CGO
Go は GC が必要なため、一部の性能要件がより高いシーンでは、Go は処理に適さない可能性があります。C は伝統的なシステムプログラミング言語として、性能は非常に優れています。CGO は両者を結びつけ、相互に呼び出すことを可能にします。Go が C を呼び出すことで、性能に敏感なタスクを C に任せ、Go は上位ロジックの処理を担当します。CGO は C が Go を呼び出すこともサポートしていますが、この種のシーンはあまり一般的ではなく、推奨もされていません。
TIP
文中のコードデモの環境は Win10 で、コマンドラインは gitbash を使用しています。Windows ユーザーは事前に mingw のインストールを推奨します。
CGO については、公式に簡単な紹介があります:C? Go? Cgo! - The Go Programming Language。より詳細な紹介が必要な場合は、標準ライブラリ cmd/cgo/doc.go でより詳細な情報を確認するか、または直接ドキュメント cgo command - cmd/cgo - Go Packages を参照することもできます。両者の内容は完全に同一です。
コード呼び出し
以下の例をご覧ください。
package main
//#include <stdio.h>
import "C"
func main() {
C.puts(C.CString("hello, cgo!"))
}CGO 特性を使用するには、インポート文 import "C" を通じて有効にする必要があります。注意すべき点は、C は大文字である必要があり、インポート名は上書きできないことです。また、環境変数 CGO_ENABLED が 1 に設定されていることを確認する必要があります。デフォルトでは、この環境変数は有効になっています。
$ go env | grep CGO
$ go env -w CGO_ENABLED=1除此之外、还需要确保本地拥有 C/C++ の構築ツールチェーン、つまり gcc を持っていることを確認する必要があります。Windows プラットフォームでは mingw です。これにより、プログラムが正常にコンパイルされることが保証されます。以下のコマンドを実行してコンパイルします。CGO を有効にすると、コンパイル時間は純粋な Go よりも長くなります。
$ go build -o ./ main.go
$ ./main.exe
hello, cgo!また注意すべき点は、CGO を有効にすると、クロスコンパイルがサポートされなくなることです。
Go への C コードの埋め込み
CGO は C コードを直接 Go ソースファイルに記述して直接呼び出すことをサポートしています。以下の例をご覧ください。例では printSum という名前の関数を作成し、Go の main 関数内で呼び出しています。
package main
/*
#include <stdio.h>
void printSum(int a, int b) {
printf("c:%d+%d=%d",a,b,a+b);
}
*/
import "C"
func main() {
C.printSum(C.int(1), C.int(2))
}出力
c:1+2=3これはシンプルなシーンに適しています。C コードが非常に多く、Go コードと混在すると可読性が大幅に低下するため、あまり適していません。
エラー処理
Go 言語では、エラー処理は戻り値として返されますが、C 言語は複数戻り値を許可していません。このため、C の errno を使用できます。これは関数呼び出し中にエラーが発生したことを表します。CGO はこれに対応しており、C 関数を呼び出す際に Go と同様に戻り値を使用してエラーを処理できます。errno を使用するには、まず errno.h をインポートします。以下の例をご覧ください。
package main
/*
#include <stdio.h>
#include <stdint.h>
#include <errno.h>
int32_t sum_positive(int32_t a, int32_t b) {
if (a <= 0 || b <= 0) {
errno = EINVAL;
return 0;
}
return a + b;
}
*/
import "C"
import (
"fmt"
"reflect"
)
func main() {
sum, err := C.sum_positive(C.int32_t(0), C.int32_t(1))
if err != nil {
fmt.Println(reflect.TypeOf(err))
fmt.Println(err)
return
}
fmt.Println(sum)
}出力
syscall.Errno
The device does not recognize the command.エラータイプが syscall.Errno であることがわかります。errno.h には他の多くのエラーコードも定義されています。自分で調べてみてください。
Go による C ファイルのインポート
C ファイルをインポートすることで、上記の問題をうまく解決できます。まずヘッダーファイル sum.h を作成します。内容は以下の通りです。
int sum(int a, int b);次に sum.c を作成し、具体的な関数を実装します。
#include "sum.h"
int sum(int a, int b) {
return a + b;
}次に main.go でヘッダーファイルをインポートします。
package main
//#include "sum.h"
import "C"
import "fmt"
func main() {
res := C.sum(C.int(1), C.int(2))
fmt.Printf("cgo sum: %d\n", res)
}これでコンパイルする場合、現在のフォルダーを指定する必要があります。そうしないと C ファイルが見つかりません。以下の通りです。
$ go build -o sum.exe . && ./sum.exe
cgo sum: 3コード内の res は Go の変数で、C.sum は C 言語の関数です。その戻り値は C 言語の int であり、Go の int ではありません。正常に呼び出せるのは、CGO が型変換を行っているためです。
C による Go の呼び出し
C による Go の呼び出しとは、CGO 内で C が Go を呼び出すことを指し、ネイティブの C プログラムが Go を呼び出すのではありません。それらはこのような呼び出しチェーンになります:go-cgo-c->cgo->go。Go が C を呼び出すのは、C のエコシステムと性能を利用するためであり、ネイティブの C プログラムが Go を呼び出すようなニーズはほとんどありません。もしあるとしても、ネットワーク通信を通じて置き換えることを推奨します。
CGO は Go 関数をエクスポートして C に呼び出させることをサポートしています。Go 関数をエクスポートする場合、関数シグネチャの上部に //export func_name コメントを追加する必要があります。また、パラメータと戻り値はすべて CGO がサポートする型である必要があります。例は以下の通りです。
//export sum
func sum(a, b C.int32_t) C.int32_t {
return a + b
}先ほどの sum.c ファイルを以下のように書き換えます。
#include <stdint.h>
#include <stdio.h>
#include "sum.h"
#include "_cgo_export.h"
extern int32_t sum(int32_t a, int32_t b);
void do_sum() {
int32_t a = 10;
int32_t b = 10;
int32_t c = sum(a, b);
printf("%d", c);
}同時にヘッダーファイル sum.h を修正します。
void do_sum();次に Go で関数をエクスポートします。
package main
/*
#include <stdio.h>
#include <stdint.h>
#include "sum.h"
*/
import "C"
func main() {
C.do_sum()
}
//export sum
func sum(a, b C.int32_t) C.int32_t {
return a + b
}これで C 内で使用されている sum 関数は実際には Go が提供するものです。出力結果は以下の通りです。
20重要なポイントは、sum.c ファイル内でインポートされている _cgo_export.h です。これにはすべての Go がエクスポートする型に関する情報が含まれています。インポートしない場合、Go がエクスポートする関数を使用できません。もう 1 つの注意点は、_cgo_export.h を Go ファイル内でインポートできないことです。このヘッダーファイルが生成される前提は、すべての Go ソースファイルがコンパイルを通過できることです。したがって、以下の書き方は誤りです。
package main
/*
#include <stdint.h>
#include <stdio.h>
#include "_cgo_export.h"
void do_sum() {
int32_t a = 10;
int32_t b = 10;
int32_t c = sum(a, b);
printf("%d", c);
}
*/
import "C"
func main() {
C.do_sum()
}
//export sum
func sum(a, b C.int32_t) C.int32_t {
return a + b
}コンパイラーはヘッダーファイルが存在しないと表示します。
fatal error: _cgo_export.h: No such file or directory
#include "_cgo_export.h"
^~~~~~~~~~~~~~~
compilation terminated.Go 関数が複数の戻り値を持つ場合、C 呼び出し時は構造体が返されます。
ついでに言うと、Go ポインタを C 関数のパラメータを通じて C に渡すことができます。C 関数呼び出し期間中、CGO はメモリ安全性をできるだけ保証しますが、エクスポートされた Go 関数の戻り値はポインタを含めることはできません。この場合、CGO はそれが参照されているかどうかを判断できず、メモリを固定することもできないためです。返されたメモリが参照され、その後 Go 内でそのメモリが GC されるかオフセットが発生した場合、ポインタが範囲外になります。以下の通りです。
//export newCharPtr
func newCharPtr() *C.char {
return new(C.char)
}上記の書き方はデフォルトではコンパイルを通過できません。このチェックを無効にしたい場合は、以下のように設定できます。
GODEBUG=cgocheck=0これには 2 つのチェックレベルがあり、1、2 に設定できます。レベルが高いほど、実行時のオーバーヘッドが大きくなります。詳細は cgo command - passing_pointer を参照してください。
型変換
CGO は C と Go の間の型にマッピングを提供し、実行時の呼び出しを容易にします。C の型については、import "C" をインポートした後、ほとんどの場合、以下の方法で直接アクセスできます。
C.typename例えば
C.int(1)
C.char('a')しかし、C 言語の型は複数のキーワードで構成される可能性があります。例えば
unsigned charこの場合、直接アクセスできませんが、C の typedef キーワードを使用して型に別名を付けることができます。その機能は Go の型エイリアスと同等です。以下の通りです。
typedef unsigned char byte;これで、C.byte を通じて型 unsigned char にアクセスできます。例は以下の通りです。
package main
/*
#include <stdio.h>
typedef unsigned char byte;
void printByte(byte b) {
printf("%c\n",b);
}
*/
import "C"
func main() {
C.printByte(C.byte('a'))
C.printByte(C.byte('b'))
C.printByte(C.byte('c'))
}出力
a
b
cほとんどの場合、CGO は一般的な型(基本型など)にすでに別名を付けています。上記の方法に従って自分で定義することもでき、競合しません。
char
C の char は Go の int8 型に対応し、unsigned char は Go の uint8、つまり byte 型に対応します。
package main
/*
#include <stdio.h>
#include<complex.h>
char ch;
char get() {
return ch;
}
void set(char c) {
ch = c;
}
*/
import "C"
import (
"fmt"
"reflect"
)
func main() {
C.set(C.char('c'))
res := C.get()
fmt.Printf("type: %s, val: %v", reflect.TypeOf(res), res)
}出力
type: main._Ctype_char, val: 99set のパラメータを C.char(math.MaxInt8 + 1) に変更すると、コンパイルに失敗し、以下のエラーが表示されます。
cannot convert math.MaxInt8 + 1 (untyped int constant 128) to type _Ctype_char文字列
CGO は C と Go の間で文字列とバイトスライスを渡すためにいくつかの疑似関数を提供しています。これらの関数は実際には存在せず、定義を見つけることもできません。import "C" と同様に、C パッケージも存在しません。これは開発者が使用しやすいようにするためだけで、コンパイル後には他の操作に変換されます。
// Go string to C string
// The C string is allocated in the C heap using malloc.
// It is the caller's responsibility to arrange for it to be
// freed, such as by calling C.free (be sure to include stdlib.h
// if C.free is needed).
func C.CString(string) *C.char
// Go []byte slice to C array
// The C array is allocated in the C heap using malloc.
// It is the caller's responsibility to arrange for it to be
// freed, such as by calling C.free (be sure to include stdlib.h
// if C.free is needed).
func C.CBytes([]byte) unsafe.Pointer
// C string to Go string
func C.GoString(*C.char) string
// C data with explicit length to Go string
func C.GoStringN(*C.char, C.int) string
// C data with explicit length to Go []byte
func C.GoBytes(unsafe.Pointer, C.int) []byteGo の文字列の本質は構造体で、内部には基底配列の参照を保持しています。C 関数に渡す際は、C.CString() を使用して C 内で malloc を使用して「文字列」を作成し、メモリスペースを割り当て、C ポインタを返す必要があります。C には文字列という型がないため、通常は char* を使用して文字列を表します。つまり、文字配列のポインタです。使用後は free を使用してメモリを解放することを忘れないでください。
package main
/*
#include <stdio.h>
#include <stdlib.h>
void printfGoString(char* s) {
puts(s);
}
*/
import "C"
import "unsafe"
func main() {
cstring := C.CString("this is a go string")
C.printfGoString(cstring)
C.free(unsafe.Pointer(cstring))
}char 配列型でもかまいません。実際にはどちらも同じで、先頭要素へのポインタです。
void printfGoString(char s[]) {
puts(s);
}バイトスライスを渡すこともできます。C.CBytes() は unsafe.Pointer を返すため、C 関数に渡す前に *C.char 型に変換する必要があります。
package main
/*
#include <stdio.h>
#include <stdlib.h>
void printfGoString(char* s) {
puts(s);
}
*/
import "C"
import "unsafe"
func main() {
cbytes := C.CBytes([]byte("this is a go string"))
C.printfGoString((*C.char)(cbytes))
C.free(unsafe.Pointer(cbytes))
}上記の例の出力はすべて同じです。
this is a go string上記のいくつかの文字列転送方法は 1 回のメモリコピーを伴います。転送後、実際には C メモリと Go メモリにそれぞれ 1 部ずつ保持されています。これにより、より安全になります。そうは言っても、ポインタを直接 C 関数に渡すこともでき、C 内で直接 Go の文字列を修正することもできます。以下の例をご覧ください。
package main
/*
#include <stdio.h>
#include <stdlib.h>
void printfGoString(char* s) {
puts(s);
}
*/
import "C"
import "unsafe"
func main() {
ptr := unsafe.Pointer(unsafe.SliceData([]byte("this is a go string")))
C.printfGoString((*C.char)(ptr))
}出力
this is a go string例では unsafe.SliceData を通じて文字列の基底配列のポインタを直接取得し、それを C ポインタに変換して C 関数に渡しています。該文字列のメモリは Go によって管理されているため、free は不要です。これを行う利点は、転送プロセス中にコピーが不要になることですが、一定のリスクがあります。以下の例では、C 内で Go の文字列を修正するデモを行っています。
package main
/*
#include <stdio.h>
#include <stdlib.h>
void printfGoString(char* s, int len) {
puts(s);
s[8] = 'c';
puts(s);
}
*/
import "C"
import (
"fmt"
"unsafe"
)
func main() {
var buf []byte
buf = []byte("this is a go string")
ptr := unsafe.Pointer(unsafe.SliceData(buf))
C.printfGoString((*C.char)(ptr), C.int(len(buf)))
fmt.Println(string(buf))
}出力
this is a go string
this is c go string
this is c go string整数
Go と C の間の整数マッピング関係は以下の表に示されています。整数の型マッピングについては、標準ライブラリ cmd/cgo/gcc.go でもいくつかの関連情報を確認できます。
| go | c | cgo |
|---|---|---|
| int8 | singed char | C.schar |
| uint8 | unsigned char | C.uchar |
| int16 | short | C.short |
| uint16 | unsigned short | C.ushort |
| int32 | int | C.int |
| uint32 | unsigned int | C.uint |
| int32 | long | C.long |
| uint32 | unsigned long | C.ulong |
| int64 | long long int | C.longlong |
| uint64 | unsigned long long int | C.ulonglong |
サンプルコードは以下の通りです。
package main
/*
#include <stdio.h>
void printGoInt8(signed char n) {
printf("%d\n",n);
}
void printGoUInt8(unsigned char n) {
printf("%d\n",n);
}
void printGoInt16(signed short n) {
printf("%d\n",n);
}
void printGoUInt16(unsigned short n) {
printf("%d\n",n);
}
void printGoInt32(signed int n) {
printf("%d\n",n);
}
void printGoUInt32(unsigned int n) {
printf("%d\n",n);
}
void printGoInt64(signed long long int n) {
printf("%ld\n",n);
}
void printGoUInt64(unsigned long long int n) {
printf("%ld\n",n);
}
*/
import "C"
func main() {
C.printGoInt8(C.schar(1))
C.printGoInt8(C.schar(1))
C.printGoInt16(C.short(1))
C.printGoUInt16(C.ushort(1))
C.printGoInt32(C.int(1))
C.printGoUInt32(C.uint(1))
C.printGoInt64(C.longlong(1))
C.printGoUInt64(C.ulonglong(1))
}CGO は <stdint.h> の整数型もサポートしています。こちらの型のメモリサイズはより明確で、命名スタイルも Go と非常によく似ています。
| go | c | cgo |
|---|---|---|
| int8 | int8_t | C.int8_t |
| uint8 | uint8_t | C.uint8_t |
| int16 | int16_t | C.int16_t |
| uint16 | uint16_t | C.uint16_t |
| int32 | int32_t | C.int32_t |
| uint32 | uint32_t | C.uint32_t |
| int64 | int64_t | C.int64_t |
| uint64 | uint64_t | C.uint64_t |
CGO を使用する際は、<stdint.h> の整数型を使用することを推奨します。
浮動小数点数
Go と C の浮動小数点数型のマッピングは以下の通りです。
| go | c | cgo |
|---|---|---|
| float32 | float | C.float |
| float64 | double | C.double |
コード例は以下の通りです。
package main
/*
#include <stdio.h>
void printGoFloat32(float n) {
printf("%f\n",n);
}
void printGoFloat64(double n) {
printf("%lf\n",n);
}
*/
import "C"
func main() {
C.printGoFloat32(C.float(1.11))
C.printGoFloat64(C.double(3.14))
}スライス
スライスの状況は実際には上記の文字列とあまり変わりませんが、違いは CGO がスライスのコピーを行う疑似関数を提供していないことです。C に Go のスライスにアクセスさせたい場合は、スライスのポインタを渡すしかありません。以下の例をご覧ください。
package main
/*
#include <stdio.h>
#include <stdint.h>
void printInt32Arr(int32_t* s, int32_t len) {
for (int32_t i = 0; i < len; i++) {
printf("%d ", s[i]);
}
}
*/
import "C"
import (
"unsafe"
)
func main() {
var arr []int32
for i := 0; i < 10; i++ {
arr = append(arr, int32(i))
}
ptr := unsafe.Pointer(unsafe.SliceData(arr))
C.printInt32Arr((*C.int32_t)(ptr), C.int(len(arr)))
}出力
0 1 2 3 4 5 6 7 8 9ここではスライスの基底配列のポインタを C 関数に渡しています。該配列のメモリは Go によって管理されているため、C が長期間そのポインタ参照を保持することは推奨されません。逆に、C の配列を Go スライスの基底配列として使用する例は以下の通りです。
package main
/*
#include <stdio.h>
#include <stdint.h>
int32_t s[] = {1, 2, 3, 4, 5, 6, 7};
*/
import "C"
import (
"fmt"
"unsafe"
)
func main() {
l := unsafe.Sizeof(C.s) / unsafe.Sizeof(C.s[0])
fmt.Println(l)
goslice := unsafe.Slice(&C.s[0], l)
for i, e := range goslice {
fmt.Println(i, e)
}
}出力
7
0 1
1 2
2 3
3 4
4 5
5 6
6 7unsafe.Slice 関数を通じて、配列ポインタをスライスに変換できます。直感的には、C の配列は先頭要素へのポインタであるため、理にかなって以下のように使用するべきです。
goslice := unsafe.Slice(&C.s, l)出力を通じて、このようにすると、最初の要素を除いて残りのメモリがすべて範囲外になることがわかります。
0 [1 2 3 4 5 6 7]
1 [0 -1 0 0 0 3432824 0]
2 [0 0 -1 -1 0 0 -1]
3 [0 0 0 255 0 0 0]
4 [2 0 0 0 3432544 0 0]
5 [0 3432576 0 3432592 0 3432608 0]
6 [0 0 3432624 0 0 0 1422773729]C の配列が単なる先頭ポインタであっても、CGO にラップされた後には Go 配列になり、独自のアドレスを持ちます。したがって、配列の先頭要素のアドレスを取得するべきです。
goslice := unsafe.Slice(&C.s[0], l)構造体
C.struct_ プレフィックスに構造体名を追加することで、C 構造体にアクセスできます。C 構造体は匿名構造体として Go 構造体に埋め込むことはできません。以下はシンプルな C 構造体の例です。
package main
/*
#include <stdio.h>
#include <stdint.h>
struct person {
int32_t age;
char* name;
};
*/
import "C"
import (
"fmt"
"reflect"
)
func main() {
var p C.struct_person
p.age = C.int32_t(18)
p.name = C.CString("john")
fmt.Println(reflect.TypeOf(p))
fmt.Printf("%+v", p)
}出力
main._Ctype_struct_person
{age:18 name:0x1dd043b6e30}C 構造体の一部のメンバーが bit-field を含む場合、CGO は该类の構造体メンバーを無視します。例えば、person を以下のように修正します。
struct person {
int32_t age: 1;
char* name;
};再度実行するとエラーが発生します。
p.age undefined (type _Ctype_struct_person has no field or method age)C と Go の構造体フィールドのメモリ整列ルールは同じではありません。CGO を有効にしている場合、ほとんどの場合 C が主導権を握ります。
共用体
C.union_ に名前を追加することで、C の共用体にアクセスできます。Go は共用体をサポートしていないため、それらは Go 内でバイト配列として存在します。以下はシンプルな例です。
package main
/*
#include <stdio.h>
#include <stdint.h>
union data {
int32_t age;
char ch;
};
*/
import "C"
import (
"fmt"
"reflect"
)
func main() {
var u C.union_data
fmt.Println(reflect.TypeOf(u), u)
}出力
[4]uint8 [0 0 0 0]unsafe.Pointer を通じてアクセスと修正が行えます。
func main() {
var u C.union_data
ptr := (*C.int32_t)(unsafe.Pointer(&u))
fmt.Println(*ptr)
*ptr = C.int32_t(1024)
fmt.Println(*ptr)
fmt.Println(u)
}出力
0
1024
[0 4 0 0]列挙型
プレフィックス C.enum_ に列挙型名を追加することで、C の列挙型にアクセスできます。以下はシンプルな例です。
package main
/*
#include <stdio.h>
#include <stdint.h>
enum player_state {
alive,
dead,
};
*/
import "C"
import "fmt"
type State C.enum_player_state
func (s State) String() string {
switch s {
case C.alive:
return "alive"
case C.dead:
return "dead"
default:
return "unknown"
}
}
func main() {
fmt.Println(C.alive, State(C.alive))
fmt.Println(C.dead, State(C.dead))
}出力
0 alive
1 deadポインタ
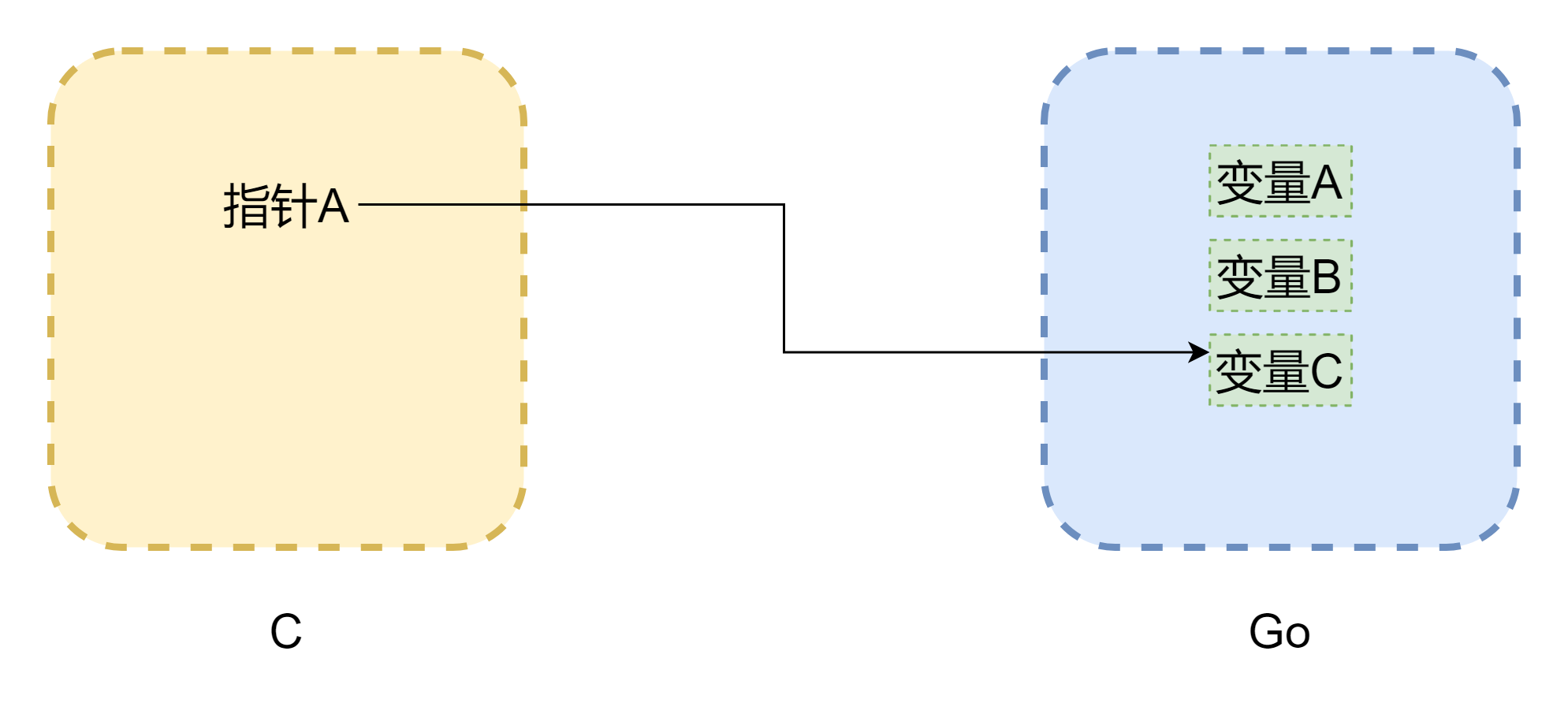
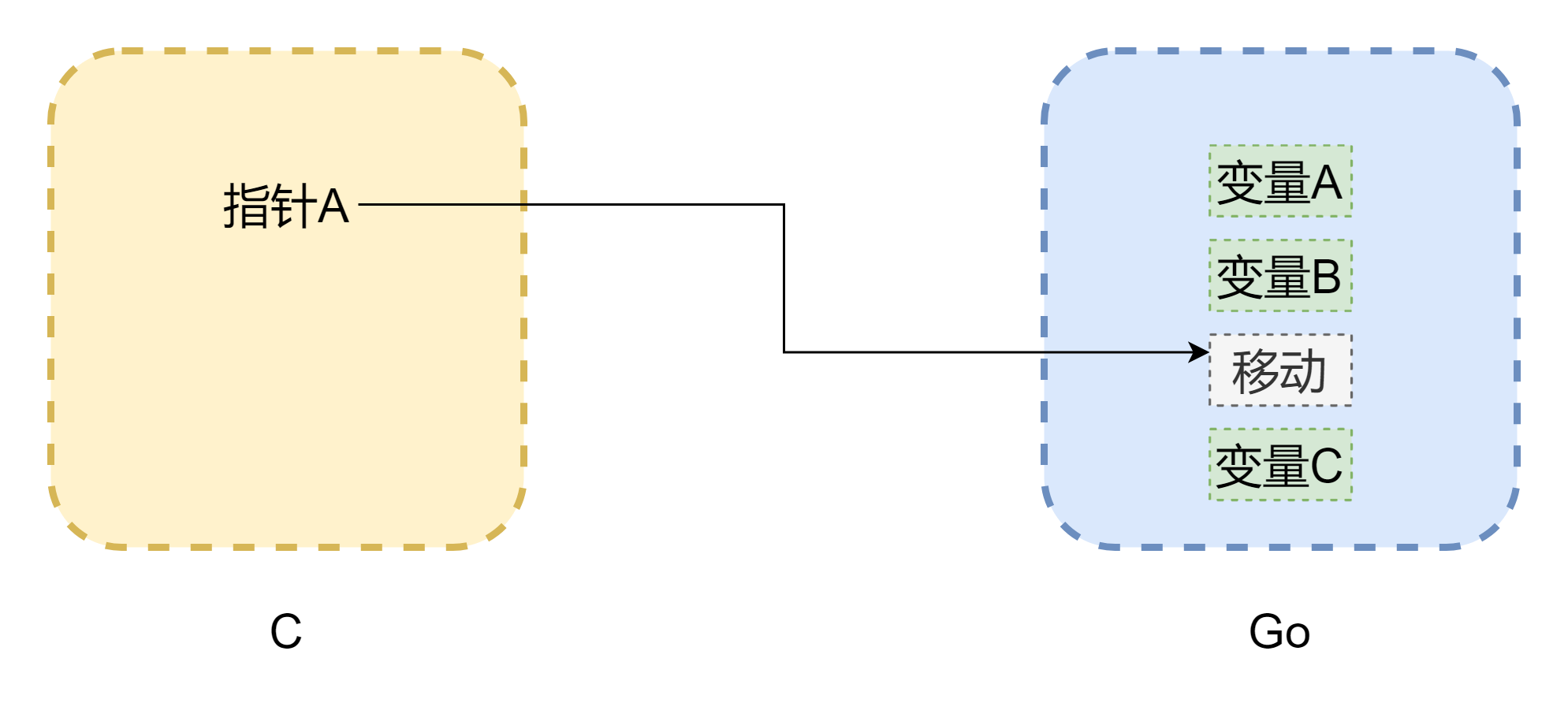
ポインタについて語ると、メモリから避けて通れません。CGO 間の相互呼び出しの最大の問題は、両言語のメモリモデルが同じではないことです。C 言語のメモリは完全に開発者によって手動で管理され、malloc() でメモリを割り当て、free() でメモリを解放します。手動で解放しない限り、それは絶対に自分で解放されることはありません。したがって、C のメモリ管理は非常に安定しています。一方、Go は GC を備えており、Goroutine のスタックスペースは動的に調整されます。スタックスペースが不足すると増加します。这样一来、メモリアドレスが変化する可能性があります。上記の図と同じように(図は厳密ではありませんが)、ポインタは C で一般的なダングリングポインタになる可能性があります。CGO がほとんどの場合メモリの移動を回避できても(runtime.Pinner によってメモリを固定)、Go 公式は C 内で長期間 Go のメモリを参照することを推奨していません。しかし逆に、Go 内のポインタが C 内のメモリを参照する場合、比較的安全です。手動で C.free() を呼び出さない限り、そのメモリは自動的に解放されることはありません。
C と Go の間でポインタを渡す場合は、まず unsafe.Pointer に変換し、その後対応するポインタ型に変換する必要があります。C の void* と同じです。2 つの例をご覧ください。1 つ目は C ポインタが Go 変数を参照する例で、変数を変更しています。
package main
/*
#include <stdio.h>
#include <stdint.h>
void printNum(int32_t* s) {
printf("%d\n", *s);
*s = 3;
printf("%d\n", *s);
}
*/
import "C"
import (
"fmt"
"unsafe"
)
func main() {
var num int32 = 1
ptr := unsafe.Pointer(&num)
C.printNum((*C.int32_t)(ptr))
fmt.Println(num)
}出力
1
3
32 つ目は Go ポインタが C 変数を参照し、それを変更する例です。
package main
/*
#include <stdio.h>
#include <stdint.h>
int32_t num = 10;
*/
import "C"
import (
"fmt"
"unsafe"
)
func main() {
fmt.Println(C.num)
ptr := unsafe.Pointer(&C.num)
iptr := (*int32)(ptr)
*iptr++
fmt.Println(C.num)
}出力
10
11ついでに言うと、CGO は C の関数ポインタをサポートしていません。
リンクライブラリ
C 言語には Go のような依存関係管理がありません。他人が書いたライブラリを直接使用には、ソースコードを直接取得する以外に、静的リンクライブラリと動的リンクライブラリという方法があります。CGO もこれらをサポートしています。これにより、Go プログラム内で他人が書いたライブラリをインポートでき、ソースコードは不要になります。
動的リンクライブラリ
動的リンクライブラリは単独で実行できません。実行時に実行ファイルと一緒にメモリにロードされます。以下では、シンプルな動的リンクライブラリを作成し、CGO を通じて呼び出すデモを行います。まず lib/sum.c ファイルを準備します。内容は以下の通りです。
#include <stdint.h>
int32_t sum(int32_t a, int32_t b) {
return a + b;
}ヘッダーファイル lib/sum.h を作成します。
#include <stdint.h>
int sum(int32_t a, int32_t b);次に gcc を使用して動的リンクライブラリを作成します。まず目的ファイルをコンパイルして生成します。
$ cd lib
$ gcc -c sum.c -o sum.o次に動的リンクライブラリを作成します。
$ gcc -shared -o libsum.dll sum.o作成後、Go コード内で sum.h ヘッダーファイルをインポートし、マクロを通じて CGO にライブラリファイルの場所を指示する必要があります。
package main
/*
#cgo CFLAGS: -I ./lib
#cgo LDFLAGS: -L${SRCDIR}/lib -llibsum
#include "sum.h"
*/
import "C"
import "fmt"
func main() {
res := C.sum(C.int32_t(1), C.int32_t(2))
fmt.Println(res)
}CFLAGS: -Iはヘッダーファイルの検索相対パスを指します。-Lはライブラリの検索パスを指します。${SRCDIR}は現在のパスの絶対パスを指します。そのパラメータは絶対パスである必要があるためです。-lはライブラリファイルの名前を指します。sum はsum.dllです。
CFFLAGS と LDFLAGS は両方とも gcc のコンパイルオプションです。セキュリティ上の理由から、CGO は一部のパラメータを無効にしています。詳細は cgo command を参照してください。
動的ライブラリを exe と同じディレクトリに配置します。
$ ls
go.mod go.sum lib/ libsum.dll* main.exe* main.go最後に Go プログラムをコンパイルして実行します。
$ go build main.go && ./main.exe
3これで動的リンクライブラリの呼び出しに成功しました。
静的リンクライブラリ
動的リンクライブラリとは異なり、CGO を使用して静的リンクライブラリをインポートする場合、Go の目的ファイルと最終的にリンクされて 1 つの実行ファイルになります。引き続き sum.c を例として、まずソースファイルを目的ファイルにコンパイルします。
$ gcc -o sum.o -c sum.c次に目的ファイルを静的リンクライブラリにパッケージ化します(lib プレフィックスで始まる必要があります。そうしないと見つかりません)。
$ ar rcs libsum.a sum.oGo ファイルの内容
package main
/*
#cgo CFLAGS: -I ./lib
#cgo LDFLAGS: -L${SRCDIR}/lib -llibsum
#include "sum.h"
*/
import "C"
import "fmt"
func main() {
res := C.sum(C.int32_t(1), C.int32_t(2))
fmt.Println(res)
}コンパイル
$ go build && ./main.exe
3これで、静的リンクライブラリの呼び出しに成功しました。
最後に
CGO を使用する目的は性能のためですが、C と Go の間で切り替えることも性能の損失を引き起こします。一部の非常にシンプルなタスクでは、CGO の効率は純粋な Go ほど良くありません。以下の例をご覧ください。
package main
/*
#include <stdint.h>
int32_t cgo_sum(int32_t a, int32_t b) {
return a + b;
}
*/
import "C"
import (
"fmt"
"time"
)
func go_sum(a, b int32) int32 {
return a + b
}
func testSum(N int, do func()) int64 {
var sum int64
for i := 0; i < N; i++ {
start := time.Now()
do()
sum += time.Now().Sub(start).Nanoseconds()
}
return sum / int64(N)
}
func main() {
N := 1000_000
nsop1 := testSum(N, func() {
C.cgo_sum(C.int32_t(1), C.int32_t(2))
})
fmt.Printf("cgo_sum: %d ns/op\n", nsop1)
nsop2 := testSum(N, func() {
go_sum(1, 2)
})
fmt.Printf("pure_go_sum: %d ns/op\n", nsop2)
}これは非常にシンプルなテストで、C と Go でそれぞれ 2 つの数の和を求める関数を作成し、それぞれ 100 万回実行して平均耗时を求めます。テスト結果は以下の通りです。
cgo_sum: 49 ns/op
pure_go_sum: 2 ns/op結果から、CGO の平均耗时は純粋な Go の 20 数倍であることがわかります。実行するのが単純な 2 つの数の加算ではなく、より時間のかかるタスクである場合、CGO の優位性はより大きくなります。除此之外、CGO を使用するには以下の欠点もあります。
- Go の多くのツールチェーンが使用できなくなります。例えば gotest、pprof です。上記のテスト例では gotest を使用できず、手動で記述する必要があります。
- コンパイル速度が遅くなり、組み込みのクロスコンパイルも使用できなくなります。
- メモリ安全性の問題
- 依存関係の問題。他人があなたのライブラリを使用する場合、CGO を有効にする必要があります。
十分に考慮する前に、プロジェクト内で CGO を導入しないでください。一部の非常に複雑なタスクでは、CGO を使用することで確かにメリットをもたらしますが、一部のシンプルなタスクの場合は、素直に Go を使用しましょう。