性能分析
當一個程序編寫完畢後,我們對它的要求不僅僅只是能運行,還希望它是一個穩定高效的應用。通過各種各樣的測試,我們可以保證程序大部分的穩定性,而程序是否高效,就需要我們對其進行性能分析,在此前的內容中,性能分析的唯一手段就只能通過 Benchmark 來測試某一個功能單元的平均執行耗時,內存分配情況等,然而現實中對程序性能分析的需求遠遠不止於此,有時候我們需要分析程序整體的 CPU 佔用,內存佔用,堆分配情況,協程狀態,熱點代碼路徑等等,這是 Benchmark 所不能滿足的。好在 go 工具鏈集成了許多性能分析工具以供開發者使用,下面就來逐一講解。
逃逸分析
在 go 中,變量的內存分配是由編譯器決定的,一般就分配到棧上和堆上這兩個地方。如果一個本該分配到棧上的變量被分配到了堆上,那麼這種情況就稱之為逃逸,逃逸分析便是要分析程序中的內存分配情況,由於它是在編譯期進行,所以是靜態分析的一種。
TIP
前往內存分配文章了解 go 具體是如分配內存的。
引用局部指針
package main
func main() {
GetPerson()
}
type Person struct {
Name string
Mom *Person
}
func GetPerson() Person {
mom := Person{Name: "lili"}
son := Person{Name: "jack", Mom: &mom}
return son
}GetPerson函數中創建了mom變量,由於它是函數內創建的,本來應該是將其分配到棧上,但是它被son的Mom字段所引用了,並且son被作為了函數返回值返回出去,所以編譯器就將其分配到了堆上。這是一個很簡單的示例,所以理解起來不需要花費太多力氣,但如果是一個大點的項目,代碼行數有好幾萬,人工分析就不是那麼的輕松了,為此就需要使用工具來進行逃逸分析。前面提到過內存的分配是由編譯器主導的,所以逃逸分析也是由編譯器來完成,使用起來十分簡單,只需要執行如下命令:
$ go build -gcflags="-m -m -l"gcflags即編譯器gc的參數,
-m,打印出代碼優化建議,同時出現兩個會更加進行細節的輸出-l,禁用內聯優化
輸出如下
$ go build -gcflags="-m -m -l" .
# golearn/example
./main.go:13:2: mom escapes to heap:
./main.go:13:2: flow: son = &mom:
./main.go:13:2: from &mom (address-of) at ./main.go:14:35
./main.go:13:2: from Person{...} (struct literal element) at ./main.go:14:15
./main.go:13:2: from son := Person{...} (assign) at ./main.go:14:6
./main.go:13:2: flow: ~r0 = son:
./main.go:13:2: from return son (return) at ./main.go:15:2
./main.go:13:2: moved to heap: mom編譯器很明確的告訴了我們變量mom發生了逃逸,導致原因是因為返回值包含了函數內的局部指針,除了這種情況外還有其它情況可能會發生逃逸現象
::: tips
如果你對逃逸分析的細節感興趣,可以在標准庫cmd/compile/internal/escape/escape.go裡面了解到更多內容。
:::
閉包引用
閉包引用了函數外的變量,那麼該變量也會逃逸到堆上,這個很好理解。
package main
func main() {
a := make([]string, 0)
do(func() []string {
return a
})
}
func do(f func() []string) []string {
return f()
}輸出
$ go build -gcflags="-m -m -l" .
# golearn/example
./main.go:10:9: f does not escape
./main.go:4:2: main capturing by value: a (addr=false assign=false width=24)
./main.go:4:11: make([]string, 0) escapes to heap:
./main.go:4:11: flow: a = &{storage for make([]string, 0)}:
./main.go:4:11: from make([]string, 0) (spill) at ./main.go:4:11
./main.go:4:11: from a := make([]string, 0) (assign) at ./main.go:4:4
./main.go:4:11: flow: ~r0 = a:
./main.go:4:11: from return a (return) at ./main.go:6:3
./main.go:4:11: make([]string, 0) escapes to heap
./main.go:5:5: func literal does not escape空間不足
棧空間不足時,也會發生逃逸現象,下面創建的切片申請了1<<15的容量
package main
func main() {
_ = make([]int, 0, 1<<15)
}輸出
$ go build -gcflags="-m -m -l" .
# golearn/example
./main.go:4:10: make([]int, 0, 32768) escapes to heap:
./main.go:4:10: flow: {heap} = &{storage for make([]int, 0, 32768)}:
./main.go:4:10: from make([]int, 0, 32768) (too large for stack) at ./main.go:4:10
./main.go:4:10: make([]int, 0, 32768) escapes to heap長度未知
當切片的長度是一個變量的時候,由於其長度未知,便會發生逃逸現象(map 並不會)
package main
func main() {
n := 100
_ = make([]int, n)
}輸出
$ go build -gcflags="-m -m -l" .
# golearn/example
./main.go:5:10: make([]int, n) escapes to heap:
./main.go:5:10: flow: {heap} = &{storage for make([]int, n)}:
./main.go:5:10: from make([]int, n) (non-constant size) at ./main.go:5:10
./main.go:5:10: make([]int, n) escapes to heap還有一種特殊情況便是函數參數為...any類型時也可能會發生逃逸
package main
import "fmt"
func main() {
n := 100
fmt.Println(n)
}輸出
$ go build -gcflags="-m -m -l" .
# golearn/example
./main.go:7:14: n escapes to heap:
./main.go:7:14: flow: {storage for ... argument} = &{storage for n}:
./main.go:7:14: from n (spill) at ./main.go:7:14
./main.go:7:14: from ... argument (slice-literal-element) at ./main.go:7:13
./main.go:7:14: flow: {heap} = {storage for ... argument}:
./main.go:7:14: from ... argument (spill) at ./main.go:7:13
./main.go:7:14: from fmt.Println(... argument...) (call parameter) at ./main.go:7:13
./main.go:7:13: ... argument does not escape
./main.go:7:14: n escapes to heap我們之所以要進行逃逸分析,把內存分配控制的這麼細,主要是為了減輕 GC 壓力,不過 go 並不是 c 語言,內存分配的最終決定權依舊掌握在編譯器手裡,除了極端的性能要求情況下,大多數時候我們也無需太過於專注內存分配的細節,畢竟 GC 誕生的目的就是為了解放開發者。
小細節
對於一些引用類型,當確認以後不會再用到它時,我們可以將其置為nil,來告訴 GC 可以將其回收。
type Writer struct {
buf []byte
}
func (w Writer) Close() error {
w.buff = nil
return nil
}pprof
pprof(program profiling),是一個程序性能分析的利器,它會對程序運行時的數據進行部分采樣,涵蓋了 cpu,內存,協程,鎖,堆棧信息等許多方面,然後再使用工具對采樣的數據進行分析並展示結果。
所以 pprof 的使用步驟就只有兩步:
- 采集數據
- 分析結果
采集
數據采集的方式有兩種,自動和手動,各有優劣。在此之前,編寫一個簡單的函數來模擬內存和 cpu 的消耗
func Do() {
for i := 0; i < 10; i++ {
slice := makeSlice()
sortSlice(slice)
}
}
func makeSlice() []int {
var s []int
for range 1 << 24 {
s = append(s, rand.Int())
}
return s
}
func sortSlice(s []int) {
slices.Sort(s)
}手動
手動采集就是通過代碼來控制,其優點是可控,靈活,可以自定義,直接在代碼中使用 pprof 需要引入runtime/pprof包
package main
import (
"log"
"os"
"runtime/pprof"
)
func main() {
Do()
w, _ := os.Create("heap.pb")
heapProfile := pprof.Lookup("heap")
err := heapProfile.WriteTo(w, 0)
if err != nil {
log.Fatal(err)
}
}pprof.Lookup支持的參數如下面代碼所示
profiles.m = map[string]*Profile{
"goroutine": goroutineProfile,
"threadcreate": threadcreateProfile,
"heap": heapProfile,
"allocs": allocsProfile,
"block": blockProfile,
"mutex": mutexProfile,
}該函數會將采集到的數據寫入到指定文件中,在寫入時傳入的數字有以下幾個含義
0,寫入壓縮後的 Protobuf 數據,沒有可讀性1,寫入文本格式的數據,能夠閱讀,http 接口返回的就是這一種數據2,僅goroutine可用,表示打印panic風格的堆棧信息
采集 cpu 數據需要單獨使用 pprof.StartCPUProfile函數,它需要一定的時間進行采樣,且其原始數據不可讀,如下所示
package main
import (
"log"
"os"
"runtime/pprof"
"time"
)
func main() {
Do()
w, _ := os.Create("cpu.out")
err := pprof.StartCPUProfile(w)
if err != nil {
log.Fatal(err)
}
time.Sleep(time.Second * 10)
pprof.StopCPUProfile()
}采集 trace 的數據也是同樣如此
package main
import (
"log"
"os"
"runtime/trace"
"time"
)
func main() {
Do()
w, _ := os.Create("trace.out")
err := trace.Start(w)
if err != nil {
log.Fatal(err)
}
time.Sleep(time.Second * 10)
trace.Stop()
}自動
net/http/pprof包將上面的分析函數包裝成了 http 接口,並注冊到了默認路由中,如下所示
package pprof
import ...
func init() {
http.HandleFunc("/debug/pprof/", Index)
http.HandleFunc("/debug/pprof/cmdline", Cmdline)
http.HandleFunc("/debug/pprof/profile", Profile)
http.HandleFunc("/debug/pprof/symbol", Symbol)
http.HandleFunc("/debug/pprof/trace", Trace)
}這使得我們可以直接一鍵運行 pprof 數據采集
package main
import (
"net/http"
// 記得要導入這個包
_ "net/http/pprof"
)
func main() {
go func(){
http.ListenAndServe(":8080", nil)
}
for {
Do()
}
}此時打開瀏覽器訪問http://127.0.0.1:8080/debug/pprof,就會出現這樣的頁面
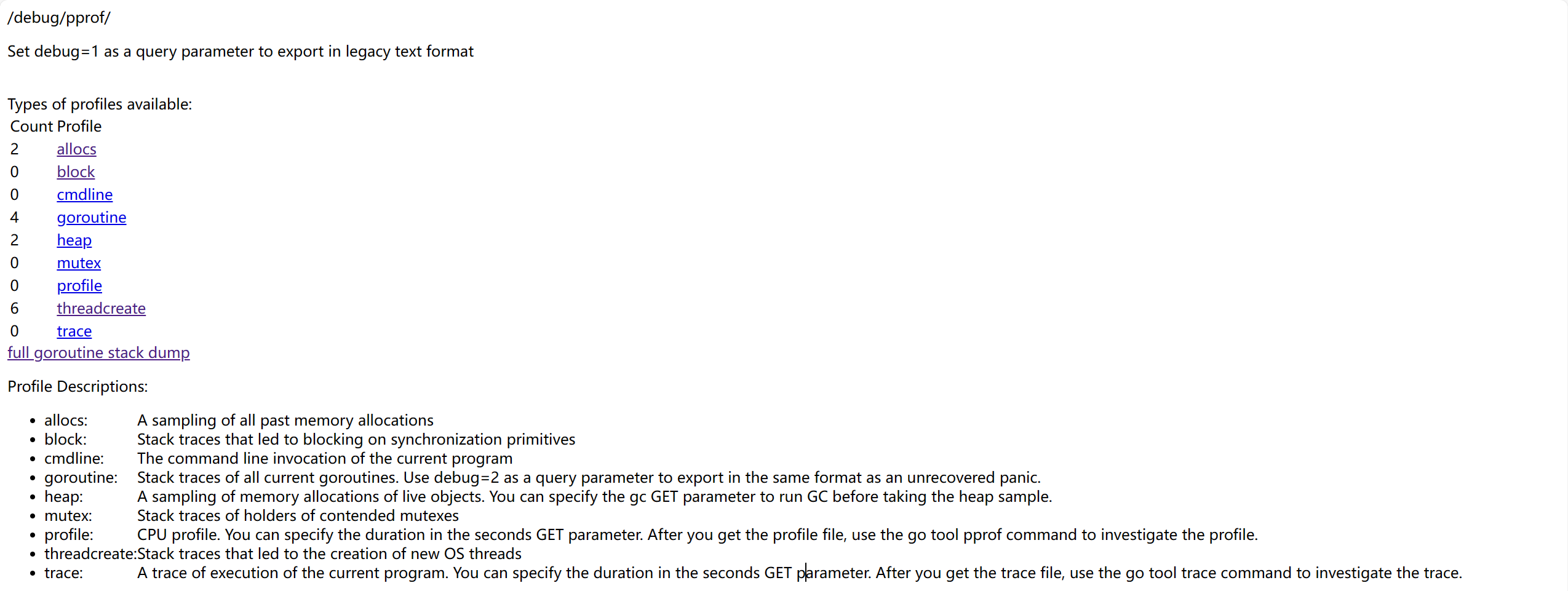
頁面中有幾個可供選擇的選項,它們分別代表了
allocs:內存分配抽樣block:同步原語的阻塞跟蹤cmdline:當前程序的命令行調用goroutine:跟蹤所有的協程heap:對於存活對象的內存分配抽樣mutex:互斥鎖相關信息的跟蹤profile:cpu 分析,會分析一段時間並下載一個文件threadcreate:分析導致創建新 OS 線程原因trace:當前程序執行情況的跟蹤,同樣會下載一個文件
這裡的數據大多數可讀性並不高,主要是拿來給工具分析用的,如下所圖
具體的分析工作要留到後面再進行,除了profile和trace兩個選項之外,如果你想要在網頁中下載數據文件,可以將query參數debug=1去掉。也可以將這些接口集成到自己的路由中而不是使用默認路由,如下所示
package main
import (
"net/http"
"net/http/pprof"
)
func main() {
mux := http.NewServeMux()
mux.HandleFunc("/trace", pprof.Trace)
servre := &http.Server{
Addr: ":8080",
Handler: mux,
}
servre.ListenAndServe()
}如此一來,也能其集成到其它的 web 框架中,比如gin,iris等等。
分析
在得到了采集的數據文件後,有兩種方式進行分析,命令行或網頁,兩者都需要借助pprof命令行工具,go 默認集成該工具,所以不需要額外下載。
pprof 開源地址:google/pprof: pprof is a tool for visualization and analysis of profiling data (github.com)
命令行
將此前收集到的數據文件作為參數
$ go tool pprof heap.pb如果數據是由 web 采集的話,用 web url 替換掉文件名即可。
$ go tool pprof -http :8080 http://127.0.0.1/debug/pprof/heap然後就會出現一個交互式的命令行
15:27:38.3266862 +0800 CST
Type: inuse_space
Time: Apr 15, 2024 at 3:27pm (CST)
No samples were found with the default sample value type.
Try "sample_index" command to analyze different sample values.
Entering interactive mode (type "help" for commands, "o" for options)
(pprof)輸入 help,可以查看其它命令
Commands:
callgrind Outputs a graph in callgrind format
comments Output all profile comments
disasm Output assembly listings annotated with samples
dot Outputs a graph in DOT format
eog Visualize graph through eog
evince Visualize graph through evince
...在命令行中查看數據一般使用top命令,也可以用traces命令不過它的輸出很冗長,top命令只是簡單的看個大概。
(pprof) top 5
Showing nodes accounting for 117.49MB, 100% of 117.49MB total
flat flat% sum% cum cum%
117.49MB 100% 100% 117.49MB 100% main.makeSlice (inline)
0 0% 100% 117.49MB 100% main.Do
0 0% 100% 117.49MB 100% main.main
0 0% 100% 117.49MB 100% runtime.main簡單介紹一些其中的一些指標(cpu 同理)
flat,代表著當前函數所消耗的資源cum,當前函數及其後續調用鏈所消耗的資源總和flat%,flat/totalcum%,cum/total
我們可以很明顯的看到整個調用棧的內存佔用是 117.49MB,由於Do函數本身什麼都沒做,只是調用了其它函數,所以其flat的指標是 0,創建切片的事情是由makeSlice函數在負責,所以其flat指標是100%。
我們可以將轉換可視化的格式,pprof支持相當多的格式,比如 pdf,svg,png,gif 等等(需要安裝Graphviz)。
(pprof) png
Generating report in profile001.png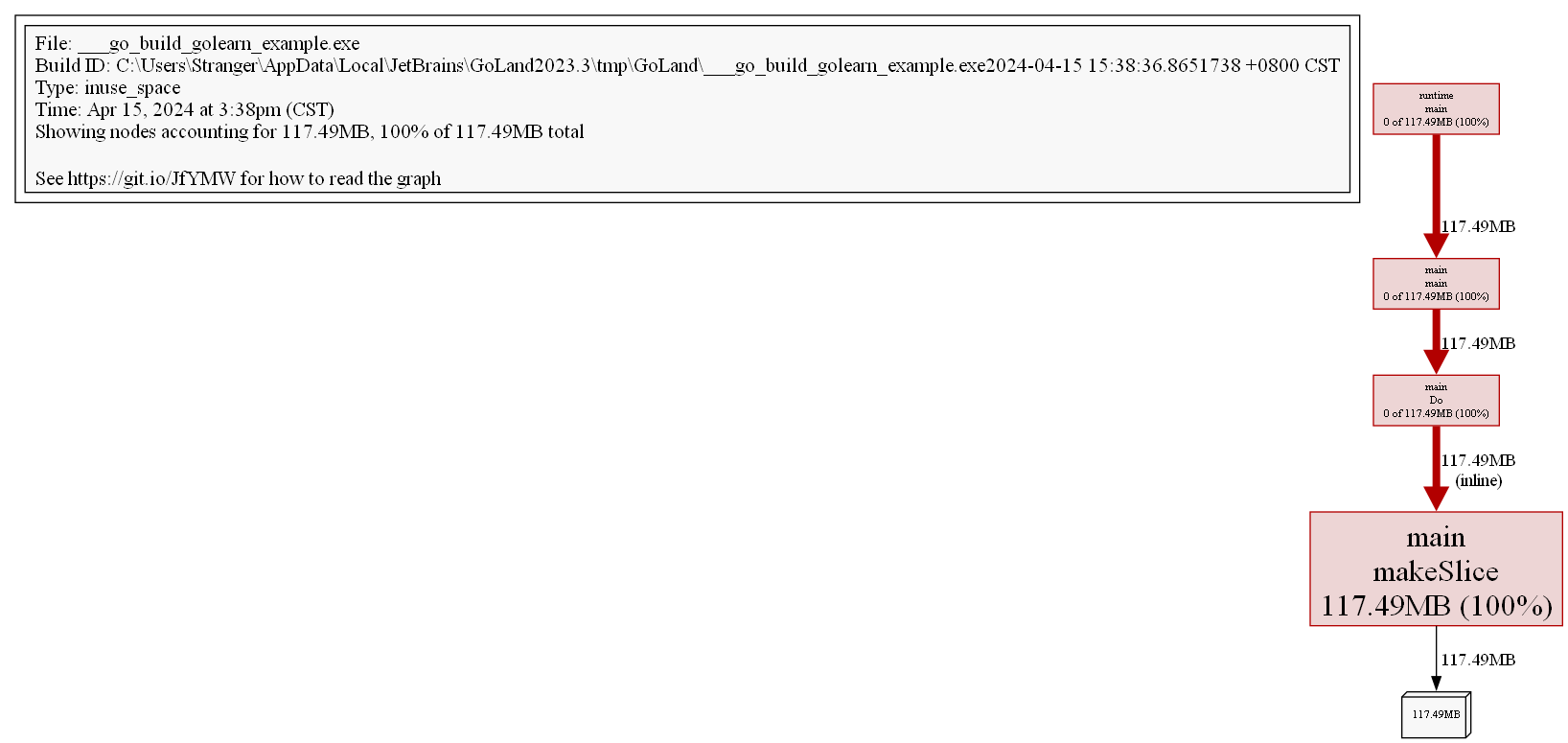
通過圖片我們可以更加清晰的看到整個調用棧的內存情況。
通過list命令以源代碼的形式查看
(pprof) list Do
Total: 117.49MB
ROUTINE ======================== main.Do in D:\WorkSpace\Code\GoLeran\golearn\example\main.go
0 117.49MB (flat, cum) 100% of Total
. . 21:func Do() {
. . 22: for i := 0; i < 10; i++ {
. 117.49MB 23: slice := makeSlice()
. . 24: sortSlice(slice)
. . 25: }
. . 26:}
. . 27:
. . 28:func makeSlice() []int {對於圖片和源代碼而言,還可以用web和weblist命令在瀏覽器中查看圖片和源代碼。
網頁
在此之前為了數據更加多樣化,修改一下模擬的函數
func Do1() {
for i := 0; i < 10; i++ {
slice := makeSlice()
sortSlice(slice)
}
}
func Do2() {
for i := 0; i < 10; i++ {
slice := makeSlice()
sortSlice(slice)
}
}
func makeSlice() []int {
var s []int
for range 1 << 12 {
s = append(s, rand.Int())
}
return s
}
func sortSlice(s []int) {
slices.Sort(s)
}網頁分析可以可視化結果,免去了我們手動操作命令行,在使用網頁分析時,只需執行如下命令
$ go tool pprof -http :8080 heap.pb如果數據是由 web 采集的話,將 web url 替換掉文件名即可
$ go tool pprof -http :8080 http://127.0.0.1:9090/debug/pprof/heap
$ go tool pprof -http :8080 http://127.0.0.1:9090/debug/pprof/profile
$ go tool pprof -http :8080 http://127.0.0.1:9090/debug/pprof/goroutineTIP
關於如何分析數據,前往pprof: How to read the graph了解更多
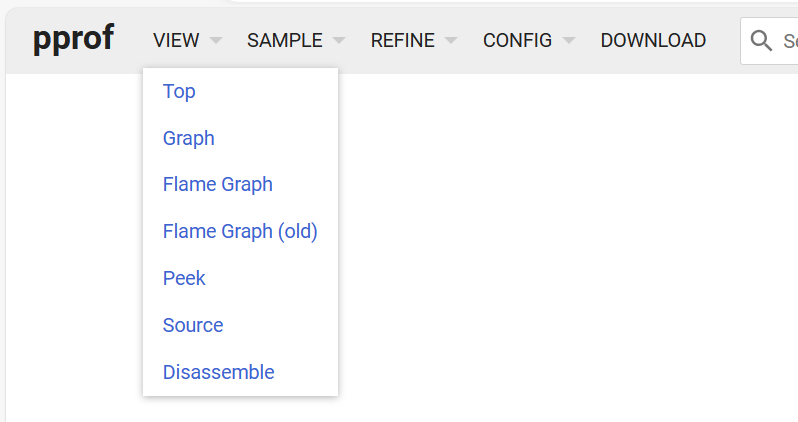
網頁中總共有 6 個可查看的項
- Top,同命令 top
- Graph,直線圖
- Flame Graph,火焰圖
- Peek,
- Source,查看源代碼
- Disassemble,反匯編查看
對於內存而言四個維度可以分析
alloc_objects:目前已分配的所有對象數量,包括已釋放alloc_spcae:目前為止已分配的所有內存空間,包括已釋放inuse_objects:正在使用的對象數量inuse_space:正在使用的內存空間
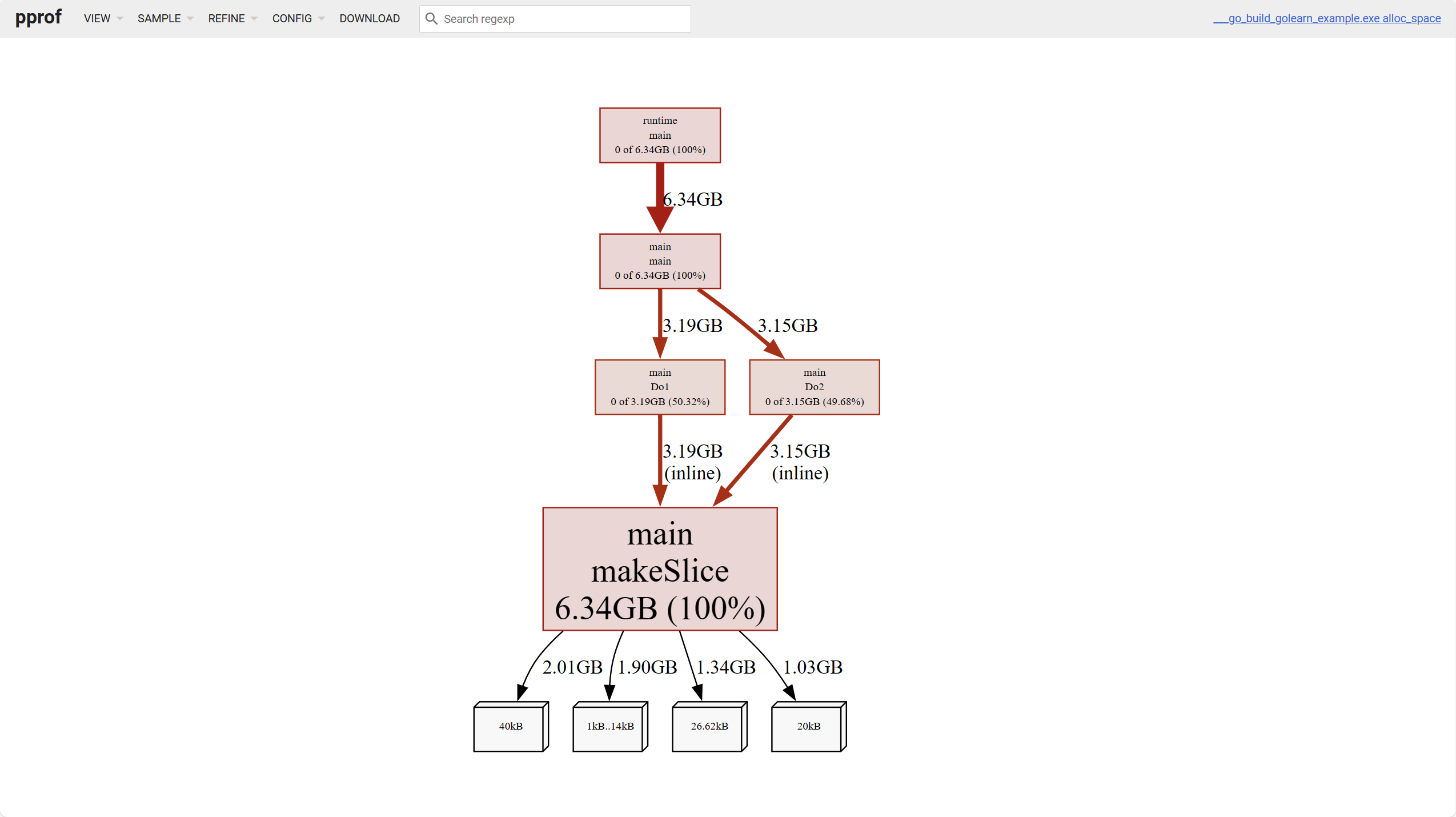
上圖最下方的白色葉子節點代表著不同大小的對象佔用。
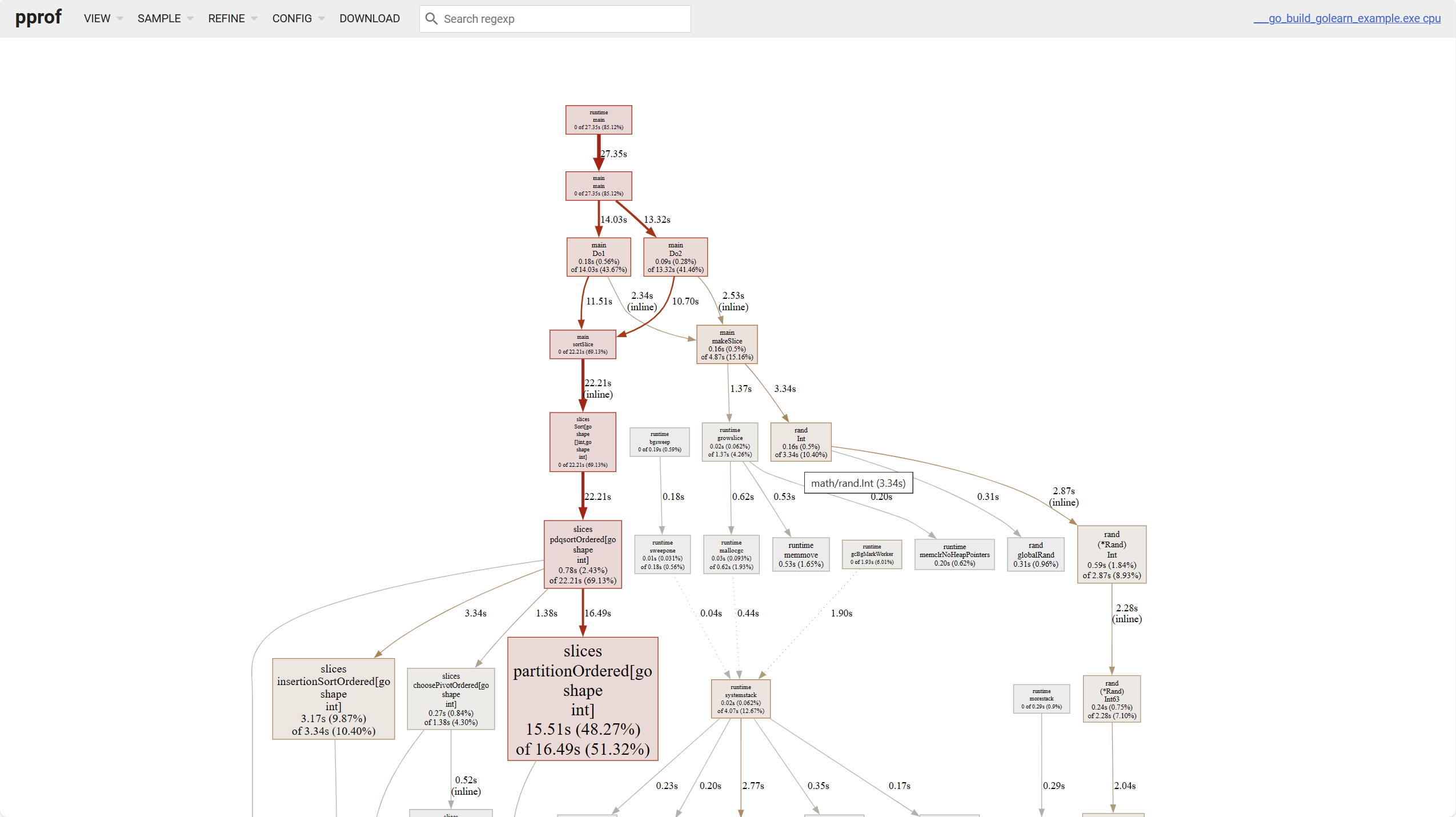
關於折線圖,有幾個點要注意
- 塊的顏色越深,佔用越高,線越粗,佔用越高
- 實線代表著直接調用,虛線代表著略過了一些調用鏈。

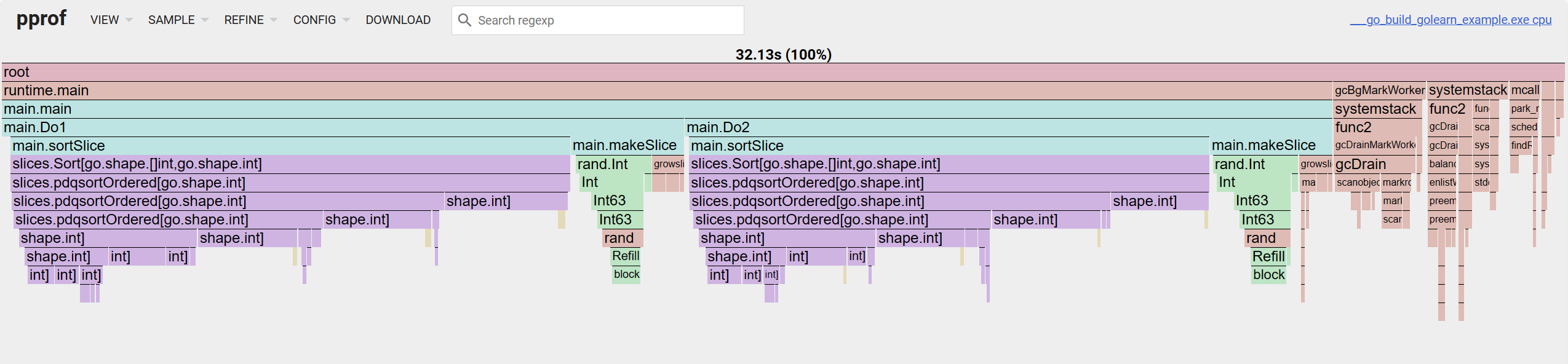
對於火焰圖而言,從上往下看是調用鏈,從左往右看是 cum 的佔用百分比。
trace
pprof 主要負責分析程序的資源佔用,而 trace 更適合跟蹤程序的運行細節,它與前者的數據文件互不兼容,由go tool trace命令來完成相關的分析工作。
如果是手動采集的數據,可以將文件名作為參數
$ go tool trace trace.out如果是自動采集,也是同樣的道理
$ curl http://127.0.0.1:8080/debug/pprof/trace > trace.out && go tool trace trace.out執行後會開啟一個 web server
2024/04/15 17:15:40 Preparing trace for viewer...
2024/04/15 17:15:40 Splitting trace for viewer...
2024/04/15 17:15:40 Opening browser. Trace viewer is listening on http://127.0.0.1:51805打開後頁面大概如下所示
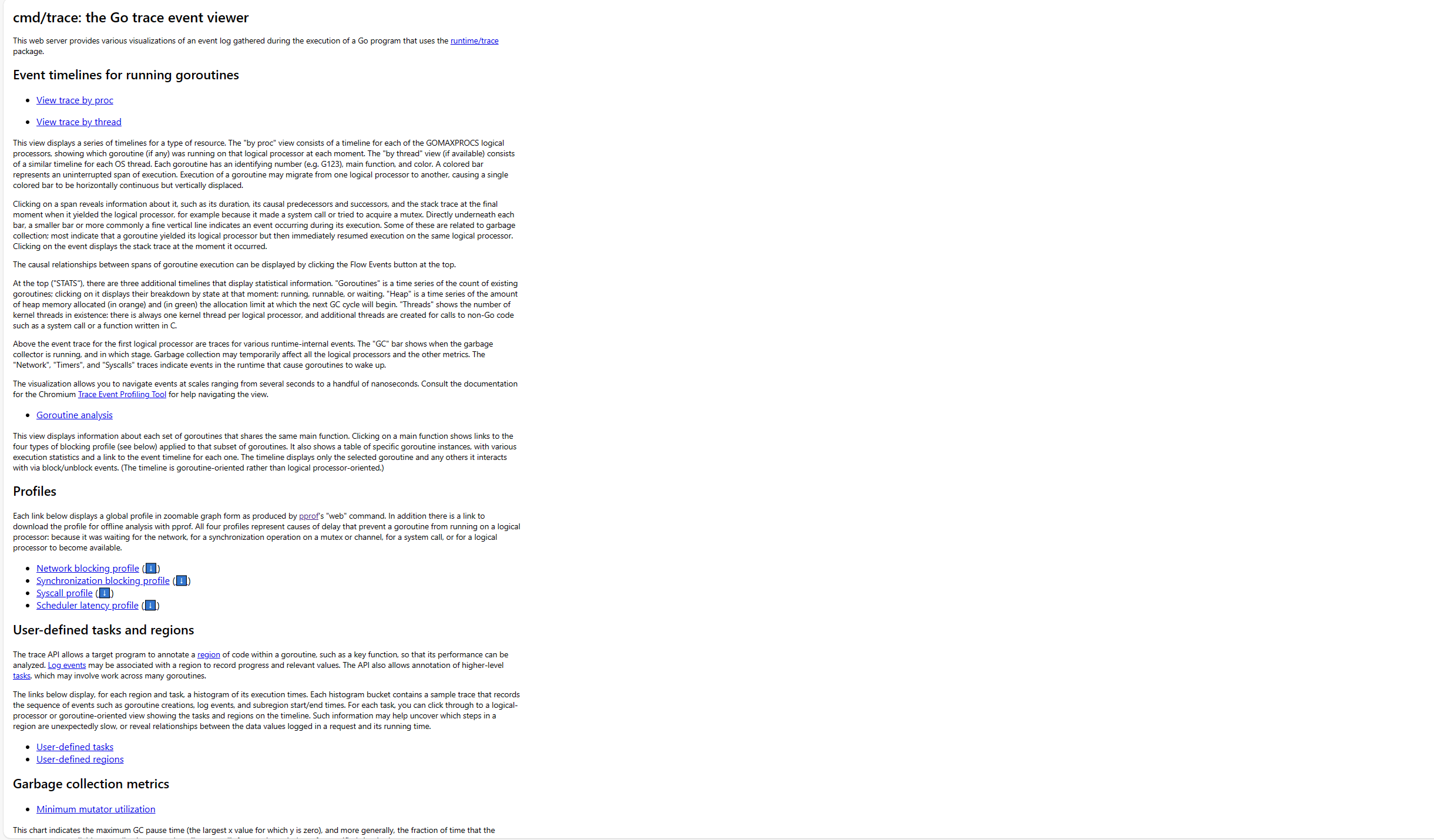
這裡面主要包含了以下幾個部分,這些數據要看懂還挺不容易的。
Event timelines for running goroutines
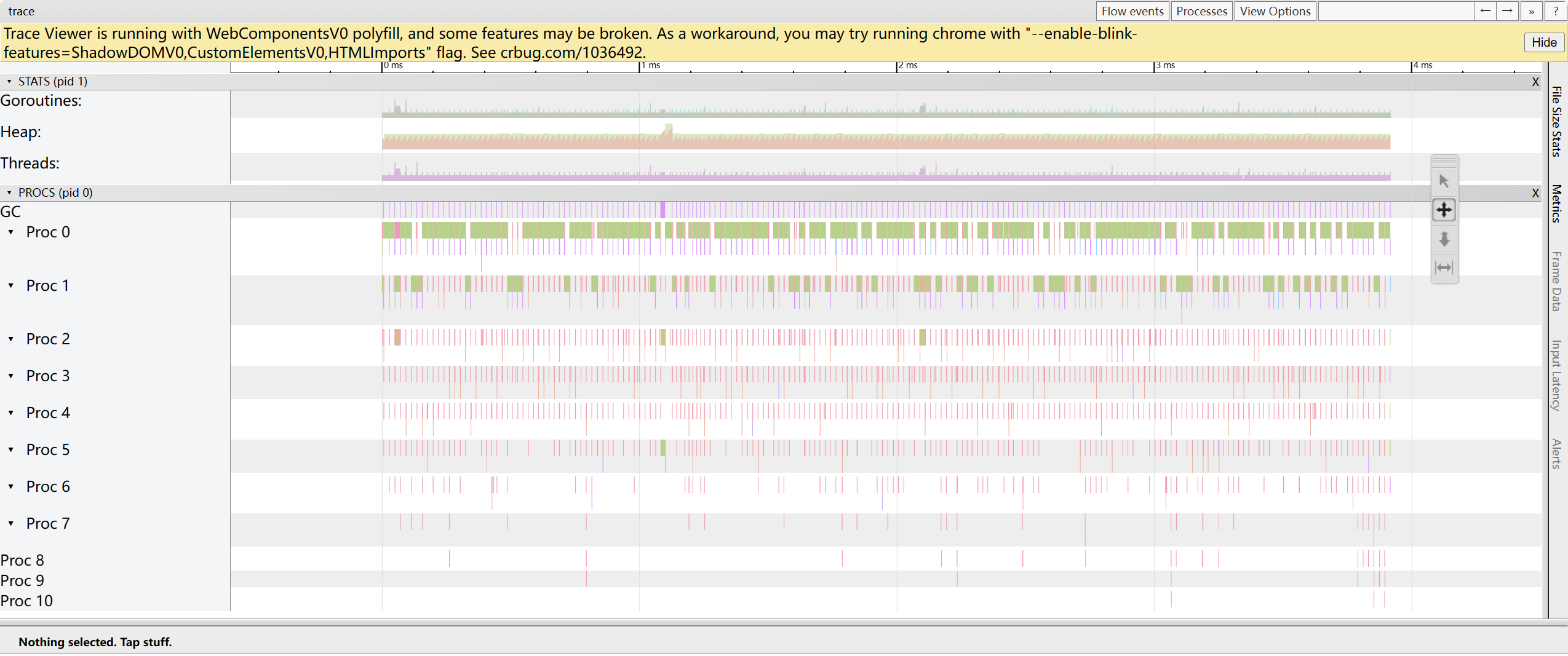
trace by proc:顯示每一時刻在該處理器上運行的協程時間線
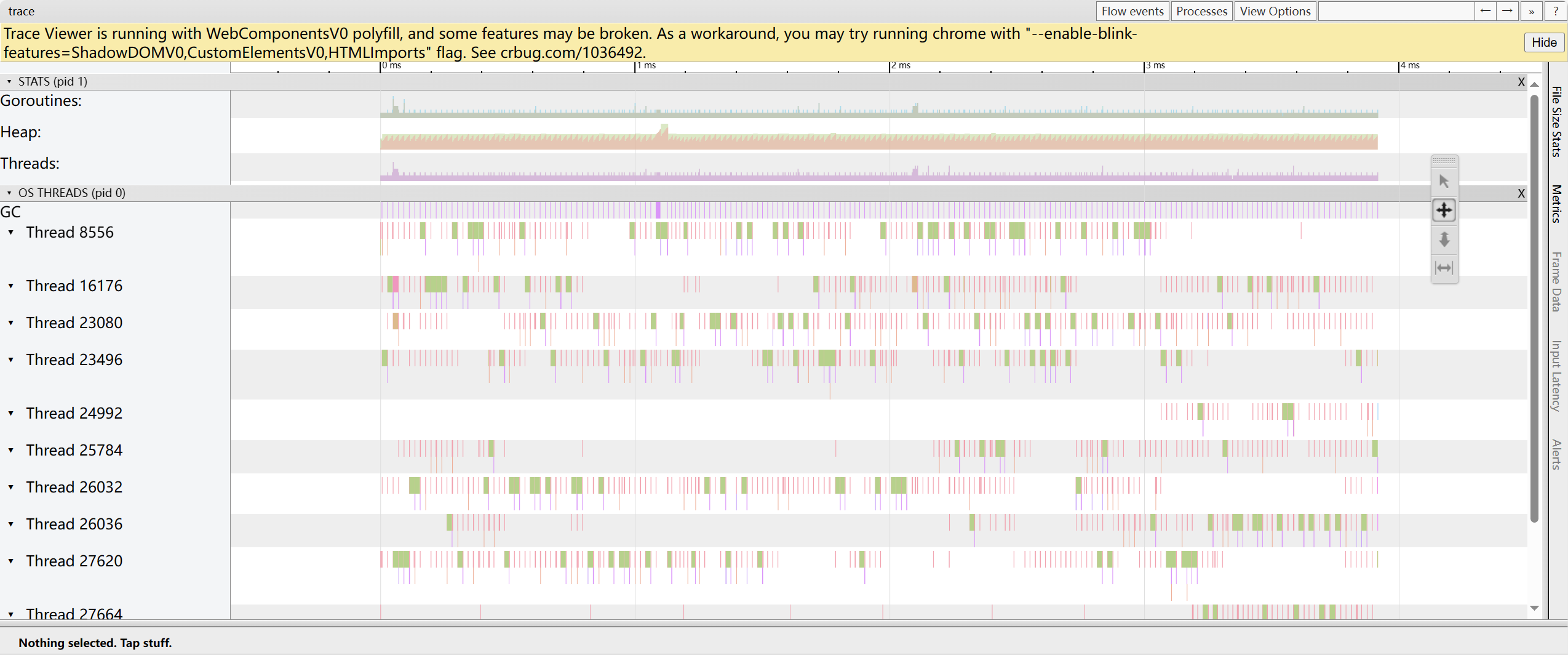
trace by thread:顯示每一時刻在 OS 線程上運行的協程時間線
Goroutine analysis:展示每組主函數的協程相關統計信息


Profiles
- Network blocking profile: 因網絡 IO 而阻塞的協程信息
- Synchronization blocking profile:因同步原語而阻塞的協程信息
- Syscall profile:因系統調用而阻塞的協程信息
User-defined tasks and regions
- User-defined tasks:用戶定義任務的相關協程信息
- User-defined regions:用戶定義代碼區域的相關協程信息
Garbage collection metrics
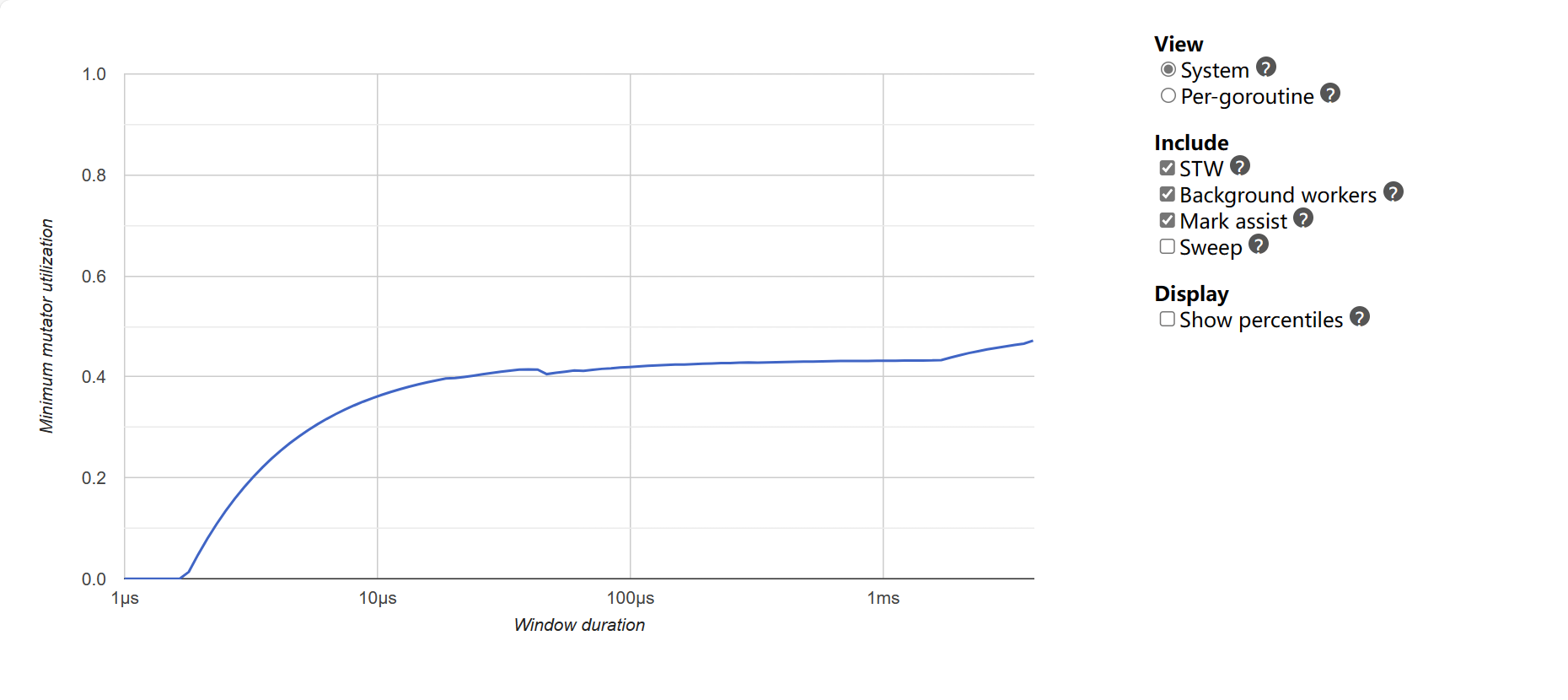
Minimum mutator utilization:展示最近 GC 的最大耗時