Protobuf
Site officiel : Protocol Buffers | Google Developers
Introduction
Tutoriel officiel : Protocol Buffer Basics: Go | Protocol Buffers | Google Developers
Protocol Buffers est un mécanisme de sérialisation de données structurées, indépendant du langage et du protocole, open source depuis 2008 par Google. Il est plus rapide lors de l'empaquetage et du dépaquetage, et est principalement utilisé dans le domaine de la communication RPC. Il permet de définir la manière dont les données sont structurées, puis d'utiliser du code source généré spécialement pour lire et écrire facilement des données structurées dans divers flux de données, et ce dans différents langages. Dans la suite, Protocol Buffers sera désigné par protobuf.
protobuf est assez populaire, en particulier dans l'écosystème Go. gRPC l'utilise comme mécanisme de sérialisation pour le transport des protocoles.
Syntaxe
Commençons par un exemple pour voir à quoi ressemble un fichier protobuf. Globalement, sa syntaxe est très simple et peut être maîtrisée en quelques minutes. Voici un exemple de fichier nommé search.proto. L'extension des fichiers protobuf est .proto.
syntax = "proto3";
message SearchRequest {
string query = 1;
string number = 2;
}
message SearchResult {
string data = 1;
}
service SearchService {
rpc Search(SearchRequest) returns(SearchResult);
}- La première ligne
syntax = "proto3";indique l'utilisation de la syntaxeproto3. Par défaut, la syntaxeproto3est utilisée. - La déclaration
messageest similaire à une structure, c'est la structure de base enproto. SearchRequestdéfinit trois champs, chaque champ a un nom et un type.servicedéfinit un service. Un service contient une ou plusieurs interfaces RPC.- Une interface RPC doit avoir exactement un paramètre et une valeur de retour. Leur type doit être
message, pas un type primitif.
Notez également que chaque ligne d'un fichier proto doit se terminer par un point-virgule.
Commentaires
Le style de commentaires est identique à celui de Go.
syntax = "proto3";
/* Commentaire
* Commentaire */
message SearchRequest {
string query = 1; //Commentaire
string number = 2;
}Types
Les modificateurs de type ne peuvent apparaître que dans un message, pas isolément.
Types primitifs
| proto Type | Go Type |
|---|---|
| double | float64 |
| float | float32 |
| int32 | int32 |
| int64 | int64 |
| uint32 | uint32 |
| uint64 | uint64 |
| sint32 | int32 |
| sint64 | int64 |
| fixed32 | uint32 |
| fixed64 | uint64 |
| sfixed32 | int32 |
| sfixed64 | int64 |
| bool | bool |
| string | string |
| bytes | []byte |
Tableaux
Ajoutez le modificateur repeated devant un type primitif pour indiquer qu'il s'agit d'un type tableau, correspondant aux slices en Go.
message Company {
repeated string employee = 1;
}map
Pour définir un type map en protobuf, le format est le suivant
map<key_type, value_type> map_field = N;key_type doit être un nombre ou une chaîne, value_type n'a pas de restriction de type. Voici un exemple
message Person {
map<string, int64> cards = 1;
}Champs
En fait, proto n'est pas un type clé-valeur traditionnel. Dans le fichier proto déclaré, aucune donnée concrète n'apparaît. Ce qui suit le = de chaque champ doit être un numéro unique dans le message actuel. Ces numéros sont utilisés pour identifier et définir ces champs dans le corps du message binaire. Les numéros commencent à 1. Les numéros 1-15 occupent 1 octet, 16-2047 occupent deux octets. Par conséquent, essayez d'attribuer les numéros 1-15 aux champs fréquemment utilisés pour économiser de l'espace, et laissez un peu de place pour les champs qui pourraient devenir fréquents par la suite.
Un champ dans un message doit suivre les règles suivantes
singular: C'est le type par défaut. Dans unmessagebien formé, il ne peut y avoir que 0 ou 1 champ de ce type, c'est-à-dire que le même champ ne peut pas être dupliqué. La déclaration suivante provoquera une erreur.protobufsyntax = "proto3"; message SearchRequest { string query = 1; string number = 2; string number = 3;//Champ dupliqué }optional: Similaire àsingular, mais permet de vérifier explicitement si la valeur du champ a été définie. Il peut y avoir deux cas :set: sera sérialiséunset: ne sera pas sérialisé
repeated: Ce type de champ peut apparaître 0 ou plusieurs fois. Les valeurs répétées seront conservées dans l'ordre (en fait, c'est un tableau, qui permet au même type de valeur d'apparaître plusieurs fois, dans l'ordre d'apparition, c'est l'index).map: Type de champ clé-valeur, déclaré comme suitprotobufmap<string,int32> config = 3;
Champs réservés
Le mot-clé reserve permet de déclarer des champs réservés. Une fois un numéro de champ réservé déclaré, il ne peut plus être utilisé comme numéro ou nom pour d'autres champs, et une erreur de compilation se produira. La réponse officielle de Google est : si un fichier proto supprime certains numéros dans une nouvelle version, d'autres utilisateurs pourraient réutiliser ces numéros supprimés à l'avenir. Mais si l'on revient aux anciens numéros, il y aura une incohérence entre les champs et les numéros, provoquant des erreurs. Les champs réservés servent d'avertissement au moment de la compilation, vous rappelant que vous ne pouvez pas utiliser ce champ réservé, sinon la compilation échouera.
syntax = "proto3";
message SearchRequest {
string query = 1;
string number = 2;
map<string, int32> config = 3;
repeated string a = 4;
reserved "a"; //Déclarer un champ de nom spécifique comme champ réservé
reserved 1 to 2; //Déclarer une séquence de numéros comme champs réservés
reserved 3,4; //Déclaration
}Ainsi, ce fichier ne passera pas la compilation.
Champs dépréciés
Si un champ est déprécié, vous pouvez l'écrire comme suit.
message Body {
string name = 1 [deprecated = true];
}Énumérations
Vous pouvez déclarer des constantes d'énumération et les utiliser comme type de champ. Notez que le premier élément de l'énumération doit être zéro, car la valeur par défaut d'un élément d'énumération est le premier élément.
syntax = "proto3";
enum Type {
GET = 0;
POST = 1;
PUT = 2;
DELETE = 3;
}
message SearchRequest {
string query = 1;
string number = 2;
map<string, int32> config = 3;
repeated string a = 4;
Type type = 5;
}Lorsqu'il existe des éléments d'énumération avec la même valeur dans l'énumération, vous pouvez utiliser des alias d'énumération
syntax = "proto3";
enum Type {
option allow_alias = true; //Il faut activer l'option permettant d'utiliser des alias
GET = 0;
GET_ALIAS = 0; //Alias de l'élément GET
POST = 1;
PUT = 2;
DELETE = 3;
}
message SearchRequest {
string query = 1;
string number = 2;
map<string, int32> config = 3;
repeated string a = 4;
Type type = 5;
}Messages imbriqués
message Outer { // Niveau 0
message MiddleAA { // Niveau 1
message Inner { // Niveau 2
int64 ival = 1;
bool booly = 2;
}
}
message MiddleBB { // Niveau 1
message Inner { // Niveau 2
int32 ival = 1;
bool booly = 2;
}
}
}Un message peut contenir des déclarations imbriquées de message, comme des structures imbriquées.
Package
Vous pouvez ajouter un modificateur de package optionnel à un fichier protobuf pour éviter les conflits de noms entre les types de messages de protocole.
package foo.bar;
message Open { ... }Ensuite, vous pouvez utiliser le nom du package lors de la définition des champs de type message :
message Foo {
...
foo.bar.Open open = 1;
...
}Import
L'importation permet à plusieurs fichiers protobuf de partager des définitions. La syntaxe est la suivante. L'extension de fichier ne doit pas être omise lors de l'importation.
import "a/b/c.proto";L'importation utilise toujours des chemins relatifs. Ce chemin relatif n'est pas celui entre le fichier d'importation et le fichier importé, mais dépend du chemin de balayage spécifié lors de la génération du code par le compilateur protoc. Supposons la structure de fichiers suivante
pb_learn
│ common.proto
│
├─monster
│ monster.proto
│
└─player
health.proto
player.protoSi nous devons générer uniquement le code de la partie player, et que seul le répertoire player est spécifié comme chemin de balayage, alors l'importation mutuelle entre health.proto et player.proto peut se faire en écrivant directement le nom du fichier, par exemple player.proto important health.proto.
import "health.proto";Si player.proto importe common.proto ou des fichiers du répertoire monster, la compilation échouera. Donc l'écriture suivante est totalement erronée, car le compilateur ne peut pas trouver ces fichiers.
import "../common.proto"; // Écriture incorrecteTIP
Soit dit en passant, les symboles .., . ne sont pas autorisés dans les chemins d'importation.
Supposons que lors de la compilation, pb_learn soit spécifié comme chemin de balayage. Alors vous pouvez importer des fichiers d'autres répertoires via des chemins relatifs. Le chemin d'importation réel est le chemin absolu du fichier relatif à pb_learn. Voici un exemple d'importation d'autres fichiers par player.proto :
import "common.proto";
imrpot "monster/monster.proto";
import "player/health.proto";Même health.proto dans le même répertoire doit maintenant utiliser un chemin relatif. Donc dans un projet, nous créons généralement un dossier séparé pour stocker tous les fichiers protobuf, et spécifions ce dossier comme chemin de balayage lors de la compilation. Tous les comportements d'importation dans ce répertoire sont basés sur son chemin relatif.
TIP
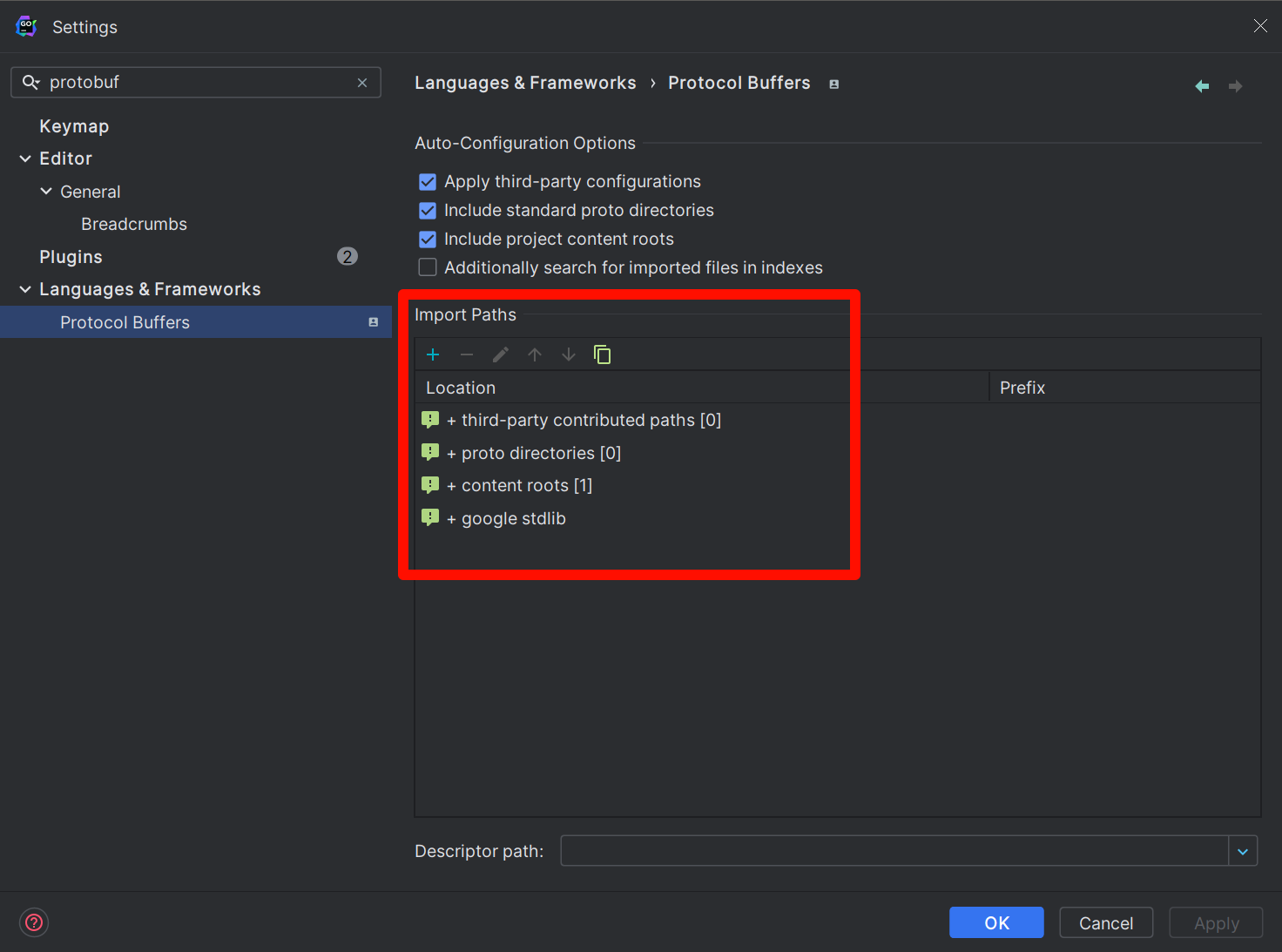
Si vous utilisez l'éditeur GoLand, pour les répertoires protobuf que vous créez, ils ne peuvent pas être résolus par défaut et des erreurs apparaîtront. Pour que GoLand les reconnaisse, vous devez définir manuellement le chemin de balayage. Le principe est exactement le même que ci-dessus. La méthode est la suivante, ouvrez les paramètres :
File | Settings | Languages & Frameworks | Protocol BuffersDans Import Paths, ajoutez manuellement le chemin de balayage. Ce chemin doit être identique à celui spécifié lors de la compilation.
Any
Le type Any permet d'utiliser des messages comme type intégré sans avoir besoin de leur définition proto. Nous pouvons importer directement les types définis par Google, qui sont intégrés et ne nécessitent pas d'écriture manuelle.
import "google/protobuf/any.proto";
message ErrorStatus {
string message = 1;
repeated google.protobuf.Any details = 2;
}Google a prédéfini de nombreux autres types, consultez protobuf/ptypes at master · golang/protobuf (github.com) pour en savoir plus, principalement :
- Encapsulation des types primitifs
- Types temporels
- Type Duration
Leurs définitions protobuf se trouvent dans le répertoire include du compilateur protoc.
OneOf
L'explication de la documentation officielle est très complexe. En termes simples, cela signifie qu'un champ peut avoir plusieurs types possibles lors de la transmission, mais qu'un seul type sera finalement utilisé. Son contenu ne permet pas les champs modifiés par repeated. C'est comme le union en langage C.
message Stock {
// Données spécifiques à Stock
}
message Currency {
// Données spécifiques à Currency
}
message ChangeNotification {
int32 id = 1;
oneof instrument {
Stock stock = 2;
Currency currency = 3;
}
}Service
Le mot-clé service permet de définir un service RPC. Un service RPC contient plusieurs interfaces RPC. Les interfaces sont divisées en interfaces unaires et interfaces en flux.
message Body {
string name = 1;
}
service ExampleService {
rpc DoSomething(Body) returns(Body);
}Les interfaces en flux sont divisées en flux unidirectionnels et flux bidirectionnels, généralement modifiés par le mot-clé stream. Voici un exemple :
message Body {
string name = 1;
}
service ExampleService {
// Flux client
rpc DoSomething(stream Body) returns(Body);
// Flux serveur
rpc DoSomething1(Body) returns(stream Body);
// Flux bidirectionnel
rpc DoSomething2(stream Body) returns(stream Body);
}Le flux signifie que dans une connexion, les données sont envoyées continuellement sur une longue période, au lieu du simple échange question-réponse des interfaces unaires.
Empty
empty est en fait un message vide, correspondant à une structure vide en Go. Il est rarement utilisé pour modifier des champs, principalement pour indiquer qu'une interface RPC n'a pas besoin de paramètres ou n'a pas de valeur de retour.
syntax = "proto3";
import "google/protobuf/empty.proto";
service EmptyService {
rpc Do(google.protobuf.Empty) returns(google.protobuf.Empty);
}Option
option est généralement utilisé pour contrôler certains comportements de protobuf. Par exemple, pour contrôler le package du code source Go généré, vous pouvez le déclarer comme suit.
option go_package = "github/jack/sample/pb_learn;pb_learn"La partie avant le point-virgule est le chemin d'importation après génération du code pour d'autres fichiers sources. La partie après le point-virgule est le nom du package correspondant aux fichiers générés.
Il peut effectuer certaines optimisations avec les valeurs suivantes, qui ne peuvent pas être déclarées plusieurs fois :
SPEED, niveau d'optimisation le plus élevé, le code généré est le plus volumineux, c'est la valeur par défaut.CODE_SIZE, réduit la taille du code généré, mais utilise la réflexion pour la sérialisation.LIFE_RUNEIMTE, le code le plus petit, mais manque de certaines fonctionnalités.
Voici un exemple d'utilisation
option optimize_for = SPEED;De plus, option peut ajouter des métadonnées aux message et enum. Ces informations peuvent être récupérées par réflexion, ce qui est particulièrement utile pour la validation de paramètres.
Compilation
La compilation est la génération de code. Ci-dessus, nous avons seulement défini les fichiers protobuf. Pour les utiliser réellement, ils doivent être convertis en code source dans un langage spécifique. Nous utilisons le compilateur protoc pour cela. Il supporte plusieurs langages.
Installation
Pour télécharger le compilateur, allez sur protocolbuffers/protobuf: Protocol Buffers - Google's data interchange format (github.com) et téléchargez la dernière version Release. C'est généralement un fichier compressé
protoc-25.1-win64
│ readme.txt
│
├─bin
│ protoc.exe
│
└─include
└─google
└─protobuf
│ any.proto
│ api.proto
│ descriptor.proto
│ duration.proto
│ empty.proto
│ field_mask.proto
│ source_context.proto
│ struct.proto
│ timestamp.proto
│ type.proto
│ wrappers.proto
│
└─compiler
plugin.protoAprès le téléchargement, ajoutez le répertoire bin aux variables d'environnement pour pouvoir utiliser la commande protoc. Ensuite, vérifiez la version. Une sortie normale signifie que l'installation a réussi.
$ protoc --version
libprotoc 25.1Le compilateur téléchargé ne supporte pas Go par défaut, car la génération de code Go est un exécutable séparé. Les autres langages sont regroupés. Installez donc le plugin Go pour traduire les définitions protocbuf en code source Go.
$ go install google.golang.org/protobuf/cmd/protoc-gen-go@latestSi vous avez également besoin de générer du code de service gRPC, installez le plugin suivant
$ go install google.golang.org/grpc/cmd/protoc-gen-go-grpc@latestAprès l'installation, vérifiez la version
$ protoc-gen-go-grpc --version
protoc-gen-go-grpc 1.3.0
$ protoc-gen-go --version
protoc-gen-go.exe v1.31.0Ces plugins sont également des exécutables séparés, mais ils ne peuvent être appelés que via protoc, pas exécutés directement.
(this program should be run by protoc, not directly)Il existe de nombreux autres plugins, comme celui pour générer la documentation d'interface openapi, etc. Vous pouvez les rechercher vous-même si intéressé.
Génération
Reprenons l'exemple précédent. La structure est la suivante
pb_learn
│ common.proto
│
├─monster
│ monster.proto
│
└─player
health.proto
player.protoPour la génération de code, trois paramètres doivent être spécifiés au total
- Le chemin de balayage, qui indique au compilateur où chercher les fichiers
protobufet comment analyser les chemins d'importation - Le chemin de génération, où placer les fichiers compilés
- Les fichiers cibles, quels fichiers doivent être compilés.
Avant de commencer, assurez-vous que go_package dans les fichiers protobuf est correctement défini. Utilisez protoc -h pour voir les paramètres supportés. Le plus couramment utilisé est -I ou --proto_path, qui peut être utilisé plusieurs fois pour spécifier plusieurs chemins de balayage. Par exemple
$ protoc --proto_path=./pb_learn --proto_path=./third_partySpécifier uniquement le chemin de balayage ne suffit pas. Il faut aussi spécifier le chemin de génération et les fichiers protobuf cibles. Ici, pour générer des fichiers Go, utilisez le paramètre --go_out, supporté par le plugin protoc-gen-go téléchargé précédemment.
$ cd pb_learn
$ protoc --proto_path=. --go_out=. common.proto
$ ls
common.pb.go common.proto monster/ player/Le paramètre de --go_out est le chemin de génération spécifié. . signifie le chemin actuel. common.proto est le fichier à compiler. Si vous voulez générer du code grpc (à condition d'avoir installé le plugin grpc), vous pouvez ajouter le paramètre --go-grpc_out (si le fichier protobuf ne définit pas de service, le fichier correspondant ne sera pas généré).
$ protoc --proto_path=. --go_out=. --go-grpc_out=. common.proto
$ ls
common.pb.go common.proto common_grpc.pb.go monster/ player/common.pb.go contient les définitions de types protobuf générées, common_grpc.pb.go contient le code gRPC généré, basé sur le premier. Si les définitions dans le langage correspondant n'ont pas été générées, le code gRPC ne peut pas être généré non plus.
Si vous voulez compiler tous les fichiers protobuf de ce répertoire, vous pouvez utiliser le caractère générique *.
$ protoc --proto_path=. --go_out=.. common.proto --go-grpc_out=. ./*.protoSi vous voulez inclure tous les fichiers, vous pouvez utiliser le caractère générique **, par exemple ./**/*.proto.
$ protoc --proto_path=. --go_out=.. common.proto --go-grpc_out=. ./**/*.protoCependant, cette méthode ne fonctionne que pour les shells qui supportent cette syntaxe. Par exemple, sous Windows, cmd ou powershell ne supportent pas cette écriture
D> protoc --proto_path=. --go_out=.. common.proto --go-grpc_out=. ./**/*.proto
Invalid file name pattern or missing input file "./**/*.proto"Heureusement, gitbash supporte de nombreuses commandes linux, et peut aussi faire fonctionner cette syntaxe sous Windows. Pour éviter de répéter les mêmes commandes, vous pouvez les placer dans un makefile
.PHONY: all
proto_gen:
protoc --proto_path=. \
--go_out=paths=source_relative:. \
--go-grpc_out=paths=source_relative:. \
./**/*.proto ./*.protoNotez qu'il y a un paramètre supplémentaire paths=source_relative:.. Cela définit le mode de chemin pour la génération des fichiers. Les options sont :
paths=import, c'est la valeur par défaut. Les fichiers seront générés dans le répertoire spécifié parimport. Cela peut aussi être un chemin de module. Par exemple, s'il existe un fichierprotos/buzz.proto, et quepaths=example.com/project/protos/fizzest spécifié, alors le fichier généré seraexample.com/project/protos/fizz/buzz.pb.go.module=$PREFIX, lors de la génération, le préfixe de chemin sera supprimé. Dans l'exemple ci-dessus, si le préfixeexample.com/projectest spécifié, le fichier généré seraprotos/fizz/buzz.pb.go. Ce mode est principalement utilisé pour générer directement dans un module (on dirait qu'il n'y a pas de grande différence).paths=source_relative, les fichiers générés garderont la même structure relative que les fichiersprotobufdans le répertoire spécifié.
Le caractère : sépare le chemin de génération spécifié.
| common.proto
| common.pb.go
│
├─monster
│ monster.pb.go
│ monster.proto
│
└─player
health.pb.go
health.proto
health_grpc.pb.go
player.pb.go
player.protoRéflexion
Via options, vous pouvez étendre les enum et message. Importez d'abord "google/protobuf/descriptor.proto"
import "google/protobuf/descriptor.proto";
extend google.protobuf.EnumValueOptions {
optional string string_name = 123456789;
}
enum Integer {
INT64 = 0[
(string_name) = "int_64"
];
}Cela équivaut à ajouter une métadonnée à cette valeur d'énumération. Pour un message, c'est la même chose :
import "google/protobuf/descriptor.proto";
extend google.protobuf.MessageOptions {
optional string my_option = 51234;
}
message MyMessage {
option (my_option) = "Hello world!";
}C'est une forme de réflexion sur protobuf. Après la génération du code, vous pouvez y accéder via le Descriptor, comme suit
func main() {
message := pb_learn.MyMessage{}
message.ProtoReflect().Descriptor().Options().ProtoReflect().Range(func(descriptor protoreflect.FieldDescriptor, value protoreflect.Value) bool {
fmt.Println(descriptor.FullName(), ":", value)
return true
})
}Sortie
my_option:"Hello world!"Cette méthode peut être comparée à l'ajout de tags aux structures en Go. C'est assez similaire. Cette approche permet aussi d'implémenter la validation de paramètres, en écrivant les règles dans options et en vérifiant via le Descriptor.