string
string — очень распространённый базовый тип данных в Go, первый тип данных, с которым я столкнулся в языке Go:
package main
import "fmt"
func main() {
fmt.Println("hello,world!")
}Наверное, этот код большинство людей набирало при первом знакомстве с Go. В builtin/builtin.go есть простое описание string:
// string — это набор всех строк из 8-битных байтов, традиционно, но не
// обязательно, представляющих текст в кодировке UTF-8. Строка может быть пустой, но
// не nil. Значения строкового типа неизменяемы.
type string stringИз этого описания можно выделить следующую информацию:
string— это набор 8-битных байтовstringобычно в кодировкеUTF-8stringможет быть пустой, но неnilstringнеизменяема
Эти характеристики хорошо известны тем, кто часто использует Go. Ниже рассмотрим более детально.
Структура
В Go строка во время выполнения представляется структурой runtime.stringStruct, но она не экспортируется. В качестве альтернативы можно использовать reflect.StringHeader.
TIP
Хотя StringHeader устарел в версии go1.21, он очень нагляден, поэтому в дальнейшем изложении будет использоваться он. Это не влияет на понимание, подробности см. в Issues · golang/go (github.com).
// runtime/string.go
type stringStruct struct {
str unsafe.Pointer
len int
}
// reflect/value.go
type StringHeader struct {
Data uintptr
Len int
}Значения полей:
Data— указатель на начальный адрес памяти строкиLen— количество байтов строки
Ниже приведён пример доступа к адресу строки через указатель unsafe:
func main() {
str := "hello,world!"
h := *((*reflect.StringHeader)(unsafe.Pointer(&str)))
for i := 0; i < h.Len; i++ {
fmt.Printf("%s ", string(*((*byte)(unsafe.Add(unsafe.Pointer(h.Data), uintptr(i)*unsafe.Sizeof(str[0]))))))
}
}Теперь Go рекомендует использовать unsafe.StringData вместо этого:
func main() {
str := "hello,world!"
ptr := unsafe.Pointer(unsafe.StringData(str))
for i := 0; i < len(str); i++ {
fmt.Printf("%s ", string(*((*byte)(unsafe.Add(ptr, uintptr(i)*unsafe.Sizeof(str[0]))))))
}
}Оба вывода одинаковы:
h e l l o , w o r l d !
Строка по сути представляет собой непрерывную область памяти, где каждый адрес хранит один байт. Другими словами, это байтовый массив. Результат функции len — количество байтов, а не количество символов в строке. Это особенно важно, когда строка содержит не-ASCII символы.
string сам занимает очень мало памяти — только указатель на реальные данные. Это делает передачу строк очень дешёвой. Поскольку хранится только ссылка на память, если бы строку можно было легко изменять, было бы трудно определить, остаются ли старые данные актуальными (требуется либо рефлексия, либо пакет unsafe). Ещё одно преимущество — врождённая потокобезопасность: в обычных условиях никто не может её изменить.
Конкатенация
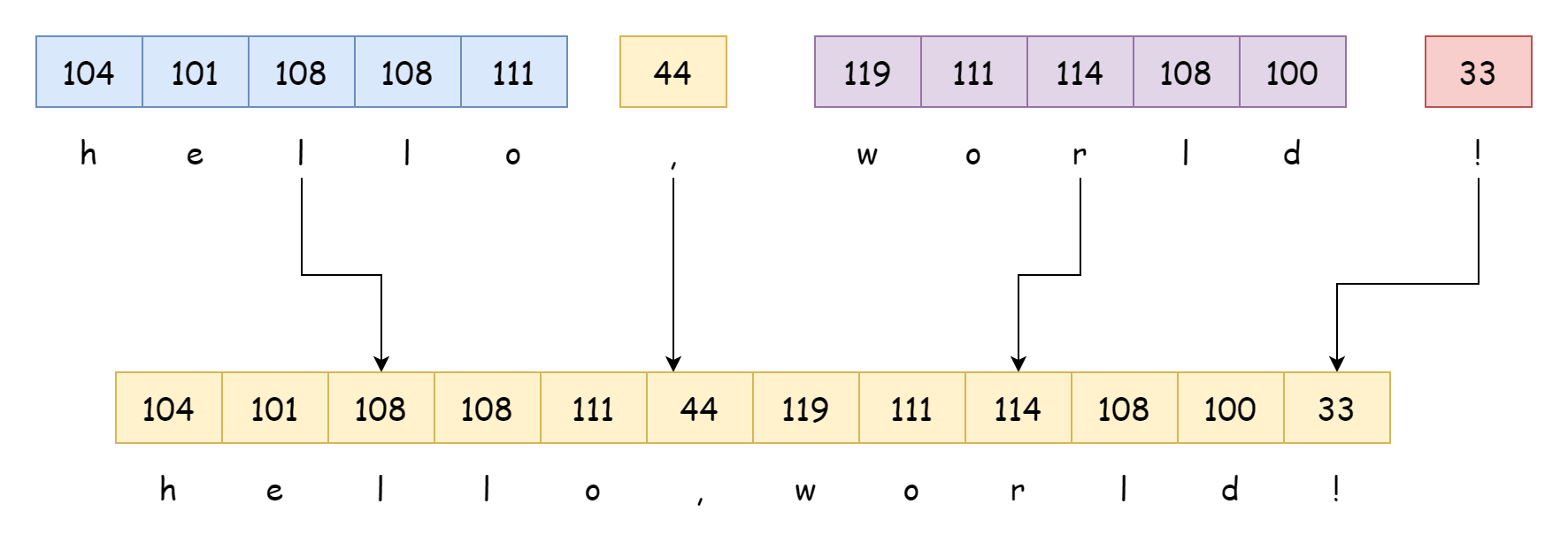
Синтаксис конкатенации строк показан ниже, используется оператор +:
var (
hello = "hello"
dot = ","
world = "world"
last = "!"
)
str := hello + dot + world + lastОперация конкатенации во время выполнения выполняется функцией runtime.concatstrings. Если это конкатенация литералов, как в примере ниже, компилятор напрямую выводит результат:
str := "hello" + "," + "world" + "!"
_ = strВывод ассемблерного кода показывает результат, часть ниже:
LEAQ go:string."hello,world!"(SB), AX
MOVQ AX, main.str(SP)Очевидно, что компилятор рассматривает это как одну完整ную строку, значение которой определяется во время компиляции, а не конкатенируется функцией runtime.concatstrings во время выполнения. Конкатенация переменных строк выполняется во время выполнения. Сигнатура функции принимает байтовый массив и срез строк:
func concatstrings(buf *tmpBuf, a []string) stringКогда количество конкатенируемых строк меньше 5, используются следующие функции вместо (предположение: параметры и анонимные переменные хранятся в стеке, что лучше для GC по сравнению со срезом, созданным во время выполнения?), хотя в конечном итоге конкатенация выполняется concatstrings:
func concatstring2(buf *tmpBuf, a0, a1 string) string {
return concatstrings(buf, []string{a0, a1})
}
func concatstring3(buf *tmpBuf, a0, a1, a2 string) string {
return concatstrings(buf, []string{a0, a1, a2})
}
func concatstring4(buf *tmpBuf, a0, a1, a2, a3 string) string {
return concatstrings(buf, []string{a0, a1, a2, a3})
}
func concatstring5(buf *tmpBuf, a0, a1, a2, a3, a4 string) string {
return concatstrings(buf, []string{a0, a1, a2, a3, a4})
}Рассмотрим, что делает функция concatstrings:
func concatstrings(buf *tmpBuf, a []string) string {
idx := 0
l := 0
count := 0
for i, x := range a {
n := len(x)
// Пропускаем, если длина 0
if n == 0 {
continue
}
// Переполнение при вычислении
if l+n < l {
throw("string concatenation too long")
}
l += n
// Счётчик
count++
idx = i
}
// Возвращаем пустую строку, если нет строк
if count == 0 {
return ""
}
// Возвращаем напрямую, если только одна строка
if count == 1 && (buf != nil || !stringDataOnStack(a[idx]) {
return a[idx]
}
// Выделяем память для новой строки
s, b := rawstringtmp(buf, l)
for _, x := range a {
// Копирование
copy(b, x)
// Усечение
b = b[len(x):]
}
return s
}Сначала выполняется подсчёт общей длины и количества конкатенируемых строк, затем выделяется память согласно общей длине. Функция rawstringtmp возвращает строку s и байтовый срез b. Хотя их длина определена, они не содержат данных, поскольку по сути являются двумя указателями на новые адреса памяти. Код выделения памяти:
func rawstring(size int) (s string, b []byte) {
// Тип не указан
p := mallocgc(uintptr(size), nil, false)
// Память выделена, но пуста
return unsafe.String((*byte)(p), size), unsafe.Slice((*byte)(p), size)
}Возвращаемая строка s удобна для представления, байтовый срез b — для модификации строки. Оба указывают на один и тот же адрес памяти.
for _, x := range a {
// Копирование
copy(b, x)
// Усечение
b = b[len(x):]
}Функция copy во время выполнения вызывает runtime.slicecopy, которая напрямую копирует память из src в адрес dst. После копирования всех строк процесс конкатенации завершается. Если копируемые строки очень велики, этот процесс потребляет значительные ресурсы.
Преобразование
Как упоминалось ранее, строку нельзя изменить. Попытка изменения не пройдёт даже компиляцию, Go выдаст ошибку:
str := "hello" + "," + "world" + "!"
str[0] = '1'cannot assign to string (neither addressable nor a map index expression)Для модификации строки необходимо сначала преобразовать её в байтовый срез []byte, что очень просто:
bs := []byte(str)Внутри вызывается функция runtime.stringtoslicebyte, логика которой очень проста:
func stringtoslicebyte(buf *tmpBuf, s string) []byte {
var b []byte
if buf != nil && len(s) <= len(buf) {
*buf = tmpBuf{}
b = buf[:len(s)]
} else {
b = rawbyteslice(len(s))
}
copy(b, s)
return b
}Если длина строки меньше длины буфера, возвращается байтовый срез буфера, что экономит память при преобразовании небольших строк. Иначе выделяется память, равная длине строки, и строка копируется в новый адрес памяти. Функция rawbyteslice(len(s)) выполняет аналогичную rawstring работу — выделение памяти.
Аналогично, байтовый срез можно легко преобразовать в строку:
str := string([]byte{'h','e','l','l','o'})Внутри вызывается функция runtime.slicebytetostring, тоже легко понимаемая:
func slicebytetostring(buf *tmpBuf, ptr *byte, n int) string {
if n == 0 {
return ""
}
if n == 1 {
p := unsafe.Pointer(&staticuint64s[*ptr])
if goarch.BigEndian {
p = add(p, 7)
}
return unsafe.String((*byte)(p), 1)
}
var p unsafe.Pointer
if buf != nil && n <= len(buf) {
p = unsafe.Pointer(buf)
} else {
p = mallocgc(uintptr(n), nil, false)
}
memmove(p, unsafe.Pointer(ptr), uintptr(n))
return unsafe.String((*byte)(p), n)
}Сначала обрабатываются специальные случаи длины среза 0 и 1, в этих случаях копирование памяти не требуется. Затем, если длина меньше размера буфера, используется память буфера, иначе выделяется новая память. Наконец, memmove напрямую копирует память. Скопированная память не связана с исходной, поэтому её можно свободно изменять.
Стоит отметить, что оба метода преобразования требуют копирования памяти. Если копируемая память очень велика, потребление ресурсов будет значительным. В обновлении до go1.20 пакет unsafe получил новые функции:
// Передаётся указатель типа на адрес памяти и длина данных, возвращается срез
func Slice(ptr *ArbitraryType, len IntegerType) []ArbitraryType
// Передаётся срез, возвращается указатель на базовый массив
func SliceData(slice []ArbitraryType) *ArbitraryType
// По адресу и длине возвращается строка
func String(ptr *byte, len IntegerType) string
// Передаётся строка, возвращается начальный адрес памяти, но байты нельзя изменять
func StringData(str string) *byteОсобенно функции String и StringData не涉及ят копирование памяти и также могут выполнять преобразование. Однако следует убедиться, что данные только для чтения и не будут изменены, иначе строка изменится. Рассмотрим пример:
func main() {
bs := []byte("hello,world!")
s := unsafe.String((*byte)(unsafe.SliceData(bs)), len(bs))
bs[0] = 'b'
fmt.Println(s)
}Сначала через SliceData получается адрес базового массива байтового среза, затем через String — его строковое представление. Последующая модификация байтового среза также изменяет строку, что противоречит初衷 строки. Ещё один пример:
func main() {
str := "hello,world!"
bytes := unsafe.Slice(unsafe.StringData(str), len(str))
fmt.Println(bytes)
// fatal
bytes[0] = 'b'
fmt.Println(str)
}После получения среза строки попытка модификации байтового среза приводит к fatal. Рассмотрим другой способ объявления строки:
func main() {
var str string
fmt.Scanln(&str)
bytes := unsafe.Slice(unsafe.StringData(str), len(str))
fmt.Println(bytes)
bytes[0] = 'b'
fmt.Println(str)
}hello,world!
[104 101 108 108 111 44 119 111 114 108 100 33]
bello,world!Из результата видно, что модификация успешна. Ранее fatal происходило потому, что переменная str хранила строковый литерал. Строковые литералы хранятся в сегменте только для чтения, а не в куче или стеке, что从根本上 исключает возможность последующей модификации строк, объявленных литералами. Для обычной строковой переменной она действительно может быть изменена, но компилятор не разрешает такую запись.总之, использование функций unsafe для преобразования строк небезопасно, если нет гарантии, что данные никогда не будут изменены.
Перебор
s := "hello world!"
for i, r := range s {
fmt.Println(i, r)
}Для обработки многобайтовых символов при переборе строк обычно используется цикл for range. При переборе строки через for range компилятор во время компиляции разворачивает это в следующий код:
ha := s
for hv1 := 0; hv1 < len(ha); {
hv1t := hv1
hv2 := rune(ha[hv1])
// Проверка, является ли символ однобайтовым
if hv2 < utf8.RuneSelf {
hv1++
} else {
hv2, hv1 = decoderune(ha, hv1)
}
i, r = hv1t, hv2
// Тело цикла
}В развёрнутом коде цикл for range заменяется классическим циклом for. В цикле проверяется, является ли текущий байт однобайтовым символом. Если это многобайтовый символ, вызывается функция времени выполнения runtime.decoderune для получения полной кодировки, затем присваивается i, r. После обработки выполняется тело цикла, определённое в исходном коде.
Работа по построению промежуточного кода выполняется функцией walkRange из cmd/compile/internal/walk/range.go, которая также обрабатывает все типы, перебираемые через for range. Здесь это не развёрнуто, при желании можно изучить самостоятельно.