title: slice 數據結構 keywords: [Go, 數據結構, slice] description: 切片應該是 go 語言中最最常用的數據結構,沒有之一(實際上內置的數據結構也沒幾個),幾乎在任何地方都能看到它的身影。關於它的基本用法在語言入門中已經闡述過了,下面來看看它的內部長什麼樣,以及它內部是如何運作的。
slice
TIP
閱讀本文需要unsafe標准庫的知識。
切片應該是 go 語言中最最常用的數據結構,沒有之一(實際上內置的數據結構也沒幾個),幾乎在任何地方都能看到它的身影。關於它的基本用法在語言入門中已經闡述過了,下面來看看它的內部長什麼樣,以及它內部是如何運作的。
結構
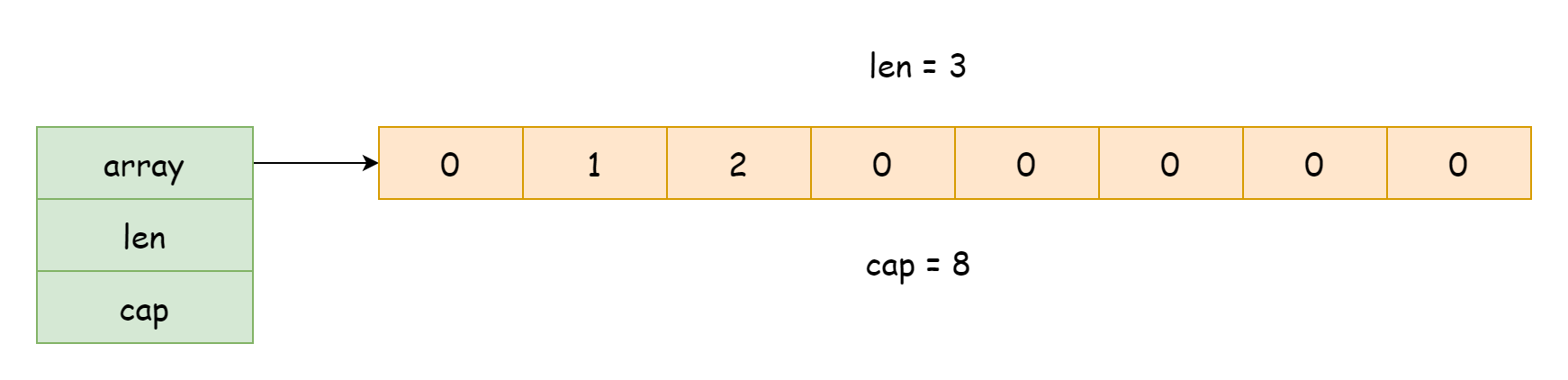
有關切片的實現,其源代碼位於runtime/slice.go文件中。在運行時,切片以一個結構體的形式而存在,其類型為runtime.slice,如下所示。
type slice struct {
array unsafe.Pointer
len int
cap int
}這個結構體只有三個字段
array,指向底層數組的指針len,切片的長度,指的是數組中已有的元素數量cap,切片的容量,指的是數組能容納元素的總數
從上面的信息可以得知,切片的底層實現還是依賴於數組,在平時它只是一個結構體,只持有對數組的引用,以及容量和長度的記錄。這樣一來傳遞切片的成本就會非常低,只需要復制其數據的引用,並不用復制所有數據,並且在使用len和cap獲取切片的長度和容量時,就等於是在獲取其字段值,不需要去遍歷數組。
不過這同樣也會帶來一些不容易發現的問題,看下面的一個例子
package main
import "fmt"
func main() {
s := make([]int, 0, 10)
s = append(s, 1, 2, 3, 4, 5)
s1 := s[:]
s1[0] = 2
fmt.Println(s)
}[2 2 3 4 5]在上面的代碼中,s1通過切割的方式創建了一個新的切片,但它和源切片所引用的都是同一個底層數組,修改s1中的數據也會導致s發生變化。所以復制切片的時候應該使用copy函數,後者復制的切片與前者毫不相干。再來看個例子
func main() {
s := make([]int, 0, 10)
s = append(s, 1, 2, 3, 4, 5)
s1 := s[:]
s1 = append(s1, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
s1[0] = 10
fmt.Println(s)
fmt.Println(s1)
}[1 2 3 4 5]
[10 2 3 4 5 1 2 3 4 5 6 7 8 9 10]同樣是使用切割方式復制切片,但這一次不會對源切片造成影響。最初s1和s確實指向的同一個數組,但是後續對s1添加了過多的元素超過了數組所能容納的數量,於是便分配了一個更大的新數組來盛放元素,所以最後它們兩個指向的就是不同的數組了。是不是覺得已經沒問題了,那就再來看一個例子
package main
import "fmt"
func main() {
s := make([]int, 0, 10)
appendData(s, 1, 2, 3, 4, 5, 6)
fmt.Println(s)
}
func appendData[T comparable](s []T, data ...T) {
s = append(s, data...)
}[]明明已經添加了元素,但是打印出來的確是空切片,實際上數據確實是已經添加到了切片中,只不過是寫入到了底層數組。go 中的函數參數是傳值傳遞,所以參數s實際上源切片結構體的一個拷貝,而append操作在添加元素後會返回一個更新了長度的切片結構體,只不過賦值的是參數s而非源切片s,兩者並其實沒有什麼聯系。
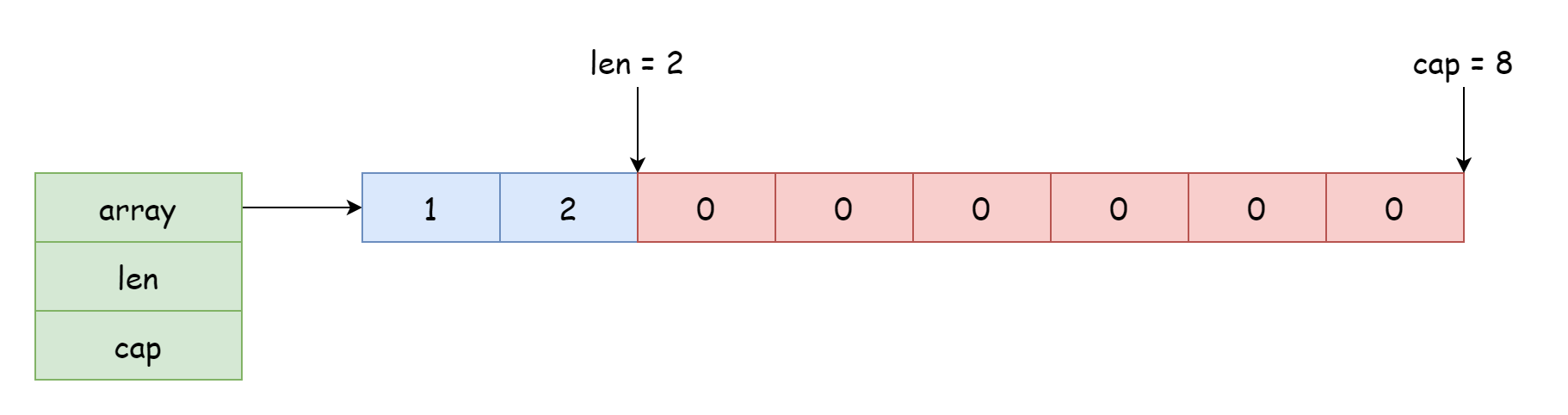
對於一個切片而言,它能訪問和修改的起始位置取決於對數組的引用位置,偏移量取決於結構體中記錄的長度。結構體中的指針除了可以指向開頭,也可以數組的中間,就像下面這張圖一樣。
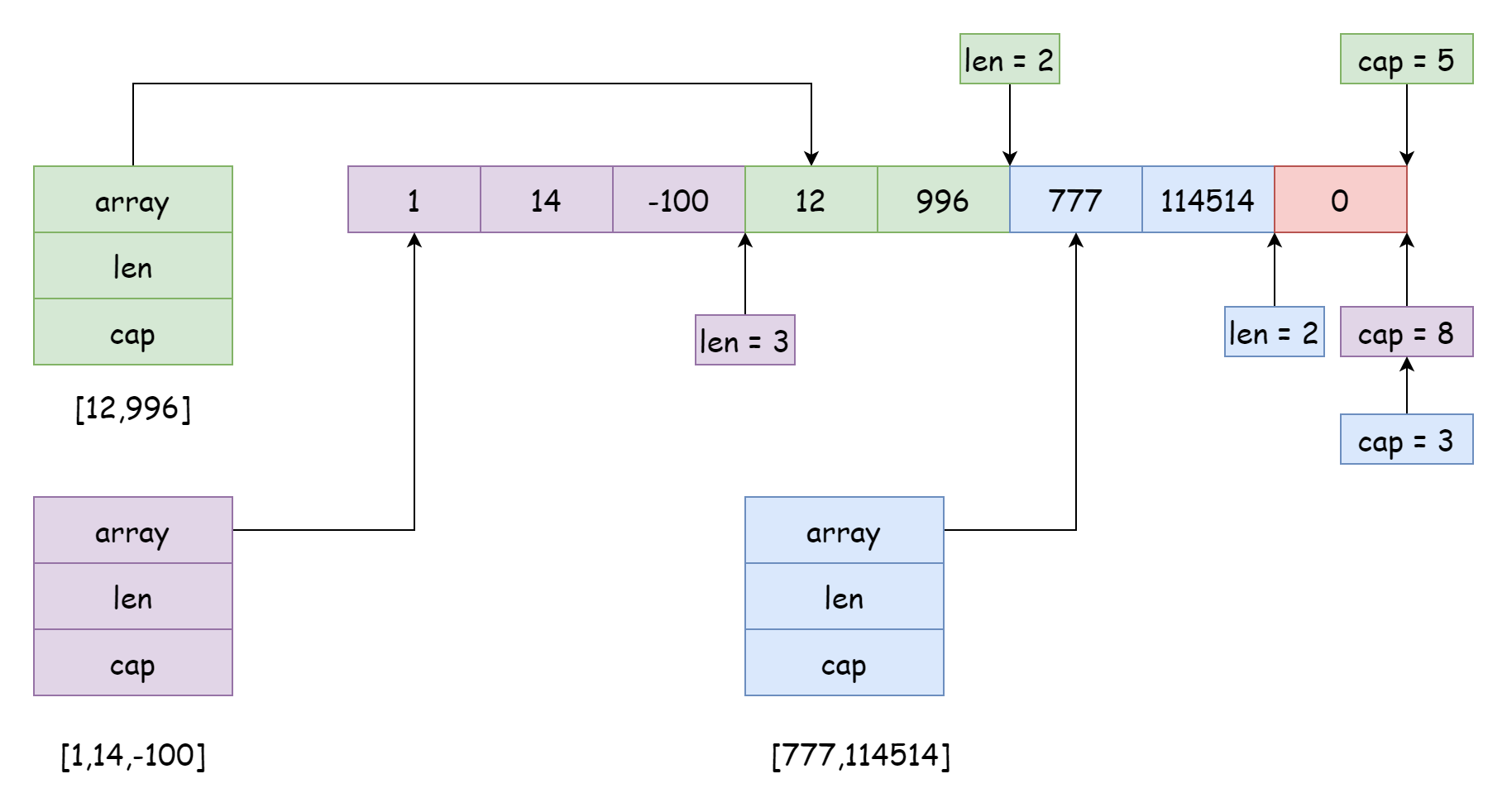
一個底層數組可以被很多個切片所引用,且引用的位置和范圍可以不同,就像上圖一樣,這種情況一般出現在對切片進行切割的時候,類似下面的代碼
s := make([]int, 0, 10)
s1 := s[:4]
s2 := s[4:6]
s3 := s[7:]在切割時,生成的新切片的容量等於數組長度減去新切片引用的起始位置。例如s[4:6]生成的新切片容量就是6 = 10 - 4。當然,切片引用的范圍也不一定非得相鄰,也可以相互交錯,不過這會產生非常大的麻煩,可能當前切片的數據在不知情的情況下就被別的切片修改了,比如上圖中的紫色切片,如果在後續過程中使用append添加元素,就有可能會把綠色切片和藍色切片的數據覆蓋。為了避免這種情況,go 允許在切割時設置容量范圍,語法如下。
s4 = s[4:6:6]在這種情況下,它的容量就被限制到了 2,那麼添加元素就會觸發擴容,擴容後就是一個新數組了,與源數組就沒有關系了,就不會有影響。你以為關於切片的問題到這裡就結束了嗎,其實並沒有,再來看一個例子。
package main
import "fmt"
func main() {
s := make([]int, 0, 10)
// 添加的元素數量剛好大於容量
appendData(s, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11)
fmt.Println(s)
}
func appendData[T comparable](s []T, data ...T) {
s = append(s, data...)
}[]代碼跟上一個例子沒有區別,只是修改了一下入參,讓添加的元素數量剛好大於切片的容量,這樣在添加時就會觸發擴容,這樣一來,數據不僅沒有添加到源切片s,甚至連其指向的底層數組也沒有被寫入數據,我們可以通過unsafe指針來證實一下,代碼如下
package main
import (
"fmt"
"unsafe"
)
func main() {
s := make([]int, 0, 10)
// 添加的元素數量剛好大於容量
appendData(s, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11)
fmt.Println("ori slice", unsafe.SliceData(s))
unsafeIterator(unsafe.Pointer(unsafe.SliceData(s)), cap(s))
}
func appendData[T comparable](s []T, data ...T) {
s = append(s, data...)
fmt.Println("new slice", unsafe.SliceData(s))
unsafeIterator(unsafe.Pointer(unsafe.SliceData(s)), cap(s))
}
func unsafeIterator(ptr unsafe.Pointer, offset int) {
for ptr, i := ptr, 0; i < offset; ptr, i = unsafe.Add(ptr, unsafe.Sizeof(int(0))), i+1 {
elem := *(*int)(ptr)
fmt.Printf("%d, ", elem)
}
fmt.Println()
}new slice 0xc0000200a0
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 0, 0, 0, 0, 0, 0, 0, 0, 0,
ori slice 0xc000018190
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,可以看到的是,源切片的底層數組空空如也,一點東西也沒有,數據全都被寫入新數組中了,不過跟源切片沒什麼關系,因為即便append返回了新的引用,修改的也只是形參s的值,影響不到源切片s。切片作為結構體確實可以讓其非常輕量,但是上面的問題同樣不可忽視,尤其是在實際的代碼中這些問題通常藏的很深,很難被發現。
創建
在運行時,使用make函數創建切片的工作由runtime.makeslice,來完成,它的邏輯比較簡單,該函數簽名如下
func makeslice(et *_type, len, cap int) unsafe.Pointer它接收三個參數,元素類型,長度,容量,完成後返回一個指向底層數組的指針,它的代碼如下
func makeslice(et *_type, len, cap int) unsafe.Pointer {
// 計算需要的總內存,如果太大會導致數值溢出
// mem = sizeof(et) * cap
mem, overflow := math.MulUintptr(et.Size_, uintptr(cap))
if overflow || mem > maxAlloc || len < 0 || len > cap {
// mem = sizeof(et) * len
mem, overflow := math.MulUintptr(et.Size_, uintptr(len))
if overflow || mem > maxAlloc || len < 0 {
panicmakeslicelen()
}
panicmakeslicecap()
}
// 沒問題的話就分配內存
return mallocgc(mem, et, true)
}可以看到邏輯非常簡單,總共就做了兩件事
- 計算所需內存
- 分配內存空間
如果條件檢查失敗了,就會直接panic
- 內存計算時數值溢出了
- 計算結果大於可分配的最大內存
- 長度與容量不合法
如果計算得到內存大於32KB,就會將其分配到堆上,完事之後就會返回一個指向底層數組的指針,構建runtime.slice結構體的工作並不由makeslice函數來完成。實際上,構建結構體的工作是編譯期間完成的,運行時的makeslice函數只負責分配內存,類似如下的代碼。
var s runtime.slice
s.array = runtime.makeslice(type,len,cap)
s.len = len
s.cap = cap感興趣的話可以去看看生成的中間代碼,跟這個類似。
name s.ptr[*int]: v11
name s.len[int]: v7
name s.cap[int]: v8如果是使用數組來創建切片的話,比如下面這種
var arr [5]int
s := arr[:]這個過程就類似下面的代碼
var arr [5]int
var s runtime.slice
s.array = &arr
s.len = len
s.cap = capgo 會直接將該數組作為切片的底層數組,所以修改切片中的數據也會影響到數組的數據。在使用數組創建切片時,長度大小等於hight-low,容量等於max-low,其中max默認為數組長度,或者也可以在切割的時候手動指定容量,例如。
var arr [5]int
s := arr[2:3:4]
訪問
訪問切片就跟訪問數組一樣使用下標索引
elem := s[i]切片的訪問操作是在編譯期間就已經完成了,通過生成中間代碼的方式來訪問,最終生成的代碼可以理解為下面的偽代碼
p := s.ptr
e := *(p + sizeof(elem(s)) * i)實際上是通過移動指針操作來訪問對應下標元素的,對應cmd/compile/internal/ssagen.exprCheckPtr函數中的如下部分代碼
case ir.OINDEX:
n := n.(*ir.IndexExpr)
switch {
case n.X.Type().IsSlice():
// 偏移指針
p := s.addr(n)
return s.load(n.X.Type().Elem(), p)在通過len和cap函數訪問切片的長度和容量時,也是同樣的道理,也是對應cmd/compile/internal/ssagen.exprCheckPtr函數中的部分代碼
case ir.OLEN, ir.OCAP:
n := n.(*ir.UnaryExpr)
switch {
case n.X.Type().IsSlice():
op := ssa.OpSliceLen
if n.Op() == ir.OCAP {
op = ssa.OpSliceCap
}
return s.newValue1(op, types.Types[types.TINT], s.expr(n.X))在實際生成的代碼中,通過移動指針來訪問切片結構體中的len字段,可以理解為下面的偽代碼
p := &s
len := *(p + 8)
cap := *(p + 16)假如現在有如下代碼
func lenAndCap(s []int) (int, int) {
l := len(s)
c := cap(s)
return l, c
}那麼在生成中的某個階段的中間代碼大概率長這樣
v9 (+9) = ArgIntReg <int> {s+8} [1] : BX (l[int], s+8[int])
v10 (+10) = ArgIntReg <int> {s+16} [2] : CX (c[int], s+16[int])
v1 (?) = InitMem <mem>
v3 (11) = Copy <int> v9 : AX
v4 (11) = Copy <int> v10 : BX
v11 (+11) = MakeResult <int,int,mem> v3 v4 v1 : <>
Ret v11 (+11)
name l[int]: v9
name c[int]: v10
name s+16[int]: v10
name s+8[int]: v9從上面大致就能看出來,一個加 8,一個加 16,很顯然是通過指針偏移來訪問的切片字段。
倘若能在編譯期間推斷出它的長度和容量,就不會在運行時偏移指針來獲取值,比如下面這種情況就不需要移動指針。
s := make([]int, 10, 20)
l := len(s)
c := cap(s)變量 l和s的值會被直接替換成10和20。
寫入
修改
s := make([]int, 10)
s[0] = 100通過索引下標修改切片的值時,在編譯期間會通過OpStore操作生成類似如下的偽代碼
p := &s
l := *(p + 8)
if !IsInBounds(l,i) {
panic()
}
ptr := (s.ptr + i * sizeof(elem) * i)
*ptr = val在生成中的某個階段的中間代碼大概率長這樣
v1 (?) = InitMem <mem>
v5 (8) = Arg <[]int> {s} (s[[]int])
v6 (?) = Const64 <int> [100]
v7 (?) = Const64 <int> [0]
v8 (+9) = SliceLen <int> v5
v9 (9) = IsInBounds <bool> v7 v8
v14 (?) = Const64 <int64> [0]
v12 (9) = SlicePtr <*int> v5
v15 (9) = Store <mem> {int} v12 v6 v1
v11 (9) = PanicBounds <mem> [0] v7 v7 v1
Exit v11 (9)
name s[[]int]: v5
name s[*int]:
name s+8[int]:可以看到代碼訪問切片長度以檢查下標是否合法,最後通過移動指針來存儲元素。
添加
通過append函數可以向切片添加元素
var s []int
s = append(s, 1, 2, 3)添加元素後,它會返回一個新的切片結構體,如果沒有擴容的話相較於源切片只是更新了長度,否則會的話會指向一個新的數組。有關於append的使用問題在結構這部分已經講的很詳細了,不再過多闡述,下面會關注於append是如何工作的。
在運行時,並沒有類似runtime.appendslice這樣的函數與之對應,添加元素的工作實際上在編譯期就已經做好了,append函數會被展開對應的中間代碼,判斷的代碼在cmd/compile/internal/walk/assign.go walkassign函數中,
case ir.OAPPEND:
// x = append(...)
call := as.Y.(*ir.CallExpr)
if call.Type().Elem().NotInHeap() {
base.Errorf("%v can't be allocated in Go; it is incomplete (or unallocatable)", call.Type().Elem())
}
var r ir.Node
switch {
case isAppendOfMake(call):
// x = append(y, make([]T, y)...)
r = extendSlice(call, init)
case call.IsDDD:
r = appendSlice(call, init) // also works for append(slice, string).
default:
r = walkAppend(call, init, as)
}可以看到分成三種情況
- 添加若干個元素
- 添加一個切片
- 添加一個臨時創建的切片
下面會講一講生成的代碼長什麼樣,這樣明白append實際上是怎麼工作的,代碼生成的過程如果感興趣可以自己去了解下。
添加元素
s = append(s, x, y, z)如果只是添加有限個元素,會由walkAppend函數展開成以下代碼
// 待添加元素數量
const argc = len(args) - 1
newLen := s.len + argc
// 是否需要擴容
if uint(newLen) <= uint(s.cap) {
s = s[:newLen]
} else {
s = growslice(s.ptr, newLen, s.cap, argc, elemType)
}
s[s.len - argc] = x
s[s.len - argc + 1] = y
s[s.len - argc + 2] = z首先計算出待添加元素數量,然後判斷是否需要擴容,最後再一個個賦值。
添加切片
s = append(s, s1...)如果是直接添加一個切片,會由appendSlice函數展開成以下代碼
newLen := s.len + s1.len
// Compare as uint so growslice can panic on overflow.
if uint(newLen) <= uint(s.cap) {
s = s[:newLen]
} else {
s = growslice(s.ptr, s.len, s.cap, s1.len, T)
}
memmove(&s[s.len-s1.len], &s1[0], s1.len*sizeof(T))還是跟之前一樣,計算新長度,判斷是否需要擴容,不同的是 go 並不會一個個去添加源切片的元素,而是選擇直接復制內存。
添加臨時切片
s = append(s, make([]T, l2)...)如果是添加一個臨時創建的切片,會由extendslice函數展開成以下代碼
if l2 >= 0 {
// Empty if block here for more meaningful node.SetLikely(true)
} else {
panicmakeslicelen()
}
s := l1
n := len(s) + l2
if uint(n) <= uint(cap(s)) {
s = s[:n]
} else {
s = growslice(T, s.ptr, n, s.cap, l2, T)
}
// clear the new portion of the underlying array.
hp := &s[len(s)-l2]
hn := l2 * sizeof(T)
memclr(hp, hn)對於臨時添加的切片,go 會獲取臨時切片的長度,如果當前切片的容量不足以足以容納,就會嘗試擴容,完事後還會清除對應部分的內存。
擴容
由結構部分的內容可以得知,切片的底層依舊是一個數組,數組是一個長度固定的數據結構,但切片長度是可變的。切片在數組容量不足時,會申請一片更大的內存空間來存放數據,也就是一個新的數組,再將舊數據拷貝過去,然後切片的引用就會指向新數組,這個過程就被稱為擴容。擴容的工作在運行時由runtime.growslice函數來完成,其函數簽名如下
func growslice(oldPtr unsafe.Pointer, newLen, oldCap, num int, et *_type) slice參數的簡單解釋
oldPtr,指向舊數組的指針newLen,新數組的長度,newLen = oldLen + numoldCap,舊切片的容量,也就等於舊數組的長度et,元素類型
它的返回值返回了一個新的切片,新切片跟原來的切片毫不相干,唯一共同點就是保存的數據是一樣的。
var s []int
s = append(s, elems...)在使用append添加元素時,會要求將其返回值覆蓋原切片,如果發生了擴容的話,返回的就是一個新切片了。
在擴容時,首先需要確定新的長度和容量,對應下面的代碼
oldLen := newLen - num
if newLen < 0 {
panic(errorString("growslice: len out of range"))
}
if et.Size_ == 0 {
return slice{unsafe.Pointer(&zerobase), newLen, newLen}
}
newcap := oldCap
// 雙倍容量
doublecap := newcap + newcap
if newLen > doublecap {
newcap = newLen
} else {
const threshold = 256
if oldCap < threshold {
newcap = doublecap
} else {
for 0 < newcap && newcap < newLen {
// newcap += 0.25 * newcap + 192
newcap += (newcap + 3*threshold) / 4
}
// 數值溢出了
if newcap <= 0 {
newcap = newLen
}
}
}由上面的代碼可知,對於容量小於 256 的切片,容量增長一倍,而容量大於等於 256 的切片,則至少會是原容量的 1.25 倍,當前切片較小時,每次都直接增大一倍,可以避免頻繁的擴容,當切片較大時,擴容的倍率就會減小,避免申請過多的內存而造成浪費。
得到新長度和容量後,再計算所需內存,對應如下代碼
var overflow bool
var lenmem, newlenmem, capmem uintptr
switch {
...
...
default:
lenmem = uintptr(oldLen) * et.Size_
newlenmem = uintptr(newLen) * et.Size_
capmem, overflow = math.MulUintptr(et.Size_, uintptr(newcap))
capmem = roundupsize(capmem)
// 最終的容量
newcap = int(capmem / et.Size_)
capmem = uintptr(newcap) * et.Size_
}
if overflow || capmem > maxAlloc {
panic(errorString("growslice: len out of range"))
}內存計算公式就是mem = cap * sizeof(et),為了方便內存對齊,過程中會將計算得到的內存向上取整為 2 的整數次方,並再次計算新容量。如果說新容量太大導致計算時數值溢出,或者說新內存超過了可以分配的最大內存,就會panic。
var p unsafe.Pointer
// 分配內存
p = mallocgc(capmem, nil, false)
memclrNoHeapPointers(add(p, newlenmem), capmem-newlenmem)
memmove(p, oldPtr, lenmem)
return slice{p, newLen, newcap}計算出所需結果後,就分配指定大小的內存,再將newLen到newCap這個區間的內存清空,然後將舊數組的數據拷貝到新切片中,最後構建切片結構體。
拷貝
src := make([]int, 10)
dst := make([]int, 20)
copy(dst, src)當使用copy函數拷貝切片時,會由cmd/compile/internal/walk.walkcopy在編譯期間生成的代碼決定以何種方式拷貝,如果是在運行時調用,就會用到函數runtime.slicecopy,該函數負責拷貝切片,函數簽名如下
func slicecopy(toPtr unsafe.Pointer, toLen int, fromPtr unsafe.Pointer, fromLen int, width uintptr) int它接收源切片和目的切片的指針和長度,以及要拷貝的長度width。這個函數的邏輯十分簡單,如下所示
func slicecopy(toPtr unsafe.Pointer, toLen int, fromPtr unsafe.Pointer, fromLen int, width uintptr) int {
if fromLen == 0 || toLen == 0 {
return 0
}
n := fromLen
if toLen < n {
n = toLen
}
if width == 0 {
return n
}
// 計算要復制的字節數
size := uintptr(n) * width
if size == 1 {
*(*byte)(toPtr) = *(*byte)(fromPtr)
} else {
memmove(toPtr, fromPtr, size)
}
return n
}width的取值,取決於兩個切片的長度最小值。可以看到的是,在復制切片的時候並不是一個個遍歷元素去復制的,而是選擇了直接把底層數組的內存整塊復制過去,當切片很大時拷貝內存帶來性能的影響並不小。
倘若不是在運行時調用,就會展開成如下形式的代碼
n := len(a)
if n > len(b) {
n = len(b)
}
if a.ptr != b.ptr {
memmove(a.ptr, b.ptr, n*sizeof(elem(a)))
}兩種方式的原理都是一樣的,都是通過拷貝內存的方式拷貝切片。memmove函數是由匯編實現的,感興趣可以去runtime/memmove_amd64.s 瀏覽細節。
清空
package main
func main() {
s := make([]int, 0, 10)
s = append(s, 1, 2, 3, 4, 5)
clear(s)
}在版本go1.21中,新增了內置函數clear函數可以用於清空切片的內容,或者說是將所有元素都置為零值。當clear函數作用於切片時,編譯器會在編譯期間由cmd/compile/internal/walk.arrayClear函數展開成下面這種形式
if len(s) != 0 {
hp = &s[0]
hn = len(s)*sizeof(elem(s))
if elem(s).hasPointer() {
memclrHasPointers(hp, hn)
}else {
memclrNoHeapPointers(hp, hn)
}
}首先判斷切片長度是否為 0,然後計算需要清理的字節數,再根據元素是否是指針分成兩種情況來處理,但最終都會用到memclrNoHeapPointers函數,其簽名如下。
func memclrNoHeapPointers(ptr unsafe.Pointer, n uintptr)它接收兩個參數,一個是指向起始地址的真,另一個就是偏移量,也就是要清理的字節數。內存起始地址為切片所持有的引用的地址,偏移量n = sizeof(et) * len,該函數是由匯編實現,感興趣可以去runtime/memclr_amd64.s查看細節。
值得一提的是,如果源代碼中嘗試使用遍歷來清空數組,例如這種
for i := range s {
s[i] = ZERO_val
}在沒有clear函數之前,通常都是這樣來清空切片。在編譯時,現在這段代碼會被cmd/compile/internal/walk.arrayRangeClear函數優化成這種形式
for i, v := range s {
if len(s) != 0 {
hp = &s[0]
hn = len(s)*sizeof(elem(s))
if elem(s).hasPointer() {
memclrHasPointers(hp, hn)
}else {
memclrNoHeapPointers(hp, hn)
}
// 停止循環
i = len(s) - 1
}
}邏輯還是跟上面的一模一樣,其中多了一行i = len(s)-1,其作用是為了在內存清除以後停止循環。
遍歷
for i, e := range s {
fmt.Println(i, e)
}在使用for range遍歷切片時,會由cmd/compile/internal/walk/range.go中的walkRange函數展開成如下形式
// 拷貝結構體
hs := s
// 獲取底層數組指針
hu = uintptr(unsafe.Pointer(hs.ptr))
v1 := 0
v2 := zero
for i := 0; i < hs.len; i++ {
hp = (*T)(unsafe.Pointer(hu))
v1, v2 = i, *hp
... body of loop ...
hu = uintptr(unsafe.Pointer(hp)) + elemsize
}可以看到的是,for range的實現依舊是通過移動指針來遍歷元素的。為了避免在遍歷時切片被更新,事先拷貝了一份結構體hs,為了避免遍歷結束後指針指向越界的內存,hu使用的uinptr類型來存放地址,在需要訪問元素的時候才轉換成unsafe.Pointer。
變量v2也就是for range中的e,在整個遍歷過程中從始至終都是一個變量,它只會被覆蓋,不會重新創建。這一點引發了困擾 go 開發者十年的循環變量問題,到了版本go.1.21官方才終於決定要打算解決,預計在後面版本的更新中,v2的創建方式可能會變成下面這樣。
v2 := *hp構造中間代碼過程這裡省略了,這並不屬於切片范圍的知識,感興趣可以自己去了解下。