CGO
Поскольку Go требует сборки мусора, для сценариев с высокими требованиями к производительности Go может быть не совсем подходящим. C как традиционный язык системного программирования обладает отличной производительностью, а CGO связывает их вместе, позволяя взаимные вызовы. Go вызывает C для выполнения задач, чувствительных к производительности, в то время как Go обрабатывает логику верхнего уровня. CGO также поддерживает вызовы C в Go, но такие сценарии встречаются реже и не рекомендуются.
TIP
Код в статье демонстрируется в среде Windows 10, командная строка — git bash. Пользователям Windows рекомендуется заранее установить MinGW.
О CGO есть простое введение на официальном сайте: C? Go? Cgo! - The Go Programming Language. Для более подробной информации можно обратиться к стандартной библиотеке cmd/cgo/doc.go или документации cgo command - cmd/cgo - Go Packages — содержание одинаково.
Вызов кода
Рассмотрим пример:
package main
//#include <stdio.h>
import "C"
func main() {
C.puts(C.CString("hello, cgo!"))
}Для использования CGO достаточно импортировать import "C". Обратите внимание: C должно быть заглавной буквой, имя импорта нельзя переопределить, и необходимо убедиться, что переменная окружения CGO_ENABLED установлена в 1. По умолчанию эта переменная включена.
$ go env | grep CGO
$ go env -w CGO_ENABLED=1Кроме того, необходимо иметь локальный инструмент сборки C/C++, т.е. gcc. На Windows это MinGW, чтобы программа могла успешно компилироваться. Выполните следующие команды для компиляции. При включённом CGO время компиляции больше, чем у чистого Go.
$ go build -o ./ main.go
$ ./main.exe
hello, cgo!Также обратите внимание: при включённом CGO кросс-компиляция невозможна.
Встраивание C-кода в Go
CGO позволяет встраивать C-код непосредственно в исходный файл Go. В примере ниже создаётся функция printSum, которая вызывается в функции main:
package main
/*
#include <stdio.h>
void printSum(int a, int b) {
printf("c:%d+%d=%d",a,b,a+b);
}
*/
import "C"
func main() {
C.printSum(C.int(1), C.int(2))
}Вывод:
c:1+2=3Это подходит для простых сценариев. Если C-кода очень много и он перемешан с Go-кодом, это снижает читаемость.
Обработка ошибок
В Go обработка ошибок осуществляется через возвращаемые значения, но C не поддерживает множественные возвращаемые значения. Для этого используется errno из C, указывающий на ошибку во время вызова функции. CGO адаптировал это: при вызове C-функции можно обрабатывать ошибки аналогично Go. Для использования errno необходимо включить errno.h. Пример:
package main
/*
#include <stdio.h>
#include <stdint.h>
#include <errno.h>
int32_t sum_positive(int32_t a, int32_t b) {
if (a <= 0 || b <= 0) {
errno = EINVAL;
return 0;
}
return a + b;
}
*/
import "C"
import (
"fmt"
"reflect"
)
func main() {
sum, err := C.sum_positive(C.int32_t(0), C.int32_t(1))
if err != nil {
fmt.Println(reflect.TypeOf(err))
fmt.Println(err)
return
}
fmt.Println(sum)
}Вывод:
syscall.Errno
The device does not recognize the command.Тип ошибки — syscall.Errno. В errno.h определено множество других кодов ошибок.
Импорт C-файлов в Go
Через импорт C-файлов можно решить проблему перемешивания кода. Сначала создайте заголовочный файл sum.h:
int sum(int a, int b);Затем создайте sum.c с реализацией:
#include "sum.h"
int sum(int a, int b) {
return a + b;
}В main.go импортируйте заголовочный файл:
package main
//#include "sum.h"
import "C"
import "fmt"
func main() {
res := C.sum(C.int(1), C.int(2))
fmt.Printf("cgo sum: %d\n", res)
}При компиляции необходимо указать текущую папку, иначе файл не будет найден:
$ go build -o sum.exe . && ./sum.exe
cgo sum: 3В коде res — переменная Go, C.sum — функция C. Её возвращаемое значение — int из C, а не из Go. Успешный вызов возможен благодаря преобразованию типов CGO.
Вызов Go из C
Вызов Go из C означает вызов Go-функций из C в контексте CGO, а не нативный C, вызывающий Go. Цепочка вызовов: go-cgo-c->cgo->go. Go вызывает C для использования его экосистемы и производительности. Практически нет сценариев, где нативный C вызывает Go. Если такая необходимость возникает, рекомендуется использовать сетевую коммуникацию.
CGO позволяет экспортировать Go-функции для вызова из C. Для экспорта функции необходимо добавить комментарий //export func_name над сигнатурой функции, и параметры/возвращаемые значения должны быть поддерживаемыми типами CGO. Пример:
//export sum
func sum(a, b C.int32_t) C.int32_t {
return a + b
}Измените файл sum.c:
#include <stdint.h>
#include <stdio.h>
#include "sum.h"
#include "_cgo_export.h"
extern int32_t sum(int32_t a, int32_t b);
void do_sum() {
int32_t a = 10;
int32_t b = 10;
int32_t c = sum(a, b);
printf("%d", c);
}Измените заголовочный файл sum.h:
void do_sum();Экспортируйте функцию в Go:
package main
/*
#include <stdio.h>
#include <stdint.h>
#include "sum.h"
*/
import "C"
func main() {
C.do_sum()
}
//export sum
func sum(a, b C.int32_t) C.int32_t {
return a + b
}Функция sum, используемая в C, фактически предоставлена Go. Вывод:
20Ключевой момент — импорт _cgo_export.h в файле sum.c, который содержит все экспортируемые типы Go. Без этого импорта функции Go недоступны. Обратите внимание: _cgo_export.h нельзя импортировать в файлы Go, так как этот заголовочный файл генерируется после успешной компиляции всех исходных файлов Go. Поэтому следующая запись неверна:
package main
/*
#include <stdint.h>
#include <stdio.h>
#include "_cgo_export.h"
void do_sum() {
int32_t a = 10;
int32_t b = 10;
int32_t c = sum(a, b);
printf("%d", c);
}
*/
import "C"
func main() {
C.do_sum()
}
//export sum
func sum(a, b C.int32_t) C.int32_t {
return a + b
}Компилятор сообщит, что заголовочный файл не существует:
fatal error: _cgo_export.h: No such file or directory
#include "_cgo_export.h"
^~~~~~~~~~~~~~~
compilation terminated.Если Go-функция имеет несколько возвращаемых значений, C вернёт структуру.
Кстати, можно передать указатель Go через параметр C-функции. Во время вызова C-функции CGO старается гарантировать безопасность памяти, но возвращаемое значение экспортированной Go-функции не должно содержать указателей. В этом случае CGO не может определить, есть ли ссылки, и сложно зафиксировать память. Если возвращаемая память ссылается на что-то, а затем эта память собирается GC в Go или смещается, указатель станет недействительным:
//export newCharPtr
func newCharPtr() *C.char {
return new(C.char)
}Такая запись по умолчанию не пройдёт компиляцию. Для отключения проверки можно установить:
GODEBUG=cgocheck=0Существует два уровня проверки: 1 и 2. Чем выше уровень, тем больше накладных расходов во время выполнения. Подробнее: cgo command - passing_pointer.
Преобразование типов
CGO предоставляет映射 типов между C и Go для удобства вызова. Для типов C после импорта import "C" в большинстве случаев можно получить доступ через:
C.typenameНапример:
C.int(1)
C.char('a')Но типы C могут состоять из нескольких ключевых слов, например:
unsigned charВ этом случае нельзя получить доступ напрямую. Можно использовать ключевое слово typedef из C для создания псевдонима типа, аналогично псевдонимам типов в Go:
typedef unsigned char byte;Теперь можно использовать C.byte для доступа к типу unsigned char. Пример:
package main
/*
#include <stdio.h>
typedef unsigned char byte;
void printByte(byte b) {
printf("%c\n",b);
}
*/
import "C"
func main() {
C.printByte(C.byte('a'))
C.printByte(C.byte('b'))
C.printByte(C.byte('c'))
}Вывод:
a
b
cВ большинстве случаев CGO уже предоставил псевдонимы для распространённых типов (базовых типов и т.д.). Можно также определить собственные псевдонимы по приведённому методу без конфликтов.
char
char из C соответствует int8 в Go, unsigned char — uint8 (или byte) в Go.
package main
/*
#include <stdio.h>
#include <complex.h>
char ch;
char get() {
return ch;
}
void set(char c) {
ch = c;
}
*/
import "C"
import (
"fmt"
"reflect"
)
func main() {
C.set(C.char('c'))
res := C.get()
fmt.Printf("type: %s, val: %v", reflect.TypeOf(res), res)
}Вывод:
type: main._Ctype_char, val: 99Если передать C.char(math.MaxInt8 + 1) в параметр set, компиляция завершится ошибкой:
cannot convert math.MaxInt8 + 1 (untyped int constant 128) to type _Ctype_charСтроки
CGO предоставляет псевдофункции для передачи строк и байтовых срезов между C и Go. Эти функции фактически не существуют, их определения нельзя найти, как и пакет C в import "C". Они предназначены для удобства разработчика и преобразуются в другие операции после компиляции.
// Go string to C string
// The C string is allocated in the C heap using malloc.
// It is the caller's responsibility to arrange for it to be
// freed, such as by calling C.free (be sure to include stdlib.h
// if C.free is needed).
func C.CString(string) *C.char
// Go []byte slice to C array
// The C array is allocated in the C heap using malloc.
// It is the caller's responsibility to arrange for it to be
// freed, such as by calling C.free (be sure to include stdlib.h
// if C.free is needed).
func C.CBytes([]byte) unsafe.Pointer
// C string to Go string
func C.GoString(*C.char) string
// C data with explicit length to Go string
func C.GoStringN(*C.char, C.int) string
// C data with explicit length to Go []byte
func C.GoBytes(unsafe.Pointer, C.int) []byteСтрока в Go по сути является структурой, содержащей ссылку на базовый массив. При передаче в C-функцию необходимо использовать C.CString() для создания «строки» в C через malloc, выделения памяти и возврата C-указателя. Поскольку в C нет типа строки, обычно используется char* — указатель на массив символов. После использования необходимо освободить память через free.
package main
/*
#include <stdio.h>
#include <stdlib.h>
void printfGoString(char* s) {
puts(s);
}
*/
import "C"
import "unsafe"
func main() {
cstring := C.CString("this is a go string")
C.printfGoString(cstring)
C.free(unsafe.Pointer(cstring))
}Можно также использовать массив типа char — оба варианта являются указателями на первый элемент.
void printfGoString(char s[]) {
puts(s);
}Можно передавать байтовые срезы. Поскольку C.CBytes() возвращает unsafe.Pointer, перед передачей в C-функцию необходимо преобразовать его в *C.char:
package main
/*
#include <stdio.h>
#include <stdlib.h>
void printfGoString(char* s) {
puts(s);
}
*/
import "C"
import "unsafe"
func main() {
cbytes := C.CBytes([]byte("this is a go string"))
C.printfGoString((*C.char)(cbytes))
C.free(unsafe.Pointer(cbytes))
}Вывод во всех случаях одинаков:
this is a go stringЭти методы передачи строк включают копирование памяти: после передачи существуют отдельные копии в памяти C и Go, что безопаснее. Тем не менее, можно напрямую передать указатель в C-функцию и даже изменить строку Go из C. Пример:
package main
/*
#include <stdio.h>
#include <stdlib.h>
void printfGoString(char* s) {
puts(s);
}
*/
import "C"
import "unsafe"
func main() {
ptr := unsafe.Pointer(unsafe.SliceData([]byte("this is a go string")))
C.printfGoString((*C.char)(ptr))
}Вывод:
this is a go stringВ примере через unsafe.SliceData получается указатель на базовый массив строки, преобразуется в C-указатель и передаётся в C-функцию. Памятью управляет Go, поэтому free не требуется. Преимущество — отсутствие копирования при передаче, но есть риски. Пример изменения строки Go из C:
package main
/*
#include <stdio.h>
#include <stdlib.h>
void printfGoString(char* s, int len) {
puts(s);
s[8] = 'c';
puts(s);
}
*/
import "C"
import (
"fmt"
"unsafe"
)
func main() {
var buf []byte
buf = []byte("this is a go string")
ptr := unsafe.Pointer(unsafe.SliceData(buf))
C.printfGoString((*C.char)(ptr), C.int(len(buf)))
fmt.Println(string(buf))
}Вывод:
this is a go string
this is c go string
this is c go stringЦелые числа
Соответствие целых чисел между Go и C:
| Go | C | CGO |
|---|---|---|
| int8 | signed char | C.schar |
| uint8 | unsigned char | C.uchar |
| int16 | short | C.short |
| uint16 | unsigned short | C.ushort |
| int32 | int | C.int |
| uint32 | unsigned int | C.uint |
| int32 | long | C.long |
| uint32 | unsigned long | C.ulong |
| int64 | long long int | C.longlong |
| uint64 | unsigned long long int | C.ulonglong |
Пример кода:
package main
/*
#include <stdio.h>
void printGoInt8(signed char n) {
printf("%d\n",n);
}
void printGoUInt8(unsigned char n) {
printf("%d\n",n);
}
void printGoInt16(signed short n) {
printf("%d\n",n);
}
void printGoUInt16(unsigned short n) {
printf("%d\n",n);
}
void printGoInt32(signed int n) {
printf("%d\n",n);
}
void printGoUInt32(unsigned int n) {
printf("%d\n",n);
}
void printGoInt64(signed long long int n) {
printf("%ld\n",n);
}
void printGoUInt64(unsigned long long int n) {
printf("%ld\n",n);
}
*/
import "C"
func main() {
C.printGoInt8(C.schar(1))
C.printGoInt8(C.schar(1))
C.printGoInt16(C.short(1))
C.printGoUInt16(C.ushort(1))
C.printGoInt32(C.int(1))
C.printGoUInt32(C.uint(1))
C.printGoInt64(C.longlong(1))
C.printGoUInt64(C.ulonglong(1))
}CGO также поддерживает целочисленные типы из <stdint.h>. Эти типы имеют более явный размер памяти и стиль именования, схожий с Go:
| Go | C | CGO |
|---|---|---|
| int8 | int8_t | C.int8_t |
| uint8 | uint8_t | C.uint8_t |
| int16 | int16_t | C.int16_t |
| uint16 | uint16_t | C.uint16_t |
| int32 | int32_t | C.int32_t |
| uint32 | uint32_t | C.uint32_t |
| int64 | int64_t | C.int64_t |
| uint64 | uint64_t | C.uint64_t |
При использовании CGO рекомендуется использовать целочисленные типы из <stdint.h>.
Числа с плавающей точкой
Соответствие типов с плавающей точкой:
| Go | C | CGO |
|---|---|---|
| float32 | float | C.float |
| float64 | double | C.double |
Пример:
package main
/*
#include <stdio.h>
void printGoFloat32(float n) {
printf("%f\n",n);
}
void printGoFloat64(double n) {
printf("%lf\n",n);
}
*/
import "C"
func main() {
C.printGoFloat32(C.float(1.11))
C.printGoFloat64(C.double(3.14))
}Срезы
Срезы аналогичны строкам, описанным выше, но CGO не предоставляет псевдофункций для копирования срезов. Для доступа C к срезу Go необходимо передать указатель среза. Пример:
package main
/*
#include <stdio.h>
#include <stdint.h>
void printInt32Arr(int32_t* s, int32_t len) {
for (int32_t i = 0; i < len; i++) {
printf("%d ", s[i]);
}
}
*/
import "C"
import (
"unsafe"
)
func main() {
var arr []int32
for i := 0; i < 10; i++ {
arr = append(arr, int32(i))
}
ptr := unsafe.Pointer(unsafe.SliceData(arr))
C.printInt32Arr((*C.int32_t)(ptr), C.int(len(arr)))
}Вывод:
0 1 2 3 4 5 6 7 8 9Здесь указатель на базовый массив среза передаётся в C-функцию. Поскольку памятью управляет Go, не рекомендуется, чтобы C долго хранил ссылку на этот указатель. Обратный пример — использование массива C как базового массива среза Go:
package main
/*
#include <stdio.h>
#include <stdint.h>
int32_t s[] = {1, 2, 3, 4, 5, 6, 7};
*/
import "C"
import (
"fmt"
"unsafe"
)
func main() {
l := unsafe.Sizeof(C.s) / unsafe.Sizeof(C.s[0])
fmt.Println(l)
goslice := unsafe.Slice(&C.s[0], l)
for i, e := range goslice {
fmt.Println(i, e)
}
}Вывод:
7
0 1
1 2
2 3
3 4
4 5
5 6
6 7Функция unsafe.Slice преобразует указатель на массив в срез. Интуитивно кажется, что массив C — это просто указатель на первый элемент, и следует использовать:
goslice := unsafe.Slice(&C.s, l)Но при таком подходе, кроме первого элемента, вся остальная память выходит за границы:
0 [1 2 3 4 5 6 7]
1 [0 -1 0 0 0 3432824 0]
2 [0 0 -1 -1 0 0 -1]
3 [0 0 0 255 0 0 0]
4 [2 0 0 0 3432544 0 0]
5 [0 3432576 0 3432592 0 3432608 0]
6 [0 0 3432624 0 0 0 1422773729]Хотя массив C — это указатель на первый элемент, после обёртки CGO он становится массивом Go с собственным адресом. Поэтому следует брать адрес первого элемента:
goslice := unsafe.Slice(&C.s[0], l)Структуры
Для доступа к структурам C используется префикс C.struct_ с именем структуры. Структуры C нельзя встраивать как анонимные в структуры Go. Пример:
package main
/*
#include <stdio.h>
#include <stdint.h>
struct person {
int32_t age;
char* name;
};
*/
import "C"
import (
"fmt"
"reflect"
)
func main() {
var p C.struct_person
p.age = C.int32_t(18)
p.name = C.CString("john")
fmt.Println(reflect.TypeOf(p))
fmt.Printf("%+v", p)
}Вывод:
main._Ctype_struct_person
{age:18 name:0x1dd043b6e30}Если некоторые поля структуры C содержат bit-field, CGO игнорирует такие поля. Например, если изменить person:
struct person {
int32_t age: 1;
char* name;
};При выполнении возникнет ошибка:
p.age undefined (type _Ctype_struct_person has no field or method age)Правила выравнивания памяти полей структур в C и Go различны. При включённом CGO в большинстве случаев доминирует C.
Объединения
Для доступа к объединениям C используется префикс C.union_ с именем. Поскольку Go не поддерживает объединения, они существуют в Go как байтовые массивы. Пример:
package main
/*
#include <stdio.h>
#include <stdint.h>
union data {
int32_t age;
char ch;
};
*/
import "C"
import (
"fmt"
"reflect"
)
func main() {
var u C.union_data
fmt.Println(reflect.TypeOf(u), u)
}Вывод:
[4]uint8 [0 0 0 0]Доступ и изменение возможны через unsafe.Pointer:
func main() {
var u C.union_data
ptr := (*C.int32_t)(unsafe.Pointer(&u))
fmt.Println(*ptr)
*ptr = C.int32_t(1024)
fmt.Println(*ptr)
fmt.Println(u)
}Вывод:
0
1024
[0 4 0 0]Перечисления
Для доступа к перечислениям C используется префикс C.enum_ с именем типа. Пример:
package main
/*
#include <stdio.h>
#include <stdint.h>
enum player_state {
alive,
dead,
};
*/
import "C"
import "fmt"
type State C.enum_player_state
func (s State) String() string {
switch s {
case C.alive:
return "alive"
case C.dead:
return "dead"
default:
return "unknown"
}
}
func main() {
fmt.Println(C.alive, State(C.alive))
fmt.Println(C.dead, State(C.dead))
}Вывод:
0 alive
1 deadУказатели
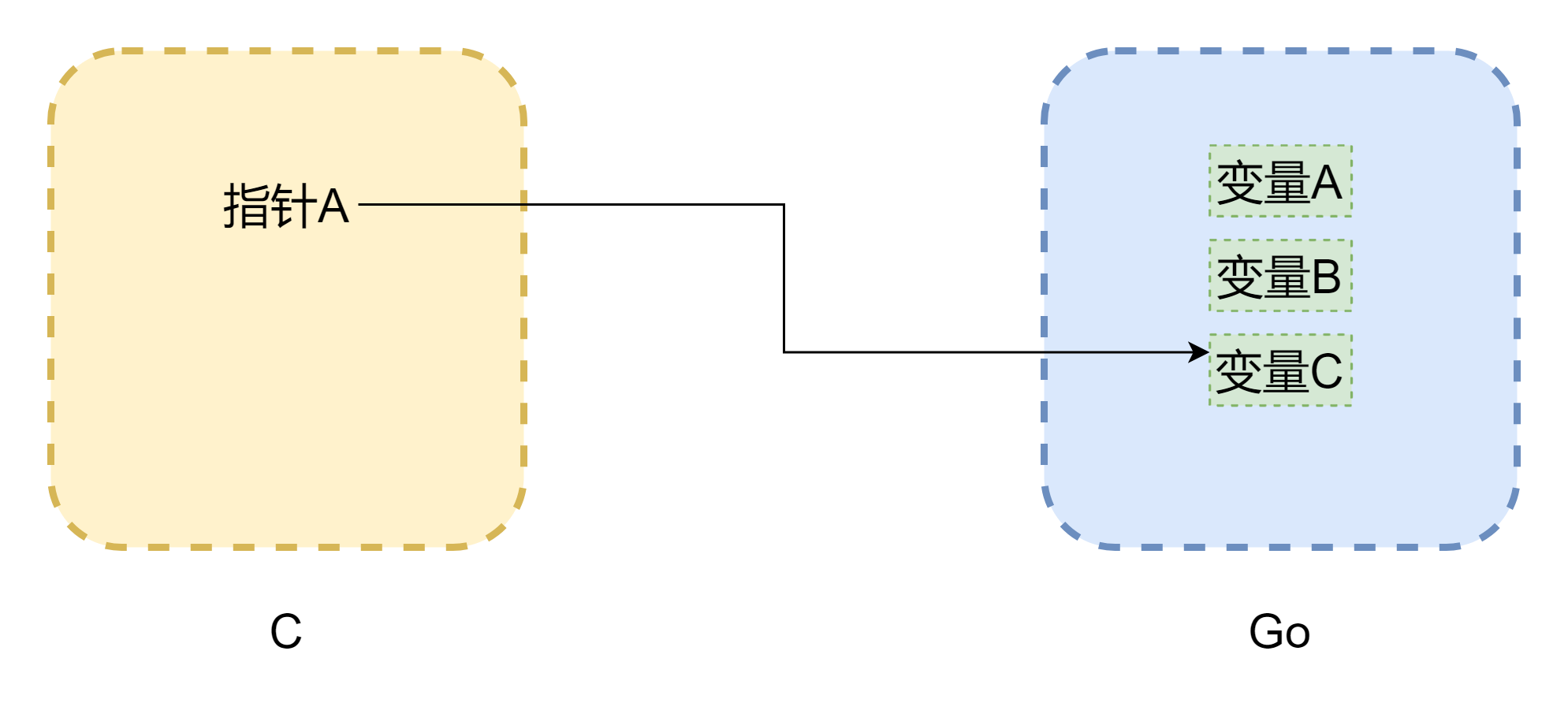
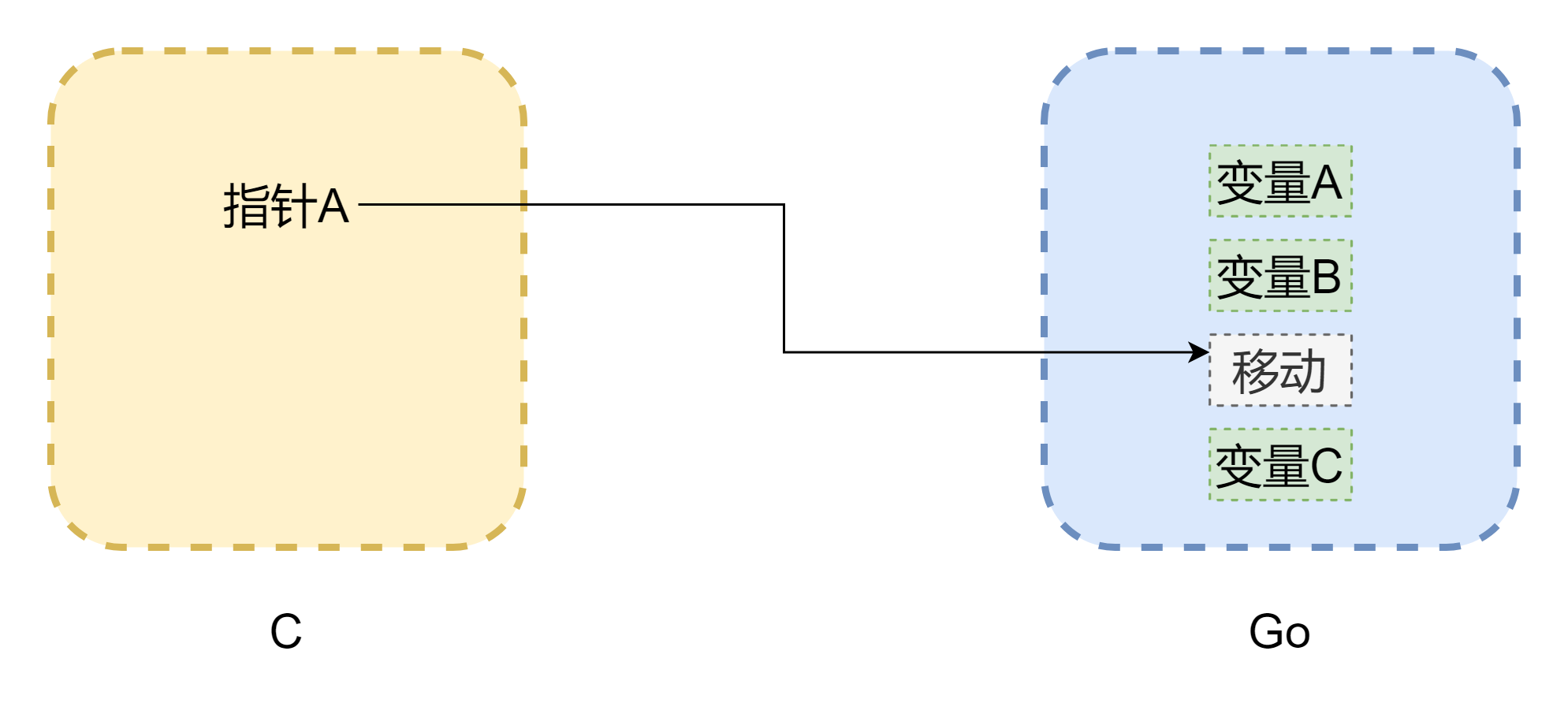
Говоря об указателях, нельзя не затронуть память. Основная проблема взаимных вызовов между C и Go — различия в моделях памяти. Память в C полностью управляется разработчиком вручную: malloc() для выделения, free() для освобождения. Если не освободить вручную, память не освободится автоматически, поэтому управление памятью в C очень стабильно. В Go всё иначе: есть сборщик мусора, а пространство стека Goroutine динамически изменяется. При недостатке стека он увеличивается, и адрес памяти может измениться, как на рисунке выше (рисунок не совсем точен), указатель может стать висячим указателем, распространённым в C. Хотя CGO в большинстве случаев может предотвратить перемещение памяти (с помощью runtime.Pinner для фиксации памяти), официальная позиция Go не рекомендует C долго хранить ссылки на память Go. Наоборот, если указатель Go ссылается на память C, это относительно безопасно, если не вызывается C.free() вручную — память не освободится автоматически.
Для передачи указателей между C и Go необходимо сначала преобразовать их в unsafe.Pointer, затем в соответствующий тип указателя, аналогично void* в C. Два примера: первый — указатель C ссылается на переменную Go и изменяет её:
package main
/*
#include <stdio.h>
#include <stdint.h>
void printNum(int32_t* s) {
printf("%d\n", *s);
*s = 3;
printf("%d\n", *s);
}
*/
import "C"
import (
"fmt"
"unsafe"
)
func main() {
var num int32 = 1
ptr := unsafe.Pointer(&num)
C.printNum((*C.int32_t)(ptr))
fmt.Println(num)
}Вывод:
1
3
3Второй пример — указатель Go ссылается на переменную C и изменяет её:
package main
/*
#include <stdio.h>
#include <stdint.h>
int32_t num = 10;
*/
import "C"
import (
"fmt"
"unsafe"
)
func main() {
fmt.Println(C.num)
ptr := unsafe.Pointer(&C.num)
iptr := (*int32)(ptr)
*iptr++
fmt.Println(C.num)
}Вывод:
10
11Кстати, CGO не поддерживает указатели на функции в C.
Библиотеки
В C нет менеджера зависимостей, как в Go. Для использования чужих библиотек, помимо получения исходного кода, можно использовать статические и динамические библиотеки. CGO поддерживает это, позволяя импортировать готовые библиотеки в Go без исходного кода.
Динамические библиотеки
Динамические библиотеки не могут выполняться отдельно — они загружаются в память вместе с исполняемым файлом во время выполнения. Ниже пример создания простой динамической библиотеки и вызова через CGO. Сначала создайте файл lib/sum.c:
#include <stdint.h>
int32_t sum(int32_t a, int32_t b) {
return a + b;
}Заголовочный файл lib/sum.h:
#include <stdint.h>
int sum(int32_t a, int32_t b);Далее используйте gcc для создания динамической библиотеки. Сначала скомпилируйте в объектный файл:
$ cd lib
$ gcc -c sum.c -o sum.oЗатем создайте динамическую библиотеку:
$ gcc -shared -o libsum.dll sum.oПосле создания импортируйте заголовочный файл sum.h в код Go и укажите CGO путь к библиотеке через макросы:
package main
/*
#cgo CFLAGS: -I ./lib
#cgo LDFLAGS: -L${SRCDIR}/lib -llibsum
#include "sum.h"
*/
import "C"
import "fmt"
func main() {
res := C.sum(C.int32_t(1), C.int32_t(2))
fmt.Println(res)
}CFLAGS: -I— относительный путь поиска заголовочных файлов-L— путь поиска библиотек,${SRCDIR}— абсолютный путь текущей директории (параметр должен быть абсолютным)-l— имя файла библиотеки:sumсоответствуетsum.dll
CFLAGS и LDFLAGS — параметры компиляции gcc. Из соображений безопасности CGO отключил некоторые параметры. Подробнее: cgo command.
Поместите динамическую библиотеку в одну директорию с .exe:
$ ls
go.mod go.sum lib/ libsum.dll* main.exe* main.goСкомпилируйте и выполните программу Go:
$ go build main.go && ./main.exe
3Динамическая библиотека успешно вызвана.
Статические библиотеки
В отличие от динамических, при импорте статических библиотек через CGO они линкуются с целевым файлом Go в исполняемый файл. На примере sum.c сначала скомпилируйте в объектный файл:
$ gcc -o sum.o -c sum.cЗатем упакуйте в статическую библиотеку (должна начинаться с префикса lib, иначе не будет найдена):
$ ar rcs libsum.a sum.oФайл Go:
package main
/*
#cgo CFLAGS: -I ./lib
#cgo LDFLAGS: -L${SRCDIR}/lib -llibsum
#include "sum.h"
*/
import "C"
import "fmt"
func main() {
res := C.sum(C.int32_t(1), C.int32_t(2))
fmt.Println(res)
}Компиляция:
$ go build && ./main.exe
3Статическая библиотека успешно вызвана.
Заключение
Хотя использование CGO мотивировано производительностью, переключение между C и Go вызывает значительные потери производительности. Для очень простых задач эффективность CGO ниже, чем у чистого Go. Пример:
package main
/*
#include <stdint.h>
int32_t cgo_sum(int32_t a, int32_t b) {
return a + b;
}
*/
import "C"
import (
"fmt"
"time"
)
func go_sum(a, b int32) int32 {
return a + b
}
func testSum(N int, do func()) int64 {
var sum int64
for i := 0; i < N; i++ {
start := time.Now()
do()
sum += time.Now().Sub(start).Nanoseconds()
}
return sum / int64(N)
}
func main() {
N := 1000_000
nsop1 := testSum(N, func() {
C.cgo_sum(C.int32_t(1), C.int32_t(2))
})
fmt.Printf("cgo_sum: %d ns/op\n", nsop1)
nsop2 := testSum(N, func() {
go_sum(1, 2)
})
fmt.Printf("pure_go_sum: %d ns/op\n", nsop2)
}Это простой тест: функции суммы двух чисел написаны на C и Go, каждая выполняется 1 миллион раз, вычисляется среднее время. Результаты:
cgo_sum: 49 ns/op
pure_go_sum: 2 ns/opСреднее время CGO в 20+ раз больше, чем у чистого Go. Если выполняется не простое сложение, а более затратная задача, преимущество CGO будет больше. Кроме того, у CGO есть недостатки:
- Многие инструменты Go становятся недоступны:
go test,pprof. Приведённый тест нельзя запустить черезgo test, только вручную. - Скорость компиляции снижается, встроенная кросс-компиляция становится недоступной.
- Проблемы безопасности памяти.
- Зависимости: если кто-то использует вашу библиотеку, ему тоже придётся включить CGO.
Прежде чем вводить CGO в проект, тщательно обдумайте. Для очень сложных задач CGO может принести пользу, но для простых задач лучше использовать чистый Go.