slice
TIP
本文を読むには unsafe 標準ライブラリの知識が必要です。
スライスは Go 言語で最も一般的に使用されるデータ構造です(実際、組み込みのデータ構造はそれほど多くありません)。その基本用法については言語入門で既に説明済みです。以下ではその内部構造と動作原理について見ていきます。
構造
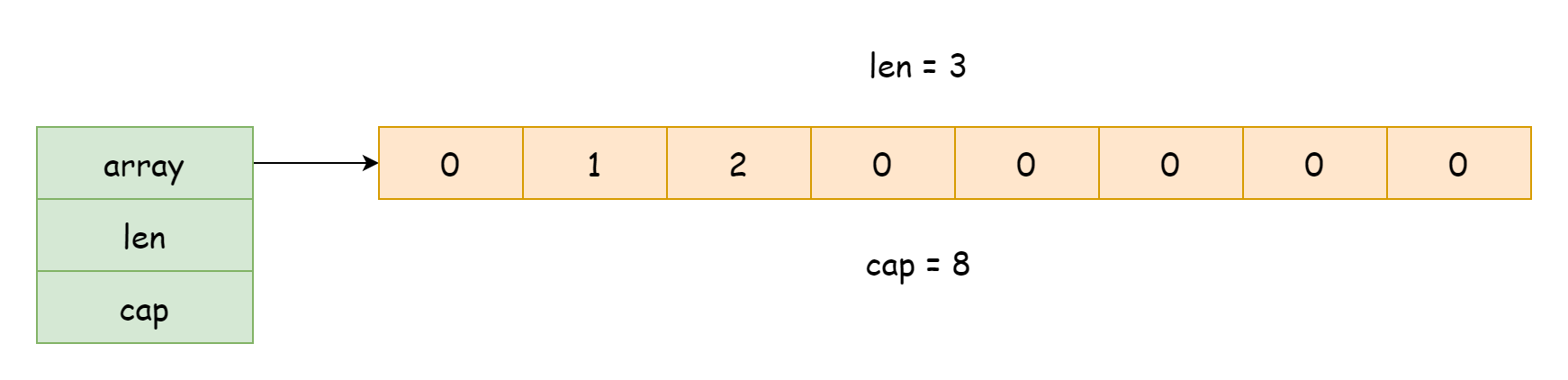
スライスの実装に関するソースコードは runtime/slice.go ファイルに位置しています。実行時において、スライスは構造体として存在し、その型は runtime.slice です。
type slice struct {
array unsafe.Pointer
len int
cap int
}この構造体には 3 つのフィールドしかありません。
array:底层配列へのポインタlen:スライスの長さ。配列内の既存要素数を指すcap:スライスの容量。配列が収容できる要素の総数を指す
上記の情報から、スライスの底层実装は配列に依存しており、通常時は構造体として配列への参照と容量・長さの記録のみを保持していることがわかります。これにより、スライスを渡すコストは非常に低くなり、データ全体をコピーする必要がなく参照のみをコピーすればよく、また len と cap でスライスの長さと容量を取得する際はフィールド値を取得するだけで配列を走査する必要がありません。
しかし、これはいくつかの発見しにくい問題ももたらします。以下の例を見てみましょう。
package main
import "fmt"
func main() {
s := make([]int, 0, 10)
s = append(s, 1, 2, 3, 4, 5)
s1 := s[:]
s1[0] = 2
fmt.Println(s)
}[2 2 3 4 5]上記のコードでは、s1 はスライスを切り出して新しいスライスを作成していますが、元のスライスと同じ底层配列を参照しています。s1 のデータを変更すると s も変更されます。したがって、スライスをコピーする際は copy 関数を使用すべきです。別の例を見てみましょう。
func main() {
s := make([]int, 0, 10)
s = append(s, 1, 2, 3, 4, 5)
s1 := s[:]
s1 = append(s1, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
s1[0] = 10
fmt.Println(s)
fmt.Println(s1)
}[1 2 3 4 5]
[10 2 3 4 5 1 2 3 4 5 6 7 8 9 10]これも切り出し方式でスライスをコピーしていますが、今回は元のスライスに影響を与えません。最初は s1 と s が同じ配列を指していましたが、その後 s1 に多すぎる要素が追加され、配列の収容可能数を超えたため、より大きな新しい配列が割り当てられました。
さらに別の例を見てみましょう。
package main
import "fmt"
func main() {
s := make([]int, 0, 10)
appendData(s, 1, 2, 3, 4, 5, 6)
fmt.Println(s)
}
func appendData[T comparable](s []T, data ...T) {
s = append(s, data...)
}[]要素を追加したにもかかわらず、空のスライスが出力されました。実際、データはスライスに追加されましたが、底层配列に書き込まれただけです。Go の関数パラメータは値渡しなので、パラメータ s は元のスライス構造体のコピーであり、append 操作は要素追加後に更新されたスライス構造体を返しますが、代入されるのはパラメータ s であり元のスライス s ではありません。
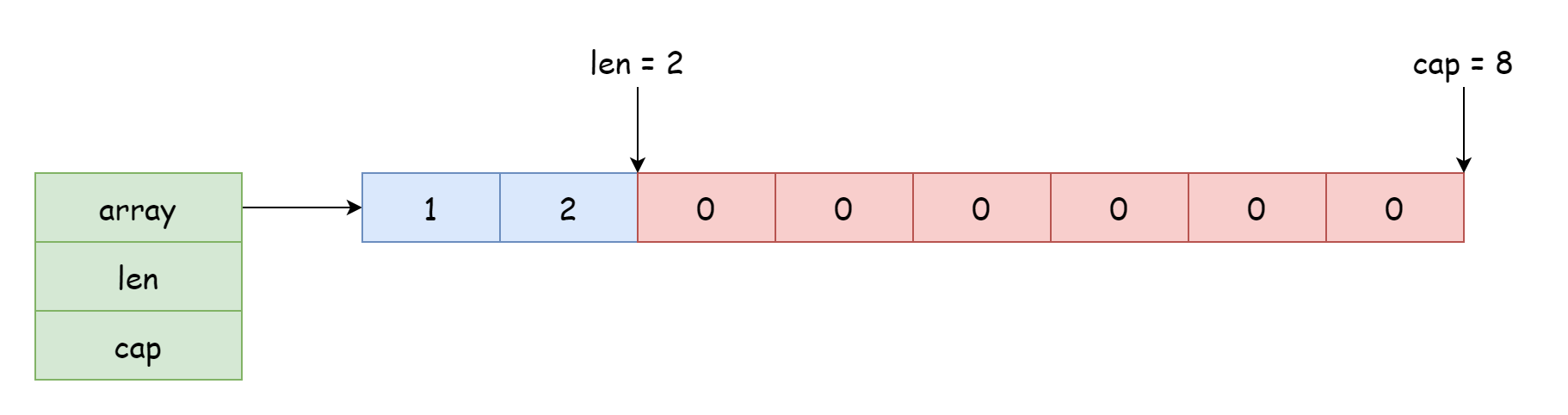
スライスがアクセス・変更可能な開始位置は配列の参照位置によって決まり、オフセットは構造体に記録された長さに依存します。構造体のポインタは配列の先頭だけでなく、中間も指すことができます。
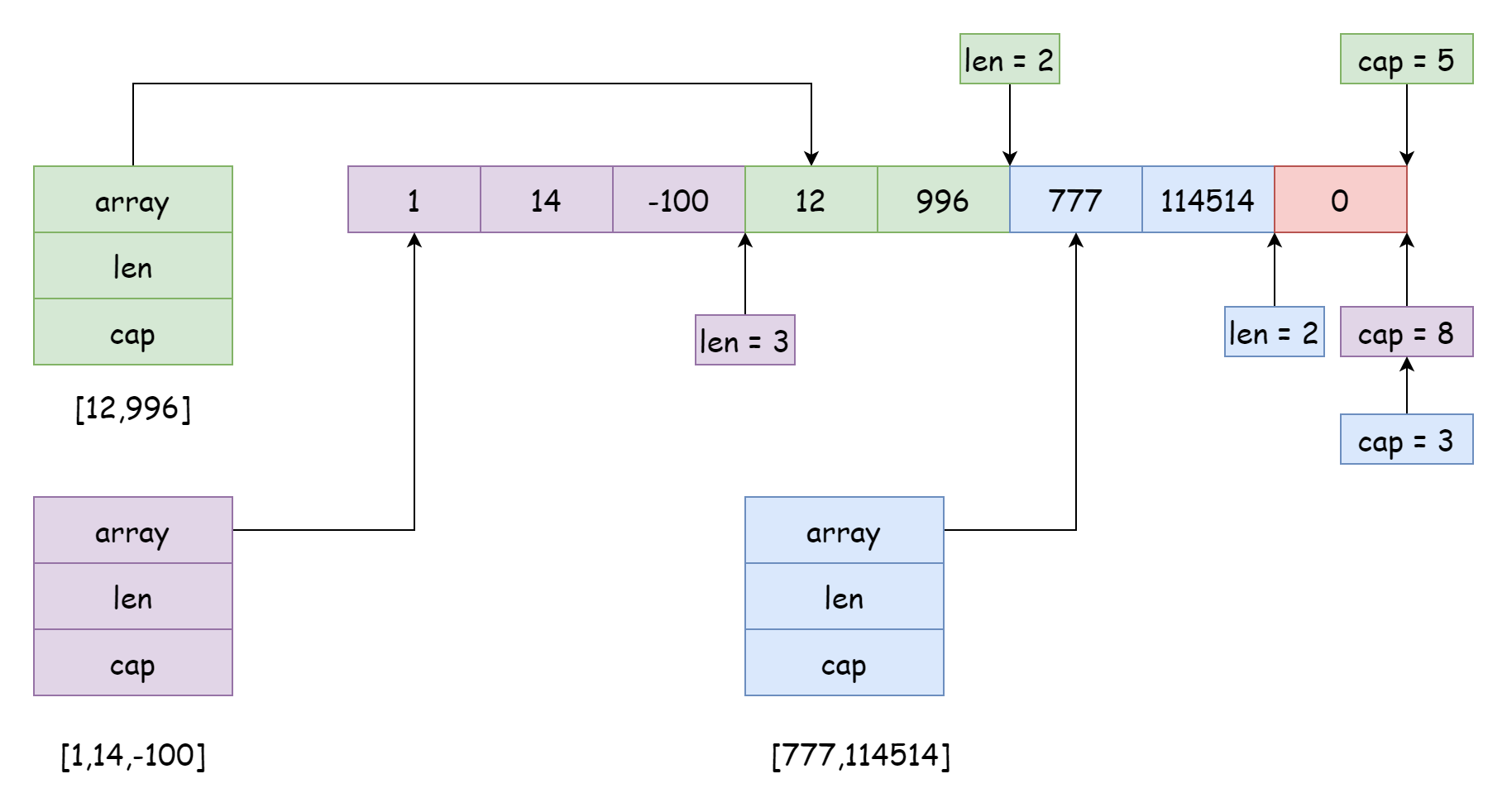
1 つの底层配列は多くのスライスに参照されることができ、参照位置と範囲は異なる場合があります。これは通常、スライスを切り出す際に発生します。
s := make([]int, 0, 10)
s1 := s[:4]
s2 := s[4:6]
s3 := s[7:]切り出し時、生成された新しいスライスの容量は配列の長さから新しいスライスの参照開始位置を引いた値になります。例えば s[4:6] で生成された新しいスライスの容量は 6 = 10 - 4 です。ただし、スライスの参照範囲は隣接している必要はなく、相互に交差することもできますが、これは非常に大きな問題を引き起こす可能性があります。これを避けるため、Go では切り出し時に容量範囲を設定できます。
s4 = s[4:6:6]この場合、容量は 2 に制限されるため、要素を追加すると拡張がトリガーされ、新しい配列になります。
さらに別の例を見てみましょう。
package main
import "fmt"
func main() {
s := make([]int, 0, 10)
// 追加する要素数が容量をわずかに超える
appendData(s, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11)
fmt.Println(s)
}
func appendData[T comparable](s []T, data ...T) {
s = append(s, data...)
}[]コードは前の例と同じですが、引数を変更して追加する要素数がスライスの容量をわずかに超えるようにしました。これにより追加時に拡張がトリガーされ、データは元のスライス s だけでなく底层配列にも書き込まれません。unsafe ポインタで確認できます。
package main
import (
"fmt"
"unsafe"
)
func main() {
s := make([]int, 0, 10)
// 追加する要素数が容量をわずかに超える
appendData(s, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11)
fmt.Println("ori slice", unsafe.SliceData(s))
unsafeIterator(unsafe.Pointer(unsafe.SliceData(s)), cap(s))
}
func appendData[T comparable](s []T, data ...T) {
s = append(s, data...)
fmt.Println("new slice", unsafe.SliceData(s))
unsafeIterator(unsafe.Pointer(unsafe.SliceData(s)), cap(s))
}
func unsafeIterator(ptr unsafe.Pointer, offset int) {
for ptr, i := ptr, 0; i < offset; ptr, i = unsafe.Add(ptr, unsafe.Sizeof(int(0))), i+1 {
elem := *(*int)(ptr)
fmt.Printf("%d, ", elem)
}
fmt.Println()
}new slice 0xc0000200a0
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 0, 0, 0, 0, 0, 0, 0, 0, 0,
ori slice 0xc000018190
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,元のスライスの底层配列は空で、データはすべて新しい配列に書き込まれました。append が新しい参照を返しても、変更されるのは形式パラメータ s の値のみで、元のスライス s には影響しません。
作成
実行時において、make 関数でスライスを作成する作業は runtime.makeslice 関数によって行われます。この関数のシグネチャは以下の通りです。
func makeslice(et *_type, len, cap int) unsafe.Pointer3 つのパラメータ(要素型、長さ、容量)を受け取り、底层配列へのポインタを返します。
func makeslice(et *_type, len, cap int) unsafe.Pointer {
// 必要な総メモリを計算。大きすぎると数値オーバーフローの可能性がある
// mem = sizeof(et) * cap
mem, overflow := math.MulUintptr(et.Size_, uintptr(cap))
if overflow || mem > maxAlloc || len < 0 || len > cap {
// mem = sizeof(et) * len
mem, overflow := math.MulUintptr(et.Size_, uintptr(len))
if overflow || mem > maxAlloc || len < 0 {
panicmakeslicelen()
}
panicmakeslicecap()
}
// 問題なければメモリを割り当て
return mallocgc(mem, et, true)
}ロジックは非常にシンプルで、2 つのことしか行っていません。
- 必要なメモリを計算
- メモリ空間を割り当て
条件チェックに失敗すると、直接 panic します。
- メモリ計算時に数値がオーバーフロー
- 計算結果が割り当て可能な最大メモリを超える
- 長さと容量が不正
計算されたメモリが 32KB を超えると、ヒープに割り当てられます。その後、底层配列へのポインタを返し、runtime.slice 構造体の構築は makeslice 関数ではなくコンパイル時に行われます。
var s runtime.slice
s.array = runtime.makeslice(type,len,cap)
s.len = len
s.cap = cap興味があれば、生成された中間コードを確認してみてください。
name s.ptr[*int]: v11
name s.len[int]: v7
name s.cap[int]: v8配列を使用してスライスを作成する場合、例えば以下のようになります。
var arr [5]int
s := arr[:]このプロセスは以下のコードのようになります。
var arr [5]int
var s runtime.slice
s.array = &arr
s.len = len
s.cap = capGo は配列をスライスの底层配列として直接使用するため、スライスのデータを変更すると配列のデータにも影響します。配列でスライスを作成する際、長さは high-low、容量は max-low になります。ここで max はデフォルトで配列の長さですが、切り出し時に容量を手動で指定することもできます。
var arr [5]int
s := arr[2:3:4]
アクセス
配列と同様に、インデックスでスライスにアクセスします。
elem := s[i]スライスのアクセス操作はコンパイル時に完了し、中間コードを生成することでアクセスします。
p := s.ptr
e := *(p + sizeof(elem(s)) * i)実際にはポインタを移動して対応するインデックス要素にアクセスします。
len と cap 関数でスライスの長さと容量にアクセスする際も同様です。
case ir.OLEN, ir.OCAP:
n := n.(*ir.UnaryExpr)
switch {
case n.X.Type().IsSlice():
op := ssa.OpSliceLen
if n.Op() == ir.OCAP {
op = ssa.OpSliceCap
}
return s.newValue1(op, types.Types[types.TINT], s.expr(n.X))実際に生成されるコードでは、ポインタを移動してスライス構造体の len フィールドにアクセスします。
p := &s
len := *(p + 8)
cap := *(p + 16)以下のコードがあるとします。
func lenAndCap(s []int) (int, int) {
l := len(s)
c := cap(s)
return l, c
}生成される中間コードはおそらく以下のようになります。
v9 (+9) = ArgIntReg <int> {s+8} [1] : BX (l[int], s+8[int])
v10 (+10) = ArgIntReg <int> {s+16} [2] : CX (c[int], s+16[int])
v1 (?) = InitMem <mem>
v3 (11) = Copy <int> v9 : AX
v4 (11) = Copy <int> v10 : BX
v11 (+11) = MakeResult <int,int,mem> v3 v4 v1 : <>
Ret v11 (+11)
name l[int]: v9
name c[int]: v10
name s+16[int]: v10
name s+8[int]: v9上記から、一方が 8 を加え、他方が 16 を加えていることがわかります。これは明らかにポインタオフセットでスライスフィールドにアクセスしています。
コンパイル時に長さと容量を推論できる場合、実行時にポインタをオフセットして値を取得する必要はありません。
s := make([]int, 10, 20)
l := len(s)
c := cap(s)変数 l と c の値は直接 10 と 20 に置き換えられます。
書き込み
変更
s := make([]int, 10)
s[0] = 100インデックスでスライスの値を変更する際、コンパイル時に OpStore 操作で以下の擬似コードが生成されます。
p := &s
l := *(p + 8)
if !IsInBounds(l,i) {
panic()
}
ptr := (s.ptr + i * sizeof(elem) * i)
*ptr = val生成される中間コードはおそらく以下のようになります。
v1 (?) = InitMem <mem>
v5 (8) = Arg <[]int> {s} (s[[]int])
v6 (?) = Const64 <int> [100]
v7 (?) = Const64 <int> [0]
v8 (+9) = SliceLen <int> v5
v9 (9) = IsInBounds <bool> v7 v8
v14 (?) = Const64 <int64> [0]
v12 (9) = SlicePtr <*int> v5
v15 (9) = Store <mem> {int} v12 v6 v1
v11 (9) = PanicBounds <mem> [0] v7 v7 v1
Exit v11 (9)
name s[[]int]: v5
name s[*int]:
name s+8[int]:コードはスライスの長さにアクセスしてインデックスの正当性をチェックし、最後にポインタを移動して要素を格納します。
追加
append 関数でスライスに要素を追加できます。
var s []int
s = append(s, 1, 2, 3)要素を追加した後、新しいスライス構造体を返します。拡張がない場合は元のスライスと比較して長さのみが更新され、ある場合は新しい配列を指します。
実行時には runtime.appendslice のような関数は存在せず、要素追加の作業はコンパイル時に行われます。append 関数は対応する中間コードに展開されます。
case ir.OAPPEND:
// x = append(...)
call := as.Y.(*ir.CallExpr)
if call.Type().Elem().NotInHeap() {
base.Errorf("%v can't be allocated in Go; it is incomplete (or unallocatable)", call.Type().Elem())
}
var r ir.Node
switch {
case isAppendOfMake(call):
// x = append(y, make([]T, y)...)
r = extendSlice(call, init)
case call.IsDDD:
r = appendSlice(call, init) // also works for append(slice, string).
default:
r = walkAppend(call, init, as)
}3 つのケースに分かれています。
- いくつかの要素を追加
- スライスを追加
- 一時作成されたスライスを追加
要素の追加
s = append(s, x, y, z)有限個の要素を追加する場合、walkAppend 関数で以下のコードに展開されます。
// 追加する要素数
const argc = len(args) - 1
newLen := s.len + argc
// 拡張が必要か
if uint(newLen) <= uint(s.cap) {
s = s[:newLen]
} else {
s = growslice(s.ptr, newLen, s.cap, argc, elemType)
}
s[s.len - argc] = x
s[s.len - argc + 1] = y
s[s.len - argc + 2] = zまず追加する要素数を計算し、拡張が必要か判断し、最後に一つずつ代入します。
スライスの追加
s = append(s, s1...)スライスを直接追加する場合、appendSlice 関数で以下のコードに展開されます。
newLen := s.len + s1.len
// Compare as uint so growslice can panic on overflow.
if uint(newLen) <= uint(s.cap) {
s = s[:newLen]
} else {
s = growslice(s.ptr, s.len, s.cap, s1.len, T)
}
memmove(&s[s.len-s1.len], &s1[0], s1.len*sizeof(T))以前と同様に、新しい長さを計算し、拡張が必要か判断しますが、Go は元のスライスの要素を一つずつ追加するのではなく、直接メモリをコピーします。
一時スライスの追加
s = append(s, make([]T, l2)...)一時作成されたスライスを追加する場合、extendslice 関数で以下のコードに展開されます。
if l2 >= 0 {
// Empty if block here for more meaningful node.SetLikely(true)
} else {
panicmakeslicelen()
}
s := l1
n := len(s) + l2
if uint(n) <= uint(cap(s)) {
s = s[:n]
} else {
s = growslice(T, s.ptr, n, s.cap, l2, T)
}
// clear the new portion of the underlying array.
hp := &s[len(s)-l2]
hn := l2 * sizeof(T)
memclr(hp, hn)一時追加されるスライスの場合、Go は一時スライスの長さを取得し、現在のスライスの容量が十分でない場合は拡張を試み、完了後に対応部分のメモリをクリアします。
拡張
構造の部分で述べたように、スライスの底层は配列であり、配列は長さが固定されたデータ構造ですが、スライスの長さは可変です。スライスは配列の容量が不足した際に、より大きなメモリ空間を申請してデータを格納します。つまり、新しい配列を作成し、古いデータをコピーして、スライスの参照が新しい配列を指すようにします。このプロセスを拡張と呼びます。拡張の作業は実行時に runtime.growslice 関数によって行われます。
func growslice(oldPtr unsafe.Pointer, newLen, oldCap, num int, et *_type) sliceパラメータの簡単な説明:
oldPtr:古い配列へのポインタnewLen:新しい配列の長さ、newLen = oldLen + numoldCap:古いスライスの容量。古い配列の長さに等しいet:要素型
戻り値は新しいスライスを返し、新しいスライスは元のスライスとは無関係ですが、保存されているデータは同じです。
var s []int
s = append(s, elems...)append で要素を追加する際、戻り値で元のスライスを上書きする必要があります。拡張が発生した場合は、新しいスライスが返されます。
拡張時、まず新しい長さと容量を決定します。
oldLen := newLen - num
if newLen < 0 {
panic(errorString("growslice: len out of range"))
}
if et.Size_ == 0 {
return slice{unsafe.Pointer(&zerobase), newLen, newLen}
}
newcap := oldCap
// 倍の容量
doublecap := newcap + newcap
if newLen > doublecap {
newcap = newLen
} else {
const threshold = 256
if oldCap < threshold {
newcap = doublecap
} else {
for 0 < newcap && newcap < newLen {
// newcap += 0.25 * newcap + 192
newcap += (newcap + 3*threshold) / 4
}
// 数値がオーバーフロー
if newcap <= 0 {
newcap = newLen
}
}
}上記のコードから、容量が 256 未満のスライスは容量が 2 倍になり、容量が 256 以上のスライスは少なくとも元の容量の 1.25 倍になることがわかります。スライスが小さい場合は直接 2 倍にすることで頻繁な拡張を避け、スライスが大きい場合は拡張倍率を減らしてメモリの浪費を避けます。
新しい長さと容量を取得した後、必要なメモリを計算します。
var overflow bool
var lenmem, newlenmem, capmem uintptr
switch {
...
...
default:
lenmem = uintptr(oldLen) * et.Size_
newlenmem = uintptr(newLen) * et.Size_
capmem, overflow = math.MulUintptr(et.Size_, uintptr(newcap))
capmem = roundupsize(capmem)
// 最終的な容量
newcap = int(capmem / et.Size_)
capmem = uintptr(newcap) * et.Size_
}
if overflow || capmem > maxAlloc {
panic(errorString("growslice: len out of range"))
}メモリの計算式は mem = cap * sizeof(et) です。メモリアラインメントのため、計算されたメモリを 2 の整数乗に切り上げ、再度新しい容量を計算します。
var p unsafe.Pointer
// メモリを割り当て
p = mallocgc(capmem, nil, false)
memclrNoHeapPointers(add(p, newlenmem), capmem-newlenmem)
memmove(p, oldPtr, lenmem)
return slice{p, newLen, newcap}必要な結果を計算した後、指定されたサイズのメモリを割り当て、newLen から newCap までのメモリをクリアし、古い配列のデータを新しいスライスにコピーし、最後にスライス構造体を構築します。
コピー
src := make([]int, 10)
dst := make([]int, 20)
copy(dst, src)copy 関数でスライスをコピーする際、cmd/compile/internal/walk.walkcopy によってコンパイル時に生成されるコードがコピー方法を決定します。実行時に呼び出される場合、runtime.slicecopy 関数が使用されます。
func slicecopy(toPtr unsafe.Pointer, toLen int, fromPtr unsafe.Pointer, fromLen int, width uintptr) int元のスライスと目的のスライスのポインタと長さ、およびコピーする長さ width を受け取ります。
func slicecopy(toPtr unsafe.Pointer, toLen int, fromPtr unsafe.Pointer, fromLen int, width uintptr) int {
if fromLen == 0 || toLen == 0 {
return 0
}
n := fromLen
if toLen < n {
n = toLen
}
if width == 0 {
return n
}
// コピーするバイト数を計算
size := uintptr(n) * width
if size == 1 {
*(*byte)(toPtr) = *(*byte)(fromPtr)
} else {
memmove(toPtr, fromPtr, size)
}
return n
}width の値は 2 つのスライスの長さの最小値によって決まります。スライスをコピーする際、要素を一つずつ走査してコピーするのではなく、底层配列のメモリをまとめてコピーします。
実行時に呼び出されない場合、以下の形式のコードに展開されます。
n := len(a)
if n > len(b) {
n = len(b)
}
if a.ptr != b.ptr {
memmove(a.ptr, b.ptr, n*sizeof(elem(a)))
}両方の方式の原理は同じで、メモリをコピーすることでスライスをコピーします。memmove 関数はアセンブリで実装されています。
クリア
package main
func main() {
s := make([]int, 0, 10)
s = append(s, 1, 2, 3, 4, 5)
clear(s)
}Go 1.21 バージョンでは、組み込み関数 clear が追加され、スライスの内容をクリアするために使用できます。つまり、すべての要素をゼロ値に設定します。
if len(s) != 0 {
hp = &s[0]
hn = len(s)*sizeof(elem(s))
if elem(s).hasPointer() {
memclrHasPointers(hp, hn)
}else {
memclrNoHeapPointers(hp, hn)
}
}まずスライスの長さが 0 か判断し、クリアが必要なバイト数を計算し、要素がポインタかどうかによって 2 つのケースに分けて処理しますが、最終的には memclrNoHeapPointers 関数を使用します。
func memclrNoHeapPointers(ptr unsafe.Pointer, n uintptr)2 つのパラメータを受け取り、一つは開始アドレスへのポインタ、もう一つはオフセット、つまりクリアするバイト数です。
ソースコードでループを使用して配列をクリアしようとした場合、例えば以下のようになります。
for i := range s {
s[i] = ZERO_val
}clear 関数がない前は、通常このようにしてスライスをクリアしていました。コンパイル時、このコードは cmd/compile/internal/walk.arrayRangeClear 関数によって最適化されます。
for i, v := range s {
if len(s) != 0 {
hp = &s[0]
hn = len(s)*sizeof(elem(s))
if elem(s).hasPointer() {
memclrHasPointers(hp, hn)
}else {
memclrNoHeapPointers(hp, hn)
}
// ループを停止
i = len(s) - 1
}
}ロジックは上記と同じで、メモリクリア後にループを停止するために i = len(s)-1 が追加されています。
走査
for i, e := range s {
fmt.Println(i, e)
}for range でスライスを走査する際、cmd/compile/internal/walk/range.go の walkRange 関数によって以下の形式に展開されます。
// 構造体をコピー
hs := s
// 底层配列のポインタを取得
hu = uintptr(unsafe.Pointer(hs.ptr))
v1 := 0
v2 := zero
for i := 0; i < hs.len; i++ {
hp = (*T)(unsafe.Pointer(hu))
v1, v2 = i, *hp
... body of loop ...
hu = uintptr(unsafe.Pointer(hp)) + elemsize
}for range の実装はポインタを移動して要素を走査します。走査中にスライスが更新されないよう、事前に構造体のコピー hs を作成し、走査終了後にポインタが境界を越えないよう、hu は uintptr 型を使用してアドレスを格納し、要素にアクセスする際に unsafe.Pointer に変換します。
変数 v2 は for range の e で、走査全体を通じて常に同じ変数であり、上書きされるだけで再作成はされません。これは Go 開発者を 10 年間悩ませてきたループ変数問題を引き起こしました。Go 1.21 バージョンで公式に解決が決定され、今後のバージョン更新で v2 の作成方法は以下のようになる予定です。
v2 := *hp