, указывающие на стек panic и стек defer соответственно:
_panic *_panic // внутренний panic - смещение известно liblink
_defer *_defer // внутренний deferm — это корутина, в настоящее время выполняющаяся на этом g:
m *m // текущий m; смещение известно arm liblinkpreempt указывает, нуждается ли текущая корутина в вытеснении, эквивалентно g.stackguard0 = stackpreempt:
preempt bool // сигнал вытеснения, дублирует stackguard0 = stackpreemptatomicstatus используется для хранения значения статуса корутины G, со следующими возможными значениями:
| Имя | Описание |
|---|---|
_Gidle | Только что выделена и ещё не инициализирована |
_Grunnable | Указывает, что текущая корутина может выполняться, находится в очереди ожидания |
_Grunning | Указывает, что текущая корутина выполняет пользовательский код |
_Gsyscall | Назначен M для выполнения системных вызовов |
_Gwaiting | Корутина заблокирована, причина блокировки см. ниже |
_Gdead | Указывает, что текущая корутина не используется, может только что выйти или только что инициализирована |
_Gcopystack | Указывает, что стек корутины перемещается, в этот период не выполняется пользовательский код, и она не в очереди ожидания |
_Gpreempted | Заблокирована сама входит в вытеснение, ожидает пробуждения вытеснителем |
_Gscan | GC сканирует пространство стека корутины, может сосуществовать с другими состояниями |
sched используется для хранения информации о контексте корутины для восстановления состояния выполнения корутины. Вы можете видеть, что он хранит указатели sp, pc, ret.
type gobuf struct {
sp uintptr
pc uintptr
g guintptr
ctxt unsafe.Pointer
ret uintptr
lr uintptr
bp uintptr // для архитектур с framepointer
}waiting указывает на корутину, которую ожидает текущая корутина, waitsince записывает время, когда корутина была заблокирована, и waitreason указывает причину блокировки корутины, с возможными значениями следующим образом.
var waitReasonStrings = [...]string{
waitReasonZero: "",
waitReasonGCAssistMarking: "GC assist marking",
waitReasonIOWait: "IO wait",
waitReasonChanReceiveNilChan: "chan receive (nil chan)",
waitReasonChanSendNilChan: "chan send (nil chan)",
waitReasonDumpingHeap: "dumping heap",
waitReasonGarbageCollection: "garbage collection",
waitReasonGarbageCollectionScan: "garbage collection scan",
waitReasonPanicWait: "panicwait",
waitReasonSelect: "select",
waitReasonSelectNoCases: "select (no cases)",
waitReasonGCAssistWait: "GC assist wait",
waitReasonGCSweepWait: "GC sweep wait",
waitReasonGCScavengeWait: "GC scavenge wait",
waitReasonChanReceive: "chan receive",
waitReasonChanSend: "chan send",
waitReasonFinalizerWait: "finalizer wait",
waitReasonForceGCIdle: "force gc (idle)",
waitReasonSemacquire: "semacquire",
waitReasonSleep: "sleep",
waitReasonSyncCondWait: "sync.Cond.Wait",
waitReasonSyncMutexLock: "sync.Mutex.Lock",
waitReasonSyncRWMutexRLock: "sync.RWMutex.RLock",
waitReasonSyncRWMutexLock: "sync.RWMutex.Lock",
waitReasonTraceReaderBlocked: "trace reader (blocked)",
waitReasonWaitForGCCycle: "wait for GC cycle",
waitReasonGCWorkerIdle: "GC worker (idle)",
waitReasonGCWorkerActive: "GC worker (active)",
waitReasonPreempted: "preempted",
waitReasonDebugCall: "debug call",
waitReasonGCMarkTermination: "GC mark termination",
waitReasonStoppingTheWorld: "stopping the world",
}goid и parentGoid представляют уникальные идентификаторы текущей корутины и родительской корутины, а startpc представляет адрес входной функции текущей корутины.
M
M представлен во время выполнения как структура runtime.m, которая является абстракцией рабочих потоков:
type m struct {
id int64
g0 *g // goroutine с стеком планирования
curg *g // текущая выполняющаяся goroutine
gsignal *g // g обработки сигналов
goSigStack gsignalStack // выделенный Go стек обработки сигналов
p puintptr // прикреплённый p для выполнения кода go (nil если не выполняет код go)
nextp puintptr
oldp puintptr // p, который был прикреплён перед выполнением системного вызова
mallocing int32
throwing throwType
preemptoff string // если != "", держать curg выполняющимся на этом m
locks int32
dying int32
spinning bool // m без работы и активно ищет работу
tls [tlsSlots]uintptr
...
}Аналогично, M имеет много внутренних полей. Здесь представлены только некоторые поля для облегчения понимания.
id: Уникальный идентификатор Mg0: Корутина со стеком планированияcurg: Пользовательская корутина, выполняющаяся на рабочем потокеgsignal: Корутина, ответственная за обработку сигналов потокаgoSigStack: Пространство стека, выделенное Go для обработки сигналовp: Адрес процессора P,oldpуказывает на P перед выполнением системного вызова,nextpуказывает на вновь выделенный Pmallocing: Указывает, выделяется ли в настоящее время новое пространство памятиthrowing: Указывает тип ошибки, когда происходит Mpreemptoff: Идентификатор вытеснения, когда это пустая строка, указывает, что текущая выполняющаяся корутина может быть вытесненаlocks: Указывает текущее количество "блокировок" M, вытеснение запрещено, когда не 0dying: Указывает, что M столкнулся с невосстановимымpanic, имеет[0,3]четыре возможных значения, от низкого к высокому указывая на серьёзность.spinning: Указывает, что M находится в состоянии простоя и随时 доступен.tls: Локальное хранилище потока
P
P представлен во время выполнения как runtime.p, отвечает за работу планирования между M и G. Его структура следующая:
type p struct {
id int32
status uint32 // одно из pidle/prunning/...
schedtick uint32 // увеличивается при каждом вызове планировщика
syscalltick uint32 // увеличивается при каждом системном вызове
sysmontick sysmontick // последний тик, наблюдаемый sysmon
m muintptr // обратная ссылка на связанный m (nil если простаивает)
// Очередь выполняемых goroutine. Доступ без блокировки.
runqhead uint32
runqtail uint32
runq [256]guintptr
runnext guintptr
// Доступные G's (status == Gdead)
gFree struct {
gList
n int32
}
// preempt установлен, чтобы указать, что этот P должен войти в
// планировщик как можно скорее (независимо от того, какая G выполняется на нём).
preempt bool
...
}status указывает состояние P, со следующими возможными значениями:
| Значение | Описание |
|---|---|
_Pidle | P находится в состоянии простоя, может быть назначен M планировщиком, или может просто переходить между другими состояниями |
_Prunning | P связан с M и выполняет пользовательский код |
_Psyscall | Указывает, что M, связанный с P, выполняет системный вызов, в этот период P может быть вытеснен другим M |
_Pgcstop | Указывает, что P остановлен из-за GC |
_Pdead | Большинство ресурсов P удалены, больше не будет использоваться |
Следующие поля записывают локальную очередь runq P. Вы можете видеть, что максимальный размер локальной очереди — 256. За пределами этого числа G будет помещён в глобальную очередь.
runqhead uint32
runqtail uint32
runq [256]guintptrrunnext указывает на следующую доступную G:
runnext guintptrДругие поля объясняются следующим образом:
id: Уникальный идентификатор Pschedtick: Увеличивается с каждым планированием корутины, видно в функцииruntime.execute.syscalltick: Увеличивается с каждым системным вызовомsysmontick: Записывает информацию, последнюю наблюдаемую системным мониторомm: M, связанный с PgFree: Список простаивающих Gpreempt: Указывает, что P должен снова войти в планирование
Информация о глобальной очереди хранится в структуре runtime.schedt, которая является представлением планировщика во время выполнения, следующим образом.
type schedt struct {
...
midle muintptr // простаивающие m, ожидающие работы
ngsys atomic.Int32 // количество системных goroutine
pidle puintptr // простаивающие p
// Глобальная выполняемая очередь.
runq gQueue
runqsize int32
...
}Инициализация
Инициализация планировщика находится в фазе bootstrap программ Go. Функция, ответственная за bootstrap программы Go, — runtime.rt0_go, реализована на ассемблере и находится в файле runtime/asm_*.s. Часть кода следующая:
TEXT runtime·rt0_go(SB),NOSPLIT|NOFRAME|TOPFRAME,$0
...
...
CALL runtime·check(SB)
MOVL 24(SP), AX // copy argc
MOVL AX, 0(SP)
MOVQ 32(SP), AX // copy argv
MOVQ AX, 8(SP)
CALL runtime·args(SB)
CALL runtime·osinit(SB)
CALL runtime·schedinit(SB)
// создать новую goroutine для запуска программы
MOVQ $runtime·mainPC(SB), AX // entry
PUSHQ AX
CALL runtime·newproc(SB)
POPQ AX
// запустить этот M
CALL runtime·mstart(SB)
CALL runtime·abort(SB) // mstart никогда не должен возвращаться
RETВы можете видеть вызовы runtime·osinit и runtime·schedinit из следующих двух строк.
CALL runtime·osinit(SB)
CALL runtime·schedinit(SB)Первая отвечает за инициализацию работы, связанной с операционной системой, а вторая отвечает за инициализацию планировщика, что является функцией runtime·schedinit. Она отвечает за инициализацию ресурсов, необходимых для работы планировщика при запуске программы. Ниже приведён упрощённый код.
func schedinit() {
...
gp := getg()
sched.maxmcount = 10000
// Мир начинается остановленным.
worldStopped()
...
stackinit()
mallocinit()
mcommoninit(gp.m, -1)
lock(&sched.lock)
procs := ncpu
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
}
if procresize(procs) != nil {
throw("unknown runnable goroutine during bootstrap")
}
unlock(&sched.lock)
...
// Мир фактически запущен теперь, так как P могут выполняться.
worldStarted()
...
}Функция runtime.getg реализована на ассемблере. Её функция — получить представление текущей корутины во время выполнения, которое является указателем на структуру runtime.g. Через sched.maxmcount = 10000, вы можете видеть, что максимальное количество M установлено в 10000 при инициализации планировщика. Это значение фиксировано и не может быть изменено. После этого инициализируется куча стек, затем используется функция runtime.mcommoninit для инициализации M. Её реализация функции следующая:
func mcommoninit(mp *m, id int64) {
gp := getg()
// стек g0 не будет иметь смысла для пользователя (и не необходим для размотки).
if gp != gp.m.g0 {
callers(1, mp.createstack[:])
}
lock(&sched.lock)
if id >= 0 {
mp.id = id
} else {
mp.id = mReserveID()
}
...
mpreinit(mp)
if mp.gsignal != nil {
mp.gsignal.stackguard1 = mp.gsignal.stack.lo + stackGuard
}
// Добавить в allm, чтобы сборщик мусора не освобождал g->m
// когда он просто в регистре или thread-local storage.
mp.alllink = allm
// NumCgoCall() итерирует по allm без schedlock,
// поэтому мы должны опубликовать это безопасно.
atomicstorep(unsafe.Pointer(&allm), unsafe.Pointer(mp))
unlock(&sched.lock)
...
}Эта функция предварительно инициализирует M, в основном выполняя следующую работу:
- Выделяет id M
- Выделяет отдельную G для обработки сигналов потока, завершается функцией
runtime.mpreinit - Добавляет его как головной узел глобального связного списка M
runtime.allm
Далее инициализируем P. Его количество по умолчанию равно количеству логических ядер CPU, за которым следует значение переменной окружения.
procs := ncpu
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
}
if procresize(procs) != nil {
throw("unknown runnable goroutine during bootstrap")
}Наконец, функция runtime.procresize отвечает за инициализацию P. Она модифицирует глобальный срез runtime.allp, который хранит все P, на основе переданного количества. Сначала определяет, нужно ли расширять ёмкость в зависимости от размера количества.
if nprocs > int32(len(allp)) {
// Синхронизировать с retake, который может выполняться
// конкурентно, поскольку он не выполняется на P.
lock(&allpLock)
if nprocs <= int32(cap(allp)) {
allp = allp[:nprocs]
} else {
nallp := make([]*p, nprocs)
// Копируем всё до ёмкости allp, чтобы мы
// никогда не теряли старые выделенные Ps.
copy(nallp, allp[:cap(allp)])
allp = nallp
}
unlock(&allpLock)
}Затем инициализируем каждый P:
// инициализируем новые P
for i := old; i < nprocs; i++ {
pp := allp[i]
if pp == nil {
pp = new(p)
}
pp.init(i)
atomicstorep(unsafe.Pointer(&allp[i]), unsafe.Pointer(pp))
}Если P, в настоящее время используемый текущей корутиной, нуждается в уничтожении, он заменяется на allp[0], и функция runtime.acquirep завершает ассоциацию между M и новым P.
gp := getg()
if gp.m.p != 0 && gp.m.p.ptr().id < nprocs {
gp.m.p.ptr().status = _Prunning
gp.m.p.ptr().mcache.prepareForSweep()
} else {
if gp.m.p != 0 {
gp.m.p.ptr().m = 0
}
gp.m.p = 0
pp := allp[0]
pp.m = 0
pp.status = _Pidle
acquirep(pp)
}Затем уничтожаем P, которые больше не нужны. Во время уничтожения все ресурсы P освобождаются, все G в его локальной очереди помещаются в глобальную очередь, и после уничтожения срезается allp.
// освобождаем ресурсы от неиспользуемых P
for i := nprocs; i < old; i++ {
pp := allp[i]
pp.destroy()
// не можем освободить сам P, потому что он может быть сослан M в системном вызове
}
// Обрезаем allp.
if int32(len(allp)) != nprocs {
lock(&allpLock)
allp = allp[:nprocs]
unlock(&allpLock)
}Наконец, связываем простаивающие P в связный список и в конечном итоге возвращаем головной узел списка:
var runnablePs *p
for i := nprocs - 1; i >= 0; i-- {
pp := allp[i]
if gp.m.p.ptr() == pp {
continue
}
pp.status = _Pidle
if runqempty(pp) {
pidleput(pp, now)
} else {
pp.m.set(mget())
pp.link.set(runnablePs)
runnablePs = pp
}
}
return runnablePsПосле этого планировщик инициализирован, и runtime.worldStarted восстанавливает все P к выполнению.
MOVQ $runtime·mainPC(SB), AX // entry
PUSHQ AX
CALL runtime·newproc(SB)
POPQ AX
// запустить этот M
CALL runtime·mstart(SB)Затем новая корутина создаётся через функцию runtime.newproc для запуска программы Go, за которым следует вызов runtime.mstart для официального начала работы планировщика. Он также реализован на ассемблере, и внутренне вызывает функцию runtime.mstart0 для создания. Часть кода функции следующая:
gp := getg()
osStack := gp.stack.lo == 0
if osStack {
size := gp.stack.hi
if size == 0 {
size = 16384 * sys.StackGuardMultiplier
}
gp.stack.hi = uintptr(noescape(unsafe.Pointer(&size)))
gp.stack.lo = gp.stack.hi - size + 1024
}
gp.stackguard0 = gp.stack.lo + stackGuard
gp.stackguard1 = gp.stackguard0
mstart1()В этот момент M имеет только одну корутину g0, которая использует системный стек потока, а не отдельно выделенное пространство стека. Функция mstart0 сначала инициализирует границу стека G, затем передаёт mstart1 для завершения оставшейся работы инициализации.
gp := getg()
gp.sched.g = guintptr(unsafe.Pointer(gp))
gp.sched.pc = getcallerpc()
gp.sched.sp = getcallersp()
asminit()
minit()
if gp.m == &m0 {
mstartm0()
}
if fn := gp.m.mstartfn; fn != nil {
fn()
}
if gp.m != &m0 {
acquirep(gp.m.nextp.ptr())
gp.m.nextp = 0
}
schedule()Перед запуском сначала записывает текущий контекст выполнения, потому что после успешной инициализации войдёт в цикл планирования и никогда не вернётся. Другие вызовы могут переиспользовать контекст выполнения для возврата из функции mstart1 для достижения цели выхода потока. После записи, функции runtime.asminit и runtime.minit отвечают за инициализацию системного стека, затем функция runtime.mstartm0 настраивает обратные вызовы для обработки сигналов. После выполнения функции обратного вызова m.mstartfn, функция runtime.acquirep связывает M с ранее созданным P, и наконец входит в цикл планирования.
Вызванный здесь runtime.schedule — это первый цикл планирования всего runtime Go, представляющий официальное начало работы планировщика.
Потоки
В планировщике G нуждается в P для выполнения пользовательского кода, и P должен быть связан с M для нормальной работы. M относится к системным потокам.
Создание
Создание M завершается функцией runtime.newm, которая принимает функцию, P и id в качестве параметров. Функция в качестве параметра не может быть замыканием.
func newm(fn func(), pp *p, id int64) {
acquirem()
mp := allocm(pp, fn, id)
mp.nextp.set(pp)
mp.sigmask = initSigmask
newm1(mp)
releasem(getg().m)
}Перед запуском newm сначала вызывает функцию runtime.allocm для создания представления потока во время выполнения, которое является M. Во время процесса использует функцию runtime.mcommoninit для инициализации границы стека M.
func allocm(pp *p, fn func(), id int64) *m {
allocmLock.rlock()
// Вызывающий владеет pp, но мы можем занять (т.е. acquirep) это. Мы должны
// отключить вытеснение, чтобы убедиться, что это не украдено, что заставило бы
// вызывающего потерять владение.
acquirem()
gp := getg()
if gp.m.p == 0 {
acquirep(pp) // временно занимаем p для malloc в этой функции
}
mp := new(m)
mp.mstartfn = fn
mcommoninit(mp, id)
mp.g0.m = mp
releasem(gp.m)
allocmLock.runlock()
return mp
}Затем runtime.newm1 вызывает функцию runtime.newosproc для завершения фактического создания системного потока.
func newm1(mp *m) {
execLock.rlock()
newosproc(mp)
execLock.runlock()
}Реализация runtime.newosproc варьируется в зависимости от операционной системы. Как именно это создаётся, не наша забота; это обрабатывается операционной системой. Затем runtime.mstart используется для запуска работы M.
Выход
runtime.gogo(&mp.g0.sched)Как упоминалось во время инициализации, при вызове функции mstart1, контекст выполнения сохраняется в поле sched из g0. Передача этого поля функции runtime.gogo (реализована на ассемблере) позволяет потоку перейти к контексту выполнения и продолжить выполнение. При сохранении использовалось getcallerpc(), поэтому при восстановлении контекста возвращается к функции mstart0.
mstart1()
if mStackIsSystemAllocated() {
osStack = true
}
mexit(osStack)После восстановления контекста выполнения, следуя порядку выполнения, входит в функцию mexit для выхода потока.
mp := getg().m
unminit()
lock(&sched.lock)
for pprev := &allm; *pprev != nil; pprev = &(*pprev).alllink {
if *pprev == mp {
*pprev = mp.alllink
}
}
mp.freeWait.Store(freeMWait)
mp.freelink = sched.freem
sched.freem = mp
unlock(&sched.lock)
handoffp(releasep())
mdestroy(mp)
exitThread(&mp.freeWait)В основном делает следующие вещи:
- Вызывает
runtime.unminitдля отмены работыruntime.minit - Удаляет этот M из глобальной переменной
allm - Устанавливает
freemпланировщика, чтобы указывать на текущий M - Использует
runtime.releasepдля развязки P от текущего M, и используетruntime.handoffpдля связки P с другим M для продолжения работы - Использует
runtime.destroyдля уничтожения ресурсов M - Наконец, операционная система выходит из потока
В этот момент M успешно вышел.
Пауза
Когда M нуждается в паузе из-за планирования планировщика, GC, системных вызовов или других причин, вызывается функция runtime.stopm для паузы потока. Ниже приведён упрощённый код.
func stopm() {
gp := getg()
lock(&sched.lock)
mput(gp.m)
unlock(&sched.lock)
mPark()
acquirep(gp.m.nextp.ptr())
gp.m.nextp = 0
}Сначала помещает M в глобальный список простаивающих M, затем использует mPark() для блокировки текущего потока на notesleep(&gp.m.park). Когда пробуждён, эта функция возвращается.
func mPark() {
gp := getg()
notesleep(&gp.m.park)
noteclear(&gp.m.park)
}После пробуждения M будет искать P для связки и продолжит выполнение задач.
Корутины
Жизненный цикл корутины точно соответствует нескольким состояниям корутины. Понимание жизненного цикла корутины очень полезно для понимания планировщика, в конце концов, весь планировщик спроектирован вокруг корутин. Весь жизненный цикл корутины如图所示 ниже.
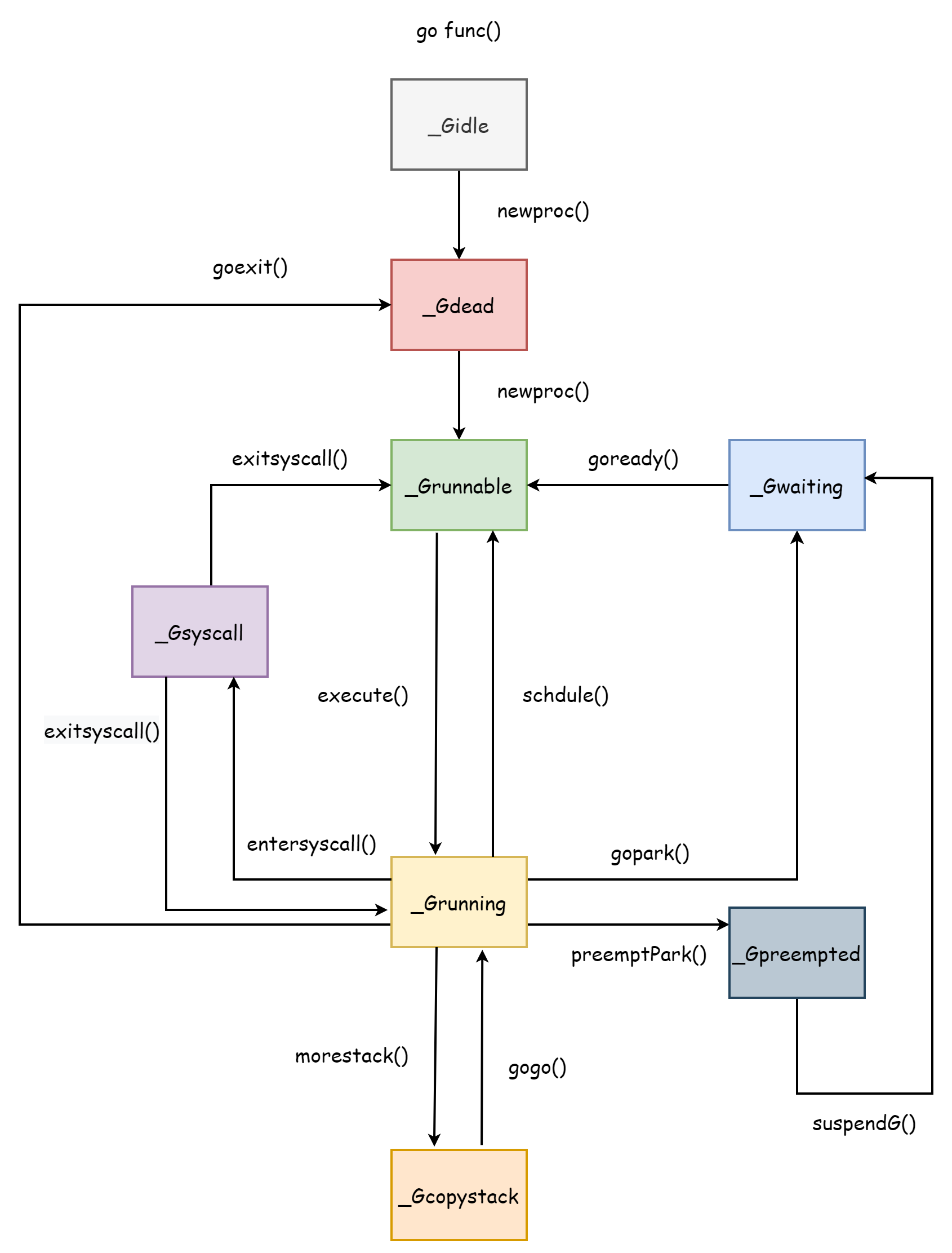
_Gcopystack — это состояние, когда стек корутины расширяется, что будет объяснено в разделе Стек корутины.
Создание
С точки зрения синтаксиса, создание корутины требует только ключевого слова go плюс функция.
go doSomething()После компиляции становится вызовом функции runtime.newproc:
func newproc(fn *funcval) {
gp := getg()
pc := getcallerpc()
systemstack(func() {
newg := newproc1(fn, gp, pc)
pp := getg().m.p.ptr()
runqput(pp, newg, true)
if mainStarted {
wakep()
}
})
}Фактическое создание завершается runtime.newproc1. Во время создания сначала блокирует M, запрещает вытеснение, затем ищет простаивающую G в локальном списке gfree P для повторного использования. Если не найдено, создаёт новую G используя runtime.malg и выделяет 2kb пространства стека. В этот момент статус G — _Gdead.
mp := acquirem() // отключаем вытеснение, потому что держим M и P в локальных переменных.
pp := mp.p.ptr()
newg := gfget(pp)
if newg == nil {
newg = malg(stackMin)
casgstatus(newg, _Gidle, _Gdead)
allgadd(newg) // публикует со статусом g->status Gdead, чтобы сканер GC не смотрел на неинициализированный стек.
}В Go 1.18 и позже, копирование параметров больше не завершается функцией newproc1. До этого использовалось runtime.memmove для копирования параметров функции. Теперь это только отвечает за сброс пространства стека корутины, используя runtime.goexit как основание стека для обработки выхода корутины, затем устанавливает PC входной функции newg.startpc = fn.fn, чтобы указать, что выполнение начинается отсюда. После установки завершено, статус G — _Grunnable.
totalSize := uintptr(4*goarch.PtrSize + sys.MinFrameSize) // дополнительное пространство на случай чтений немного за пределами фрейма
totalSize = alignUp(totalSize, sys.StackAlign)
sp := newg.stack.hi - totalSize
spArg := sp
if usesLR {
// LR вызывающего
*(*uintptr)(unsafe.Pointer(sp)) = 0
prepGoExitFrame(sp)
spArg += sys.MinFrameSize
}
memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched))
newg.sched.sp = sp
newg.stktopsp = sp
newg.sched.pc = abi.FuncPCABI0(goexit) + sys.PCQuantum // +PCQuantum, чтобы предыдущая инструкция была в той же функции
newg.sched.g = guintptr(unsafe.Pointer(newg))
gostartcallfn(&newg.sched, fn)
newg.parentGoid = callergp.goid
newg.gopc = callerpc
newg.ancestors = saveAncestors(callergp)
newg.startpc = fn.fn
casgstatus(newg, _Gdead, _Grunnable)Наконец, устанавливает уникальный идентификатор G, затем освобождает M и возвращает созданную корутину G.
newg.goid = pp.goidcache
pp.goidcache++
releasem(mp)
return newgПосле создания корутины, функция runtime.runqput пытается поместить её в локальную очередь P. Если не помещается, помещается в глобальную очередь. Во время всего процесса создания корутины, её статус сначала меняется с _Gidle на _Gdead, и после установки входной функции, с _Gdead на _Grunnable.
Выход
Во время создания Go уже установил функцию runtime.goexit как основание стека корутины. Поэтому когда выполнение корутины завершено, в конечном итоге войдёт в эту функцию. Через цепочку вызовов goexit->goexit1->goexit0, функция runtime.goexit0 в конечном итоге отвечает за работу выхода корутины.
func goexit0(gp *g) {
mp := getg().m
pp := mp.p.ptr()
...
casgstatus(gp, _Grunning, _Gdead)
...
gp.m = nil
locked := gp.lockedm != 0
gp.lockedm = 0
mp.lockedg = 0
gp.preemptStop = false
gp.paniconfault = false
gp._defer = nil // должно быть true уже, но на всякий случай.
gp._panic = nil // non-nil для Goexit во время panic. указывает на выделенные в стеке данные.
gp.writebuf = nil
gp.waitreason = waitReasonZero
gp.param = nil
gp.labels = nil
gp.timer = nil
dropg()
...
gfput(pp, gp)
...
schedule()
}Эта функция в основном делает следующие вещи:
- Устанавливает статус в
_Gdead - Сбрасывает значения полей
dropg()разрезает ассоциацию между M и Ggfput(pp, gp)помещает текущую G в локальный список простаивающих Pschedule()выполняет новый раунд планирования, передавая права выполнения M другим G
После выхода статус корутины меняется с _Grunning на _Gdead, и она всё ещё может быть переиспользована при создании новых корутин в будущем.
Системные вызовы
Когда корутина G выполняет пользовательский код, если она выполняет системный вызов, есть два способа запустить системный вызов:
- Системные вызовы из стандартной библиотеки
syscall - Вызовы cgo
Поскольку системные вызовы блокируют рабочие потоки, перед этим нужно выполнить подготовительную работу, завершённую функцией runtime.entersyscall. Однако первая — это просто простой вызов функции runtime.reentersyscall, и фактическая работа завершается последней. Сначала блокирует текущий M. Во время подготовки G запрещено вытеснение и запрещено расширение стека. Установка gp.stackguard0 = stackPreempt указывает, что после завершения подготовки права выполнения P будут вытеснены другим G. Затем сохраняет контекст выполнения корутины для восстановления после возврата системного вызова.
gp := getg()
// Отключаем вытеснение, потому что во время этой функции g находится в статусе Gsyscall,
// но может иметь несогласованный g->sched, не позволяем GC наблюдать это.
gp.m.locks++
// Entersyscall не должен вызывать любую функцию, которая может разделить/вырастить стек.
// (См. детали в комментарии выше.)
// Ловим вызовы, которые могут, заменяя guard стека чем-то, что
// споткнётся на любой проверке стека и оставляя флаг, чтобы сказать newstack умереть.
gp.stackguard0 = stackPreempt
gp.throwsplit = true
// Оставляем SP вокруг для GC и traceback.
save(pc, sp)
gp.syscallsp = sp
gp.syscallpc = pcПосле этого, чтобы предотвратить долгосрочную блокировку от влияния на выполнение других G, M и P развяжутся. После развязки M и G заблокируются из-за выполнения системных вызовов, в то время как P, после развязки, может связаться с другим простаивающим M, чтобы другие G в локальной очереди P могли продолжить работу.
casgstatus(gp, _Grunning, _Gsyscall)
gp.m.syscalltick = gp.m.p.ptr().syscalltick
pp := gp.m.p.ptr()
pp.m = 0
gp.m.oldp.set(pp)
gp.m.p = 0
atomic.Store(&pp.status, _Psyscall)
gp.m.locks--После завершения подготовки освобождает блокировку M. В этот период статус G меняется с _Grunning на _Gsyscall, и статус P становится _Psyscall.
Когда системный вызов возвращается, поток M больше не заблокирован, и соответствующая G также должна быть запланирована снова для выполнения пользовательского кода, завершённого функцией runtime.exitsyscall. Сначала блокирует текущий M и получает ссылку на старый P.
gp := getg()
gp.waitsince = 0
oldp := gp.m.oldp.ptr()
gp.m.oldp = 0В этот момент есть два случая для обработки. Первый случай — есть ли P, доступный для прямого использования. Функция runtime.exitsyscallfast определит, доступен ли оригинальный P, т.е. является ли статус P _Psyscall. В противном случае будет искать простаивающий P.
func exitsyscallfast(oldp *p) bool {
gp := getg()
// Freezetheworld устанавливает stopwait, но не забирает P.
if sched.stopwait == freezeStopWait {
return false
}
// Пытаемся повторно захватить последний P.
if oldp != nil && oldp.status == _Psyscall && atomic.Cas(&oldp.status, _Psyscall, _Pidle) {
// Есть cpu для нас, поэтому мы можем выполняться.
wirep(oldp)
exitsyscallfast_reacquired()
return true
}
// Пытаемся получить любой другой простаивающий P.
if sched.pidle != 0 {
var ok bool
systemstack(func() {
ok = exitsyscallfast_pidle()
})
if ok {
return true
}
}
return false
}Если успешно найден usable P, M свяжется с P, G переключится со статуса _Gsyscall на статус _Grunning, и затем через runtime.Gosched, G добровольно уступит права выполнения, и P войдёт в цикл планирования для поиска других доступных G.
oldp := gp.m.oldp.ptr()
gp.m.oldp = 0
if exitsyscallfast(oldp) {
// Есть cpu для нас, поэтому мы можем выполняться.
gp.m.p.ptr().syscalltick++
// Мы должны cas статус и сканировать перед возобновлением...
casgstatus(gp, _Gsyscall, _Grunning)
// Сборщик мусора не выполняется (поскольку мы выполняемся),
// поэтому можно очистить syscallsp.
gp.syscallsp = 0
gp.m.locks--
if gp.preempt {
// восстановить запрос вытеснения в случае, если мы очистили это в newstack
gp.stackguard0 = stackPreempt
} else {
// иначе восстановить реальный stackGuard, мы испортили это в entersyscall/entersyscallblock
gp.stackguard0 = gp.stack.lo + stackGuard
}
gp.throwsplit = false
if sched.disable.user && !schedEnabled(gp) {
// Планирование этой goroutine отключено.
Gosched()
}
return
}Если не найдено, M развяжется с G, G переключится со статуса _Gsyscall на статус _Grunnable, затем снова попытается найти простаивающий P. Если не найдено, напрямую поместит G в глобальную очередь, затем войдёт в новый цикл планирования. Старый M войдёт в состояние простоя через runtime.stopm, ожидая новых задач в будущем. Если P найден, старый M и G свяжутся с новым P, затем продолжат выполнять пользовательский код, со статусом, меняющимся с _Grunnable на _Grunning.
func exitsyscall0(gp *g) {
casgstatus(gp, _Gsyscall, _Grunnable)
dropg()
lock(&sched.lock)
var pp *p
if schedEnabled(gp) {
pp, _ = pidleget(0)
}
var locked bool
if pp == nil {
globrunqput(gp)
}
unlock(&sched.lock)
if pp != nil {
acquirep(pp)
execute(gp, false) // Никогда не возвращается.
}
stopm()
schedule() // Никогда не возвращается.
}После выхода из системного вызова, статус G в конечном итоге имеет два результата: один — _Grunnable, ожидающий планирования, и другой — _Grunning, продолжающий выполняться.
Приостановка
Когда текущая корутина приостановлена по какой-либо причине, её статус меняется с _Grunnable на _Gwaiting. Есть много причин для приостановки, таких как блокировка канала, select, блокировки или time.sleep. Для большего количества причин см. Структура G. Взяв time.Sleep в качестве примера, это фактически ссылается на runtime.timesleep. Код последнего следующий.
func timeSleep(ns int64) {
if ns <= 0 {
return
}
gp := getg()
t := gp.timer
if t == nil {
t = new(timer)
gp.timer = t
}
t.f = goroutineReady
t.arg = gp
t.nextwhen = nanotime() + ns
if t.nextwhen < 0 { // проверка на переполнение.
t.nextwhen = maxWhen
}
gopark(resetForSleep, unsafe.Pointer(t), waitReasonSleep, traceBlockSleep, 1)
}Как вы можете видеть, получает текущую корутину через getg, затем заставляет текущую корутину приостановиться через runtime.gopark. runtime.gopark обновляет причину блокировки G и M, освобождает блокировку M.
mp := acquirem()
gp := mp.curg
status := readgstatus(gp)
if status != _Grunning && status != _Gscanrunning {
throw("gopark: bad g status")
}
mp.waitlock = lock
mp.waitunlockf = unlockf
gp.waitreason = reason
mp.waitTraceBlockReason = traceReason
mp.waitTraceSkip = traceskip
releasem(mp)
// не можем делать ничего, что может переместить G между Ms здесь.
mcall(park_m)Затем переключается на системный стек и использует runtime.park_m для переключения статуса G на _Gwaiting, затем разрезает ассоциацию между M и G и входит в новый цикл планирования для уступки прав выполнения другим G. После приостановки G не выполняет пользовательский код и не находится в локальной очереди, просто поддерживая ссылки на M и P.
mp := getg().m
casgstatus(gp, _Grunning, _Gwaiting)
dropg()
schedule()В функции runtime.timesleep есть эта строка кода, указывающая значение t.f:
t.f = goroutineReadyЭта функция runtime.goroutineReady используется для пробуждения приостановленных корутин. Она вызывает функцию runtime.ready для пробуждения корутины.
status := readgstatus(gp)
// Помечаем выполняемой.
mp := acquirem()
casgstatus(gp, _Gwaiting, _Grunnable)
runqput(mp.p.ptr(), gp, next)
wakep()
releasem(mp)После пробуждения переключает статус G на _Grunnable, затем помещает G в локальную очередь P для ожидания будущего планирования.
Стек корутины
Корутины в языке Go являются типичным стеком корутины. Каждая корутина выделяется независимым пространством стека на куче, и оно растёт или сжимается с изменениями использования. Во время инициализации планировщика, функция runtime.stackinit отвечает за инициализацию глобального кэша пространства стека stackpool и stackLarge.
func stackinit() {
if _StackCacheSize&_PageMask != 0 {
throw("cache size must be a multiple of page size")
}
for i := range stackpool {
stackpool[i].item.span.init()
lockInit(&stackpool[i].item.mu, lockRankStackpool)
}
for i := range stackLarge.free {
stackLarge.free[i].init()
lockInit(&stackLarge.lock, lockRankStackLarge)
}
}Кроме того, каждый P имеет свой независимый кэш пространства стека mcache:
type p struct {
...
mcache *mcache
...
}
type mcache struct {
_ sys.NotInHeap
nextSample uintptr
scanAlloc uintptr
tiny uintptr
tinyoffset uintptr
tinyAllocs uintptr
alloc [numSpanClasses]*mspan
stackcache [_NumStackOrders]stackfreelist
flushGen atomic.Uint32
}Кэш потока mcache независим для каждого потока и не выделяется на памяти кучи. Блокировка не нужна при доступе. Эти три кэша стека будут использованы в последующем выделении пространства.
Выделение
При создании корутины, если нет переиспользуемой корутины, новое пространство стека будет выделено для неё. Его размер по умолчанию — 2KB.
newg := gfget(pp)
if newg == nil {
newg = malg(stackMin)
casgstatus(newg, _Gidle, _Gdead)
allgadd(newg) // публикует со статусом g->status Gdead, чтобы сканер GC не смотрел на неинициализированный стек.
}Функция, ответственная за выделение пространства стека — runtime.stackalloc:
func stackalloc(n uint32) stackЕсть два случая в зависимости от того, меньше ли запрошенный размер памяти стека 32KB. 32KB — это также стандарт Go для определения, является ли объект маленьким или большим. Если меньше этого значения, будет получено из кэша stackpool. Когда M связан с P и M не разрешено вытеснение, будет получено из локального кэша потока.
if n < fixedStack<<_NumStackOrders && n < _StackCacheSize {
order := uint8(0)
n2 := n
for n2 > fixedStack {
order++
n2 >>= 1
}
var x gclinkptr
if stackNoCache != 0 || thisg.m.p == 0 || thisg.m.preemptoff != "" {
lock(&stackpool[order].item.mu)
x = stackpoolalloc(order)
unlock(&stackpool[order].item.mu)
} else {
c := thisg.m.p.ptr().mcache
x = c.stackcache[order].list
if x.ptr() == nil {
stackcacherefill(c, order)
x = c.stackcache[order].list
}
c.stackcache[order].list = x.ptr().next
c.stackcache[order].size -= uintptr(n)
}
v = unsafe.Pointer(x)
}Если больше 32KB, будет получено из кэша stackLarge. Если этого всё ещё недостаточно, память напрямую выделяется на куче.
else {
var s *mspan
npage := uintptr(n) >> _PageShift
log2npage := stacklog2(npage)
// Пытаемся получить стек из кэша больших стеков.
lock(&stackLarge.lock)
if !stackLarge.free[log2npage].isEmpty() {
s = stackLarge.free[log2npage].first
stackLarge.free[log2npage].remove(s)
}
unlock(&stackLarge.lock)
lockWithRankMayAcquire(&mheap_.lock, lockRankMheap)
if s == nil {
// Выделяем новый стек из кучи.
s = mheap_.allocManual(npage, spanAllocStack)
if s == nil {
throw("out of memory")
}
osStackAlloc(s)
s.elemsize = uintptr(n)
}
v = unsafe.Pointer(s.base())
}После завершения возвращает низкий и высокий адреса пространства стека:
return stack{uintptr(v), uintptr(v) + uintptr(n)}Расширение
Размер стека корутины по умолчанию — 2KB, что достаточно легко, поэтому стоимость создания корутины очень низка. Но этого может быть недостаточно. Когда пространство стека недостаточно, оно нуждается в расширении. Компилятор вставляет функцию runtime.morestack в начале функций для проверки, нуждается ли текущая корутина в расширении стека. Если нужно, вызывает runtime.newstack для завершения фактической операции расширения.
TIP
Поскольку morestack вставляется в начале почти всех функций, время проверки расширения стека также является точкой вытеснения корутины.
thisg := getg()
gp := thisg.m.curg
// Выделяем больший сегмент и перемещаем стек.
oldsize := gp.stack.hi - gp.stack.lo
newsize := oldsize * 2
// Goroutine должна выполняться, чтобы вызвать newstack,
// поэтому она должна быть Grunning (или Gscanrunning).
casgstatus(gp, _Grunning, _Gcopystack)
// Конкурентный GC не будет сканировать стек, пока мы выполняем копирование, поскольку
// gp находится в статусе Gcopystack.
copystack(gp, newsize)
casgstatus(gp, _Gcopystack, _Grunning)
gogo(&gp.sched)Как вы можете видеть, рассчитанная ёмкость пространства стека в два раза больше оригинала. Функция runtime.copystack завершает работу копирования стека. Перед копированием статус G переключается с _Grunning на _Gcopystack.
func copystack(gp *g, newsize uintptr) {
old := gp.stack
used := old.hi - gp.sched.sp
// выделяем новый стек
new := stackalloc(uint32(newsize))
// Вычисляем корректировку.
var adjinfo adjustinfo
adjinfo.old = old
adjinfo.delta = new.hi - old.hi
// Копируем стек (или остальную часть) в новое место
memmove(unsafe.Pointer(new.hi-ncopy), unsafe.Pointer(old.hi-ncopy), ncopy)
// Корректируем оставшиеся структуры, которые имеют указатели в стеки.
// Мы должны сделать большинство из них перед тем, как отследить новый
// стек, потому что gentraceback использует их.
adjustctxt(gp, &adjinfo)
adjustdefers(gp, &adjinfo)
adjustpanics(gp, &adjinfo)
if adjinfo.sghi != 0 {
adjinfo.sghi += adjinfo.delta
}
// Меняем старый стек на новый
gp.stack = new
gp.stackguard0 = new.lo + stackGuard // ПРИМЕЧАНИЕ: может затереть запрос вытеснения
gp.sched.sp = new.hi - used
gp.stktopsp += adjinfo.delta
// Корректируем указатели в новом стеке.
var u unwinder
for u.init(gp, 0); u.valid(); u.next() {
adjustframe(&u.frame, &adjinfo)
}
stackfree(old)
}Эта функция выполняет следующую работу:
- Выделяет новое пространство стека
- Напрямую копирует старую память стека в новое пространство стека через
runtime.memmove - Корректирует структуры, содержащие указатели стека, такие как defer, panic и т.д.
- Обновляет поле пространства стека G
- Корректирует указатели, указывающие на старую память стека через
runtime.adjustframe - Освобождает старую память стека
После завершения статус G переключается с _Gcopystack на _Grunning, и функция runtime.gogo позволяет G продолжить выполнение пользовательского кода. Именно из-за расширения стека корутины память в Go нестабильна.
Сжатие
Когда статус G — _Grunnable, _Gsyscall или _Gwaiting, GC сканирует пространство памяти стека корутины.
func scanstack(gp *g, gcw *gcWork) int64 {
switch readgstatus(gp) &^ _Gscan {
case _Grunnable, _Gsyscall, _Gwaiting:
// ok
}
...
if isShrinkStackSafe(gp) {
// Сжимаем стек, если не много используется.
shrinkstack(gp)
}
...
}Фактическая работа сжатия стека завершается runtime.shrinkstack.
func shrinkstack(gp *g) {
if !isShrinkStackSafe(gp) {
throw("shrinkstack at bad time")
}
oldsize := gp.stack.hi - gp.stack.lo
newsize := oldsize / 2
if newsize < fixedStack {
return
}
avail := gp.stack.hi - gp.stack.lo
if used := gp.stack.hi - gp.sched.sp + stackNosplit; used >= avail/4 {
return
}
copystack(gp, newsize)
}Когда используемое пространство стека меньше 1/4 от оригинала, использует runtime.copystack для сжатия до 1/2 от оригинала. Оставшаяся работа такая же, как и раньше.
Сегментированный стек
Из процесса copystack вы можете видеть, что он копирует старую память стека в большее пространство стека. И оригинальный стек, и новый стек имеют непрерывные адреса памяти. В древнем языке Go расширение стека выполнялось по-другому. В то время считалось, что копирование памяти слишком затратно по производительности, поэтому был принят подход сегментированного стека. Если память пространства стека была недостаточной, запрашивалось новое пространство стека. Оригинальная память пространства стека не освобождалась и не копировалась, и они связывались вместе через указатели, образуя связанный список стека. Это происхождение сегментированных стеков, как показано на рисунке ниже.
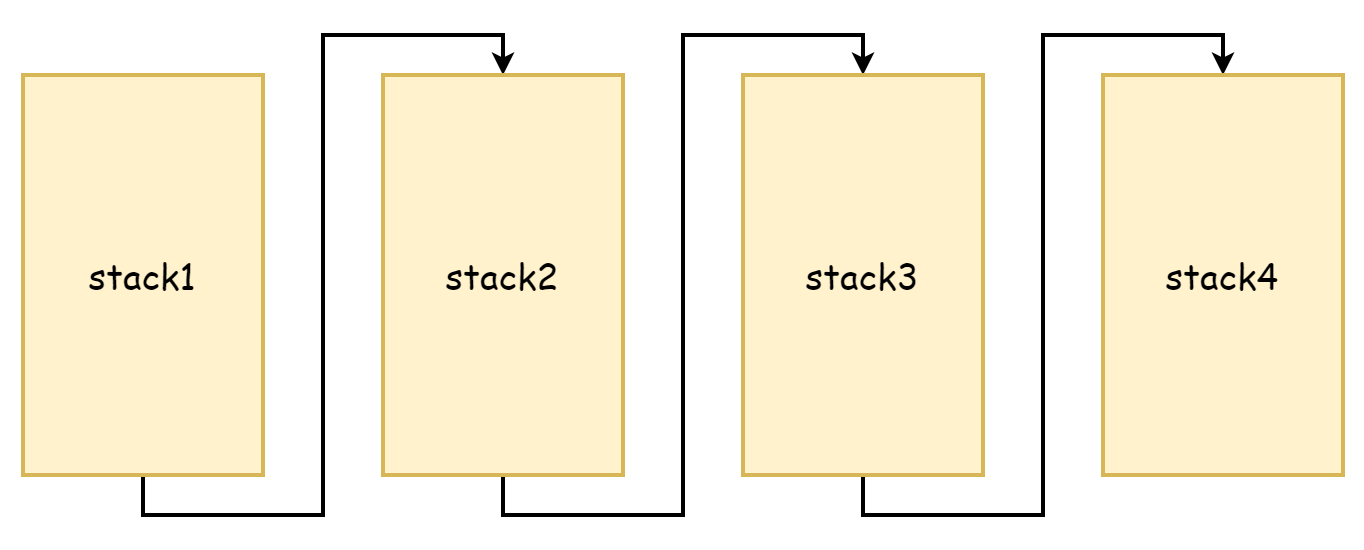
Преимущество этого подхода в том, что не нужно копировать оригинальный стек, но недостатки также очень очевидны: он запускает расширение и сжатие стека очень часто. Когда свободная память пространства стека заканчивается, новые вызовы функций запускают расширение стека. Когда эти функции возвращаются и новое пространство стека больше не нужно, снова запускается сжатие. Если эти вызовы функций очень частые, потеря производительности, вызванная такими операциями, очень значительна.
Поэтому после Go 1.4 переключились на непрерывные стеки. Непрерывные стеки выделяют пространство стека большей ёмкости, поэтому когда используемая память достигает критического значения, она не часто запускает расширение/сжатие из-за вызовов функций. И поскольку адреса памяти непрерывны, согласно принципу пространственной локальности кэша, непрерывные стеки также более дружелюбны к кэшу CPU.
Цикл планирования
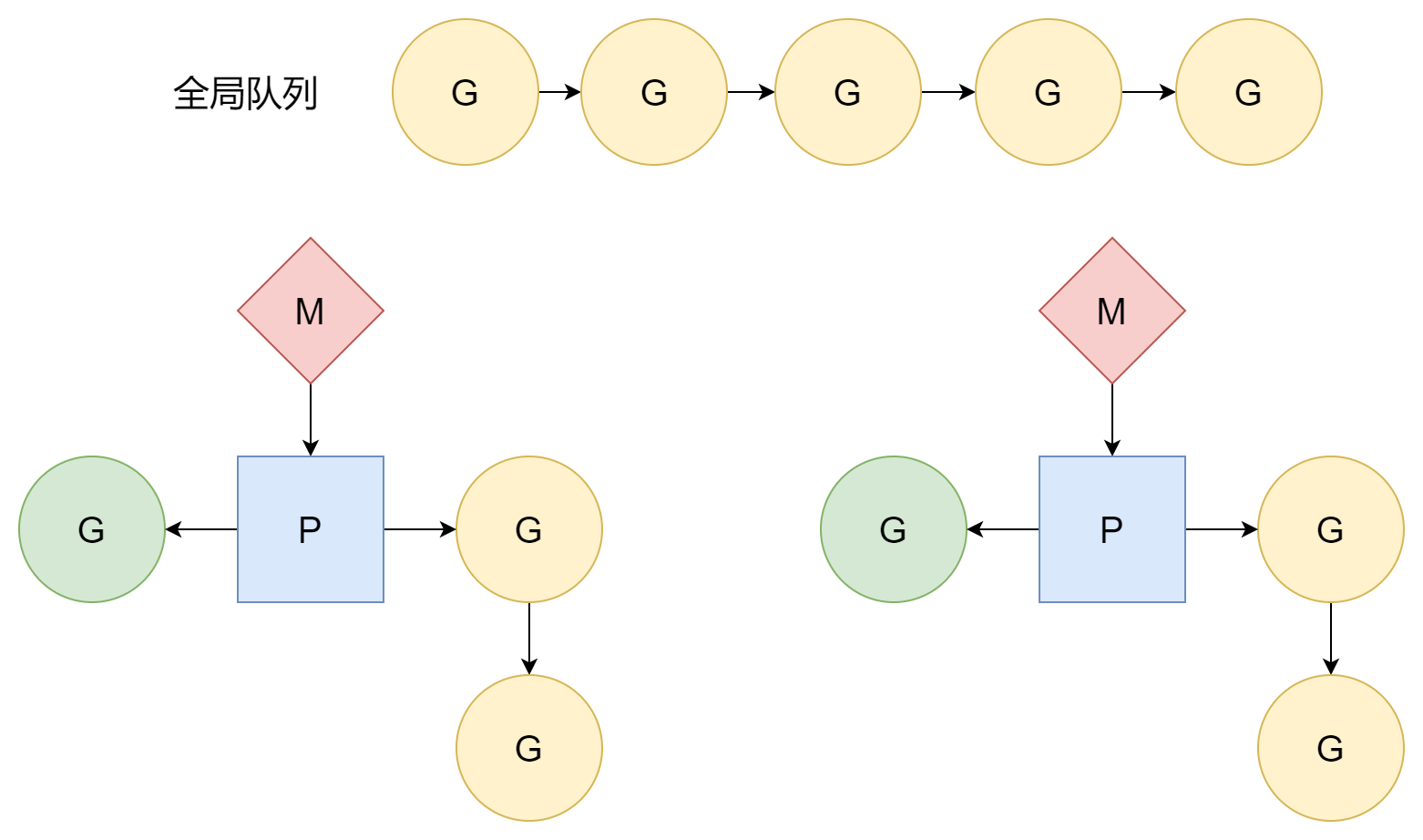
Как упоминалось в разделе инициализации планировщика, в функции runtime.mstart1, после успешной ассоциации M и P, входит в первый цикл планирования runtime.schedule, официально начиная планирование G для выполнения пользовательского кода. В цикле планирования эта часть в основном где P играет роль. M соответствует системным потокам, G соответствует входным функциям (т.е. пользовательскому коду), но P не как M и G, которые имеют соответствующие сущности. Это просто абстрактная концепция, действующая как посредник, обрабатывающий отношения между M и G.
func schedule() {
mp := getg().m
top:
pp := mp.p.ptr()
pp.preempt = false
if mp.spinning {
resetspinning()
}
gp, inheritTime, tryWakeP := findRunnable() // блокирует до доступности работы
execute(gp, inheritTime)
}Приведённый выше код упрощён, с удалением многих условных суждений. Самые ядровые точки только две: runtime.findRunnable и runtime.execute. Первая отвечает за поиск G и обязательно вернёт доступную G, в то время как вторая отвечает за то, чтобы G продолжила выполнение пользовательского кода.
Для функции findRunnable, первый источник G — локальная очередь P:
// локальная runq
if gp, inheritTime := runqget(pp); gp != nil {
return gp, inheritTime, false
}Если в локальной очереди нет G, затем пытается получить из глобальной очереди:
// глобальная runq
if sched.runqsize != 0 {
lock(&sched.lock)
gp := globrunqget(pp, 0)
unlock(&sched.lock)
if gp != nil {
return gp, false, false
}
}Если не найдено в локальных и глобальных очередях, пытается получить из сетевого опросника:
if netpollinited() && netpollWaiters.Load() > 0 && sched.lastpoll.Load() != 0 {
if list := netpoll(0); !list.empty() { // non-blocking
gp := list.pop()
injectglist(&list)
casgstatus(gp, _Gwaiting, _Grunnable)
if traceEnabled() {
traceGoUnpark(gp, 0)
}
return gp, false, false
}
}Если всё ещё не найдено, в конечном итоге украдёт G из локальных очередей других P. Как упоминалось во время создания корутины, один основной источник G в локальной очереди P — это под-корутины, порождённые текущей корутиной. Однако не все корутины будут создавать под-корутины, поэтому возможно, что некоторые P очень заняты, в то время как другие P простаивают. Это может привести к ситуации, где некоторые G ожидают и не могут выполняться долгое время, в то время как с другой стороны P очень простаивают, нечего делать. Чтобы выжать все P для максимизации их эффективности работы, когда P не может найти G, он будет "красть" выполняемые G из локальных очередей других P. Таким образом, каждый P может иметь относительно равномерную очередь G, и менее вероятно иметь ситуацию, где P смотрят друг на друга через реку.
gp, inheritTime, tnow, w, newWork := stealWork(now)
if gp != nil {
// Успешно украли.
return gp, inheritTime, false
}runtime.stealWork будет случайно выбирать P для кражи. Фактическая работа кражи завершается функцией runtime.runqgrab, которая пытается украсть половину G из локальной очереди этого P.
for {
h := atomic.LoadAcq(&pp.runqhead) // load-acquire, синхронизирует с другими потребителями
t := atomic.LoadAcq(&pp.runqtail) // load-acquire, синхронизирует с производителем
n := t - h
n = n - n/2
if n > uint32(len(pp.runq)/2) { // читаем несогласованные h и t
continue
}
for i := uint32(0); i < n; i++ {
g := pp.runq[(h+i)%uint32(len(pp.runq))]
batch[(batchHead+i)%uint32(len(batch))] = g
}
if atomic.CasRel(&pp.runqhead, h, h+n) { // cas-release, фиксирует потребление
return n
}
}Вся работа кражи выполняется четыре раза. Если после четырёх раз не украдено G, возвращается. Если в конечном итоге не удалось найти, текущий M приостанавливается runtime.stopm до пробуждения для продолжения повторения вышеуказанных шагов. Когда G найдена и возвращена, передаётся runtime.execute для запуска G.
mp := getg().m
mp.curg = gp
gp.m = mp
casgstatus(gp, _Grunnable, _Grunning)
gp.waitsince = 0
gp.preempt = false
gp.stackguard0 = gp.stack.lo + stackGuard
gogo(&gp.sched)Сначала обновляет curg M, затем обновляет статус G на _Grunning, и наконец передаёт runtime.gogo для восстановления выполнения G.
В целом, в цикле планирования источники G делятся на четыре уровня согласно приоритету:
- Локальная очередь P
- Глобальная очередь
- Сетевой опросник
- Кража из локальных очередей других P
После выполнения runtime.execute не возвращается. Только что полученная G не будет выполняться вечно либо. В какой-то момент, когда планирование запущено, её права выполнения будут лишены, затем войдёт в новый цикл планирования, уступая права выполнения другим G.
Стратегия планирования
Разные G могут иметь разное время выполнения пользовательского кода. Некоторые G могут занимать много времени, в то время как другие занимают мало времени. G с долгим временем выполнения могут вызвать невозможность выполнения других G долгое время, поэтому чередующееся выполнение G — это правильный способ. Этот рабочий метод называется конкурентностью в операционных системах.
Кооперативное планирование
Основная идея кооперативного планирования — позволить G добровольно уступать права выполнения другим G. Есть в основном два метода.
Первый метод — добровольно уступать в пользовательском коде. Go предоставляет функцию runtime.Gosched(), позволяющую пользователям решать, когда уступать права выполнения. Однако во многих случаях внутренние рабочие детали планировщика являются чёрным ящиком для пользователей, что затрудняет определение, когда добровольно уступать. Это требует более высоких требований к пользователям. Более того, планировщик Go стремится экранировать большинство деталей от пользователей и追求 более простые методы использования. В этом случае вовлечение пользователей в работу планирования — это не хорошо.
Второй метод — маркировка вытеснения. Хотя его имя имеет слово "вытеснение", это по сути всё ещё стратегия кооперативного планирования. Идея — вставить код обнаружения вытеснения runtime.morestack() в начале функций. Процесс вставки завершается во время фазы компиляции. Как упоминалось ранее, это изначально функция для обнаружения расширения стека. Поскольку её точка обнаружения — каждый вызов функции, это также хорошее время для обнаружения вытеснения. Верхняя часть функции runtime.newstack вся для обнаружения вытеснения, в то время как нижняя часть для обнаружения расширения стека. Чтобы избежать помех раньше, эта часть была опущена. Теперь посмотрим, что делает эта часть. Сначала делает суждение вытеснения на основе gp.stackguard0. Если вытеснение не нужно, продолжает выполнять пользовательский код.
stackguard0 := atomic.Loaduintptr(&gp.stackguard0)
preempt := stackguard0 == stackPreempt
if preempt {
if !canPreemptM(thisg.m) {
gp.stackguard0 = gp.stack.lo + stackGuard
gogo(&gp.sched) // никогда не возвращается
}
}Когда g.stackguard0 == stackPreempt, функция runtime.canPreemptM() определяет, нуждаются ли условия корутины в вытеснении. Код следующий:
func canPreemptM(mp *m) bool {
return mp.locks == 0 && mp.mallocing == 0 && mp.preemptoff == "" && mp.p.ptr().status == _Prunning
}Как вы можете видеть, быть вытесняемым требует выполнения четырёх условий:
- M не заблокирован
- Не выделяет память в настоящее время
- Вытеснение не отключено
- P находится в статусе
_Prunning
В следующих двух ситуациях g.stackguard0 устанавливается в stackPreempt:
- Когда нужна сборка мусора
- Когда происходит системный вызов
if preempt {
if gp.preemptShrink {
gp.preemptShrink = false
shrinkstack(gp)
}
// Действуем как goroutine вызвала runtime.Gosched.
gopreempt_m(gp) // никогда не возвращается
}Наконец, переходит к runtime.gopreempt_m() для добровольной уступки прав выполнения текущей корутины. Сначала разрезает соединение между M и G, статус становится _Grunnable, затем помещает G в глобальную очередь, и наконец входит в цикл планирования для уступки прав выполнения другим G.
casgstatus(gp, _Grunning, _Grunnable)
dropg()
lock(&sched.lock)
globrunqput(gp)
unlock(&sched.lock)
schedule()Таким образом, все корутины могут войти в эту функцию для обнаружения вытеснения во время вызовов функций. Эта стратегия полагается на время вызова функций для запуска вытеснения и добровольной уступки. До Go 1.14 Go всегда использовал эту стратегию планирования. Но это имеет проблему: если нет вызова функции, обнаружение не может произойти. Например, следующий классический код, который должен был появиться во многих учебниках:
func main() {
// Ограничиваем количество P только 1
runtime.GOMAXPROCS(1)
// Корутина 1
go func() {
for {
// Эта корутина продолжает вращаться вхолостую
}
}()
// Входим в системный вызов, основная корутина уступает другим корутинам
time.Sleep(time.Millisecond)
println("exit")
}Код создаёт вращающуюся вхолостую корутину 1, затем основная корутина добровольно уступает из-за системного вызова. В этот момент корутина 1 планируется, но поскольку она вообще не вызывает функции, не может выполнить обнаружение вытеснения. Поскольку есть только один P и нет других простаивающих P, это вызывает, что основная корутина никогда не планируется, и exit никогда не выводится. Однако эта проблема ограничена до Go 1.14.
Вытесняющее планирование
Официальные лица добавили стратегию вытесняющего планирования на основе сигналов в Go 1.14. Это асинхронная стратегия вытеснения, которая вытесняет потоки путём отправки сигналов через асинхронные потоки. Вытесняющее планирование на основе сигналов в настоящее время имеет две точки входа: системный мониторинг и GC.
В цикле системного мониторинга обходит каждый P. Если G, планируемая P, выполняется более 10ms, принудительно запускает вытеснение. Эта работа завершается функцией runtime.retake. Ниже приведён упрощённый код.
func retake(now int64) uint32 {
n := 0
lock(&allpLock)
for i := 0; i < len(allp); i++ {
pp := allp[i]
if pp == nil {
continue
}
pd := &pp.sysmontick
s := pp.status
sysretake := false
if s == _Prunning || s == _Psyscall {
// Вытесняем G, если выполняется слишком долго.
t := int64(pp.schedtick)
if int64(pd.schedtick) != t {
pd.schedtick = uint32(t)
pd.schedwhen = now
} else if pd.schedwhen+forcePreemptNS <= now {
preemptone(pp)
sysretake = true
}
}
}
unlock(&allpLock)
return uint32(n)
}Когда нужна сборка мусора, если статус G — _Grunning, значит она всё ещё выполняется, это также запустит вытеснение.
func suspendG(gp *g) suspendGState {
for i := 0; ; i++ {
switch s := readgstatus(gp); s {
case _Grunning:
gp.preemptStop = true
gp.preempt = true
gp.stackguard0 = stackPreempt
casfrom_Gscanstatus(gp, _Gscanrunning, _Grunning)
if preemptMSupported && debug.asyncpreemptoff == 0 && needAsync {
now := nanotime()
if now >= nextPreemptM {
nextPreemptM = now + yieldDelay/2
preemptM(asyncM)
}
}
......
......
func preemptM(mp *m) {
if mp.signalPending.CompareAndSwap(0, 1) {
if GOOS == "darwin" || GOOS == "ios" {
pendingPreemptSignals.Add(1)
}
signalM(mp, sigPreempt)
}
}Обе точки входа вытеснения в конечном итоге входят в функцию runtime.preemptM, которая завершает отправку сигналов вытеснения. Когда сигнал успешно отправлен, функция обратного вызова обработчика сигналов runtime.sighandler, зарегистрированная через runtime.initsig в runtime.mstart, вступает в игру. Если обнаруживает, что сигнал вытеснения был отправлен, начинает вытеснение.
func sighandler(sig uint32, info *siginfo, ctxt unsafe.Pointer, gp *g) {
...
if sig == sigPreempt && debug.asyncpreemptoff == 0 && !delayedSignal {
// Может быть сигнал вытеснения.
doSigPreempt(gp, c)
}
...
}doSigPreempt модифицирует контекст целевой корутины и вставляет вызов runtime.asyncPreempt.
func doSigPreempt(gp *g, ctxt *sigctxt) {
// Проверяем, хочет ли эта G быть вытесненной и безопасно ли
// вытеснять.
if wantAsyncPreempt(gp) {
if ok, newpc := isAsyncSafePoint(gp, ctxt.sigpc(), ctxt.sigsp(), ctxt.siglr()); ok {
// Корректируем PC и вставляем вызов asyncPreempt.
ctxt.pushCall(abi.FuncPCABI0(asyncPreempt), newpc)
}
}
...Таким образом, при переключении обратно на пользовательский код, целевая корутина пойдёт к функции runtime.asyncPreempt, которая включает вызов runtime.asyncPreempt2.
TEXT ·asyncPreempt(SB),NOSPLIT|NOFRAME,$0-0
PUSHQ BP
MOVQ SP, BP
// Сохраняем флаги перед разрушением их
PUSHFQ
// obj не понимает ADD/SUB на SP, но понимает ADJSP
ADJSP $368
// Но vet не знает ADJSP, поэтому подавляем проверку стека vet
...
CALL ·asyncPreempt2(SB)
...
RETЭто заставляет текущую корутину прекратить работу и выполнить новый раунд цикла планирования для уступки прав выполнения другим корутинам.
func asyncPreempt2() {
gp := getg()
gp.asyncSafePoint = true
if gp.preemptStop {
mcall(preemptPark)
} else {
mcall(gopreempt_m)
}
gp.asyncSafePoint = false
}Весь этот процесс происходит в функции runtime.asyncPreempt, которая реализована на ассемблере (находится в runtime/preempt_*.s) и восстанавливает ранее модифицированный контекст корутины после завершения планирования, чтобы корутина могла нормально восстановиться в будущем. После принятия стратегии асинхронного вытеснения, предыдущий пример больше не будет навсегда блокировать основную корутину. Когда вращающаяся корутина выполняется определённое время, она будет принудительно выполнена в цикле планирования, тем самым уступая права выполнения основной корутине, в конечном итоге позволяя программе нормально завершиться.
Сводка
В целом, время для запуска планирования включает следующее:
- Вызовы функций
- Системные вызовы
- Системный мониторинг
- Сборка мусора (GC также вытесняет корутины, которые выполняются слишком долго)
- Приостановка корутины из-за каналов, блокировок или других причин
Стратегии планирования в основном две категории: кооперативное и вытесняющее. Кооперативное — это добровольная уступка прав выполнения, в то время как вытесняющее — асинхронное захватывание прав выполнения. Оба сосуществуют, образуя сегодняшний планировщик.