gc
Задача сборки мусора — освобождение памяти объектов, которые больше не используются, и освобождение места для других объектов. Это простое описание реализуется удивительно сложным образом. Сборка мусора имеет историю развития, охватывающую десятилетия. Ещё в 1960-х годах язык Lisp впервые принял механизмы сборки мусора. Python и Objective-C, которые нам знакомы, в основном используют подсчёт ссылок для своих механизмов GC, в то время как Java и C# используют поколенческую сборку.
На сегодняшний день алгоритмы сборки мусора можно условно разделить на следующие типы:
- Подсчёт ссылок: Каждый объект отслеживает, сколько раз на него ссылаются. Когда счётчик достигает 0, он перерабатывается.
- Mark-Sweep (Пометь-и-очисти): Активные объекты помечаются, а непомеченные объекты собираются.
- Алгоритм копирования: Активные объекты копируются в новую память, а все объекты в старой памяти собираются для освобождения места.
- Mark-Compact (Пометь-и-уплотни): Улучшение mark-sweep, которое перемещает активные объекты к началу кучи для удобства управления.
С точки зрения приложения, они могут быть классифицированы как:
- Глобальная сборка: Собирает весь мусор за один проход
- Поколенческая сборка: Объекты делятся на поколения в зависимости от их времени жизни, с разными алгоритмами сборки для каждого
- Инкрементальная сборка: Каждый раз выполняется только частичная сборка мусора
TIP
Посетите The Journey of Go's Garbage Collector, чтобы прочитать оригинальную статью на английском языке и узнать больше об истории сборки мусора в Go.
Когда Go только был выпущен, его механизм сборки мусора был очень примитивным, с только простым алгоритмом mark-sweep. STW (Stop The World, относящийся к паузе всей программы для сборки мусора), вызванный сборкой мусора, мог длиться несколько секунд или даже дольше. Осознав эту проблему, команда Go начала улучшать алгоритм сборки мусора. Между версиями Go 1.0 и Go 1.8 они попробовали много подходов:
- Read Barrier Concurrent Copying GC: Этот подход был отклонён из-за высокой неопределённости накладных расходов read barrier.
- Request-Oriented Collector (ROC): Требовал, чтобы write barriers были включены постоянно, замедляя выполнение и увеличивая время компиляции.
- Поколенческая сборка: Поколенческая сборка не была эффективной в Go, потому что компилятор Go склонен выделять новые объекты в стеке, а долгоживущие объекты в куче, поэтому большинство объектов нового поколения будут напрямую переработаны стеком.
- Card Marking Without Write Barriers: Заменил затраты write barrier на затраты hash scattering, требуя поддержки оборудования.
В конечном итоге, команда Go выбрала комбинацию трёхцветной конкурентной маркировки с write barriers, постоянно улучшая и оптимизируя её в последующих версиях. Этот подход продолжается и по сей день. Следующий набор графиков показывает изменения задержки GC от Go 1.4 до Go 1.9.
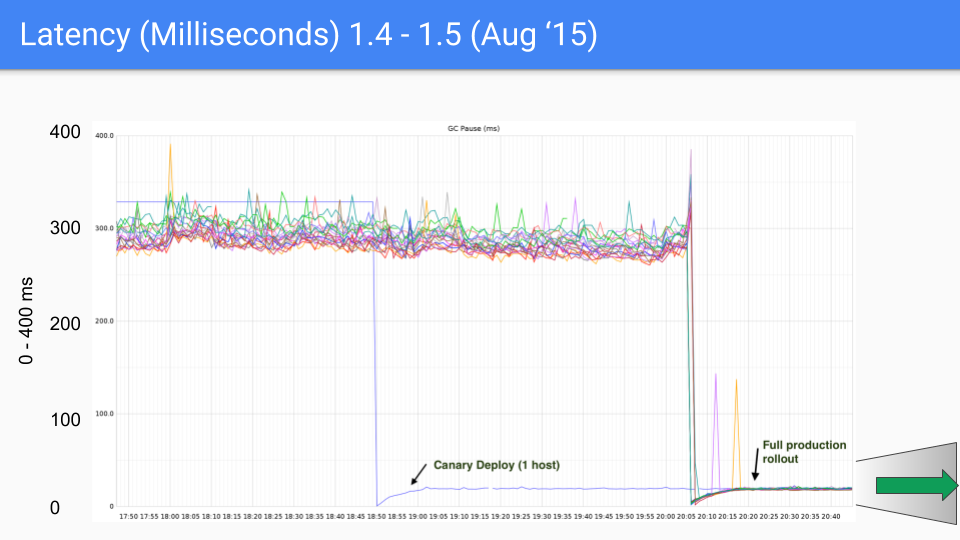
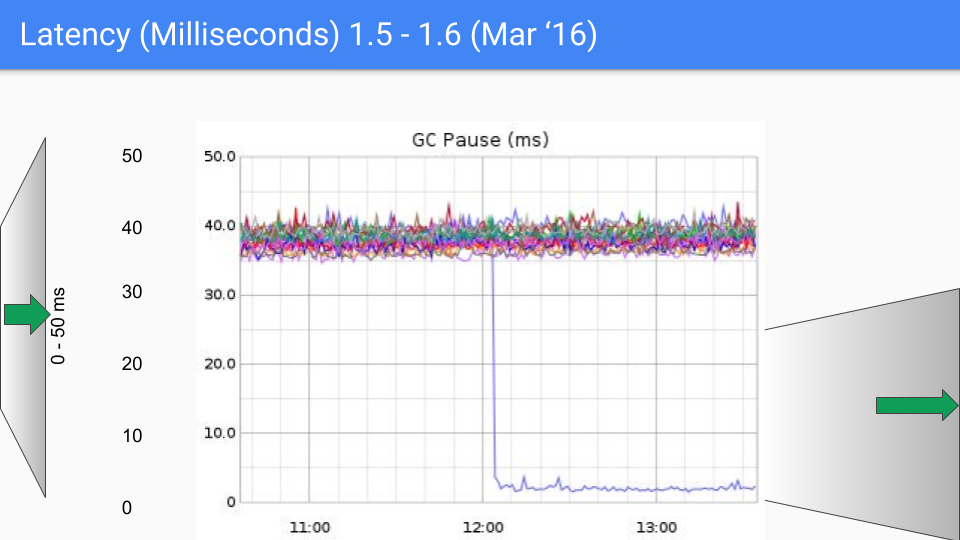
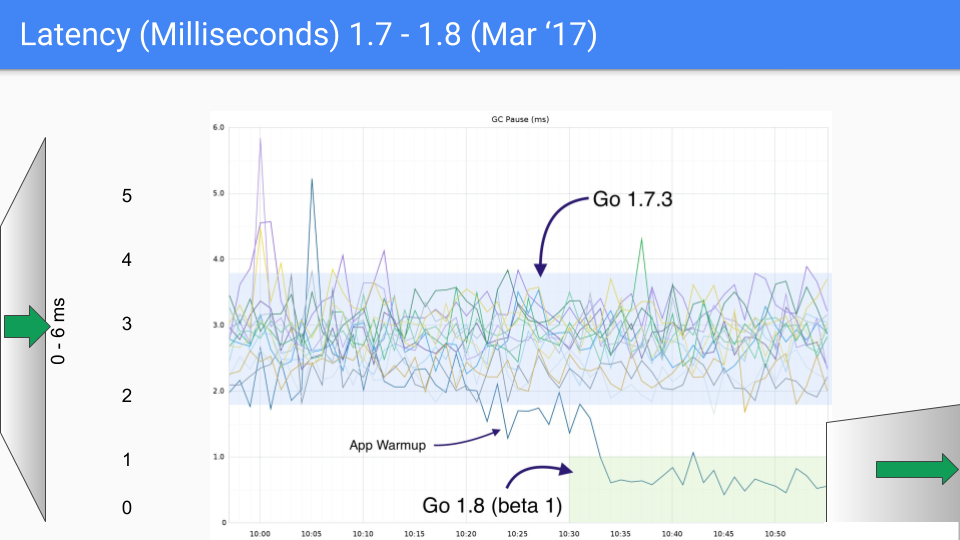
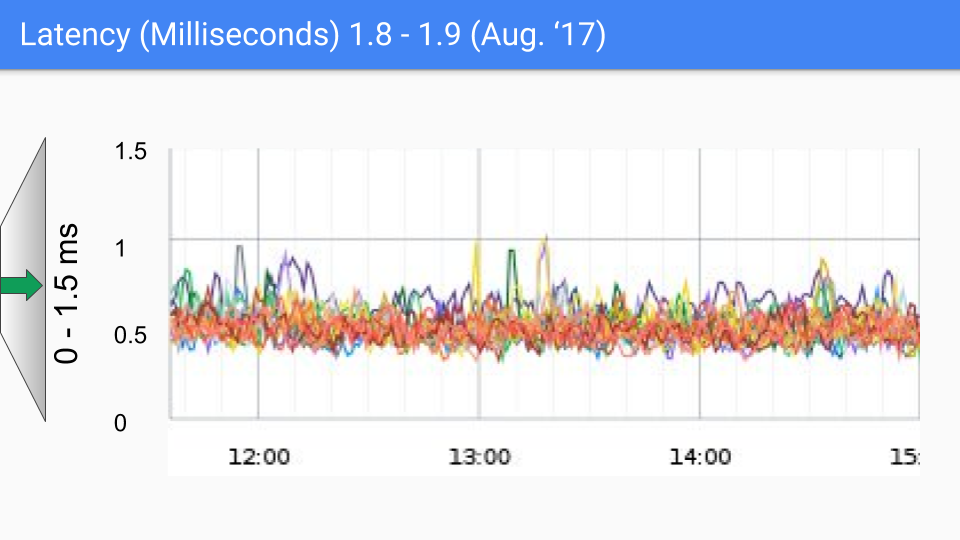
На момент написания этой статьи последняя версия Go приближается к Go 1.23. Для сегодняшнего Go производительность GC больше не вызывает беспокойства. Задержка GC теперь в основном ниже 100 микросекунд, удовлетворяя потребности большинства бизнес-сценариев.
В целом, сборка мусора в Go может быть разделена на следующие этапы:
- Фаза сканирования: Сбор корневых объектов из стека и глобальных переменных
- Фаза маркировки: Раскрашивание объектов
- Фаза завершения маркировки: Обработка работы по очистке, закрытие барьеров
- Фаза очистки: Освобождение и переработка памяти мусорных объектов
Концепции
Следующие концепции могут появляться в официальной документации и статьях, с краткими объяснениями ниже:
- Mutator: Технический термин, относящийся к пользовательским программам. В Go это относится к пользовательскому коду.
- Collector: Относится к программе, ответственной за сборку мусора. В Go это runtime.
- Finalizer: Код, ответственный за переработку и очистку памяти объекта после завершения работы mark-sweep.
- Controller: Относится к глобальной переменной
runtime.gcController, чей тип —gcControllerState. Он реализует алгоритм pacing и отвечает за определение, когда выполнять сборку мусора и сколько работы выполнить. - Limiter: Относится к
runtime.gcCPULimiter, который предотвращает чрезмерное использование CPU во время сборки мусора от влияния на пользовательские программы.
Триггер
func gcStart(trigger gcTrigger)Сборка мусора инициируется функцией runtime.gcStart, которая принимает только структуру runtime.gcTrigger в качестве параметра, содержащую причину запуска GC, текущее время и какой раунд GC это является.
type gcTrigger struct {
kind gcTriggerKind
now int64 // gcTriggerTime: текущее время
n uint32 // gcTriggerCycle: номер цикла для запуска
}Где gcTriggerKind имеет следующие возможные значения:
const (
// gcTriggerHeap указывает, что цикл должен быть запущен, когда
// размер кучи достигает размера триггера кучи, вычисленного контроллером.
gcTriggerHeap gcTriggerKind = iota
// gcTriggerTime указывает, что цикл должен быть запущен, когда
// прошло больше forcegcperiod наносекунд с момента предыдущего цикла GC.
gcTriggerTime
// gcTriggerCycle указывает, что цикл должен быть запущен, если
// мы ещё не запустили цикл номер gcTrigger.n (относительно
// work.cycles).
gcTriggerCycle
)В целом, существует три времени запуска для сборки мусора:
При создании новых объектов: При выделении памяти вызовом
runtime.mallocgc, если обнаруживается, что память кучи достигла порога (обычно в два раза больше размера при предыдущем GC, это значение также корректируется алгоритмом pacing), инициируется сборка мусора.gofunc mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer { ... if shouldhelpgc { if t := (gcTrigger{kind: gcTriggerHeap}); t.test() { gcStart(t) } } ... }Запланированный принудительный триггер: Go запускает отдельную goroutine во время выполнения для запуска функции
runtime.forcegchelper. Если сборка мусора не выполнялась долгое время, она принудительно запускает GC. Это время определяется константойruntime.forcegcperiod, которая равна 2 минутам. Кроме того, goroutine системного мониторинга также периодически проверяет, нужна ли принудительная GC.gofunc forcegchelper() { for { ... gcStart(gcTrigger{kind: gcTriggerTime, now: nanotime()}) ... } }gofunc sysmon() { ... for { ... // проверяем, нужна ли принудительная GC if t := (gcTrigger{kind: gcTriggerTime, now: now}); t.test() && forcegc.idle.Load() { lock(&forcegc.lock) forcegc.idle.Store(false) var list gList list.push(forcegc.g) injectglist(&list) unlock(&forcegc.lock) } } }Ручной триггер: Через функцию
runtime.GCпользователи могут вручную запускать сборку мусора.gofunc GC() { ... n := work.cycles.Load() gcStart(gcTrigger{kind: gcTriggerCycle, n: n + 1}) ... }
TIP
Если интересно, вы можете прочитать Go Gc Pacer Re-Design на английском языке, который объясняет философию дизайна и улучшения алгоритма pacing для запуска GC. Из-за сложного содержания, включающего много математических формул, это не подробно рассматривается в тексте.
Маркировка
Сегодня алгоритм GC в Go всё ещё mark-then-sweep, но его реализация больше не такая простая, как раньше.
Mark-Sweep
Начнём с простейшего алгоритма mark-sweep. В памяти отношения ссылок между объектами образуют граф. Сборка мусора работает с этим графом, разделённым на две фазы:
- Фаза маркировки: Начиная с корневых узлов (корневые узлы обычно являются переменными в стеке, глобальными переменными и другими активными объектами), обходит каждый достижимый узел по одному и помечает их как активные объекты, пока все достижимые узлы не будут обходятся.
- Фаза очистки: Обходит все объекты в куче, перерабатывает непомеченные объекты и освобождает или повторно использует их пространство памяти.
Во время процесса сбора структура графа объектов не может быть изменена, поэтому вся программа должна быть остановлена, что является STW. Только после завершения сбора может продолжить выполнение. Недостаток этого алгоритма в том, что он занимает много времени, что значительно влияет на эффективность выполнения программы. Это был алгоритм маркировки, используемый в ранних версиях Go, и его недостатки очевидны:
- Он производит фрагменты памяти (из-за управления памятью в стиле TCMalloc в Go, влияние фрагментации не значительно)
- Во время фазы маркировки сканируются все объекты в куче
- Он вызывает STW, паузу всей программы, и время не короткое
Трёхцветная маркировка
Для повышения эффективности Go принял классический алгоритм трёхцветной маркировки. Так называемые три цвета относятся к чёрному, серому и белому:
- Чёрный: Объект был посещён во время маркировки, и все объекты, на которые он напрямую ссылается, также были посещены, указывая на активные объекты.
- Серый: Объект был посещён во время маркировки, но объекты, на которые он напрямую ссылается, не все были посещены. Когда все посещены, он становится чёрным, указывая на активные объекты.
- Белый: Объект никогда не был посещён во время маркировки. После посещения он становится серым, указывая, что он может быть мусорным объектом.
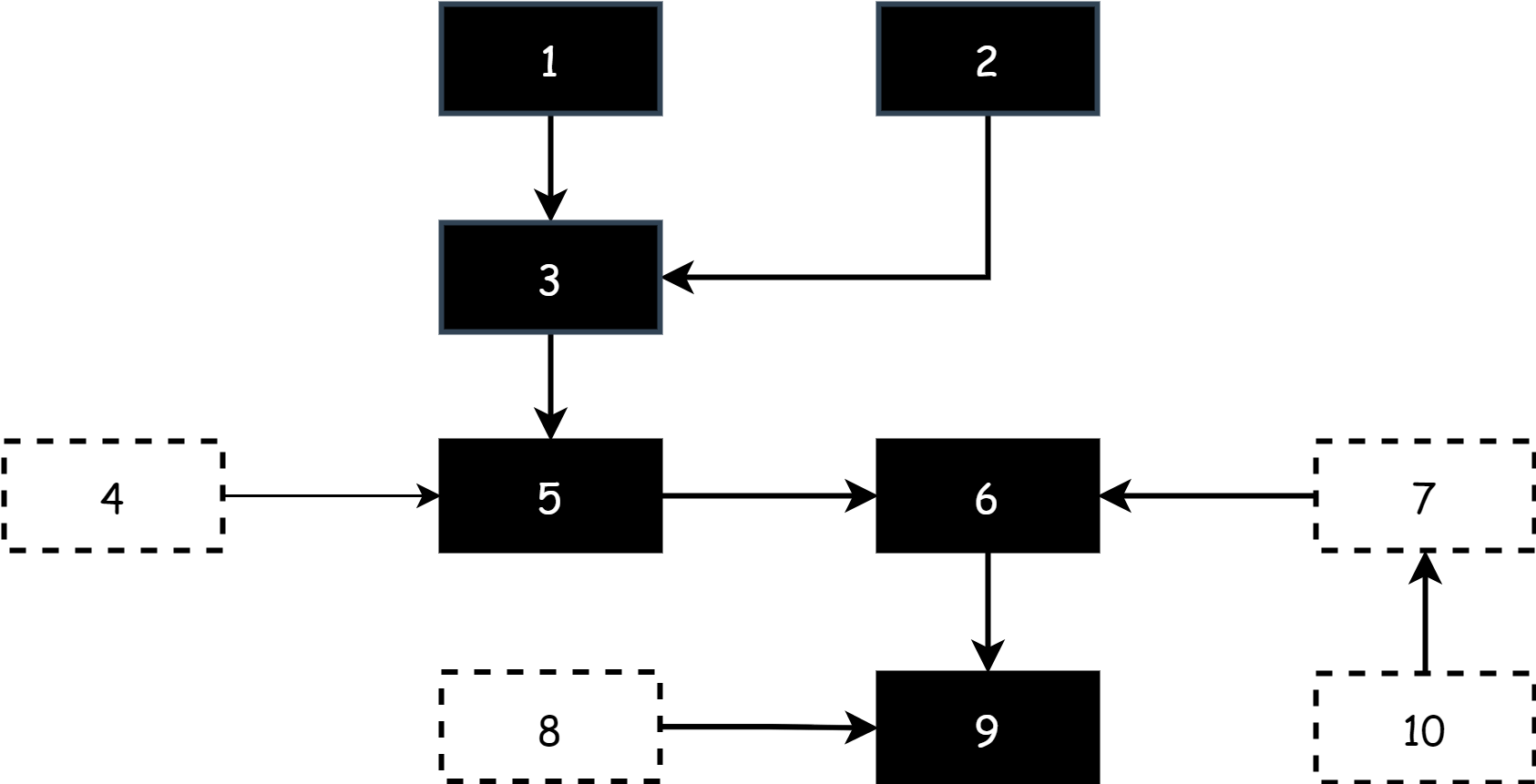
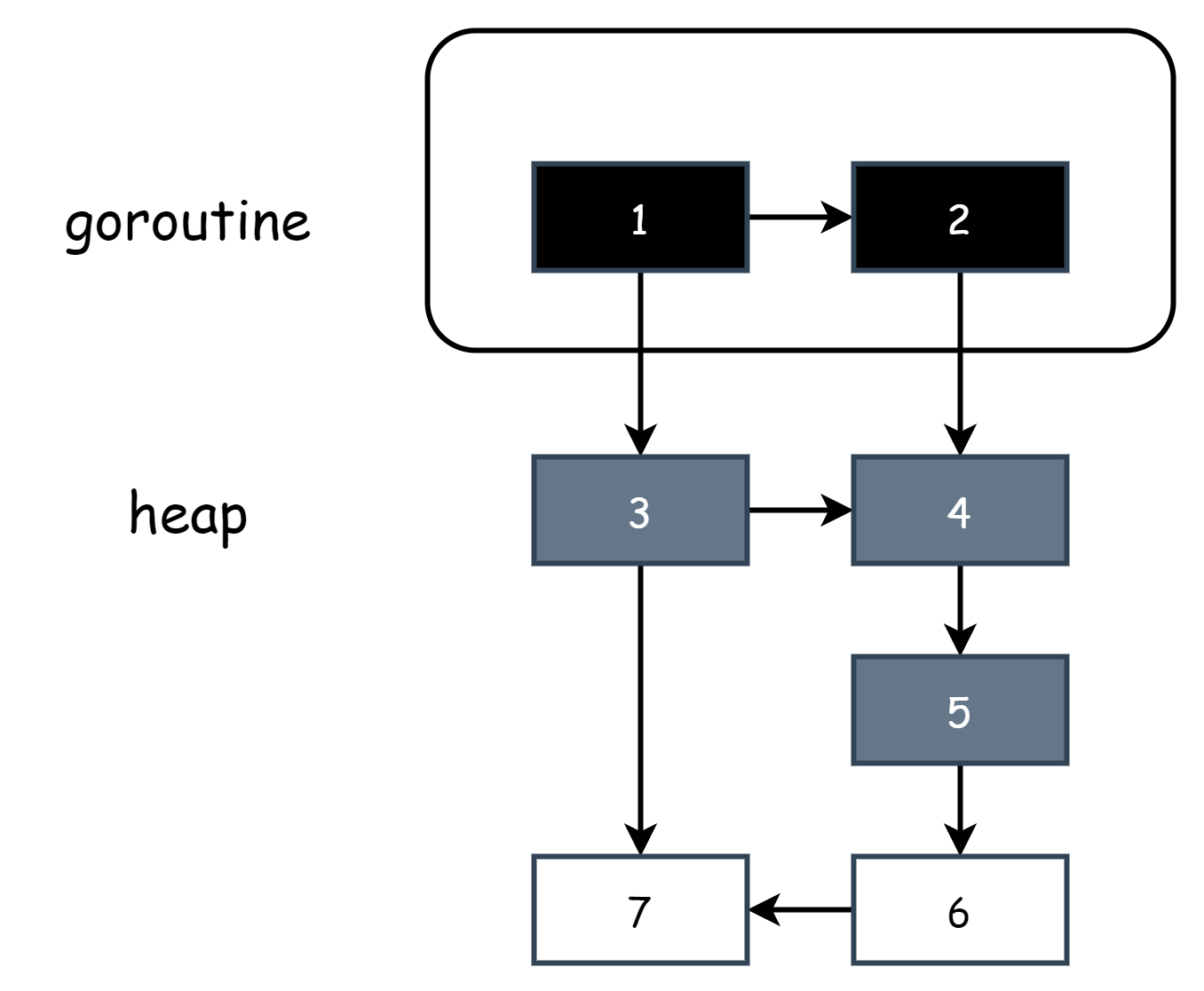
В начале работы трёхцветной маркировки на поле есть только серые и белые объекты. Все корневые объекты серые, а другие объекты белые, как показано ниже.
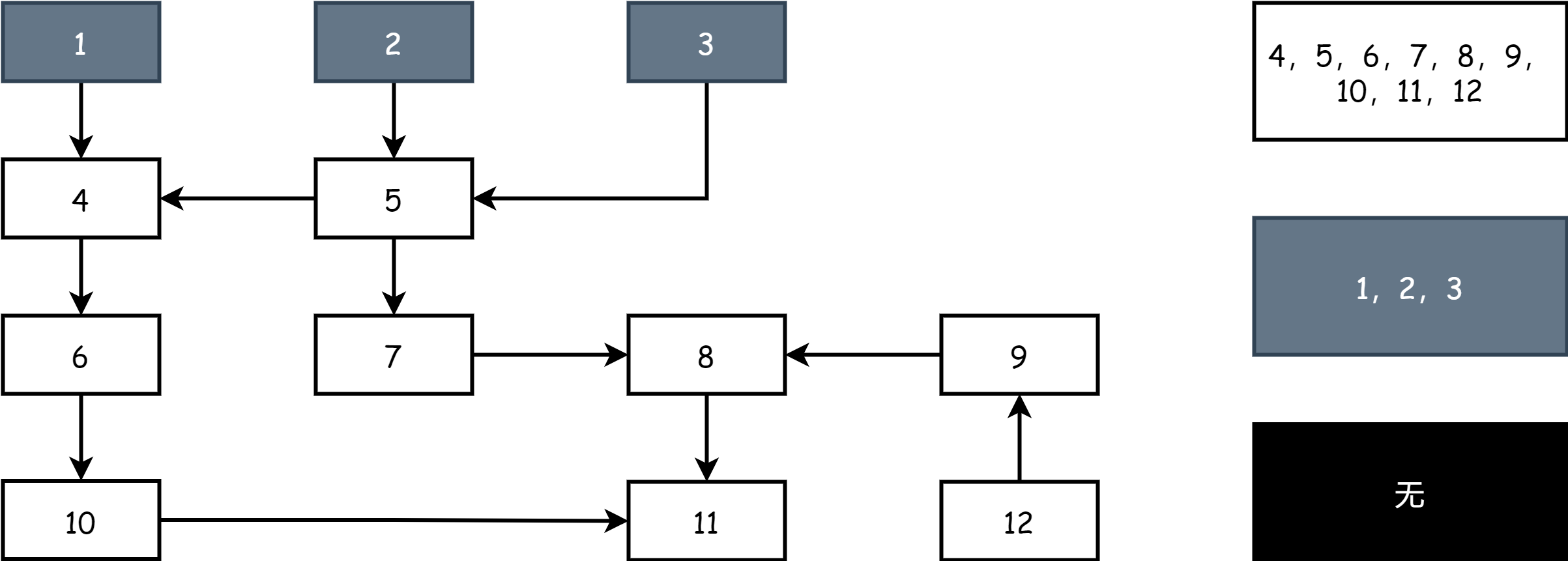
В начале каждого раунда маркировки начинают с серых объектов, помечают серые объекты как чёрные, чтобы указать, что они активные объекты, затем помечают все объекты, на которые напрямую ссылаются чёрные объекты, как серые. Остальные остаются белыми. В этот момент на поле есть чёрные, серые и белые объекты.
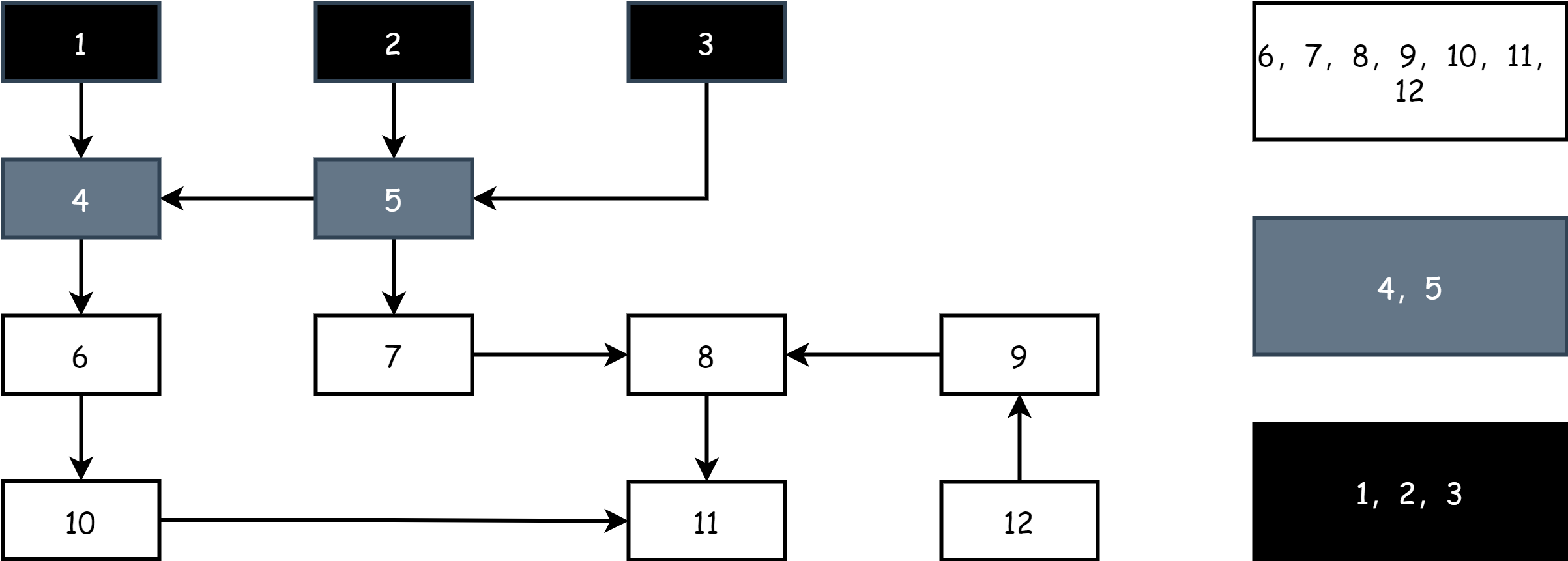
Непрерывно повторяют вышеуказанные шаги, пока на поле не останутся только чёрные и белые объекты. Когда набор серых объектов пуст, это указывает, что маркировка завершена, как показано ниже.
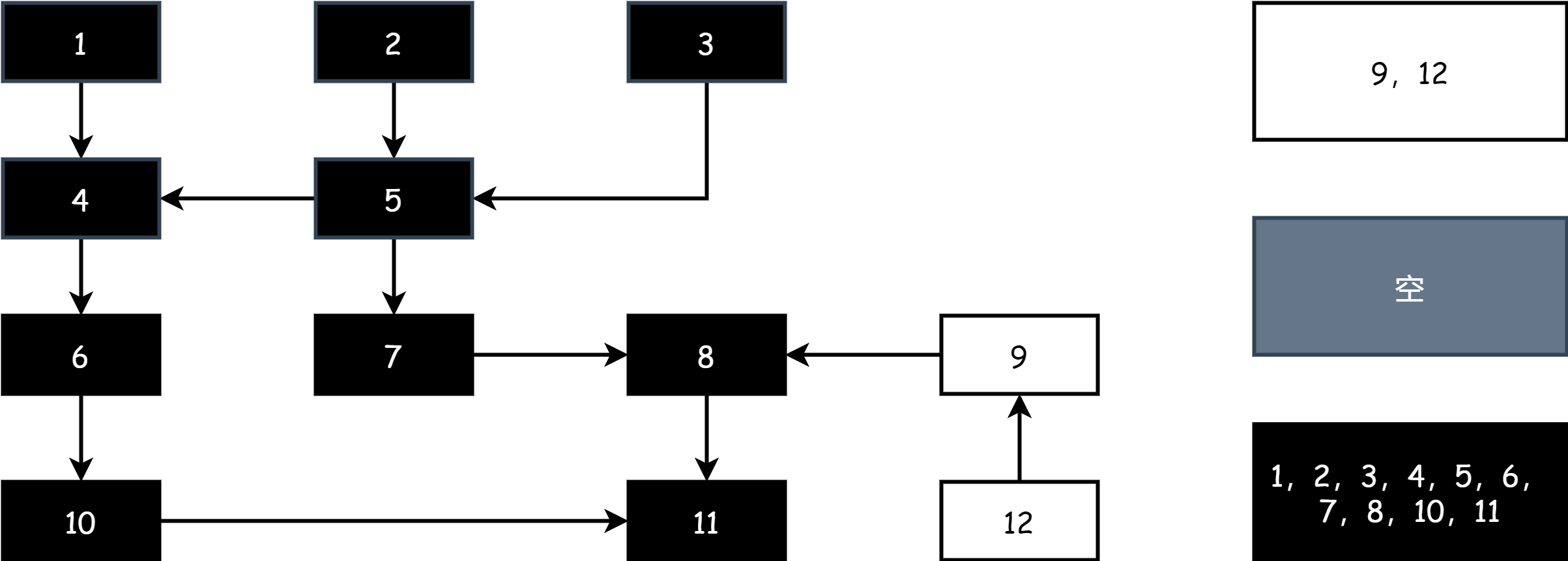
После завершения маркировки, в фазе очистки, просто освобождают память объектов в белом наборе.
Инвариантность
Алгоритм трёхцветной маркировки сам по себе не может выполнять конкурентную маркировку (относящуюся к работе программы во время маркировки). Если структура графа объектов изменяется во время маркировки, это может привести к двум ситуациям:
- Чрезмерная маркировка: После того как объект помечен как чёрный, пользовательская программа удаляет все ссылки на этот объект. Тогда он должен быть белым объектом и нуждается в сборе.
- Недостаточная маркировка: После того как объект помечен как белый, другие объекты в пользовательской программе ссылаются на этот объект. Тогда он должен быть чёрным объектом и не должен собираться.
Первая ситуация приемлема, потому что несобранные объекты могут быть обработаны в следующем раунде сбора. Но вторая ситуация неприемлема. Освобождение памяти объекта, который используется, вызовет серьёзные ошибки программы, которых необходимо избегать.
Концепция трёхцветной инвариантности происходит из статьи Pekka P. Pirinen 1998 года "Barrier Techniques for Incremental Tracing". Она относится к двум инвариантам цветов объектов во время конкурентной маркировки:
- Сильная трёхцветная инвариантность: Чёрные объекты не могут напрямую ссылаться на белые объекты.
- Слабая трёхцветная инвариантность: Когда чёрный объект напрямую ссылается на белый объект, должен быть другой серый объект, который может напрямую или косвенно достичь этого белого объекта, называемый защищённым серым объектом.
Для сильной трёхцветной инвариантности, известно, что чёрный объект 3 — это уже посещённый объект, и его дочерние объекты также были посещены и помечены как серые объекты. Если в этот момент пользовательская программа конкурентно добавляет новую ссылку на белый объект 7 для чёрного объекта 3, нормально белый объект 7 должен быть помечен как серый. Но поскольку чёрный объект 3 уже был посещён, объект 7 не будет посещён, поэтому он всегда остаётся белым объектом и в конечном итоге ошибочно очищается.

Для слабой трёхцветной инвариантности, это на самом деле похоже на сильную трёхцветную инвариантность. Поскольку серые объекты могут напрямую или косвенно достичь белого объекта, во время последующей маркировки он в конечном итоге будет помечен как серый объект, таким образом избегая ошибочного сбора.
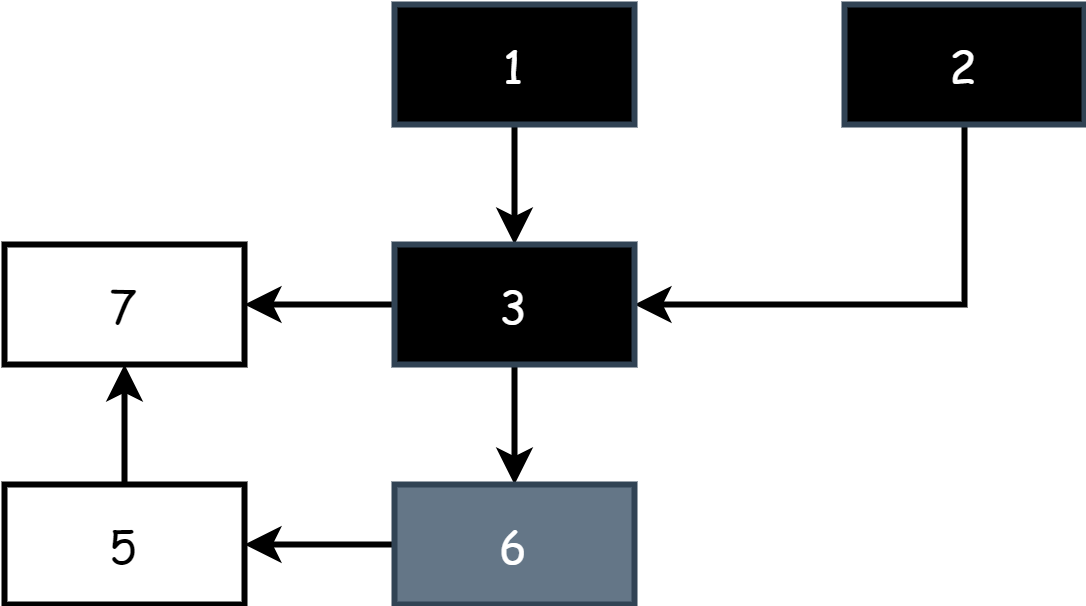
Через инвариантность можно гарантировать, что никакие объекты не будут ошибочно собраны во время маркировки, таким образом гарантируя правильность работы маркировки в конкурентных условиях. Это позволяет трёхцветной маркировке работать конкурентно, значительно повышая эффективность маркировки по сравнению с алгоритмом mark-sweep. Ключ к обеспечению трёхцветной инвариантности в конкурентных условиях лежит в технологии барьеров.
Работа маркировки
Во время фазы сканирования GC существует глобальная переменная runtime.gcphase, используемая для указания статуса GC, со следующими возможными значениями:
_GCoff: Работа маркировки не началась_GCmark: Работа маркировки началась_GCmarktermination: Работа маркировки собирается завершиться
Когда работа маркировки начинается, статус runtime.gcphase — _GCmark. Работа маркировки выполняется функцией runtime.gcDrain, где параметр runtime.gcWork — это пул буферов, хранящий указатели объектов для отслеживания.
func gcDrain(gcw *gcWork, flags gcDrainFlags)Во время работы пытается получить отслеживаемые указатели из пула буферов. Если они есть, вызывает функцию runtime.scanobject для продолжения задачи сканирования. Её роль — непрерывно сканировать объекты в буфере, помечая их чёрным.
if work.full == 0 {
gcw.balance()
}
b := gcw.tryGetFast()
if b == 0 {
b = gcw.tryGet()
if b == 0 {
// Очистить буфер write barrier
// это может создать больше работы.
wbBufFlush()
b = gcw.tryGet()
}
}
if b == 0 {
// Невозможно получить работу.
break
}
scanobject(b, gcw)Работа маркировки останавливается только когда P вытеснен или即将发生 STW.
for !(gp.preempt && (preemptible || sched.gcwaiting.Load() || pp.runSafePointFn != 0)) {
...
scanobject(b, gcw)
...
}runtime.gcwork — это очередь, использующая модель производитель/потребитель. Очередь отвечает за хранение серых объектов для сканирования. Каждый процессор P имеет такую очередь локально, соответствующую полю runtime.p.gcw.
func scanobject(b uintptr, gcw *gcWork) {
...
for {
var addr uintptr
if hbits, addr = hbits.nextFast(); addr == 0 {
if hbits, addr = hbits.next(); addr == 0 {
break
}
}
scanSize = addr - b + goarch.PtrSize
obj := *(*uintptr)(unsafe.Pointer(addr))
if obj != 0 && obj-b >= n {
if obj, span, objIndex := findObject(obj, b, addr-b); obj != 0 {
greyobject(obj, b, addr-b, span, gcw, objIndex)
}
}
}
gcw.bytesMarked += uint64(n)
gcw.heapScanWork += int64(scanSize)
}Функция runitme.scanobject непрерывно помечает достижимые белые объекты как серые во время сканирования, затем помещает их в локальную очередь через gcw.put. Между тем, функция gcDrain непрерывно пытается получить серые объекты через gcw.tryget для продолжения сканирования. Процесс маркировки и сканирования инкрементальный и не нуждается в завершении всей работы маркировки сразу. Когда задачи маркировки вытеснены по какой-либо причине, они прерываются. При возобновлении они могут продолжить работу маркировки на основе оставшихся серых объектов в очереди.
Фоновая маркировка
Работа маркировки не выполняется немедленно при запуске GC. Когда GC впервые запускается, Go создаёт столько задач маркировки, сколько текущее общее количество процессоров P. Они добавляются в глобальную очередь задач и затем входят в сон до пробуждения во время фазы маркировки. Во время выполнения распределение задач выполняется runtime.gcBgMarkStartWorkers. Задача маркировки фактически относится к функции runtime.gcBgMarkWorker, где gcBgMarkWorkerCount и gomaxprocs — две глобальные переменные runtime, представляющие текущее количество работников и количество процессоров P соответственно.
func gcBgMarkStartWorkers() {
// Фоновая маркировка выполняется per-P G. Убедимся, что каждый P имеет
// фоновый GC G.
//
// Worker G не выходят, если gomaxprocs уменьшен. Если он снова
// поднят, мы можем переиспользовать старых работников; не нужно создавать новых.
for gcBgMarkWorkerCount < gomaxprocs {
go gcBgMarkWorker()
notetsleepg(&work.bgMarkReady, -1)
noteclear(&work.bgMarkReady)
// Работник теперь гарантированно добавлен в пул до
// следующего findRunnableGCWorker его P.
gcBgMarkWorkerCount++
}
}После запуска работника создаётся структура runtime.gcBgMarkWorkerNode, добавляется в глобальный пул работников runitme.gcBgMarkWorkerPool, затем вызывается функция runtime.gopark для перевода goroutine в сон.
func gcBgMarkWorker() {
...
node := new(gcBgMarkWorkerNode)
node.gp.set(gp)
notewakeup(&work.bgMarkReady)
for {
// Идём спать до пробуждения
// gcController.findRunnableGCWorker.
gopark(func(g *g, nodep unsafe.Pointer) bool {
node := (*gcBgMarkWorkerNode)(nodep)
// Освобождаем этого G в пул.
gcBgMarkWorkerPool.push(&node.node)
// Заметим, что в этот момент G может немедленно быть
// запланирован и может выполняться.
return true
}, unsafe.Pointer(node), waitReasonGCWorkerIdle, traceBlockSystemGoroutine, 0)
}
...
}Существует две ситуации, которые могут разбудить работников:
- Во время фазы маркировки цикл планирования будит спящих работников через функцию
runtime.runtime.gcController.findRunnableGCWorker. - Во время фазы маркировки, если процессор P в настоящее время в состоянии простоя, цикл планирования пытается напрямую получить доступных работников из глобального пула работников
gcBgMarkWorkerPool.
func findRunnable() (gp *g, inheritTime, tryWakeP bool) {
top:
// Пытаемся запланировать GC работника.
if gcBlackenEnabled != 0 {
gp, tnow := gcController.findRunnableGCWorker(pp, now)
if gp != nil {
return gp, false, true
}
now = tnow
}
...
// Нам нечего делать.
//
// Если мы в фазе маркировки GC, можем безопасно сканировать и чернить объекты,
// и есть работа для выполнения, запускаем маркировку времени простоя вместо того, чтобы отдавать P.
if gcBlackenEnabled != 0 && gcMarkWorkAvailable(pp) && gcController.addIdleMarkWorker() {
node := (*gcBgMarkWorkerNode)(gcBgMarkWorkerPool.pop())
if node != nil {
pp.gcMarkWorkerMode = gcMarkWorkerIdleMode
gp := node.gp.ptr()
trace := traceAcquire()
casgstatus(gp, _Gwaiting, _Grunnable)
if trace.ok() {
trace.GoUnpark(gp, 0)
traceRelease(trace)
}
return gp, false, false
}
gcController.removeIdleMarkWorker()
}
...
}Процессор P имеет поле в своей структуре gcMarkWorkerMode для указания режима выполнения задач маркировки, со следующими возможными значениями:
gcMarkWorkerNotWorker: Указывает, что текущий процессор P не выполняет задачи маркировки.gcMarkWorkerDedicatedMode: Указывает, что текущий процессор P посвящён выполнению задач маркировки и не будет вытеснен в этот период.gcMarkWorkerFractionalMode: Указывает, что текущий процессор выполняет задачи маркировки, потому что утилизация GC не соответствует стандарту (25% — это стандарт). Выполнение может быть вытеснено в этот период. Предполагая, что текущее количество процессоров P равно 5, согласно формуле расчёта, нужен один процессор P, посвящённый задачам маркировки. Утилизация достигла только 20%, и оставшиеся 5% утилизации требуют открытия процессора PFractionalModeдля дополнения. Конкретный код расчёта следующий:gofunc (c *gcControllerState) startCycle(markStartTime int64, procs int, trigger gcTrigger) { ... totalUtilizationGoal := float64(procs) * gcBackgroundUtilization dedicatedMarkWorkersNeeded := int64(totalUtilizationGoal + 0.5) if float64(dedicatedMarkWorkersNeeded) > totalUtilizationGoal { // Слишком много посвящённых работников. dedicatedMarkWorkersNeeded-- } c.fractionalUtilizationGoal = (totalUtilizationGoal - float64(dedicatedMarkWorkersNeeded)) / float64(procs) ... }gcMarkWorkerIdleMode: Указывает, что текущий процессор выполняет задачи маркировки, потому что он простаивает. Выполнение может быть вытеснено в этот период.
Команда Go не хочет, чтобы GC занимал слишком много производительности, таким образом влияя на нормальную работу пользовательских программ. Выполняя работу маркировки согласно этим различным режимам, GC может быть завершён без траты производительности или влияния на пользовательские программы. Стоит отметить, что базовая единица выделения задач маркировки — процессор P, поэтому работа маркировки выполняется конкурентно. Несколько задач маркировки и пользовательские программы выполняются конкурентно, не влияя друг на друга.
Mark Assist
Goroutine G имеет поле gcAssistBytes во время выполнения, здесь называемое GC assist credits. Во время состояния маркировки GC, когда goroutine пытается выделить определённый размер памяти, вычитаются credits, равные размеру выделенной памяти. Если credits отрицательны в этот момент, goroutine должна помочь завершить количественное количество задач сканирования GC для погашения credits. Когда credits положительны, goroutine не нуждается в завершении задач assist маркировки.
Функция для вычитания credits — runtime.deductAssistCredit, которая вызывается перед функцией runtime.mallocgc выделяет память.
func deductAssistCredit(size uintptr) *g {
var assistG *g
if gcBlackenEnabled != 0 {
// Заряжаем текущий пользовательский G за это выделение.
assistG = getg()
if assistG.m.curg != nil {
assistG = assistG.m.curg
}
// Заряжаем выделение против G. Мы учтём
// внутреннюю фрагментацию в конце mallocgc.
assistG.gcAssistBytes -= int64(size)
if assistG.gcAssistBytes < 0 {
// Этот G в долгу. Помогаем GC исправить
// это перед выделением. Это должно произойти
// перед отключением вытеснения.
gcAssistAlloc(assistG)
}
}
return assistG
}Однако, когда goroutine завершает количественное количество assist работы сканирования, она погашает количественные credits текущей goroutine. Функция, фактически отвечающая за assist маркировку — runtime.gcDrainN.
func gcAssistAlloc1(gp *g, scanWork int64) {
...
gcw := &getg().m.p.ptr().gcw
// Работа завершена
workDone := gcDrainN(gcw, scanWork)
...
assistBytesPerWork := gcController.assistBytesPerWork.Load()
gp.gcAssistBytes += 1 + int64(assistBytesPerWork*float64(workDone))
...
}Поскольку сканирование конкурентное, только часть записанной работы от текущей goroutine. Оставшаяся работа погашается другим goroutine по одной согласно порядку очереди assist. Если всё ещё остаётся, добавляется к глобальным credits gcController.assistBytesPerWork.
func gcFlushBgCredit(scanWork int64) {
// Если очередь пуста, напрямую добавляем к глобальным credits
if work.assistQueue.q.empty() {
gcController.bgScanCredit.Add(scanWork)
return
}
assistBytesPerWork := gcController.assistBytesPerWork.Load()
scanBytes := int64(float64(scanWork) * assistBytesPerWork)
lock(&work.assistQueue.lock)
for !work.assistQueue.q.empty() && scanBytes > 0 {
gp := work.assistQueue.q.pop()
if scanBytes+gp.gcAssistBytes >= 0 {
scanBytes += gp.gcAssistBytes
gp.gcAssistBytes = 0
ready(gp, 0, false)
} else {
gp.gcAssistBytes += scanBytes
scanBytes = 0
work.assistQueue.q.pushBack(gp)
break
}
}
// Всё ещё остаётся
if scanBytes > 0 {
assistWorkPerByte := gcController.assistWorkPerByte.Load()
scanWork = int64(float64(scanBytes) * assistWorkPerByte)
gcController.bgScanCredit.Add(scanWork)
}
unlock(&work.assistQueue.lock)
}Соответственно, когда слишком много credits нужно погасить (выделение слишком большой памяти), глобальные credits также могут быть использованы для погашения части собственного долга.
func gcAssistAlloc(gp *g) {
...
assistWorkPerByte := gcController.assistWorkPerByte.Load()
assistBytesPerWork := gcController.assistBytesPerWork.Load()
debtBytes := -gp.gcAssistBytes
scanWork := int64(assistWorkPerByte * float64(debtBytes))
if scanWork < gcOverAssistWork {
scanWork = gcOverAssistWork
debtBytes = int64(assistBytesPerWork * float64(scanWork))
}
// Используем глобальные credits как залог
bgScanCredit := gcController.bgScanCredit.Load()
stolen := int64(0)
if bgScanCredit > 0 {
if bgScanCredit < scanWork {
stolen = bgScanCredit
gp.gcAssistBytes += 1 + int64(assistBytesPerWork*float64(stolen))
} else {
stolen = scanWork
gp.gcAssistBytes += debtBytes
}
gcController.bgScanCredit.Add(-stolen)
scanWork -= stolen
if scanWork == 0 {
return
}
}
...
}Mark assist — это балансирующая мера в условиях высокой нагрузки. Скорость, с которой пользовательские программы выделяют память, намного выше скорости маркировки. На каждый байт выделенной памяти выполняется соответствующее количество работы маркировки.
Завершение маркировки
Когда все достижимые серые объекты были раскрашены в чёрный, состояние переходит от _GCmark к _GCmarktermination. Этот процесс завершается функцией runtime.gcMarkDone. В начале проверяется, есть ли ещё задачи для выполнения.
top:
if !(gcphase == _GCmark && work.nwait == work.nproc && !gcMarkWorkAvailable(nil)) {
return
}
gcMarkDoneFlushed = 0
// Выполняем все операции маркировки, перехваченные write barriers, пакетно
forEachP(waitReasonGCMarkTermination, func(pp *p) {
wbBufFlush1(pp)
pp.gcw.dispose()
if pp.gcw.flushedWork {
atomic.Xadd(&gcMarkDoneFlushed, 1)
pp.gcw.flushedWork = false
}
})
if gcMarkDoneFlushed != 0 {
goto top
}После того как нет глобальных задач и локальных задач для выполнения, вызывается runtime.stopTheWorldWithSema для STW, затем выполняется некоторая работа по очистке.
// Отключаем assist и фоновых работников. Мы должны сделать
// это перед пробуждением заблокированных assist.
atomic.Store(&gcBlackenEnabled, 0)
// Уведомляем CPU limiter, что GC assist теперь прекратятся.
gcCPULimiter.startGCTransition(false, now)
// Пробуждаем все заблокированные assist. Они запустятся, когда мы
// снова запустим мир.
gcWakeAllAssists()
// В режиме STW, повторно включаем пользовательские goroutine. Они будут
// поставлены в очередь для запуска после того, как мы запустим мир.
schedEnableUser(true)
// endCycle зависит от того, что все статистические данные кэша gcWork сброшены.
// Алгоритм завершения выше обеспечил это до
// выделений с момента ragged barrier.
gcController.endCycle(now, int(gomaxprocs), work.userForced)
// Выполняем завершение маркировки. Это перезапустит мир.
gcMarkTermination(stw)Сначала устанавливает runtime.BlackenEnabled в 0, указывая, что работа маркировки закончилась. Уведомляет limiter, что mark assist закончилась, закрывает барьеры памяти, пробуждает все goroutine, спящие из-за assist маркировки, затем повторно пробуждает все пользовательские goroutine. Также собирает различные данные из этого раунда работы сканирования для корректировки алгоритма pacing для следующего раунда сканирования. После завершения работы по очистке вызывается функция runtime.gcSweep для очистки мусорных объектов, затем вызывается runtime.startTheWorldWithSema для возобновления работы программы.
Барьеры
Роль барьеров памяти может быть понята как перехват поведения присваивания объектов, выполнение указанных операций перед присваиванием. Этот код хука обычно вставляется в код компилятором во время компиляции. Как упоминалось ранее, добавление и удаление ссылок на объекты во время трёхцветной маркировки в конкурентных условиях оба вызывают проблемы. Поскольку оба являются операциями записи (удаление — это присваивание нулевого значения), барьеры, перехватывающие их, collectively называются write barriers. Но механизмы барьеров не без затрат. Перехват операций записи памяти вызывает дополнительные накладные расходы, поэтому механизмы барьеров действуют только на кучу. Учитывая сложность реализации и накладные расходы производительности, они не действуют на стеки и регистры.
TIP
Чтобы узнать больше о деталях применения технологии барьеров в Go, посетите Eliminate STW stack rescan, чтобы прочитать оригинальную статью на английском языке. Эта статья ссылается на много содержания из неё.
Insertion Write Barrier
Insertion write barrier был предложен Dijkstra. Он удовлетворяет сильной трёхцветной инвариантности. Когда чёрный объект добавляет новую ссылку на белый объект, insertion write barrier перехватывает эту операцию и помечает белый объект как серый. Это избегает прямого ссылания чёрных объектов на белые объекты, обеспечивая сильную трёхцветную инвариантность. Это довольно легко понять.

Как упоминалось ранее, write barriers не применяются к стекам. Если отношение ссылок стековых объектов изменяется во время конкурентной маркировки, такое как чёрный объект в стеке, ссылающийся на белый объект в куче, для обеспечения правильности стековых объектов, все объекты в стеке могут быть только помечены как серые объекты снова после завершения маркировки, затем отсканированы. Это означает, что один раунд маркировки нуждается в сканировании пространства стека дважды, и второе сканирование требует STW. Если сотни или тысячи стеков goroutine существуют одновременно в программе, время этого процесса сканирования нельзя игнорировать. Согласно официальной статистике, время пересканирования составляет около 10-100 миллисекунд.
Преимущества: STW не требуется во время сканирования.
Недостатки: Требуется второе сканирование пространства стека для обеспечения правильности, требует STW.
Deletion Write Barrier
Deletion write barrier был предложен Yuasa, также известный как snapshot-at-the-beginning barrier. Этот метод требует STW в начале для snapshot записи корневых объектов, и помечает все корневые объекты чёрным и все дочерние объекты первого уровня серым. Таким образом, остальные белые дочерние объекты находятся под защитой серых объектов. Команда Go не напрямую применила deletion write barrier, но выбрала смешать его с insertion write barrier. Поэтому для удобства понимания позже, это всё ещё нужно объяснить здесь. Правило для deletion write barrier для обеспечения правильности в конкурентных условиях: при удалении ссылки на белый объект из серого или белого объекта, белый объект напрямую помечается как серый.
Интерпретируем в двух ситуациях:
- Удаление ссылки серого объекта на белый объект: Поскольку неизвестно, ссылается ли downstream белого объекта чёрным объектом, это действие может отрезать защиту белого объекта серым объектом.
- Удаление ссылки белого объекта на белый объект: Поскольку неизвестно, защищён ли upstream белого объекта серым и ссылается ли downstream чёрным, это действие также может отрезать защиту белого серым.
В любой ситуации deletion write barrier помечает ссыланный белый объект как серый. Это удовлетворяет слабой трёхцветной инвариантности. Это консервативный подход, потому что ситуации upstream и downstream неизвестны. Помечая его как серый, означает, что он больше не рассматривается как мусорный объект. Даже если удаление ссылки делает объект недостижимым (т.е. становится мусорным объектом), он всё ещё помечен как серый. Он будет освобождён в следующем раунде сканирования, что лучше, чем ошибки памяти, вызванные ошибочным сбором объектов.

Преимущества: Поскольку стековые объекты все чёрные, нет нужды во втором сканировании пространства стека.
Недостатки: Требуется STW в начале сканирования для snapshot записи корневых объектов в пространстве стека.
Hybrid Write Barrier
Версия Go 1.8 представила новый механизм барьеров: hybrid write barrier, смесь insertion write barrier и deletion write barrier, комбинирующая преимущества обоих:
- Insertion write barrier не требует STW для snapshot в начале.
- Deletion write barrier не требует STW для второго сканирования пространства стека.
Ниже приведён псевдокод, данный официальными лицами:
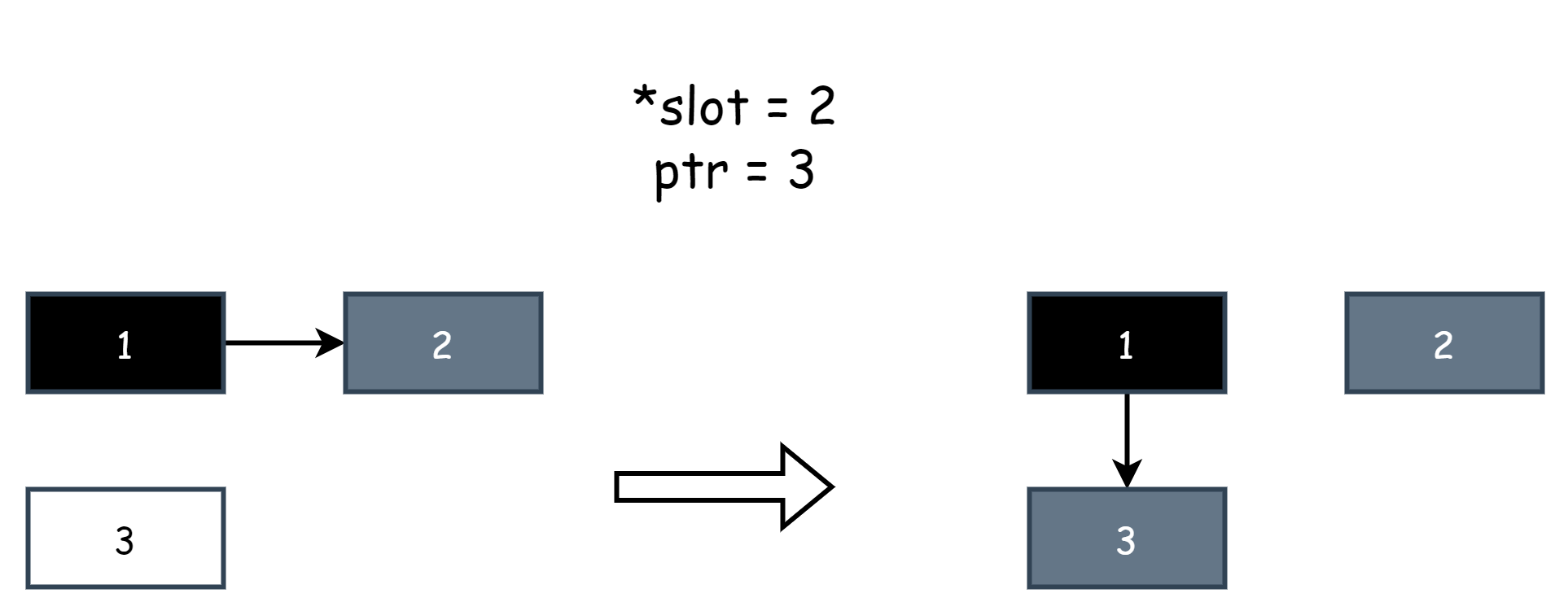
writePointer(slot, ptr):
shade(*slot)
if current stack is grey:
shade(ptr)
*slot = ptrПросто объясним некоторые концепции внутри: slot — указатель, представляющий ссылку на другие объекты, *slot — оригинальный объект, ptr — новый объект, *slot=ptr — операция присваивания, эквивалентна модификации ссылки объекта. Присваивание null — это удаление ссылки. shade() означает помечать объект как серый. shade(*slot) означает помечать оригинальный объект как серый, и shade(ptr) означает помечать новый объект как серый. Ниже приведена примерная диаграмма. Предполагая, что объект 1 изначально ссылается на объект 2, затем пользовательская программа модифицирует ссылку, чтобы объект 1 ссылался на объект 3. Hybrid write barrier захватывает это поведение, где *slot представляет объект 2 и ptr представляет объект 1.
Официальные лица резюмировали эффект вышеуказанного псевдокода в одном предложении:
the write barrier shades the object whose reference is being overwritten, and, if the current goroutine's stack has not yet been scanned, also shades the reference being installed.
В переводе, когда hybrid write barrier перехватывает операцию записи, он помечает оригинальный объект как серый. Если стек текущей goroutine ещё не был отсканирован, он также помечает новый объект как серый.
Когда работа маркировки начинается, пространство стека нуждается в сканировании для сбора корневых объектов. В это время они напрямую помечаются все чёрным. В этот период любые newly created объекты также помечаются чёрным, чтобы обеспечить все объекты в стеке являются чёрными объектами. Поэтому current stack is grey в псевдокоде означает, что стек текущей goroutine ещё не был отсканирован. Поэтому стеки goroutine имеют только два состояния: либо все чёрные, либо все серые. Во время процесса от всех серых к всем чёрным, текущая goroutine нуждается в паузе. Поэтому под hybrid write barrier всё ещё существует локальный STW. Когда стек goroutine весь чёрный, сильная трёхцветная инвариантность должна быть удовлетворена в этот момент. Потому что после сканирования, чёрные объекты в стеке только ссылаются на серые объекты. Не будет ситуации, где чёрные объекты напрямую ссылаются на белые объекты. Поэтому в этот момент insertion write barrier не нужен, соответствует псевдокоду:
if current stack is grey:
shade(ptr)Но deletion write barrier всё ещё нужен для удовлетворения слабой трёхцветной инвариантности, которая:
shade(*slot)После завершения сканирования, поскольку объекты в пространстве стека уже все чёрные, нет нужды во втором сканировании пространства стека, экономя время STW.
В этот момент, который после версии Go 1.8, Go в значительной степени установил основную структуру сборки мусора. Последующие оптимизации версий, связанные со сборкой мусора, также построены на основе hybrid write barrier. Поскольку большинство STW было устранено, средняя задержка сборки мусора была снижена до уровня микросекунд.
Shading Cache
В механизмах барьеров, упомянутых ранее, при перехвате операций записи, цвета объектов помечаются немедленно. После принятия hybrid write barrier, поскольку и оригинальный объект, и новый объект нуждаются в раскрашивании, рабочая нагрузка удваивается, и код, вставленный компилятором, также увеличивается. Для оптимизации, в версии Go 1.10, write barriers больше не помечают цвета объектов немедленно при shading. Вместо этого, оригинальный объект и новый объект хранятся в пуле кэша. После накопления определённого количества, выполняется пакетная маркировка. Это более эффективно.
Структура, ответственная за кэширование — runtime.wbBuf, которая на самом деле является массивом с размером 512.
type wbBuf struct {
next uintptr
end uintptr
buf [wbBufEntries]uintptr
}Каждый P локально имеет такой кэш:
type p struct {
...
wbBuf wbBuf
...
}Во время работы маркировки, если нет доступных серых объектов в очереди gcw, объекты в кэше помещаются в локальную очередь.
func gcDrain(gcw *gcWork, flags gcDrainFlags) {
for !(gp.preempt && (preemptible || sched.gcwaiting.Load() || pp.runSafePointFn != 0)) {
if work.full == 0 {
gcw.balance()
}
b := gcw.tryGetFast()
if b == 0 {
b = gcw.tryGet()
if b == 0 {
// Очистить кэш write barrier
wbBufFlush()
b = gcw.tryGet()
}
}
if b == 0 {
break
}
scanobject(b, gcw)
}
}Другая ситуация — когда происходит завершение маркировки, локальный wbBuf каждого P также проверяется на оставшиеся серые объекты:
func gcMarkDone() {
...
forEachP(waitReasonGCMarkTermination, func(pp *p) {
wbBufFlush1(pp)
pp.gcw.dispose()
})
...
}Очистка
В сборке мусора, самая важная часть — как найти мусорные объекты, что является работой сканирования и маркировки. После завершения работы маркировки, работа очистки относительно менее сложна. Она только нуждается в переработке и освобождении непомеченных объектов. Эта часть кода в основном в файле runtime/mgcsweep.go. Согласно комментариям в файле, алгоритмы очистки Go делятся на два типа.
Очистка объектов
Работа очистки объектов завершается runtime.sweepone во время фазы завершения маркировки. Процесс асинхронный. Во время очистки пытается найти непомеченные объекты в единицах памяти и перерабатывает их. Если вся единица памяти непомечена, тогда вся единица перерабатывается.
func sweepone() uintptr {
sl := sweep.active.begin()
npages := ^uintptr(0)
var noMoreWork bool
for {
s := mheap_.nextSpanForSweep()
if s == nil {
noMoreWork = sweep.active.markDrained()
break
}
if state := s.state.get(); state != mSpanInUse {
continue
}
// Пытаемся получить переработчик
if s, ok := sl.tryAcquire(s); ok {
npages = s.npages
// Очистка
if s.sweep(false) {
mheap_.reclaimCredit.Add(npages)
} else {
npages = 0
}
break
}
}
sweep.active.end(sl)
return npages
}Для алгоритма очистки объектов, переработка всей единицы относительно сложна, поэтому существует второй алгоритм очистки.
Очистка единиц
Работа очистки единиц выполняется перед выделением памяти, завершается методом runtime.mheap.reclaim. Он ищет в куче единицы памяти, где все объекты непомечены, затем перерабатывает всю единицу.
func (h *mheap) reclaim(npage uintptr) {
mp := acquirem()
trace := traceAcquire()
if trace.ok() {
trace.GCSweepStart()
traceRelease(trace)
}
arenas := h.sweepArenas
locked := false
for npage > 0 {
if credit := h.reclaimCredit.Load(); credit > 0 {
take := credit
if take > npage {
take = npage
}
if h.reclaimCredit.CompareAndSwap(credit, credit-take) {
npage -= take
}
continue
}
idx := uintptr(h.reclaimIndex.Add(pagesPerReclaimerChunk) - pagesPerReclaimerChunk)
if idx/pagesPerArena >= uintptr(len(arenas)) {
h.reclaimIndex.Store(1 << 63)
break
}
nfound := h.reclaimChunk(arenas, idx, pagesPerReclaimerChunk)
if nfound <= npage {
npage -= nfound
} else {
h.reclaimCredit.Add(nfound - npage)
npage = 0
}
}
trace = traceAcquire()
if trace.ok() {
trace.GCSweepDone()
traceRelease(trace)
}
releasem(mp)
}Для единиц памяти, существует поле sweepgen, используемое для указания их статуса очистки:
mspan.sweepgen == mheap.sweepgen - 2: Единица памяти нуждается в очистке.mspan.sweepgen == mheap.sweepgen - 1: Единица памяти очищается.mspan.sweepgen == mheap.sweepgen: Единица памяти была очищена и может использоваться нормально.mspan.sweepgen == mheap.sweepgen + 1: Единица памяти в кэше и нуждается в очистке.mspan.sweepgen == mheap.sweepgen + 3: Единица памяти была очищена, но всё ещё в кэше.
mheap.sweepgen увеличивается с каждым раундом GC, и каждый раз увеличивается на 2.