並行処理
Go 言語の並行処理へのサポートは純粋で、これはこの言語の核心であり、習得難易度は比較的低く、開発者は底层実装をあまり気にせずに素晴らしい並行アプリケーションを作成でき、開発者の下限を引き上げます。
ゴルーチン
ゴルーチン(coroutine)は軽量スレッド、またはユーザーランドスレッドであり、オペレーティングシステムによって直接スケジューリングされず、Go 言語自身のスケジューラによって実行時にスケジューリングされるため、コンテキストスイッチングのオーバーヘッドが非常に小さく、这也是 Go の並行処理性能が非常に優れている理由の 1 つです。ゴルーチンという概念は Go が初めて提案したものではなく、Go もゴルーチンをサポートした最初の言語ではありませんが、Go はゴルーチンと並行処理をサポートする最もシンプルでエレガントな言語です。
Go では、ゴルーチンの作成は非常に簡単で、go キーワード 1 つで関数呼び出しを迅速に開始できます。go キーワードの後ろには関数呼び出しが必要です。例は以下の通りです。
TIP
戻り値を持つ組み込み関数は go キーワードの後ろに続けることはできません。以下の誤った例をご覧ください。
go make([]int,10) // go discards result of make([]int, 10) (value of type []int)func main() {
go fmt.Println("hello world!")
go hello()
go func() {
fmt.Println("hello world!")
}()
}
func hello() {
fmt.Println("hello world!")
}上記の 3 つのゴルーチン開始方法はすべて可能ですが、実際にはこの例を実行してもほとんどの場合何も出力されません。ゴルーチンは並行実行され、システムがゴルーチンを作成するには時間がかかり、その前にメインゴルーチンがすでに実行を終了しているため、メインスレッドが終了すると、他のサブルーチンも自然に終了します。また、ゴルーチンの実行順序も不確定で予測できません。以下の例をご覧ください。
func main() {
fmt.Println("start")
for i := 0; i < 10; i++ {
go fmt.Println(i)
}
fmt.Println("end")
}これはループ内でゴルーチンを開始する例で、何が出力されるかを正確に予測することはできません。サブルーチンが実行を開始する前にメインゴルーチンが終了している可能性があります。状況は以下の通りです。
start
endまたは、一部のサブルーチンのみがメインゴルーチンが終了する前に実行に成功します。状況は以下の通りです。
start
0
1
5
3
4
6
7
end最も簡単な方法はメインゴルーチンに少し待たせることで、time パッケージの Sleep 関数を使用する必要があります。これにより、現在のゴルーチンを一定時間一時停止できます。例は以下の通りです。
func main() {
fmt.Println("start")
for i := 0; i < 10; i++ {
go fmt.Println(i)
}
// 1ms 一時停止
time.Sleep(time.Millisecond)
fmt.Println("end")
}再度実行すると、以下のように出力され、すべての数字が漏れなく出力されていることがわかります。
start
0
1
5
2
3
4
6
8
9
7
endしかし順序はまだ乱れています。そのため、各ループを少し待たせます。例は以下の通りです。
func main() {
fmt.Println("start")
for i := 0; i < 10; i++ {
go fmt.Println(i)
time.Sleep(time.Millisecond)
}
time.Sleep(time.Millisecond)
fmt.Println("end")
}現在の出力は正常な順序になっています。
start
0
1
2
3
4
5
6
7
8
9
end上記の例の結果出力は完璧ですが、並行処理の問題は解決したでしょうか?いいえ、全くありません。並行処理プログラムにとって、制御できない要因は非常に多く、実行のタイミング、前後順序、実行プロセスの時間消費などです。ループ内のサブルーチンの作業が単純な数字の出力ではなく、非常に巨大で複雑なタスクで、時間消費が不確実な場合、以前の問題が再び発生します。以下のコードをご覧ください。
func main() {
fmt.Println("start")
for i := 0; i < 10; i++ {
go hello(i)
time.Sleep(time.Millisecond)
}
time.Sleep(time.Millisecond)
fmt.Println("end")
}
func hello(i int) {
// ランダムな時間消費をシミュレート
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
fmt.Println(i)
}このコードの出力はまだ不確定です。以下は可能性の 1 つです。
start
0
3
4
endしたがって、time.Sleep は良い解決策ではありません。幸いなことに、Go は多くの並行処理制御手段を提供しています。一般的な並行処理制御方法は 3 つあります。
channel:パイプWaitGroup:セマフォContext:コンテキスト
3 つの方法はそれぞれ異なる適用状況があります。WaitGroup は指定された数のゴルーチングループを動的に制御でき、Context は子孫ゴルーチンのネストレベルがより深い状況に適しており、パイプはゴルーチン間通信に適しています。より伝統的なロック制御について、Go もサポートを提供しています。
Mutex:相互排他ロックRWMutex:読み書き相互排他ロック
パイプ
channel、パイプと訳され、Go はパイプの役割を以下のように説明しています。
Do not communicate by sharing memory; instead, share memory by communicating.
つまり、メッセージを通じてメモリを共有し、channel はこのために生まれました。これはゴルーチン間通信の解決策であり、並行処理制御にも使用できます。まず channel の基本構文を認識しましょう。Go では、キーワード chan を通じてパイプタイプを表し、同時にパイプの保存タイプを宣言して、保存するデータがどのタイプかを指定する必要があります。以下の例は通常のパイプの様子です。
var ch chan intこれはパイプの宣言文で、この時点でパイプはまだ初期化されておらず、値は nil で、直接使用することはできません。
作成
パイプを作成する際、方法は 1 つだけで、組み込み関数 make を使用することです。パイプにとって、make 関数は 2 つのパラメータを受け取ります。1 つ目はパイプのタイプで、2 つ目はオプションパラメータでパイプのバッファサイズです。例は以下の通りです。
intCh := make(chan int)
// バッファサイズ 1 のパイプ
strCh := make(chan string, 1)パイプの使用後は、必ずそのパイプを閉じる必要があります。組み込み関数 close を使用してパイプを閉じます。この関数シグネチャは以下の通りです。
func close(c chan<- Type)パイプを閉じる例は以下の通りです。
func main() {
intCh := make(chan int)
// 何か処理を行う
close(intCh)
}場合によっては、defer を使用してパイプを閉じる方が良いかもしれません。
読み書き
パイプに対して、Go は読み書き操作を表すために 2 つの非常に形象的な演算子を使用しています。
ch <-:パイプにデータを書き込むことを表します。
<- ch:パイプからデータを読み取ることを表します。
<- はデータの流動方向を非常に形象的に表しています。int タイプのパイプの読み書きの例をご覧ください。
func main() {
// バッファがない場合、デッドロックが発生します
intCh := make(chan int, 1)
defer close(intCh)
// データを書き込む
intCh <- 114514
// データを読み取る
fmt.Println(<-intCh)
}上記の例では、バッファサイズが 1 の int 型パイプを作成し、データ 114514 を書き込み、その後データを読み取って出力し、最後にそのパイプを閉じます。読み取り操作には 2 つ目の戻り値があり、ブール型の値で、データが正常に読み取れたかどうかを表します。
ints, ok := <-intChパイプ内のデータの流動方法はキューと同じで、先入れ先出し(FIFO)です。ゴルーチンのパイプ操作は同期的で、ある時点で、1 つのゴルーチンのみでデータを書き込むことができ、同時に 1 つのゴルーチンのみでパイプ内のデータを読み取ることができます。
バッファなし
バッファなしパイプの場合、バッファ容量が 0 であるため、一時的にデータを保存することはできません。バッファなしパイプはデータを保存できないため、パイプにデータを書き込む際は、直ちに他のゴルーチンがデータを読み取る必要があります。否则ブロックして待機します。データを読み取る際も同様です。这也是以下の非常に正常に見えるコードがデッドロックを発生させる理由を説明しています。
func main() {
// バッファなしパイプを作成
ch := make(chan int)
defer close(ch)
// データを書き込む
ch <- 123
// データを読み取る
n := <-ch
fmt.Println(n)
}バッファなしパイプは同期的に使用するべきではありません。正しくは新しいゴルーチンを開始してデータを送信することです。以下の例をご覧ください。
func main() {
// バッファなしパイプを作成
ch := make(chan int)
defer close(ch)
go func() {
// データを書き込む
ch <- 123
}()
// データを読み取る
n := <-ch
fmt.Println(n)
}バッファあり
パイプにバッファがあると、ブロッキングキューのようになります。空のパイプを読み取るのと、満杯のパイプに書き込むのは、どちらもブロックを引き起こします。バッファなしパイプはデータを送信する際、直ちに誰かが受信する必要があります。否则常にブロックし続けます。バッファありパイプの場合、その必要はありません。バッファありパイプにデータを書き込む際、まずデータをバッファに格納し、バッファ容量が満杯になった場合にのみ、ゴルーチンがパイプ内のデータを読み取るまでブロックして待機します。同様に、バッファありパイプを読み取る際、まずバッファからデータを読み取り、バッファにデータがなくなるまで、ゴルーチンがパイプにデータを書き込むまでブロックして待機します。したがって、バッファなしパイプでデッドロックを発生させる例は、ここでは正常に実行できます。
func main() {
// バッファありパイプを作成
ch := make(chan int, 1)
defer close(ch)
// データを書き込む
ch <- 123
// データを読み取る
n := <-ch
fmt.Println(n)
}正常に実行できますが、この同期読み書き方法は非常に危険です。パイプバッファが空になったり満杯になったりすると、常にブロックし続けます。他のゴルーチンがパイプにデータを書き込んだり読み取ったりしないためです。以下の例をご覧ください。
func main() {
// バッファありパイプを作成
ch := make(chan int, 5)
// 2 つのバッファなしパイプを作成
chW := make(chan struct{})
chR := make(chan struct{})
defer func() {
close(ch)
close(chW)
close(chR)
}()
// 書き込みを担当
go func() {
for i := 0; i < 10; i++ {
ch <- i
fmt.Println("書き込み", i)
}
chW <- struct{}{}
}()
// 読み取りを担当
go func() {
for i := 0; i < 10; i++ {
// 読み取りごとに 1ms かかります
time.Sleep(time.Millisecond)
fmt.Println("読み取り", <-ch)
}
chR <- struct{}{}
}()
fmt.Println("書き込み完了", <-chW)
fmt.Println("読み取り完了", <-chR)
}ここでは合計 3 つのパイプを作成しました。1 つのバッファありパイプはゴルーチン間通信用で、2 つのバッファなしパイプは親子ゴルーチンの実行順序を同期するために使用されます。読み取りを担当するゴルーチンは、読み取る前に毎回 1ms 待機し、書き込みを担当するゴルーチンは一度に最大 5 つのデータしか書き込めません。パイプバッファの最大容量は 5 であるため、他のゴルーチンが読み取る前にブロックして待機する必要があります。したがって、このサンプルの出力は以下の通りです。
書き込み 0
書き込み 1
書き込み 2
書き込み 3
書き込み 4 // 5 つ書き込んで、バッファが満杯、他のゴルーチンが読み取るのを待つ
読み取り 0
書き込み 5 // 1 つ読み取って、1 つ書き込む
読み取り 1
書き込み 6
読み取り 2
書き込み 7
読み取り 3
書き込み 8
書き込み 9
読み取り 4
書き込み完了 {} // すべてのデータが送信完了、書き込みゴルーチン実行終了
読み取り 5
読み取り 6
読み取り 7
読み取り 8
読み取り 9
読み取り完了 {} // すべてのデータが読み取り完了、読み取りゴルーチン実行終了書き込みを担当するゴルーチンは最初に 5 つのデータを一気に送信し、バッファが満杯になると読み取りゴルーチンがデータを読み取るまでブロックして待機します。その後、読み取りゴルーチンが 1ms ごとに 1 つのデータを読み取り、バッファに空きができると、書き込みゴルーチンが 1 つのデータを書き込みます。すべてのデータが送信完了し、書き込みゴルーチンの実行が終了します。その後、読み取りゴルーチンがバッファ内のすべてのデータを読み取ると、読み取りゴルーチンも実行が終了し、最後にメインゴルーチンが終了します。
TIP
組み込み関数 len を通じてパイプバッファ内のデータ数をアクセスでき、cap を通じてパイプバッファのサイズをアクセスできます。
func main() {
ch := make(chan int, 5)
ch <- 1
ch <- 2
ch <- 3
fmt.Println(len(ch), cap(ch))
}出力
3 5パイプのブロッキング条件を利用して、メインゴルーチンがサブルーチンの実行完了を待つ例を簡単に作成できます。
func main() {
// バッファなしパイプを作成
ch := make(chan struct{})
defer close(ch)
go func() {
fmt.Println(2)
// 書き込み
ch <- struct{}{}
}()
// ブロックして待機して読み取り
<-ch
fmt.Println(1)
}出力
2
1バッファありパイプを使用して、シンプルな相互排他ロックを実装することもできます。以下の例をご覧ください。
var count = 0
// バッファサイズ 1 のパイプ
var lock = make(chan struct{}, 1)
func Add() {
// ロック
lock <- struct{}{}
fmt.Println("現在の计数", count, "加算を実行")
count += 1
// アンロック
<-lock
}
func Sub() {
// ロック
lock <- struct{}{}
fmt.Println("現在の计数", count, "減算を実行")
count -= 1
// アンロック
<-lock
}パイプのバッファサイズが 1 であるため、バッファ内に最大 1 つのデータしか格納できません。Add と Sub 関数は、データを操作する前にパイプにデータを送信しようとします。バッファサイズが 1 であるため、他のゴルーチンがすでにデータを書き込んでバッファが満杯の場合、現在のゴルーチンはバッファに空きができるまでブロックして待機する必要があります。これにより、ある時点で、最大 1 つのゴルーチンのみで変数 count を変更でき、これによりシンプルな相互排他ロックを実装します。
注意点
以下はまとめです。以下のいくつかの状況では、使用不当によりパイプがブロックする可能性があります。
バッファなしパイプの読み書き
バッファなしパイプに対して同期読み書き操作を直接実行すると、現在のゴルーチンがブロックします。
func main() {
// バッファなしパイプを作成
intCh := make(chan int)
defer close(intCh)
// データを送信
intCh <- 1
// データを読み取り
ints, ok := <-intCh
fmt.Println(ints, ok)
}空バッファのパイプを読み取る
バッファが空のパイプを読み取ると、現在のゴルーチンがブロックします。
func main() {
// バッファありパイプを作成
intCh := make(chan int, 1)
defer close(intCh)
// バッファが空、他のゴルーチンがデータを書き込むのをブロックして待機
ints, ok := <-intCh
fmt.Println(ints, ok)
}満杯バッファのパイプに書き込む
パイプのバッファが満杯の場合、データを書き込むと現在のゴルーチンがブロックします。
func main() {
// バッファありパイプを作成
intCh := make(chan int, 1)
defer close(intCh)
intCh <- 1
// 満杯、他のゴルーチンがデータを読み取るのをブロックして待機
intCh <- 1
}パイプが nil
パイプが nil の場合、どのように読み書きしても現在のゴルーチンがブロックします。
func main() {
var intCh chan int
// 書き込み
intCh <- 1
}func main() {
var intCh chan int
// 読み取り
fmt.Println(<-intCh)
}パイプブロックの条件はよく理解し、熟悉する必要があります。ほとんどの場合、これらの問題は非常に隠れており、例のように直感的ではありません。
以下のいくつかの状況では、panic も引き起こします。
nil パイプを閉じる
パイプが nil の場合、close 関数を使用して閉じると panic が発生します。
func main() {
var intCh chan int
close(intCh)
}閉じられたパイプに書き込む
閉じられたパイプにデータを書き込むと panic が発生します。
func main() {
intCh := make(chan int, 1)
close(intCh)
intCh <- 1
}閉じられたパイプを閉じる
一部の状況では、パイプが何層も渡される可能性があり、呼び出し元は誰がパイプを閉じるべきか分からないかもしれません。これにより、すでに閉じられたパイプを閉じようとすると panic が発生します。
func main() {
ch := make(chan int, 1)
defer close(ch)
go write(ch)
fmt.Println(<-ch)
}
func write(ch chan<- int) {
// パイプにデータを送信することのみ可能
ch <- 1
close(ch)
}単方向パイプ
双方向パイプは、書き込みも読み取りも可能で、パイプの両側で操作できることを指します。単方向パイプは、読み取り専用または書き込み専用のパイプで、パイプの片側でのみ操作できることを指します。手動で作成した読み取り専用または書き込み専用のパイプは、パイプの読み書きができないため、その存在意義が失われ、あまり意味がありません。単方向パイプは通常、パイプの動作を制限するために使用され、一般に関数の形式パラメータと戻り値に現れます。例えば、パイプを閉じるために使用される組み込み関数 close の関数シグネチャは単方向パイプを使用しています。
func close(c chan<- Type)または、よく使用される time パッケージの After 関数
func After(d Duration) <-chan Timeclose 関数の形式パラメータは書き込み専用パイプで、After 関数の戻り値は読み取り専用パイプです。したがって、単方向パイプの構文は以下の通りです。
- 矢印記号
<-が前の場合、読み取り専用パイプです。例:<-chan int - 矢印記号
<-が後場合、書き込み専用パイプです。例:chan<- string
読み取り専用パイプにデータを書き込もうとすると、コンパイルに合格しません。
func main() {
timeCh := time.After(time.Second)
timeCh <- time.Now()
}エラーは以下の通りで、意味は非常に明確です。
invalid operation: cannot send to receive-only channel timeCh (variable of type <-chan time.Time)書き込み専用パイプからデータを読み取るのも同様です。
双方向パイプは単方向パイプに変換できますが、逆はできません。通常、双方向パイプをあるゴルーチンまたは関数に渡し、読み取り/送信してほしくない場合、単方向パイプを使用して相手の動作を制限できます。
func main() {
ch := make(chan int, 1)
go write(ch)
fmt.Println(<-ch)
}
func write(ch chan<- int) {
// パイプにデータを送信することのみ可能
ch <- 1
}読み取り専用パイプも同様の道理です。
TIP
chan は参照タイプであり、Go の関数パラメータは値渡しですが、その参照は依然として同じものです。これは後続のパイプ原理で説明します。
for range
for range 文を通じて、バッファパイプ内のデータを読み取ることができます。以下の例をご覧ください。
func main() {
ch := make(chan int, 10)
go func() {
for i := 0; i < 10; i++ {
ch <- i
}
}()
for n := range ch {
fmt.Println(n)
}
}通常、for range は他の反復可能データ構造を遍历する際、2 つの戻り値があります。1 つ目はインデックスで、2 つ目は要素値です。しかしパイプの場合、戻り値は 1 つだけです。for range はパイプ内の要素を継続的に読み取り、バッファが空またはバッファなしの場合、他のゴルーチンがパイプにデータを書き込むまでブロックして待機します。したがって、出力は以下の通りです。
0
1
2
3
4
5
6
7
8
9
fatal error: all goroutines are asleep - deadlock!上記のコードはデッドロックを発生させたことがわかります。サブルーチンがすでに実行を終了しているため、メインゴルーチンが他のゴルーチンがパイプにデータを書き込むのをブロックして待機しているため、パイプは書き込み完了後に閉じる必要があります。以下のコードに修正します。
func main() {
ch := make(chan int, 10)
go func() {
for i := 0; i < 10; i++ {
ch <- i
}
// パイプを閉じる
close(ch)
}()
for n := range ch {
fmt.Println(n)
}
}書き込み完了後にパイプを閉じると、上記のコードはデッドロックを発生させなくなります。前述したように、パイプの読み取りには 2 つの戻り値があります。for range がパイプを遍历する際、データを正常に読み取れない場合、ループを終了します。2 つ目の戻り値はデータを正常に読み取れるかどうかを指し、パイプがすでに閉じられているかどうかではありません。パイプがすでに閉じられていても、バッファありパイプの場合、依然としてデータを読み取ることができ、2 つ目の戻り値は依然として true です。以下の例をご覧ください。
func main() {
ch := make(chan int, 10)
for i := 0; i < 5; i++ {
ch <- i
}
// パイプを閉じる
close(ch)
// さらにデータを読み取る
for i := 0; i < 6; i++ {
n, ok := <-ch
fmt.Println(n, ok)
}
}出力結果
0 true
1 true
2 true
3 true
4 true
0 falseパイプがすでに閉じられているため、バッファが空でも、さらにデータを読み取っても現在のゴルーチンがブロックすることはありません。6 回目の遍历で読み取るのはゼロ値で、ok は false であることがわかります。
TIP
パイプを閉じるタイミングについては、できるだけパイプにデータを送信する側で閉じるべきで、受信側で閉じるべきではありません。ほとんどの場合、受信側はデータを受信することのみを知っており、いつパイプを閉じるべきか分からないためです。
WaitGroup
sync.WaitGroup は sync パッケージが提供する構造体で、WaitGroup は実行を待つことを意味し、これを使用してゴルーチングループを待つ効果を簡単に実装できます。この構造体は 3 つのメソッドのみを外部に公開しています。
Add メソッドは待つゴルーチンの数を指定するために使用されます。
func (wg *WaitGroup) Add(delta int)Done メソッドは現在のゴルーチンが実行を終了したことを示します。
func (wg *WaitGroup) Done()Wait メソッドはサブルーチンが終了するのを待ちます。否则ブロックします。
func (wg *WaitGroup) Wait()WaitGroup は非常に簡単に使用でき、开箱即用です。その内部実装はカウンター + セマフォで、プログラム開始時に Add を呼び出して计数を初期化し、ゴルーチンが実行を終了するたびに Done を呼び出し、计数が 1 減ります。0 になるまで、メインゴルーチンは Wait を呼び出してブロックし続け、すべての计数が 0 になってから初めてウェイクアップします。シンプルな使用例をご覧ください。
func main() {
var wait sync.WaitGroup
// サブルーチンの数を指定
wait.Add(1)
go func() {
fmt.Println(1)
// 実行終了
wait.Done()
}()
// サブルーチンを待つ
wait.Wait()
fmt.Println(2)
}このコードは常に 1 を出力してから 2 を出力します。メインゴルーチンはサブルーチンが実行を終了してから終了します。
1
2ゴルーチン紹介の最初の例に対して、以下の修正を加えることができます。
func main() {
var mainWait sync.WaitGroup
var wait sync.WaitGroup
// 计数 10
mainWait.Add(10)
fmt.Println("start")
for i := 0; i < 10; i++ {
// ループ内で计数 1
wait.Add(1)
go func() {
fmt.Println(i)
// 2 つの计数を 1 減らす
wait.Done()
mainWait.Done()
}()
// 現在のループのゴルーチンが実行を終了するのを待つ
wait.Wait()
}
// すべてのゴルーチンが実行を終了するのを待つ
mainWait.Wait()
fmt.Println("end")
}ここでは sync.WaitGroup を使用して元の time.Sleep を置き換え、ゴルーチンの並行実行順序をより制御可能にしました。何回実行しても、出力は以下の通りです。
start
0
1
2
3
4
5
6
7
8
9
endWaitGroup は通常、ゴルーチン数を動的に調整できる状況に適しています。例えば、事前にゴルーチンの数を知っている場合や、実行中に動的に調整する必要がある場合などです。WaitGroup の値はコピーするべきではなく、コピー後の値も继续使用するべきではありません。特に関数パラメータとして渡す際は、値ではなくポインタを渡す必要があります。コピーした値を使用すると、计数が実際の WaitGroup に作用せず、メインゴルーチンが常にブロックして待機し、プログラムが正常に実行できなくなる可能性があります。以下のコードをご覧ください。
func main() {
var mainWait sync.WaitGroup
mainWait.Add(1)
hello(mainWait)
mainWait.Wait()
fmt.Println("end")
}
func hello(wait sync.WaitGroup) {
fmt.Println("hello")
wait.Done()
}エラーはすべてのゴルーチンが終了したが、メインゴルーチンがまだ待機していることを示しています。これはデッドロックを形成しています。hello 関数内部で形式パラメータ WaitGroup に対して Done を呼び出しても、元の mainWait に作用しないため、ポインタを使用して渡す必要があります。
hello
fatal error: all goroutines are asleep - deadlock!TIP
计数が負の数になる場合、または计数数がサブルーチン数より大きい場合、panic が発生します。
Context
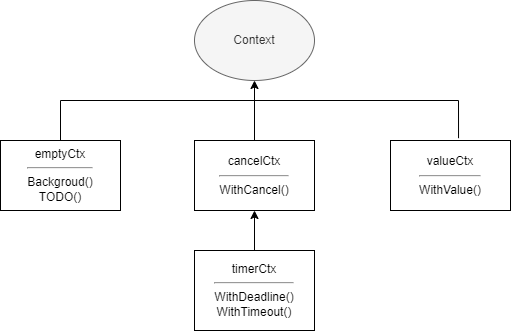
Context はコンテキストと訳され、Go が提供する並行処理制御の解決策です。パイプと WaitGroup と比較して、子孫ゴルーチンとより深い階層のゴルーチンをよりよく制御できます。Context 自体はインターフェースで、このインターフェースを実装したものはすべてコンテキストと呼ばれます。例えば、有名な Web フレームワーク Gin の gin.Context などです。context 標準ライブラリもいくつかの実装を提供しています。
emptyCtxcancelCtxtimerCtxvalueCtx
Context
まず Context インターフェースの定義を見て、その後具体的な実装を理解しましょう。
type Context interface {
Deadline() (deadline time.Time, ok bool)
Done() <-chan struct{}
Err() error
Value(key any) any
}Deadline
このメソッドは 2 つの戻り値を持ちます。deadline は締切時間で、つまりコンテキストがキャンセルされるべき時間です。2 つ目の値は deadline が設定されているかどうかで、設定されていない場合は常に false です。
Deadline() (deadline time.Time, ok bool)Done
その戻り値は空構造体タイプの読み取り専用パイプで、このパイプは通知の役割のみを果たし、データは送信しません。コンテキストが行う作業がキャンセルされるべき場合、このパイプは閉じられます。キャンセルをサポートしないコンテキストの場合、nil を返す可能性があります。
Done() <-chan struct{}Err
このメソッドは error を返し、コンテキストが閉じられた理由を示すために使用されます。Done パイプが閉じられていない場合、nil を返します。閉じられた後、err を返してなぜ閉じられたかを説明します。
Err() errorValue
このメソッドは対応するキー値を返します。key が存在しない場合、またはこのメソッドをサポートしていない場合、nil を返します。
Value(key any) anyemptyCtx
名前の通り、emptyCtx は空のコンテキストです。context パッケージのすべての実装は外部に公開されていませんが、コンテキストを作成するための関数が提供されています。emptyCtx は context.Background と context.TODO を通じて作成できます。2 つの関数は以下の通りです。
var (
background = new(emptyCtx)
todo = new(emptyCtx)
)
func Background() Context {
return background
}
func TODO() Context {
return todo
}emptyCtx ポインタを返すことのみがわかります。emptyCtx の底层タイプは実際には int です。空構造体を使用しない理由は、emptyCtx のインスタンスが異なるメモリアドレスを持つ必要があるためです。キャンセルできず、deadline もなく、値も取得できません。実装されたメソッドはすべてゼロ値を返します。
type emptyCtx int
func (*emptyCtx) Deadline() (deadline time.Time, ok bool) {
return
}
func (*emptyCtx) Done() <-chan struct{} {
return nil
}
func (*emptyCtx) Err() error {
return nil
}
func (*emptyCtx) Value(key any) any {
return nil
}emptyCtx は通常、最上位のコンテキストとして使用され、他の 3 つのコンテキストを作成する際に親コンテキストとして渡されます。context パッケージ内の各実装の関係は以下の図の通りです。
valueCtx
valueCtx の実装は比較的簡単で、内部にはキーバリューペアと、Context タイプの埋め込みフィールドのみが含まれています。
type valueCtx struct {
Context
key, val any
}それ自体は Value メソッドのみを実装しており、ロジックも非常にシンプルです。現在のコンテキストで見つからない場合は親コンテキストを探します。
func (c *valueCtx) Value(key any) any {
if c.key == key {
return c.val
}
return value(c.Context, key)
}以下に valueCtx のシンプルな使用例を示します。
var waitGroup sync.WaitGroup
func main() {
waitGroup.Add(1)
// コンテキストを渡す
go Do(context.WithValue(context.Background(), 1, 2))
waitGroup.Wait()
}
func Do(ctx context.Context) {
// 新しいタイマーを作成
ticker := time.NewTimer(time.Second)
defer waitGroup.Done()
for {
select {
case <-ctx.Done(): // 永遠に実行されない
case <-ticker.C:
fmt.Println("timeout")
return
default:
fmt.Println(ctx.Value(1))
}
time.Sleep(time.Millisecond * 100)
}
}valueCtx は多级ゴルーチンでいくつかのデータを渡すために使用され、キャンセルできないため、ctx.Done は常に nil を返し、select は nil パイプを無視します。最後に出力は以下の通りです。
2
2
2
2
2
2
2
2
2
2
timeoutcancelCtx
cancelCtx と timerCtx は両方とも canceler インターフェースを実装しています。インターフェースタイプは以下の通りです。
type canceler interface {
// removeFromParent は親コンテキストから自身を削除するかどうかを示します
// err はキャンセルの理由を示します
cancel(removeFromParent bool, err error)
// Done はキャンセルの理由を通知するために使用されるパイプを返します
Done() <-chan struct{}
}cancel メソッドは外部に公開されておらず、コンテキストを作成する際にクロージャを通じて戻り値としてパッケージ化され、外部から呼び出せるようにします。context.WithCancel ソースコードに示されている通りです。
func WithCancel(parent Context) (ctx Context, cancel CancelFunc) {
if parent == nil {
panic("cannot create context from nil parent")
}
c := newCancelCtx(parent)
// 自身を親の children に追加しようとします
propagateCancel(parent, &c)
// context と関数を返します
return &c, func() { c.cancel(true, Canceled) }
}cancelCtx はキャンセル可能なコンテキストと訳されます。作成時、親が canceler を実装している場合、自身を親の children に追加します。否则常に上に検索し続けます。すべての親が canceler を実装していない場合、ゴルーチンを開始して親がキャンセルするのを待ち、親が終了したときに現在のコンテキストをキャンセルします。cancelFunc を呼び出すと、Done パイプが閉じられ、このコンテキストのすべての子も随之にキャンセルされ、最後に自身を親から削除します。以下はシンプルなサンプルです。
var waitGroup sync.WaitGroup
func main() {
bkg := context.Background()
// cancelCtx と cancel 関数を返します
cancelCtx, cancel := context.WithCancel(bkg)
waitGroup.Add(1)
go func(ctx context.Context) {
defer waitGroup.Done()
for {
select {
case <-ctx.Done():
fmt.Println(ctx.Err())
return
default:
fmt.Println("キャンセルを待機中...")
}
time.Sleep(time.Millisecond * 200)
}
}(cancelCtx)
time.Sleep(time.Second)
cancel()
waitGroup.Wait()
}出力は以下の通りです。
キャンセルを待機中...
キャンセルを待機中...
キャンセルを待機中...
キャンセルを待機中...
キャンセルを待機中...
context canceledさらに階層ネストが深いサンプルを見てみましょう。
var waitGroup sync.WaitGroup
func main() {
waitGroup.Add(3)
ctx, cancelFunc := context.WithCancel(context.Background())
go HttpHandler(ctx)
time.Sleep(time.Second)
cancelFunc()
waitGroup.Wait()
}
func HttpHandler(ctx context.Context) {
cancelCtxAuth, cancelAuth := context.WithCancel(ctx)
cancelCtxMail, cancelMail := context.WithCancel(ctx)
defer cancelAuth()
defer cancelMail()
defer waitGroup.Done()
go AuthService(cancelCtxAuth)
go MailService(cancelCtxMail)
for {
select {
case <-ctx.Done():
fmt.Println(ctx.Err())
return
default:
fmt.Println("http リクエストを処理中...")
}
time.Sleep(time.Millisecond * 200)
}
}
func AuthService(ctx context.Context) {
defer waitGroup.Done()
for {
select {
case <-ctx.Done():
fmt.Println("auth 親キャンセル", ctx.Err())
return
default:
fmt.Println("auth...")
}
time.Sleep(time.Millisecond * 200)
}
}
func MailService(ctx context.Context) {
defer waitGroup.Done()
for {
select {
case <-ctx.Done():
fmt.Println("mail 親キャンセル", ctx.Err())
return
default:
fmt.Println("mail...")
}
time.Sleep(time.Millisecond * 200)
}
}例では 3 つの cancelCtx を作成しました。親 cancelCtx がキャンセルされると同時にその子コンテキストもキャンセルされますが、念のため、cancelCtx を作成した場合は、対応するフロー終了後に cancel 関数を呼び出す必要があります。出力は以下の通りです。
http リクエストを処理中...
auth...
mail...
mail...
auth...
http リクエストを処理中...
auth...
mail...
http リクエストを処理中...
http リクエストを処理中...
auth...
mail...
auth...
http リクエストを処理中...
mail...
context canceled
auth 親キャンセル context canceled
mail 親キャンセル context canceledtimerCtx
timerCtx は cancelCtx にタイムアウトメカニズムを追加したもので、context パッケージは 2 つの作成関数を提供しています。それぞれ WithDeadline と WithTimeout です。両者の機能は似ており、前者は具体的なタイムアウト時間を指定します。例えば、具体的な時間 2023/3/20 16:32:00 を指定します。後者はタイムアウト時間間隔を指定します。例えば、5 分後などです。2 つの関数のシグネチャは以下の通りです。
func WithDeadline(parent Context, d time.Time) (Context, CancelFunc)
func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc)timerCtx は時間到期後に自動的に現在のコンテキストをキャンセルします。キャンセルフローは timer を追加で閉じる以外は、基本的に cancelCtx と同じです。以下はシンプルな timerCtx の使用例です。
var wait sync.WaitGroup
func main() {
deadline, cancel := context.WithDeadline(context.Background(), time.Now().Add(time.Second))
defer cancel()
wait.Add(1)
go func(ctx context.Context) {
defer wait.Done()
for {
select {
case <-ctx.Done():
fmt.Println("コンテキストキャンセル", ctx.Err())
return
default:
fmt.Println("キャンセルを待機中...")
}
time.Sleep(time.Millisecond * 200)
}
}(deadline)
wait.Wait()
}コンテキストが期限到期後に自動的にキャンセルされますが、念のため、関連するフロー終了後に手動でコンテキストをキャンセルすることをお勧めします。出力は以下の通りです。
キャンセルを待機中...
キャンセルを待機中...
キャンセルを待機中...
キャンセルを待機中...
キャンセルを待機中...
コンテキストキャンセル context deadline exceededWithTimeout は実際には WithDealine と非常に似ており、その実装も少しラップして WithDeadline を呼び出すだけです。上記の例の WithDeadline の使い方と同じです。以下の通りです。
func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc) {
return WithDeadline(parent, time.Now().Add(timeout))
}TIP
メモリ割り当て後に回収しないとメモリリークを引き起こすのと同じように、コンテキストもリソースです。作成してもキャンセルしないと、コンテキストリークを引き起こします。そのため、このような状況を避けることをお勧めします。
Select
select は Linux システムでは、IO 多重化の解決策です。同様に、Go では、select はパイプ多重化の制御構造です。多重化とは何か、簡単に一言で概括すると:ある時点で、複数の要素が使用可能かどうかを同時に監視します。監視される要素はネットワークリクエスト、ファイル IO などです。Go の select が監視する要素はパイプで、パイプのみです。select の構文は switch 文と似ています。以下に select 文がどのようなものかを見てみましょう。
func main() {
// 3 つのパイプを作成
chA := make(chan int)
chB := make(chan int)
chC := make(chan int)
defer func() {
close(chA)
close(chB)
close(chC)
}()
select {
case n, ok := <-chA:
fmt.Println(n, ok)
case n, ok := <-chB:
fmt.Println(n, ok)
case n, ok := <-chC:
fmt.Println(n, ok)
default:
fmt.Println("すべてのパイプが使用できません")
}
}使用
switch と同様に、select は複数の case と 1 つの default で構成されます。default 分岐は省略できます。各 case は 1 つのパイプのみを操作でき、1 つの操作のみを実行できます。読み取りまたは書き込みのいずれかです。複数の case が使用可能な場合、select は擬似ランダムに 1 つの case を選択して実行します。すべての case が使用できない場合、default 分岐を実行します。default 分岐がない場合、少なくとも 1 つの case が使用可能になるまでブロックして待機します。上記の例ではパイプにデータが書き込まれていないため、当然すべての case が使用できず、最終的に default 分岐の実行結果が出力されます。少し修正すると以下の通りです。
func main() {
chA := make(chan int)
chB := make(chan int)
chC := make(chan int)
defer func() {
close(chA)
close(chB)
close(chC)
}()
// 新しいゴルーチンを開始
go func() {
// A パイプにデータを書き込む
chA <- 1
}()
select {
case n, ok := <-chA:
fmt.Println(n, ok)
case n, ok := <-chB:
fmt.Println(n, ok)
case n, ok := <-chC:
fmt.Println(n, ok)
}
}上記の例では新しいゴルーチンを開始してパイプ A にデータを書き込みます。select にはデフォルト分岐がないため、case が使用可能になるまでブロックして待機し続けます。パイプ A が使用可能になると、対応する分岐を実行した後、メインゴルーチンが直接終了します。パイプを常に監視するには、for ループと組み合わせて使用します。以下の通りです。
func main() {
chA := make(chan int)
chB := make(chan int)
chC := make(chan int)
defer func() {
close(chA)
close(chB)
close(chC)
}()
go Send(chA)
go Send(chB)
go Send(chC)
// for ループ
for {
select {
case n, ok := <-chA:
fmt.Println("A", n, ok)
case n, ok := <-chB:
fmt.Println("B", n, ok)
case n, ok := <-chC:
fmt.Println("C", n, ok)
}
}
}
func Send(ch chan<- int) {
for i := 0; i < 3; i++ {
time.Sleep(time.Millisecond)
ch <- i
}
}これにより確かに 3 つのパイプすべてを使用できますが、無限ループ + select はメインゴルーチンを永久にブロックするため、新しいゴルーチンに配置し、他のロジックを追加できます。
func main() {
chA := make(chan int)
chB := make(chan int)
chC := make(chan int)
defer func() {
close(chA)
close(chB)
close(chC)
}()
l := make(chan struct{})
go Send(chA)
go Send(chB)
go Send(chC)
go func() {
Loop:
for {
select {
case n, ok := <-chA:
fmt.Println("A", n, ok)
case n, ok := <-chB:
fmt.Println("B", n, ok)
case n, ok := <-chC:
fmt.Println("C", n, ok)
case <-time.After(time.Second): // 1 秒のタイムアウト時間を設定
break Loop // ループを終了
}
}
l <- struct{}{} // メインゴルーチンに終了を通知
}()
<-l
}
func Send(ch chan<- int) {
for i := 0; i < 3; i++ {
time.Sleep(time.Millisecond)
ch <- i
}
}上記の例では、for ループと select を組み合わせて、3 つのパイプが使用可能かどうかを常に監視します。4 つ目の case はタイムアウトパイプで、タイムアウト後にループを終了し、サブルーチンを終了します。最終出力は以下の通りです。
C 0 true
A 0 true
B 0 true
A 1 true
B 1 true
C 1 true
B 2 true
C 2 true
A 2 trueタイムアウト
前の例では time.After 関数を使用しました。その戻り値は読み取り専用パイプで、この関数と select を組み合わせて使用すると、非常に簡単にタイムアウトメカニズムを実装できます。例は以下の通りです。
func main() {
chA := make(chan int)
defer close(chA)
go func() {
time.Sleep(time.Second * 2)
chA <- 1
}()
select {
case n := <-chA:
fmt.Println(n)
case <-time.After(time.Second):
fmt.Println("タイムアウト")
}
}永久ブロック
select 文内に何もない場合、永久にブロックします。例えば
func main() {
fmt.Println("start")
select {}
fmt.Println("end")
}end は永遠に出力されず、メインゴルーチンは常にブロックします。この状況は通常、特別な用途があります。
TIP
select の case で値が nil のパイプを操作すると、ブロックを引き起こさず、その case は無視され、永遠に実行されません。以下のコードは何回実行しても timeout のみ出力されます。
func main() {
var nilCh chan int
select {
case <-nilCh:
fmt.Println("read")
case nilCh <- 1:
fmt.Println("write")
case <-time.After(time.Second):
fmt.Println("timeout")
}
}ノンブロッキング
select の default 分岐とパイプを組み合わせて使用することで、ノンブロッキングの送受信操作を実装できます。以下の通りです。
func TrySend(ch chan int, ele int) bool {
select {
case ch <- ele:
return true
default:
return false
}
}
func TryRecv(ch chan int) (int, bool) {
select {
case ele, ok := <-ch:
return ele, ok
default:
return 0, false
}
}同様に、context がすでに終了したかどうかをノンブロッキングで判断することもできます。
func IsDone(ctx context.Context) bool {
select {
case <-ctx.Done():
return true
default:
return false
}
}ロック
まず以下の例をご覧ください。
var wait sync.WaitGroup
var count = 0
func main() {
wait.Add(10)
for i := 0; i < 10; i++ {
go func(data *int) {
// アクセス時間消費をシミュレート
time.Sleep(time.Millisecond * time.Duration(rand.Intn(5000)))
// データにアクセス
temp := *data
// 計算時間消費をシミュレート
time.Sleep(time.Millisecond * time.Duration(rand.Intn(5000)))
ans := 1
// データを変更
*data = temp + ans
fmt.Println(*data)
wait.Done()
}(&count)
}
wait.Wait()
fmt.Println("最終結果", count)
}上記の例では、10 個のゴルーチンを開始して count に対して +1 操作を実行し、time.Sleep を使用して異なる時間消費をシミュレートしました。直感的には、10 個のゴルーチンが 10 個の +1 操作を実行するため、最終結果は必ず 10 になるはずです。正しい結果も確かに 10 ですが、事実はそうではありません。上記の例の実行結果は以下の通りです。
1
2
3
3
2
2
3
3
3
4
最終結果 4最終結果が 4 であることがわかります。これは多くの可能性のうちの 1 つに過ぎません。各ゴルーチンのアクセスと計算に必要な時間が異なるため、A ゴルーチンがデータにアクセスするのに 500ms かかり、この時点でアクセスした count 値は 1 です。その後、400ms をかけて計算しますが、この 400ms 内に、B ゴルーチンがすでにアクセスと計算を完了し、count の値を正常に更新しました。A ゴルーチンが計算を完了した後、A ゴルーチンが最初にアクセスした値はすでに古くなっていますが、A ゴルーチンはそのことを知らず、依然として最初にアクセスした値に 1 を加算し、count に代入します。これにより、B ゴルーチンの実行結果が上書きされます。複数のゴルーチンが共有データを読み取りおよびアクセスする際、特にこのような問題が発生します。そのため、ロックを使用する必要があります。
Go の sync パッケージの Mutex と RWMutex は、相互排他ロックと読み書きロックの 2 つの実装を提供しており、非常に简单易用な API を提供しています。ロックするには Lock() が必要で、アンロックするには Unlock() が必要です。注意すべき点は、Go が提供するロックは非再帰ロック、つまり非再入ロックであるため、重複ロックまたは重複アンロックは fatal を引き起こします。ロックの意義は不変量を保護することです。ロックするのは、データが他のゴルーチンによって変更されないことを望むためです。以下の通りです。
func DoSomething() {
Lock()
// このプロセス中、データは他のゴルーチンによって変更されません
Unlock()
}再帰ロックの場合、以下の状況が発生する可能性があります。
func DoSomething() {
Lock()
DoOther()
Unlock()
}
func DoOther() {
Lock()
// 何か処理を行う
Unlock()
}DoSomthing 関数は明らかに DoOther 関数がデータに対して何を行うか分からず、データを変更し、例えばさらにいくつかのサブルーチンを開始して不変量を破壊します。これは Go では許されません。ロックした後は不変量の不変性を保証する必要があります。この時点で重複ロックとアンロックはデッドロックを引き起こします。したがって、コードを記述する際には上記の状況を避けるべきで、必要に応じてロックすると同時に defer 文を使用してアンロックします。
相互排他ロック
sync.Mutex は Go が提供する相互排他ロックの実装で、sync.Locker インターフェースを実装しています。
type Locker interface {
// ロック
Lock()
// アンロック
Unlock()
}相互排他ロックを使用すると、上記の問題を非常に完璧に解決できます。例は以下の通りです。
var wait sync.WaitGroup
var count = 0
var lock sync.Mutex
func main() {
wait.Add(10)
for i := 0; i < 10; i++ {
go func(data *int) {
// ロック
lock.Lock()
// アクセス時間消費をシミュレート
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
// データにアクセス
temp := *data
// 計算時間消費をシミュレート
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
ans := 1
// データを変更
*data = temp + ans
// アンロック
lock.Unlock()
fmt.Println(*data)
wait.Done()
}(&count)
}
wait.Wait()
fmt.Println("最終結果", count)
}各ゴルーチンはデータにアクセスする前にロックし、更新完了後にアンロックします。他のゴルーチンがアクセスするには、まずロックを取得する必要があります。否则ブロックして待機します。これにより、上記の問題は存在しなくなります。したがって、出力は以下の通りです。
1
2
3
4
5
6
7
8
9
10
最終結果 10読み書きロック
相互排他ロックは読み取り操作と書き込み操作の頻度がほぼ同じ状況に適しています。読み取りが多く書き込みが少ないデータの場合、相互排他ロックを使用すると、多くの不要なゴルーチンがロックを競合し、多くのシステムリソースを消費します。この時点で読み書きロック、つまり読み書き相互排他ロックを使用する必要があります。あるゴルーチンにとって:
- 読み取りロックを取得した場合、他のゴルーチンが書き込み操作を実行するとブロックし、他のゴルーチンが読み取り操作を実行するとブロックしません。
- 書き込みロックを取得した場合、他のゴルーチンが書き込み操作を実行するとブロックし、他のゴルーチンが読み取り操作を実行するとブロックします。
Go の読み書き相互排他ロックの実装は sync.RWMutex で、これも Locker インターフェースを実装していますが、より多くの使用可能なメソッドを提供しています。以下の通りです。
// 読み取りロック
func (rw *RWMutex) RLock()
// 読み取りロックを試みる
func (rw *RWMutex) TryRLock() bool
// 読み取りアンロック
func (rw *RWMutex) RUnlock()
// 書き込みロック
func (rw *RWMutex) Lock()
// 書き込みロックを試みる
func (rw *RWMutex) TryLock() bool
// 書き込みアンロック
func (rw *RWMutex) Unlock()TryRlock と TryLock の 2 つのロック試行操作はノンブロッキング式で、ロックに成功すると true を返し、ロックを取得できない場合はブロックせず false を返します。読み書き相互排他ロックの内部実装は依然として相互排他ロックで、読み取りロックと書き込みロックに分かれているからといって 2 つのロックがあるわけではありません。最初から最後まで 1 つのロックのみです。以下に読み書き相互排他ロックの使用例を示します。
var wait sync.WaitGroup
var count = 0
var rw sync.RWMutex
func main() {
wait.Add(12)
// 読み取りが多く書き込みが少ない
go func() {
for i := 0; i < 3; i++ {
go Write(&count)
}
wait.Done()
}()
go func() {
for i := 0; i < 7; i++ {
go Read(&count)
}
wait.Done()
}()
// サブルーチンが終了するのを待つ
wait.Wait()
fmt.Println("最終結果", count)
}
func Read(i *int) {
time.Sleep(time.Millisecond * time.Duration(rand.Intn(500)))
rw.RLock()
fmt.Println("読み取りロックを取得")
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
fmt.Println("読み取りロックを解放", *i)
rw.RUnlock()
wait.Done()
}
func Write(i *int) {
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
rw.Lock()
fmt.Println("書き込みロックを取得")
temp := *i
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
*i = temp + 1
fmt.Println("書き込みロックを解放", *i)
rw.Unlock()
wait.Done()
}この例では 3 つの書き込みゴルーチンと 7 つの読み取りゴルーチンを開始しました。データを読み取る際は、まず読み取りロックを取得します。読み取りゴルーチンは正常に読み取りロックを取得できますが、書き込みゴルーチンをブロックします。書き込みロックを取得する際は、読み取りゴルーチンと書き込みゴルーチンの両方をブロックします。書き込みロックが解放されるまで、これにより読み取りゴルーチンと書き込みゴルーチンの相互排他を実装し、データの正確性を保証します。例の出力は以下の通りです。
読み取りロックを取得
読み取りロックを取得
読み取りロックを取得
読み取りロックを取得
解放読み取りロック 0
解放読み取りロック 0
解放読み取りロック 0
解放読み取りロック 0
書き込みロックを取得
解放書き込みロック 1
読み取りロックを取得
読み取りロックを取得
読み取りロックを取得
解放読み取りロック 1
解放読み取りロック 1
解放読み取りロック 1
書き込みロックを取得
解放書き込みロック 2
書き込みロックを取得
解放書き込みロック 3
最終結果 3TIP
ロックにとって、値として渡して保存するべきではなく、ポインタを使用するべきです。
条件変数
条件変数は、相互排他ロックと共に出現および使用されるため、一部の人々は条件ロックと誤って呼ぶかもしれませんが、それはロックではなく、通信メカニズムです。Go の sync.Cond はこれに対する実装を提供しています。条件変数を作成する関数シグネチャは以下の通りです。
func NewCond(l Locker) *Cond条件変数を作成する前提は、ロックを作成する必要があることがわかります。sync.Cond は以下の方法を提供して使用できます。
// 条件が有効になるまでブロックして待機し、ウェイクアップされるまで待機
func (c *Cond) Wait()
// 条件でブロックしている 1 つのゴルーチンをウェイクアップ
func (c *Cond) Signal()
// 条件でブロックしているすべてのゴルーチンをウェイクアップ
func (c *Cond) Broadcast()条件変数の使用は非常に簡単です。上記の読み書き相互排他ロックの例を少し修正するだけです。
var wait sync.WaitGroup
var count = 0
var rw sync.RWMutex
// 条件変数
var cond = sync.NewCond(rw.RLocker())
func main() {
wait.Add(12)
// 読み取りが多く書き込みが少ない
go func() {
for i := 0; i < 3; i++ {
go Write(&count)
}
wait.Done()
}()
go func() {
for i := 0; i < 7; i++ {
go Read(&count)
}
wait.Done()
}()
// サブルーチンが終了するのを待つ
wait.Wait()
fmt.Println("最終結果", count)
}
func Read(i *int) {
time.Sleep(time.Millisecond * time.Duration(rand.Intn(500)))
rw.RLock()
fmt.Println("読み取りロックを取得")
// 条件が満たされない場合は常にブロック
for *i < 3 {
cond.Wait()
}
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
fmt.Println("読み取りロックを解放", *i)
rw.RUnlock()
wait.Done()
}
func Write(i *int) {
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
rw.Lock()
fmt.Println("書き込みロックを取得")
temp := *i
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
*i = temp + 1
fmt.Println("書き込みロックを解放", *i)
rw.Unlock()
// 条件変数でブロックしているすべてのゴルーチンをウェイクアップ
cond.Broadcast()
wait.Done()
}条件変数を作成する際、ここでは条件変数が読み取りゴルーチンに作用するため、読み取りロックを相互排他ロックとして渡します。読み書き相互排他ロックを直接渡すと、書き込みゴルーチンが重複してアンロックする問題が発生します。ここでは sync.rlocker を渡します。RWMutex.RLocker メソッドを通じて取得します。
func (rw *RWMutex) RLocker() Locker {
return (*rlocker)(rw)
}
type rlocker RWMutex
func (r *rlocker) Lock() { (*RWMutex)(r).RLock() }
func (r *rlocker) Unlock() { (*RWMutex)(r).RUnlock() }rlocker も読み書き相互排他ロックの読み取りロック操作をラップしただけで、実際には同じ参照で、依然として同じロックです。読み取りゴルーチンがデータを読み取る際、3 より小さい場合は常にブロックして待機し、データが 3 より大きくなるまで待機します。書き込みゴルーチンはデータ更新後に条件変数でブロックしているすべてのゴルーチンをウェイクアップしようとします。したがって、最後の出力は以下の通りです。
読み取りロックを取得
読み取りロックを取得
読み取りロックを取得
読み取りロックを取得
書き込みロックを取得
解放書き込みロック 1
読み取りロックを取得
書き込みロックを取得
解放書き込みロック 2
読み取りロックを取得
読み取りロックを取得
書き込みロックを取得
解放書き込みロック 3 // 3 番目の書き込みゴルーチンが実行を終了
解放読み取りロック 3
解放読み取りロック 3
解放読み取りロック 3
解放読み取りロック 3
解放読み取りロック 3
解放読み取りロック 3
解放読み取りロック 3
最終結果 3結果から、3 番目の書き込みゴルーチンがデータを更新した後、条件変数でブロックしている 7 つの読み取りゴルーチンがすべて実行を再開したことがわかります。
TIP
条件変数にとって、if ではなく for を使用するべきです。条件が満たされているかどうかを判断するにはループを使用するべきです。ゴルーチンがウェイクアップされたときに現在の条件がすでに満たされているとは限らないためです。
for !condition {
cond.Wait()
}sync
Go の多くの並行処理関連ツールは sync 標準ライブラリによって提供されています。上記ですでに sync.WaitGroup、sync.Locker などを紹介しました。除此之外、sync パッケージには他にもいくつかのツールを使用できます。
Once
データ構造を使用する際、これらのデータ構造が非常に庞大な場合、遅延ロード方式を採用することを検討できます。つまり、実際に使用するときにのみそのデータ構造を初期化します。以下の例をご覧ください。
type MySlice []int
func (m *MySlice) Get(i int) (int, bool) {
if *m == nil {
return 0, false
} else {
return (*m)[i], true
}
}
func (m *MySlice) Add(i int) {
// 実際にスライスを使用するときにのみ初期化を検討
if *m == nil {
*m = make([]int, 0, 10)
}
*m = append(*m, i)
}問題が発生しました。1 つのゴルーチンのみで使用する場合、確かに問題はありませんが、複数のゴルーチンがアクセスする場合、問題が発生する可能性があります。例えば、ゴルーチン A と B が同時に Add メソッドを呼び出し、A の実行が少し速く、すでに初期化を完了し、データを正常に追加しました。その後、ゴルーチン B が再度初期化し、これによりゴルーチン A が追加したデータを直接上書きします。これが問題です。
これは sync.Once が解決する問題です。名前の通り、Once は 1 回と訳され、sync.Once は並行処理条件下で指定された操作が 1 回のみ実行されることを保証します。その使用は非常に簡単で、Do メソッド 1 つのみを外部に公開しています。シグネチャは以下の通りです。
func (o *Once) Do(f func())使用する際は、初期化操作を Do メソッドに渡すだけです。以下の通りです。
var wait sync.WaitGroup
func main() {
var slice MySlice
wait.Add(4)
for i := 0; i < 4; i++ {
go func() {
slice.Add(1)
wait.Done()
}()
}
wait.Wait()
fmt.Println(slice.Len())
}
type MySlice struct {
s []int
o sync.Once
}
func (m *MySlice) Get(i int) (int, bool) {
if m.s == nil {
return 0, false
} else {
return m.s[i], true
}
}
func (m *MySlice) Add(i int) {
// 実際にスライスを使用するときにのみ初期化を検討
m.o.Do(func() {
fmt.Println("初期化")
if m.s == nil {
m.s = make([]int, 0, 10)
}
})
m.s = append(m.s, i)
}
func (m *MySlice) Len() int {
return len(m.s)
}出力は以下の通りです。
初期化
4出力結果から、すべてのデータが正常にスライスに追加され、初期化操作が 1 回のみ実行されたことがわかります。実際、sync.Once の実装は非常に簡単で、コメントを削除すると実際のコードロジックは 16 行のみです。その原理はロック + アトミック操作です。ソースコードは以下の通りです。
type Once struct {
// 操作がすでに実行されたかどうかを判断するために使用
done uint32
m Mutex
}
func (o *Once) Do(f func()) {
// アトミックにデータをロード
if atomic.LoadUint32(&o.done) == 0 {
o.doSlow(f)
}
}
func (o *Once) doSlow(f func()) {
// ロック
o.m.Lock()
// アンロック
defer o.m.Unlock()
// 実行されたかどうかを判断
if o.done == 0 {
// 実行完了後に done を変更
defer atomic.StoreUint32(&o.done, 1)
f()
}
}Pool
sync.Pool の設計目的は、一時的なオブジェクトを格納して後続の再利用のために使用することです。一時的な並行処理安全なオブジェクトプールで、一時的に使用しないオブジェクトをプールに格納し、後続の使用で追加でオブジェクトを作成せずに直接再利用でき、メモリの割り当てと解放頻度を減らし、最も重要なのは GC 圧力を低減することです。sync.Pool は合計 2 つのメソッドのみがあります。以下の通りです。
// オブジェクトを申請
func (p *Pool) Get() any
// オブジェクトを格納
func (p *Pool) Put(x any)また、sync.Pool には外部に公開された New フィールドがあり、オブジェクトプールがオブジェクトを申請できないときにオブジェクトを初期化するために使用されます。
New func() any以下に例を示します。
var wait sync.WaitGroup
// 一時オブジェクトプール
var pool sync.Pool
// プロセス中に合計でいくつのオブジェクトが作成されたかを计数するために使用
var numOfObject atomic.Int64
// BigMemData メモリを多く占有する構造体と仮定
type BigMemData struct {
M string
}
func main() {
pool.New = func() any {
numOfObject.Add(1)
return BigMemData{"大メモリ"}
}
wait.Add(1000)
// ここで 1000 個のゴルーチンを開始
for i := 0; i < 1000; i++ {
go func() {
// オブジェクトを申請
val := pool.Get()
// オブジェクトを使用
_ = val.(BigMemData)
// 使用後にオブジェクトを解放
pool.Put(val)
wait.Done()
}()
}
wait.Wait()
fmt.Println(numOfObject.Load())
}例では 1000 個のゴルーチンを開始して、プール内でオブジェクトを申請および解放し続けます。オブジェクトプールを使用しない場合、1000 個のゴルーチンはそれぞれオブジェクトをインスタンス化する必要があり、これら 1000 個のインスタンス化後のオブジェクトは使用後に GC によってメモリを解放する必要があります。数十万個のゴルーチンがある場合、または該オブジェクトの作成コストが非常に高い場合、この状況では多くのメモリを占有し、GC に非常に大きな圧力をもたらします。オブジェクトプールを採用した後、オブジェクトを再利用してインスタンス化頻度を減らすことができます。例えば、上記の例の出力は以下のようになる可能性があります。
51000 個のゴルーチンを開始しても、プロセス中に 5 個のオブジェクトのみが作成されました。オブジェクトプールを使用しない場合、1000 個のゴルーチンは 1000 個のオブジェクトを作成します。この最適化による向上は明らかです。特に並行処理量が非常に大きく、オブジェクトのインスタンス化コストが特に高い場合、その優位性をより発揮できます。
sync.Pool を使用する際は、いくつかの点に注意する必要があります。
- 一時オブジェクト:
sync.Poolは一時オブジェクトを格納するのにのみ適しています。プール内のオブジェクトは通知なしで GC によって削除される可能性があるため、ネットワークリンク、データベース接続などをsync.Poolに格納することはお勧めしません。 - 予測不能:
sync.Poolはオブジェクトを申請する際、このオブジェクトが新規作成されたものか再利用されたものかを予測できず、プール内にいくつのオブジェクトがあるかも分かりません。 - 並行処理安全:公式は
sync.Poolが必ず並行処理安全であることを保証していますが、オブジェクトを作成するために使用されるNew関数が並行処理安全であるとは限りません。New関数は使用者によって渡されるため、New関数の並行処理安全性は使用者自身が保守する必要があります。这也是上記の例でオブジェクト计数にアトミック値を使用する理由です。
TIP
最後に注意すべき点は、オブジェクトの使用後は、必ずプールに解放することです。使用しても解放しないと、オブジェクトプールの使用は無意味になります。
標準ライブラリ fmt パッケージにはオブジェクトプールの使用例があります。fmt.Fprintf 関数内です。
func Fprintf(w io.Writer, format string, a ...any) (n int, err error) {
// 印刷バッファを申請
p := newPrinter()
p.doPrintf(format, a)
n, err = w.Write(p.buf)
// 使用後に解放
p.free()
return
}その中で newPointer 関数と free メソッドの実装は以下の通りです。
func newPrinter() *pp {
// オブジェクトプールから申請したオブジェクト
p := ppFree.Get().(*pp)
p.panicking = false
p.erroring = false
p.wrapErrs = false
p.fmt.init(&p.buf)
return p
}
func (p *pp) free() {
// オブジェクトプール内のバッファサイズをほぼ同じにして、バッファサイズをより弾力的に制御できるようにするため
// 大きすぎるバッファはオブジェクトプールに戻さない
if cap(p.buf) > 64<<10 {
return
}
// フィールドをリセット後にオブジェクトをプールに解放
p.buf = p.buf[:0]
p.arg = nil
p.value = reflect.Value{}
p.wrappedErr = nil
ppFree.Put(p)
}Map
sync.Map は公式が提供する並行処理安全な Map の実装で、开箱即用で、使用は非常に簡単です。以下はこの構造体が外部に公開するメソッドです。
// key に応じて値を読み取り、戻り値は対応する値と該値が存在するかどうかを返します
func (m *Map) Load(key any) (value any, ok bool)
// キーバリューペアを格納
func (m *Map) Store(key, value any)
// キーバリューペアを削除
func (m *Map) Delete(key any)
// 該 key がすでに存在する場合、既存の値を返し、否则新しい値を格納して返します。値を正常に読み取れた場合、loaded は true、否则 false です
func (m *Map) LoadOrStore(key, value any) (actual any, loaded bool)
// キーバリューペアを削除し、その既存の値を返します。loaded の値は key が存在するかどうかによって異なります
func (m *Map) LoadAndDelete(key any) (value any, loaded bool)
// Map を遍历します。f() が false を返すと、遍历を停止します
func (m *Map) Range(f func(key, value any) bool)以下にシンプルなサンプルを使用して sync.Map の基本使用を示します。
func main() {
var syncMap sync.Map
// データを格納
syncMap.Store("a", 1)
syncMap.Store("a", "a")
// データを読み取り
fmt.Println(syncMap.Load("a"))
// 読み取って削除
fmt.Println(syncMap.LoadAndDelete("a"))
// 読み取りまたは格納
fmt.Println(syncMap.LoadOrStore("a", "hello world"))
syncMap.Store("b", "goodbye world")
// map を遍历
syncMap.Range(func(key, value any) bool {
fmt.Println(key, value)
return true
})
}出力
a true
a true
hello world false
a hello world
b goodbye world次に、map を並行処理で使用する例を見てみましょう。
func main() {
myMap := make(map[int]int, 10)
var wait sync.WaitGroup
wait.Add(10)
for i := 0; i < 10; i++ {
go func(n int) {
for i := 0; i < 100; i++ {
myMap[n] = n
}
wait.Done()
}(i)
}
wait.Wait()
}上記の例では通常の map を使用し、10 個のゴルーチンを開始して継続的にデータを格納しました。明らかに、これは fatal をトリガーする可能性が高いです。結果はおそらく以下のようになります。
fatal error: concurrent map writessync.Map を使用すると、この問題を回避できます。
func main() {
var syncMap sync.Map
var wait sync.WaitGroup
wait.Add(10)
for i := 0; i < 10; i++ {
go func(n int) {
for i := 0; i < 100; i++ {
syncMap.Store(n, n)
}
wait.Done()
}(i)
}
wait.Wait()
syncMap.Range(func(key, value any) bool {
fmt.Println(key, value)
return true
})
}出力は以下の通りです。
8 8
3 3
1 1
9 9
6 6
5 5
7 7
0 0
2 2
4 4並行処理安全のために、ある程度の犠牲を払う必要があります。sync.Map のパフォーマンスは map より 10-100 倍程度低いです。
アトミック
計算機科学において、アトミックまたはプリミティブ操作は、通常、さらに細分化できない操作を表すために使用されます。これらの操作はさらに小さなステップに分割できないため、実行が完了する前に、他のゴルーチンによって中断されることはありません。したがって、実行結果は成功または失敗のみで、第 3 の状況はあり得ません。他の状況が発生した場合、それはアトミック操作ではありません。以下のコードをご覧ください。
func main() {
a := 0
if a == 0 {
a = 1
}
fmt.Println(a)
}上記のコードはシンプルな判断分岐で、コードは非常に少ないですが、アトミック操作ではありません。真のアトミック操作はハードウェア命令レベルでサポートされています。
タイプ
幸いなことに、ほとんどの場合、アセンブリを自分で記述する必要はありません。Go 標準ライブラリ sync/atomic パッケージはアトミック操作関連の API を提供しており、以下のいくつかのタイプを提供してアトミック操作を実行できます。
atomic.Bool{}
atomic.Pointer[]{}
atomic.Int32{}
atomic.Int64{}
atomic.Uint32{}
atomic.Uint64{}
atomic.Uintptr{}
atomic.Value{}その中で Pointer アトミックタイプはジェネリックをサポートし、Value タイプは任意のタイプを格納することをサポートしています。除此之外、操作を容易にするために多くの関数も提供しています。アトミック操作の粒度が細かすぎるため、ほとんどの場合、これらの基礎データタイプを処理するのに適しています。
TIP
atmoic パッケージのアトミック操作には関数シグネチャのみで、具体的な実装はありません。具体的な実装は plan9 アセンブリで記述されています。
使用
各アトミックタイプは以下の 3 つのメソッドを提供します。
Load():アトミックに値を取得Swap(newVal type) (old type):アトミックに値を交換し、旧値を返すStore(val type):アトミックに値を格納
異なるタイプには他の追加メソッドがある場合があります。例えば、整数タイプは Add メソッドを提供してアトミック加減算操作を実装します。以下に int64 タイプの例を示します。
func main() {
var aint64 atomic.Uint64
// 値を格納
aint64.Store(64)
// 値を交換
aint64.Swap(128)
// 増加
aint64.Add(112)
// 値をロード
fmt.Println(aint64.Load())
}または関数を直接使用することもできます。
func main() {
var aint64 int64
// 値を格納
atomic.StoreInt64(&aint64, 64)
// 値を交換
atomic.SwapInt64(&aint64, 128)
// 増加
atomic.AddInt64(&aint64, 112)
// ロード
fmt.Println(atomic.LoadInt64(&aint64))
}他のタイプの使用も非常に似ており、最終出力は以下の通りです。
240CAS
atomic パッケージは CompareAndSwap 操作、つまり CAS も提供しています。これは楽観ロックとロックフリーデータ構造の実装の核心です。楽観ロック自体はロックではなく、並行処理条件下でのロックフリー並行処理制御方式です。スレッド/ゴルーチンはデータを修正する前に、まずロックせず、まずデータを読み取り、計算を実行し、その後修正を提出する際に CAS を使用して、この期間中に他のスレッドが該データを修正したかどうかを判断します。修正していない場合(値がまだ以前読み取った値と等しい)、修正は成功します。否则、失敗して再試行します。したがって、楽観ロックと呼ばれる理由は、共有データが修正されないと楽観的に仮定し、共有データが修正されていないことが発見された場合にのみ対応する操作を実行するためです。前述の相互排他量は悲観ロックです。相互排他量は常に共有データが修正されると悲観的に仮定するため、操作時にロックし、操作完了後にアンロックします。ロックフリー実装の並行処理は、その安全性と効率がロックより高いため、多くの並行処理安全なデータ構造は CAS を使用して実装されています。ただし、真の効率は具体的な使用状況に応じて判断する必要があります。以下の例をご覧ください。
var lock sync.Mutex
var count int
func Add(num int) {
lock.Lock()
count += num
lock.Unlock()
}これは相互排他ロックを使用した例で、数字を増加するたびにまずロックし、実行完了後にアンロックします。プロセス中に他のゴルーチンがブロックします。次に CAS を使用して改造します。
var count int64
func Add(num int64) {
for {
expect := atomic.LoadInt64(&count)
if atomic.CompareAndSwapInt64(&count, expect, expect+num) {
break
}
}
}CAS にとって、3 つのパラメータがあります。メモリ値、期待値、新値です。実行時、CAS は期待値と現在のメモリ値を比較し、メモリ値が期待値と等しい場合、後続の操作を実行します。否则、何もしません。Go の atomic パッケージのアトミック操作にとって、CAS 関連の関数はアドレス、期待値、新値を渡す必要があり、置換に成功したかどうかのブール値を返します。例えば、int64 タイプの CAS 操作関数シグネチャは以下の通りです。
func CompareAndSwapInt64(addr *int64, old, new int64) (swapped bool)CAS の例では、まず LoadInt64 を通じて期待値を取得し、その後 CompareAndSwapInt64 を通じて比較交換を実行します。成功しない場合は継続的にループし、成功するまで続けます。このロックフリー操作はゴルーチンをブロックしませんが、継続的なループは CPU にとって小さな負担ではありません。したがって、一部の実装では、失敗が一定回数に達すると操作を放棄する可能性があります。ただし、上記の操作にとって、単なる数字の加算のみで、関与する操作は複雑ではないため、ロックフリー実装を検討できます。
TIP
ほとんどの場合、値を比較するだけでは並行処理安全を達成できません。例えば、CAS によって引き起こされる ABA 問題など、追加の version を使用して問題を解決する必要があります。
Value
atomic.Value 構造体は、任意のタイプの値を格納できます。構造体は以下の通りです。
type Value struct {
// any タイプ
v any
}任意のタイプを格納できますが、nil を格納することはできません。また、前後に格納する値のタイプは一致する必要があります。以下の 2 つの例はコンパイルに合格しません。
func main() {
var val atomic.Value
val.Store(nil)
fmt.Println(val.Load())
}
// panic: sync/atomic: store of nil value into Valuefunc main() {
var val atomic.Value
val.Store("hello world")
val.Store(114514)
fmt.Println(val.Load())
}
// panic: sync/atomic: store of inconsistently typed value into Value除此之外、その使用は他のアトミックタイプと大きな違いはありません。また、すべてのアトミックタイプは値をコピーするべきではなく、それらのポインタを使用するべきです。